- updated Dec.10.21: 구현 추가
Prologue
classifier를 detector로 만들어주는 핵심구조다. Faster R-CNN의 연구자들은 기존에 쓰던 selective search대신 region proposal network(RPN)를 제안했다. 이후의 detector들은 RPN을 조금씩 변형해서 활용하고 있다.
Selective search

Faster R-CNN이전의 detector에서 RoI를 추출하기 위해 사용했던 알고리즘이다. 원래는 sementic segmentation을 위해 개발했다. 이미지에서 잘 보여주듯이 유사도가 높은 pixel들을 점차 병합하는 방법을 쓰고 있는데 selective search를 detector에 쓰기에는 크게 2가지 문제가 있었다.
- 학습이 안 되서 detector의 성능개선이 어렵다.
- gpu와 cpu사이에 data를 주고받아야 해서 느리다.
RPN
이 문제를 해결하기 위해 backbone과 함께 gpu상에서 돌아가면 좋겠다고 생각했고 기왕에 gpu에서 돌릴 거면 작은 network를 만들기로 했다. 그러면 두 문제를 해결할 수 있지 않을까?
Architecture
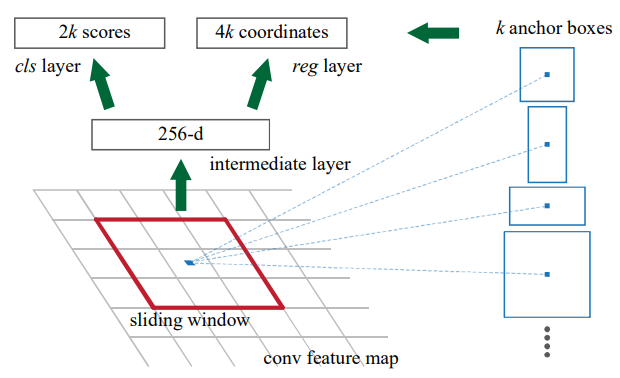
이미지에서 보는 것처럼 RPN은 conv layer 3개로 구성하고 있다.
- Intermediate layer
feature map을 크기의 kernel을 사용한다. reg layer
1의 결과에 크기의 kernel을 사용해서 bounding box(bbox)의 위치와 크기를 학습하고 예측한다. layer의 이름으로 알 수 있듯이 linear function을 activation function으로 쓴다.cls layer
1의 결과에 크기의 kernel을 사용한다. 이름은 classifier지만bbox안에 있는 object가 foreground인지 background인지 학습하고 예측하므로 sigmoid function을 activation function으로 쓴다.
연구에서는 anchor 하나에 9개의 anchor box를 생성하게 했다. 이렇게 layer를 모아서 subnetwork를 구성했으면 backward pass의 시작점인 loss function이 있어야 한다.
Loss function
Loss function은 Fast R-CNN에서 썼던 multi-task loss를 거의 그대로 가지고 왔다.
는 mini batch에 들어간 anchor의 index, 가 붙은 건 truth label이다. 는 anchor box의 objectness에 대한 예측값이므로 , 는 bbox의 좌표 4개(center x, center y, width, height)로 이루어져있다. 앞에 를 곱해주는 이유는 bbox 안에 object가 없으면 계산하지 않겠다는 의미이다.
Problem
여기까지 했으면 subnetwork와 loss function까지는 구현했다. 나는 여기에서 좀 막막했었다. 한동안 머릿속을 떠나지 않았던 점은 training data와 함께 집어넣을 truth label이 없다는 것이었다. 없으면 직접 만들어야지.
Anchor
feature map의 spatial dimention의 넓이만큼 anchor를 만들어서 image에 뿌린다. 예를 들어 resnet의 feature map이 가진 spatial dimention은 이므로 크기의 image 위에 anchor를 개 만들어서 뿌린다.
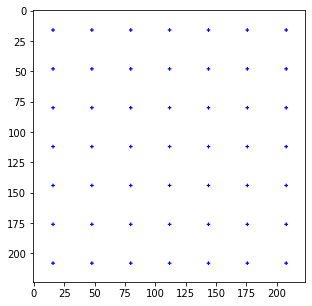
Anchor box
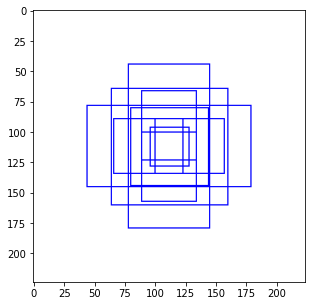
이렇게 만든 anchor를 중심으로 하는 box를 만든다. 아무렇게나 만드는 건 아니고 3가지 aspect ratio와(box의 가로, 세로 비율) 3가지 scale을(box의 크기) 조합해서 총 9개를 만든다. 이 연구에서 aspect ratio는 , scale은 의 조합을 사용했다.
