Prologue
GoogLeNet을 읽다가 같이 읽은 논문.
What did authors try to accomplish?
기존의 CNN에서 사용하는 연산을 조금 바꿔서 표현력을 좀더 키우고 싶었던 모양이다. 근데 문제가 있었다.
What were key approaches?
MLPConv layer
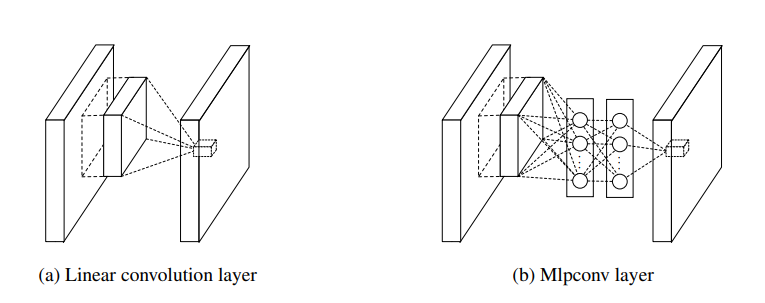
Universal approximation theorem에 근거를 두고 frobenius product를 하는 대신 kernel만큼의 영역을 Multi-layer Perceptron(MLP)처럼 연산하기로 했다. 그래서 mlpconv layer다. conv layer 안에 network가 하나 더 있다고 해서 Network in Network라는 이름이 붙었다. 수식으로 살펴보면 구체적인 연산과정이 와닿을 거다.
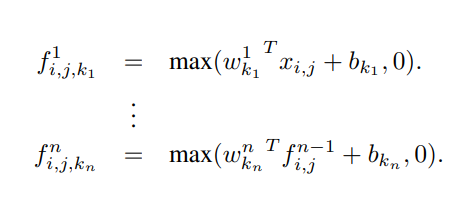
수식에서 은 MLP의 레이어 수다. 여기에서는 MLP의 노드 수, 레이어 수를 hyperparameter로 남겨뒀다는 점이 인상적이다.
이렇게 하면 feature map을 만들 때 activation function을 하나 지나므로 기존의 CNN보다는 표현력이 좋을 것 같다. 그렇지만 FC layer 같은 구조는 parameter가 급격히 늘어난다는 문제가 있다. 연구자들은 dropout보다 효과적인 방법을 찾아야 했을 거다.
Cross channel pooling
MLP로 인해 크게 늘어난 parameter를 줄이기 위한 방법이다. 2차원 평면상에서 pooling하는 게 아니라 1픽셀 크기의 채널단위로 pooling하는 작업이다.
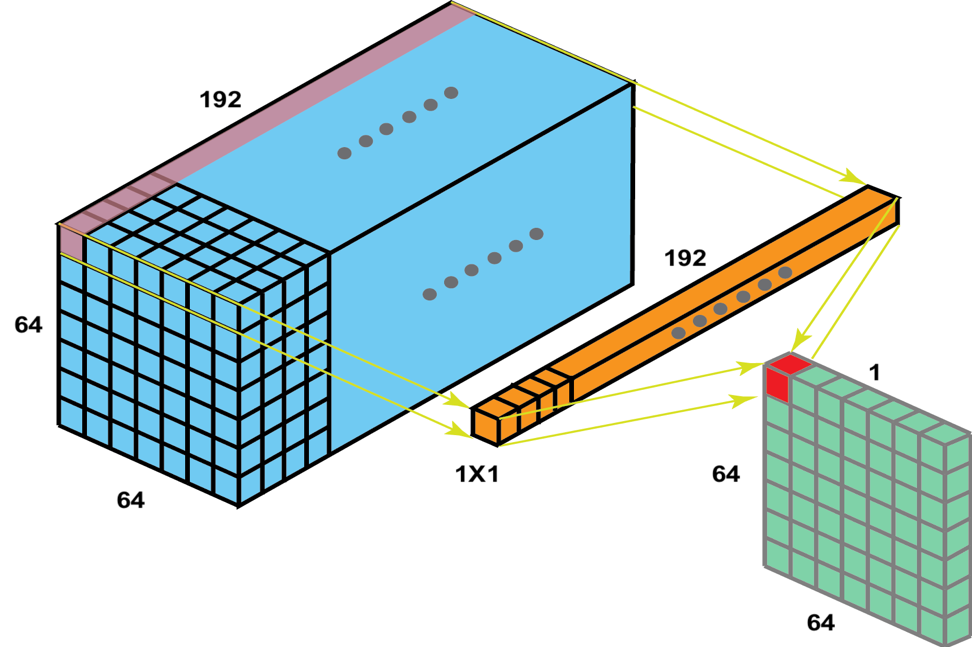
이미지처럼 (H, W, C)크기의 feature map을 cross channel pooling하면 기존에 C장이던 feature map이 (H, W)크기의 feature map 1장이 남는다. 논문에서도 이 연산은 1x1 conv layer와 같다고 서술하면서 이 점이 NIN을 좀더 직관적으로 보는 방법이라고 하고 있다.
