- updated Jul.30.21: 모델구현
Prologue

딥러닝에서 유명한 짤이다. 코드명이 인셉션이라서 그런지 Reference 1번에 위 이미지 주소를 달아놨고 딥러닝 분야의 유명한 밈이 됐다.
What did authors try to accomplilsh?
모델성능을 끌어올리는데 가장 직관적인 방법은 덩치를 키우는 것이다. 모델을 크게만드려면 3가지 방법이 있다.
- Deeper model(more layer)
- Wider model(more node)
- Both
무작정 크게 만들면 parameter도 함께 늘어난다. 일반적으로 모델이 커지는 속도보다 더 빠른 속도로 늘어나는데 이것은 곧 overfitting과 직결된다. 특히 dataset이 제한적일 때는 더 심각해진다.
이뿐만 아니라 커진 모델은 더 많은 계산자원을 요구한다. 이게 모자라면 학습이 시작하기도 전에 GPU서버가 터지는 불상사를 마주할 수도 있다.
AlexNet에서 VGGNet으로 발전하면서 모델 성능을 개선했지만 parameter 증가는 막을 수 없었다. 모바일기기, 임베디드가 늘어나는 현실을 고려하면 연구자들은 성능은 조금 양보하더라도 여기에 맞는 모델을 만들고 싶었던 것 같다.
What were the key approaches?
모순적인 이야기처럼 들리지만 크고 parameter가 적은 모델을 만드는 게 목표였다. 지금까지 overfitting을 피하기 위해 여러 학습기법을 도입했다면 이 연구는 parameter를 줄여서 연산량을 줄이는 한편, overfitting을 막기로 했다.
parameter를 줄이려면 sparse model을 만들어야 하는데 우리 컴퓨터는 dense structure 연산이 효율적이어서 sparse sturcture 연산은 오히려 계산비용이 많이 든다. dense layer module을 활용해서 부분적으로나마 sparse model을 근사하는 모듈을 설계하기로 했다. 그 이론적인 근거는 Hebbian theory가 자리하고 있다.
Hebbien theory
Things that fire together wire together.
이렇게 한 마디로 정리할 수 있다. 좀더 쉽게 말해 축구선수는 풋살을 곧잘 할 수 있다는 학습심리와 연관할 수 있다.
Arora et al의 연구에서 거대 sparse model로 데이터셋의 확률분포를 표현할 수 있다면 optimal model은 이전 layer에서 넘어오는 신호의 상관성을 분석하고 상관성이 높은 노드들을 모으는 layer를 쌓아서 구현할 수 있다고 수학적으로 증명하면서 모듈을 쌓아서 전체 모델을 구현하는 것의 이론적인 뒷받침이 됐다.
Naive Inception module
그래서 연구자들은 inception module을 고안해서 쌓기로 했다.
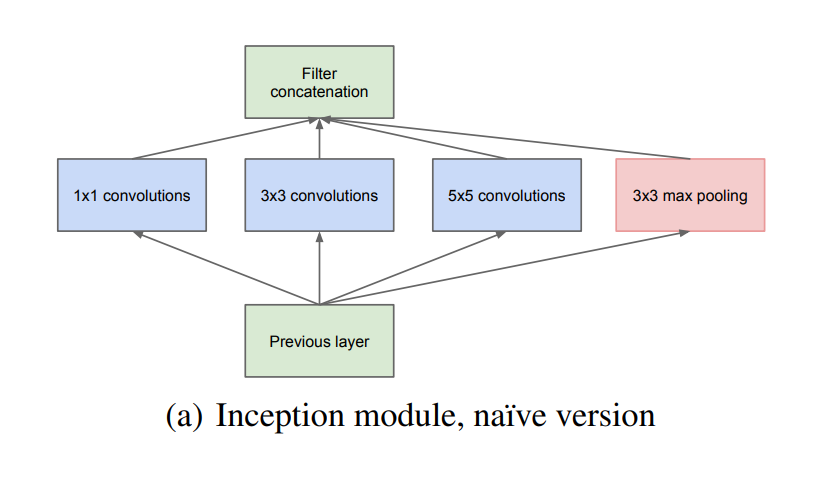
여러 크기의 Gabor filter로 다양한 크기의 물체를 포착했던 연구를 근거로 1x1, 3x3, 5x5 conv layer와 여러 CNN에서 사용하는 것처럼 max pooling layer도 하나 넣어서 합쳤다.
