- updated Aug.15.21: 모델구현 추가
Prologue
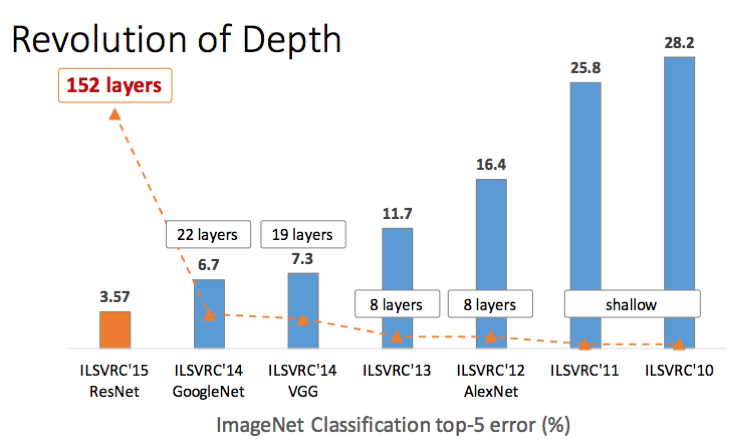
이 그래프의 주인공이자 CNN의 게임 체인저. 아직도 이 연구의 영향에서 못 벗어났다고 하는 말이 있을 정도다. 기존에 19-30 layer에 그친 depth를 152 layer까지 폭발적으로 늘리면서 ILSVRC 2015에서 우승했다.
What did authors try to accomplish?
CNN의 발전방향은 중 하나는 layer를 많이 쌓는 것이다. 그동안 축적된 연구를 통해 layer가 많을 수록 feature map이 가진 정보를 다채롭게 할 수 있다는 점이 parameter가 좀 적어도 좋은 성능을 보장한다고 경험적으로 알게 됐다. 그래서 연구자들은 모델을 할 수 있는 한 최대로 깊게 만들고 싶었다.
What were the key approaches?
Overcoming degradation
모델을 학습하는데는 vanishing / expolding gradient문제가 연구자들을 괴롭히는데 적어도 이런 문제들은 weight initialization이나 batch norm으로 해결할 수 있었지만 이번에는 또 다른 문제와 마주한다.
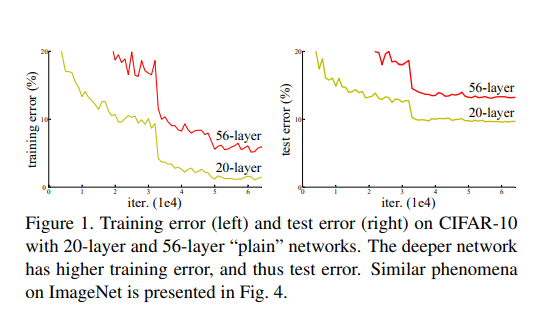
보다시피 성능개선을 위해 layer를 더 쌓았음에도 불구하고 오히려 성능이 떨어졌다고 관찰했다. 어쩌면 overfitting때문에 일어나는 것으로 생각할 수도 있지만 아닌 이유는 layer를 더 쌓으면 두 지표가 동시에 악화하기 때문이다. 이 현상을 degradation이라고 한다. 이제 문제는 degradation을 해결하는 것으로 바뀌었다.
degradation 연구하려고 한 가지 가정을 한다. 얕은 모델에 같은 layer를 몇 개 쌓으면 성능차이가 없어야 하지 않을까?
잠깐 생각해보면 깊은 모델이 얕은 모델보다 성능이 비슷하거나 미세하게나마 좋아야 하지만 실험결과는 그렇지 않았다. 오히려 얕은 모델이 더 좋았는데 identity mapping 사이에 있는 activation function때문에 identity mapping을 근사하지 못하는 것이 문제였다. identity mapping은 어떻게 하지?
Identity mapping
그래서 identity mapping을 원활하게 하려고 "출력값을 내보내기 전에 입력값을 더해주면 어떨까?"하고 생각하면서 shortcut connection을 이용하기로 했다.
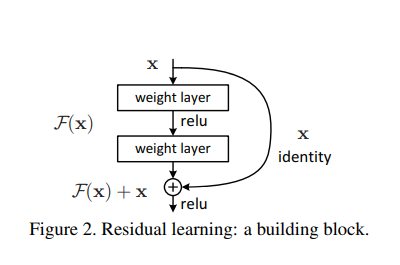
이렇게 입력값을 더해주는 건 identity mapping 외에도 parameter를 더해주지 않는다는 장점도 있다. 이미지에서는 2 layer로 표현했지만 복잡하게 하려면 얼마든지 복잡하게 할 수 있다. 연구자들은 이 모듈은 residual module이라고 부르기로 했다. 수식으로 접근하자면 residual module은 아래와 같이 표현할 수 있다.
