Prologue
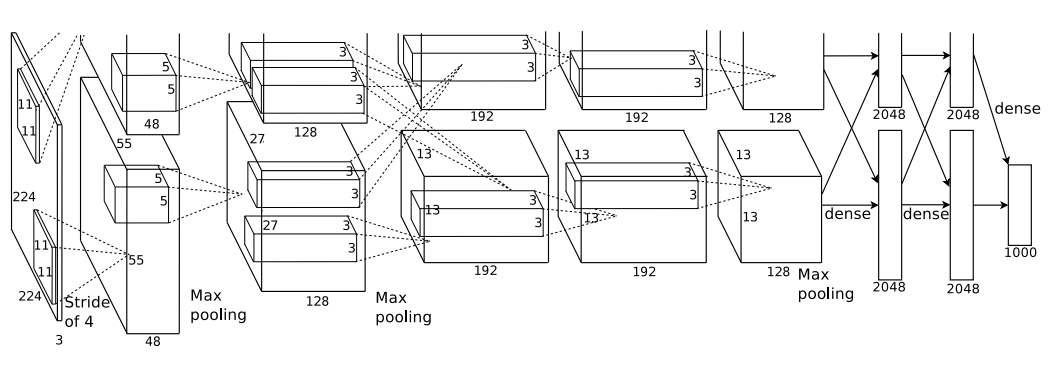
CNN은 일반적으로 pooling layer로 feature map의 크기를 줄이고 그 중 제일 마지막에 나오는 feature map을 활용한다. 먼저 메모리와 연산량을 아끼고 이미지가 가진 중요한 신호가 농축되어 있기 때문이다. 그렇지만 이런 구조는 pooling layer를 지나면서 일부 신호를 잃어버리고 작은 object를 잡아내는 성능이 떨어진다는 단점이 있다.
What did authors try to accomplish?
위의 예시에서 마지막 feature map의 1 pixel은 입력 이미지의 (47, 47)크기의 영역에 해당하는 신호를 담고 있다. 과장을 좀더 보태서 원본 이미지를 (47, 47)크기의 kernel을 이용해서 만들어낸 feature map이 (13, 13)이라고도 할 수 있는데 이 때, (47, 47)보다 작은 물체는 제대로 볼 수 없다는 말이기도 하다.
연구자들은 생각했다.
제일 마지막 feature map뿐만 아니라 앞단에 있는 feature map을 활용하면 성능을 더 끌어올릴 수 있지 않을까?
SSD로 유명한 Single Shot Detector에서 이 가설을 처음으로 검증했다.
Single Shot Detector
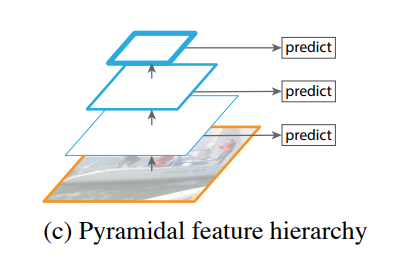
SSD에서는 이렇게 backbone network(VGGNet)가 featrue map을 줄일때마다 bbox를 예측하는 방법을 선택했다. 다만 처음부터 쓰면 모델이 요구하는 메모리 소비량과 연산량이 많아져서 conv4_3부터 썼던 것 같다. 그럼에도 이전 모델보다 작은 물체를 잡아내는 성능이 좋아졌고 후속 연구는 전부 이런 구조를 가지게 됐다. 그러면 backbone network 초반부에서 부터 쓰면 더 좋아지지 않을까?
What were key elements of the approach?
FPN
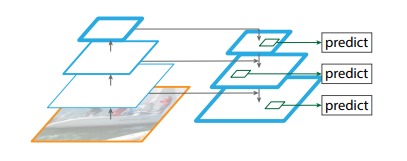
backbone network를 살펴보면 feature map의 높이와 너비를 계산할 수 있다. 일반적으로 이게 같은 feature map을 만드는 conv lyaer를 묶어서 하나의 stage로 본다. 이미지처럼 다른 stage로 넘어갈 때마다 반으로 줄인 feature map을 다시 upsampling한다. 다시 한 번 말하는데 upsampling이다. transpose convolution이 아니다.