Drawback
여기에는 치명적인 약점이 있는데 모듈을 쌓을수록 3x3, 5x5 conv layer에 의해 parameter가 급격히 늘어난다는 점이다. 여기에 pooling layer에서 나온 feature map을 얹어서 모듈을 지날 때마다 채널이 점점 늘어난다는 점이 문제를 더 키웠다.
Inception module with dimension reduction
parameter를 줄이기 위해 아래 모듈처럼 중간에 1x1 conv layer를 거치게 했다.
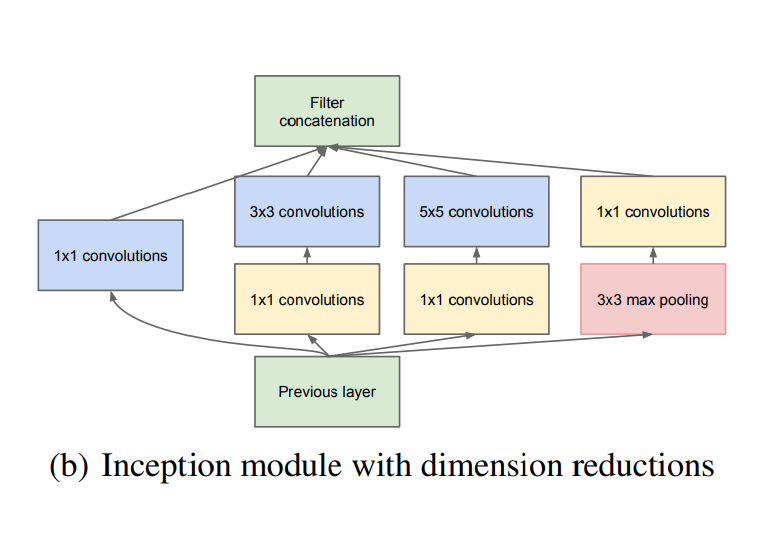
1x1 conv layer
최근에 나오는 모델에서 자주 볼 수 있는 1x1 conv layer는 Network in network에서 cross channel pooling이라는 모양으로 먼저 제안했다. 이 연구의 영향을 받아서 GoogLeNet에서는 1x1 conv layer을 적극적으로 쓰고 있다.
1x1 conv layer가 효과적으로 parameter를 줄여준 덕분에 VGGNet 보다 더 깊고 넓지만 적은 계산량을 가진 모델을 설계할 수 있었다.
이건 내 추측이지만 parameter를 줄이려는 시도 외에 Arora et al이 제안했듯 이전 모듈에서 넘겨주는 신호들 중 상관성이 높은 것들을 1x1 conv layer를 통해 묶어주려는 목적 또한 있지 않나 싶다.
Archetecture
특히 연구자들이 고려했던 것은 컴퓨팅 성능이 제한적인 기기에 모델을 실어도 원활하게 작동하는 모델을 만들어내는 것이었다. 그 중 가장 성능이 좋았던 22 layer 모델을 논문에 실었다.
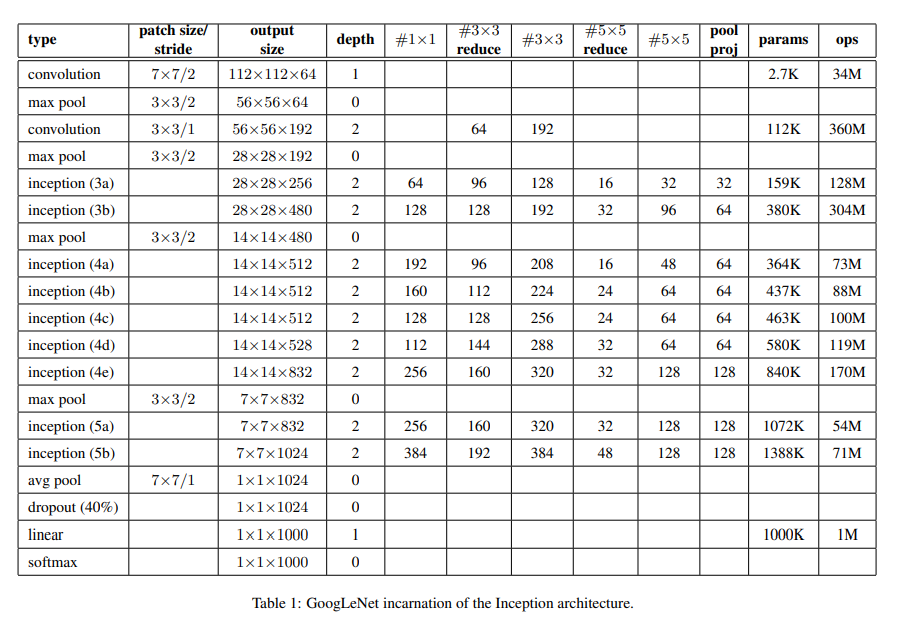
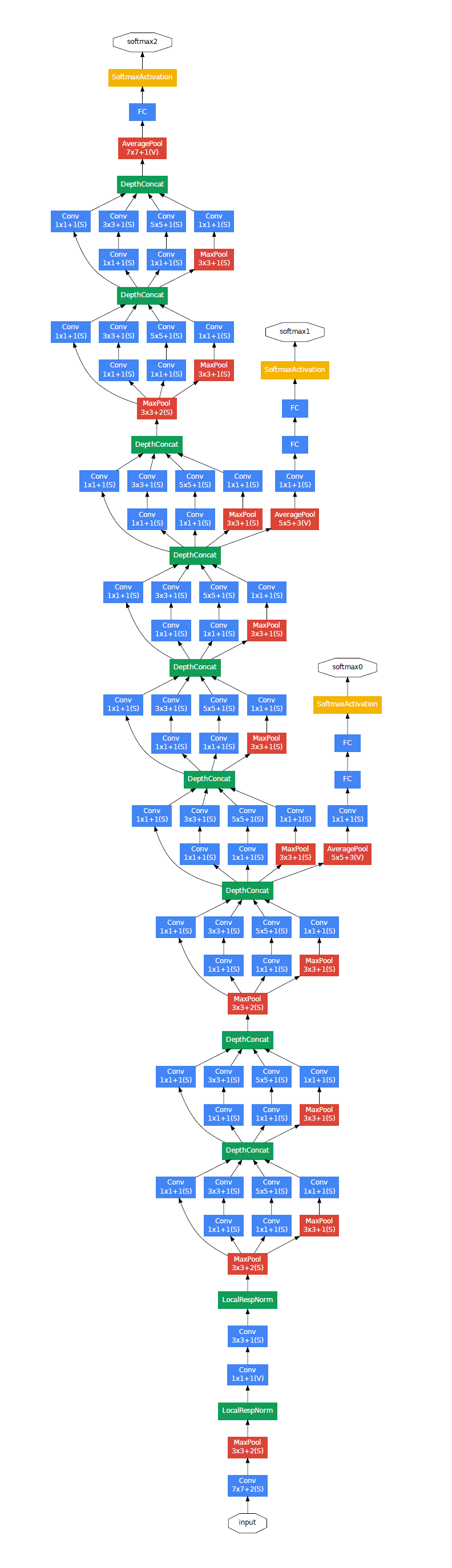