이 때, 라는 점에서 이 모듈로 identity mapping을 해야 한다면 우리 목표는 백지에서 idnetity mapping을 만들어내는 학습하는 대신 입력값과 결과값의 차이를 학습하는 것으로 과제는 단순해진다. 이 때 한 가지 더 생각해볼 점은, 이 모듈의 최적해가 identity mappinng이라면 중간에 있는 weight layer들은 0에 매우 가까운 값이 될 거다.
identity mapping을 하는 것까지는 좋다. 주의할 점은 와 를 더하려면 서로 크기가 같아야 한다. 두 feature map의 (H, W)가 다를 때는 padding을, depth가 다를 때는 1x1 conv layer를 활용한다. 그래서 기존의 residual module은 이렇게 바뀐다.
추가적으로 성능을 높이기 위해 wieght layer와 relu layer 사이에 Batch norm layer를 사용했다.
Comparision
연구자들은 shortcut connection을 뺀 plain model과 residual model을 비교하는 실험을 진행했다.
학습은 아래와 같이 했다.
Dataset: ImageNet 2012
Batch size: 256
Iteration:
Optimizer: SGD with momentum(momentum 0.9)
Learning rate: 0.1 if error is not imporved it is divided by 10
Weight decay 0.0001
이 비교실험에서 degradation문제는 residual module로 해결하면서 덩치 큰 모델을 만드는데 성공했다고 입증했다.
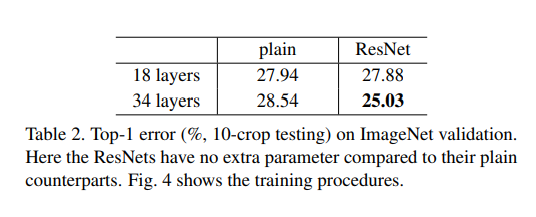
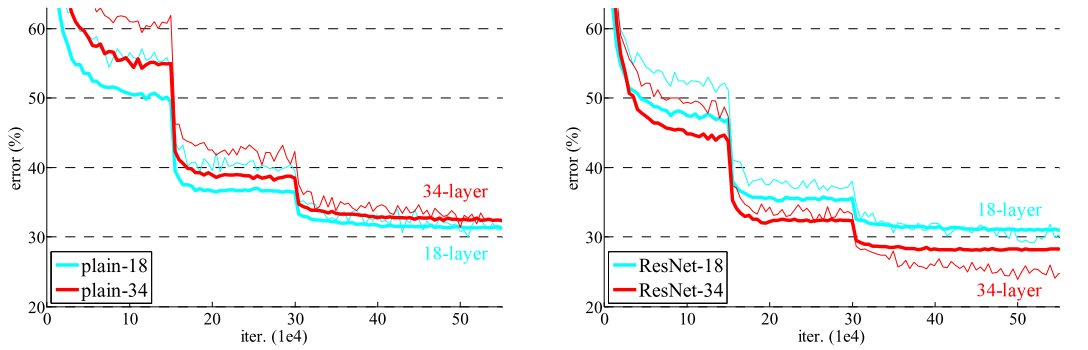
연구자들은 이 실험에서 degradation은 gradient vanishing때문에 일어나지 않는다고 봤다. 주목할 점은 plain model 사이사이에 BN layer를 사용하고 있어서 forward와 backward 모든 과정에서 gradient를 전해주는데는 문제가 없었고 VGGNet보다 크지만 오히려 성능이 좋았다. 여기에서 ResNet의 핵심은 residual module과 BN layer 두 가지라고 해야하지 않을까 싶다.