Global Average Pooling(GAP)
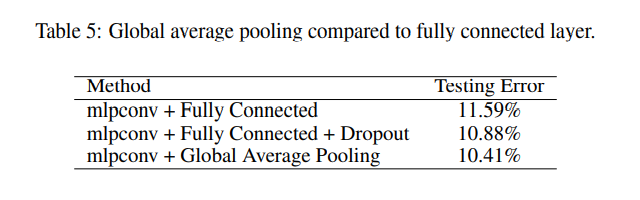
(H, W, 1)크기의 feature map을 평균내서 scalar로 만들어 feature map 하나에 하나의 클래스를 분류할 수 있도록 했다. 예를 들어 10개의 클래스를 분류하는 과제라면 (H, W, 10)크기의 feature map을 만들고 GAP를 수행하면 (10,)크기의 벡터가 하나 나온다. 다시 생각해보면 10장의 feature map은 10개 클래스 각각의 confidence score라고도 볼 수 있다. 가장 큰 장점은 parameter를 없앨 수 있다는 점이다. 전체 parameter의 90% 정도가 FC layer에 있는데 parameter를 확실히 줄여줘서 overfitting을 막아주는 역할도 한다고 실험으로 증명했다. 세 가지의 모델을 만들고 각각의 출력단에 아래와 같이 바꿔서 CIFAR-10을 학습해본 실험이다.
추가적으로 이건 나아가서 Fully Convolution Network(FCN)에도 쓰이게 된다.
Architecture
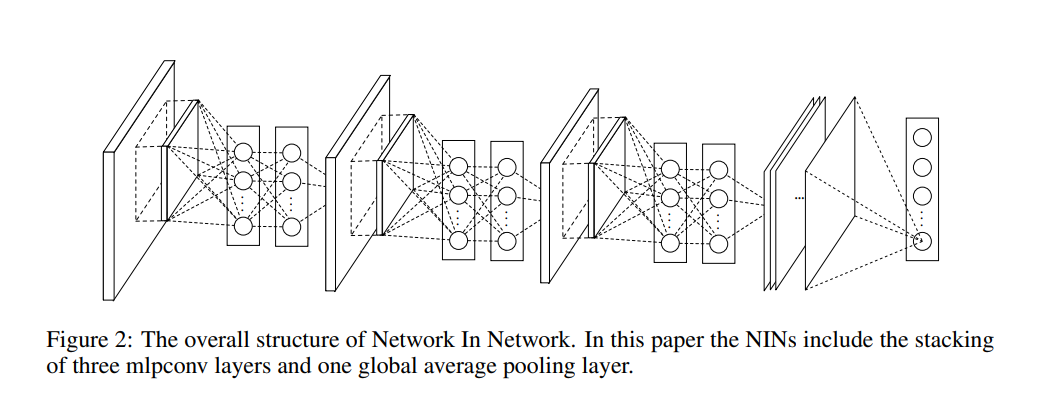
이미지에서 보는 것처럼 MLPConv layer를 주욱 붙인 다음에 출력단에 GAP를 붙였고 기존의 CNN처럼 layer 중간중간에 pooling layer를 붙인다.
MLPConv layer - cross channel pooling - MLPConv layer - cross channel pooling - ... - Global Average Pooling(GAP)Epilogue
CNN에서 게임체인저가 되지는 못 했지만 parameter를 효과적으로 줄이는 방법을 제안했다는 측면에서는 딥러닝의 발전에 기여한 연구다.