입력단에서는 (224, 224, 3) 크기의 이미지를 입력받고 모델에 들어가는 activation function은 전부 relu를 쓴다. 그리고 특이한 건 출력단 근처에서 GAP를 쓴다는 점인데 parameter가 없는 구조를 쓰고 있음에도 여전히 FC layer에서 dropout layer에 의존적이다. 아마 Batch norm이 등장하기 전이라서 그런 것 같다.
이전에는 없던 크기의 모델이었기 때문에 gradient를 입력단까지 전하는 것이 또 하나의 과제였던것 같다. 고민의 결과가 중간중간에 있는 branch network를 통해서 입력단까지 gradient를 전하기로 했다. 학습에서 loss가 3개가 생긴다. 그래서 loss를 구할 때 branch network에서 나온 loss는 0.3을 곱해서 main network loss와 더하고 추론할 때는 branch network를 무시한다.
Train
분산처리 환경에서 momentum을 0.9로 하는 asynchronous SGD with momentum을 optimizer로 사용했다. learning rate는 8 epoch마다 0.96을 곱해준다.
분산환경에서 앙상블로 학습해서 그런가 구체적인 hyperparameter는 알 수 없었다.
Epilogue
- 결과적으로 layer를 더 쌓으면서 계산량이 Alexet보다 12배 적은 모델을 만들어냈고 ILSVRC 2014에서 우승했다. 이론적으로 parameter가 적다는 데서 오는 성능적인 단점을 더 깊고 넓은 모델의 구조적인 이점에서 극복했다는 점이 인상적이었다.
- 이 논문을 읽으려고 같이 읽은 논문이 3편이다. 구현할 줄만 알면 됐지 이거 괜히 건드렸나 싶었다. 특히 Arora et al(Provable Bounds for Learning Some Deep Relationships) 이 논문은 저자들이 주장하는 바 말고 근거나 증명을 제대로 이해 못 한 것 같다. 분산처리 환경에서 학습하는 건 어떤 건지 읽어봐야겠다.