Architecture
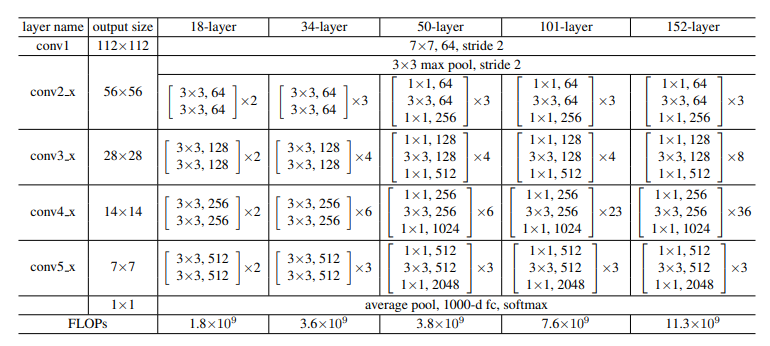
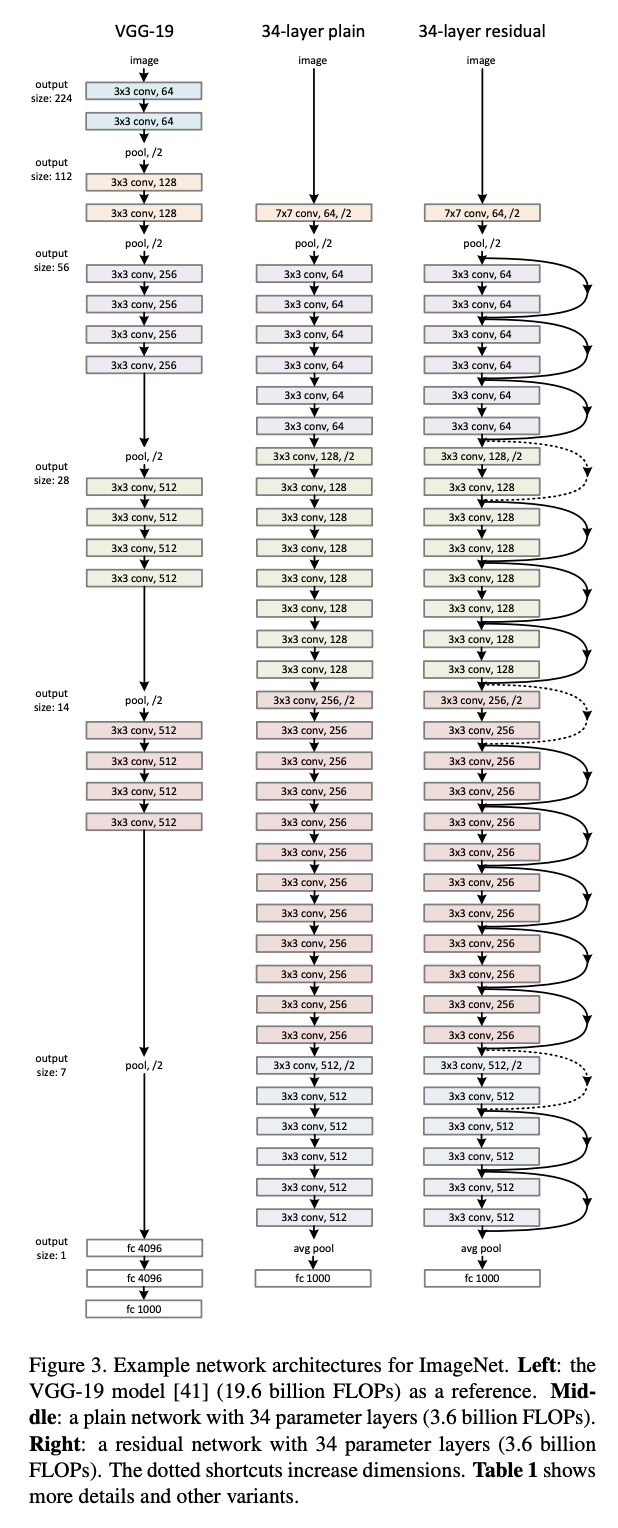
연구자들이 설계했던 전체 모델들의 구조를 정리한 표다. feature map의 줄어들 때마다 stride는 2로 한다. 출력층에서 FC layer대신 GAP를 써서 따로 dropout을 쓰지 않았다.
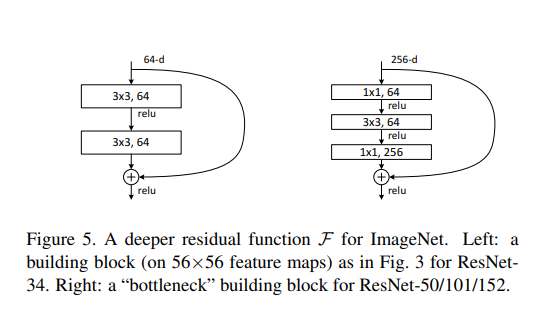
34 layer보다 더 큰 모델을 만들 때는 지금까지의 연구에서 그렇듯 parameter를 줄이기 위해 오른쪽 모듈을 활용했다.
Epilogue
연구자들은 호기심에 1202 layer까지 쌓아봤다고 적고 있다. 이 실험에서는 training error는 비슷했지만 test error는 오히려 110 layer 모델이 더 낮았다. 이게 overfitting으로 인한 degradation이다. 학습데이터로 CIFAR-10써서 1202 layer 모델이 학습하기에는 데이터가 모자랐던 것 같다.