Bottom-up
pooling layer를 통해 feature map의 크기를 줄이는 자연스러운 CNN의 전형적인 과정이다. 이 연구에서는 backbone network로 ResNet을 사용했다. ResNet은 총 5개의 stage가 있고 stage 2부터 stage 5에 걸쳐서 feature map의 크기를 반으로 줄인다. 입력 이미지를 4번에 걸쳐서 4배, 8배, 16배, 32배에 걸쳐 줄이게 되어있는데 각 stage에서 나온 feature map을 C2, C3, C4, C5라고 이름붙였다. 요구하는 메모리가 많아져서 stage 1은 포함하고 있지 않고 있다.
Top-down wih lateral connection
상위 stage의 feature map을 upsample하고 bottom-up을 통해 만들어낸 feature map과 합치는 과정이다. bottom-up에 의해 추출한 특성을 가져가는 동시에 더 큰 feature map을 만들 수 있다. 이렇게 bottom-up에서 만든 C2, C3, C4, C5에 대응하는 P2, P3, P4, P5를 만든다. 예를 들어 P5는 C5를 1x1 conv layer로 임의의 channel 로 만들고 나서 aliasing effect를 줄이기 위해 3x3 conv layer를 쓴다.
Aliasing effect
서로 다른 신호가 섞였을 때 각 신호들이 어떤 신호인지 구분할 수 없는 현상
Implementation
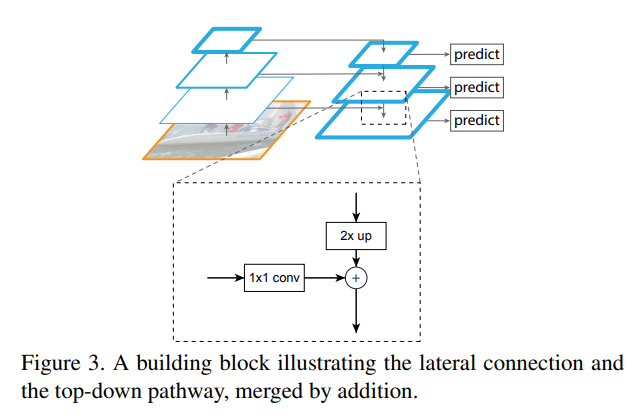
특이한 점은 top-down 때는 activation function을 쓰지 않고 있다. 논문에서는 activation function을 썼을 때는 성능이 떨어진다는 점을 발견했다고 짧막하게 서술하고 있다.
Epilogue
-
연구자들은 CNN에서 중간에 버려지는 feature map이 아까웠고 RPN(Region Proposal Network)을 좀더 효과적으로 쓰고 싶었던 것 같다. 그래서 FPN 이미지에서 보는 것처럼 모든 pyramid level에서 RPN을 적용했다. 기존 Fater R-CNN에 FPN을 적용하는 것만으로 COCO 2016에서 다른 모델을 다 제치고 리더보드 최상단을 차지했다.
-
CNN이 가지는 특성을 최대한 활용하는 구조라서 그런지 어떤 backbone network를 쓰든간에 FPN을 붙여서 쓸 수 있어서 후속연구에서도 많이 나온다.
-
구현하면서 훝어볼 때는 bottom-up과 top-down에서 만든 feature map을 합하고 정리하는 차원에서 3x3 conv layer를 쓰는 줄 알았다. 그러면서도 upscaled P3와 C2를 더하면 신호들이 전부 짬뽕이 되서 분간할 수 없을 것 같은데 3x3 conv layer를 쓴다고 이게 제대로 되나 싶었다. 논문이 그렇다고 하니까 일단 받아들이긴 하는데 한 번 파봐야겠다.