그러면 image 한 장당 개의 anchor box를 만든다.
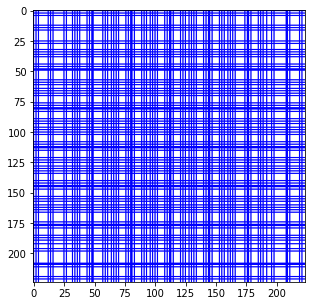
물론 위에서 만든 anchor box중에는 image를 튀어나가는 것도 있을텐데 그런 것들은 지금은 싹다 무시한다. 추가적으로 모든 anchor box에 -1로 label을 달아둔다.
Thresholding
이제 image위에 있는 anchor box와 true box를 비교해서 IoU를 계산하는데 0.7이상인 anchor box는 foreground로, 0.3미만인 anchor box는 무시, 그 중간에 남는 anchor box는 background로 한다.
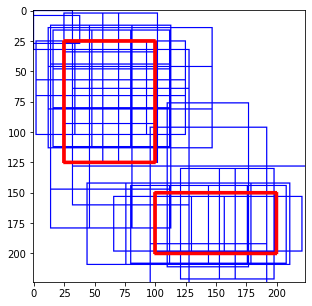
여기까지 했으면 anchor box label을 한 번 업데이트 해줄 차례다. IoU가 0.7 이상인 anchor box에는 1을, 0.3 미만인 anchor box는 0으로 바꿔준다.
Bounding box regression
이렇게 해도 여전히 true box와 bbox가 차이나는데 RPN에서는 이 차이를 계산해서 backward pass에서 쓸 수 있도록 했다.
truth label을 , predicted value를 라고 할 때 우리가 할 일은 가 에 최대한 가깝게하는 함수 를 찾는 것이다. R-CNN에서는 를 찾는 방법을 이렇게 제안했다.
좌표는 좌표끼리, 길이는 길이끼리 계산해야 한다고 생각해서 저 방법이 와닿지 않았다. 그럴 땐 시각적으로 보자.
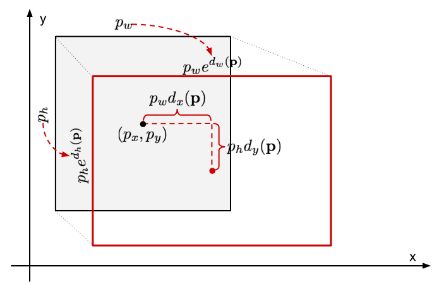
빨간선이 true box, 검은선이 prediected box다. 좌표만 따로 봤을 때 가 음수일 때는 는 왼쪽으로, 양수일 때는 오른쪽으로 움직인다. 다만 에 대한 비율로 왔다갔다 해서 변화가 크지는 않을 거다. 반면 높이와 너비는 때문에 bbox의 크기는 작은 변화에도 크게 늘었다 줄었다 할거다. 이것만 보면 RPN은 bbox의 크기를 예측하기 위한 network가 아닌가 싶다.
를 계산해보면 아래와 같다.
이 식을 활용해서 앞서 구한 전체 anchor box 중에서IoU가 0.7이상인 anchor box들의 dx, dy, dw, dh를 구한다.
이렇게 구한 objectness score와 box coordinate는 RPN에서 truth label역할을 하게 된다.
Epilogue
여기까지 하면 RPN을 학습할 준비가 됐다. RPN 이후에 RoI pooling layer에 넣기 전에 후보로 남은 anchor box 중에 N개를 골라내고 NMS를 해야하는 과정이 더 남았다.
image 안에 들어오는 anchor box를 보면 알겠지만 모서리에 가까운 영역은 anchor box가 없다시피 하다. 이걸 없애려면 anchor를 좀더 뿌리는 feature map을 디자인하거나 anchor box를 촘촘하게 뿌릴 수 있는 aspect ratio와 scale을 찾아야 한다. 나같은 경우에는 aspect ratio와 scale을 마구 조절하고 있었는데 몇 번 해보다가 문득 aspect ratio와 scale을 학습할 수도 있겠다는 생각이 들었다. 당연히 누군가가 관련연구를 수행했고 이것도 읽을 예정이다.
