Prologue
jpg(jpeg) 이미지는 r, g, b 이렇게 세가지 채널로 구성하고 있다.

이 중에 한 가지 채널이 너무 강하면 적당히 눌러줄 필요가 있다 그럴 때 쓰라고 있는 게 오늘 알아볼 histogram equalization이다.
각 픽셀의 밝기나 색깔이 얼마나 강한지 히스토그램으로 분석해서 너무 강한 픽셀은 0-255 사이의 값으로 평준화 해주는 거다. gray scale 이미지에서는 어느 정도로 밝은지, rgb이미지에서는 어떤 색이 강한지 알아볼 때도 쓸 수 있을 것 같다.
By NumPy
먼저 numpy로 내부적으로 어떻게 돌아가는지 알아보자. 먼저 이미지를 각 채널별로 쪼개서 이미지 안에서 픽셀이 가지는 밝기의 분포를 알아보자.
hist = np.zeros((3,256))
channel_wise = sooty_rgb.reshape(-1, 3)
for h in range(len(hist)):
for i in range(len(channel_wise)):
hist[h][channel_wise[i, h]] += 1
channel = ['r', 'g', 'b']
plt.figure(figsize=(11, 4))
for idx, H in enumerate(hist):
plt.subplot(1, hist.shape[0], 1+idx)
plt.bar(np.arange(hist.shape[1]), hist[idx])
plt.xlabel(f'{channel[idx]}')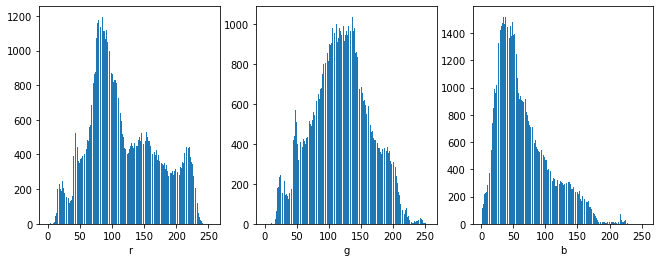
각 체널별로 특정 영역의 밝기가 많다는 점을 알 수 있다. 앞으로 해야 할 일은 지배적으로 나타다는 밝기를 좀 눌러주는 거다
누적히스토그램을 구현해볼 거다.
for h in hist:
for i in range(1, 256):
h[i] += h[i-1]
for h in range(len(hist)):
for i in range(len(channel_wise)):
hist[h][channel_wise[i, h]] += 1
channel = ['r', 'g', 'b']
plt.figure(figsize=(11, 4))
for idx, H in enumerate(hist):
plt.subplot(1, hist.shape[0], 1+idx)
plt.bar(np.arange(hist.shape[1]), hist[idx])
plt.xlabel(f'{channel[idx]}')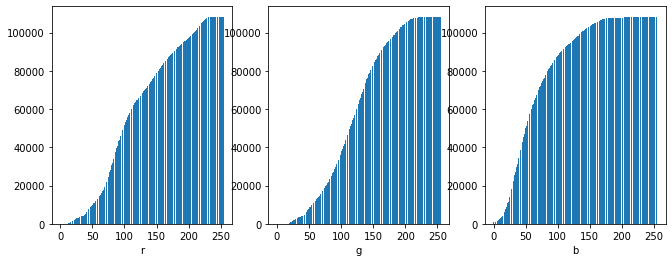
이렇게 십만단위로 누적한 히스토그램의 scale을 0-255사이로 바꿔주면 원본에서 히스토그램의 튀어나왔던 부분을 좀 눌러줄 수 있을 거다.
for i in range(len(hist)):
hist[i] = np.uint8(hist[i] * 255 / len(channel_wise) + 0.5)
channel = ['r', 'g', 'b']
plt.figure(figsize=(11, 4))
for idx, H in enumerate(hist):
plt.subplot(1, hist.shape[0], 1+idx)
plt.bar(np.arange(hist.shape[1]), hist[idx])
plt.xlabel(f'{channel[idx]}')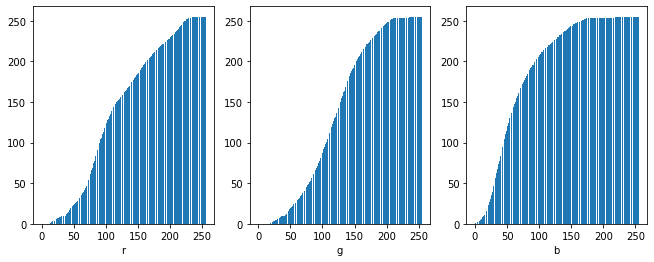
이 픽셀의 분포를 원본 이미지 픽셀의 분포로 다시 mapping해준다.
post = np.zeros_like(sooty_rgb)
for h in range(len(new)):
for w in range(len(new[0])):
for c in range(len(hist)):
post[h, w, c] = hist[c][sooty_rgb[h, w, c]]
new_hist = np.zeros((3,256))
new_wise = new.reshape(-1, 3)
for h in range(len(new_hist)):
for i in range(len(new_wise)):
new_hist[h][new_wise[i, h]] += 1
channel = ['r', 'g', 'b']
plt.figure(figsize=(11, 4))
for idx, H in enumerate(new_hist):
plt.subplot(1, new_hist.shape[0], 1+idx)
plt.bar(np.arange(new_hist.shape[1]), H )
plt.xlabel(f'{channel[idx]}')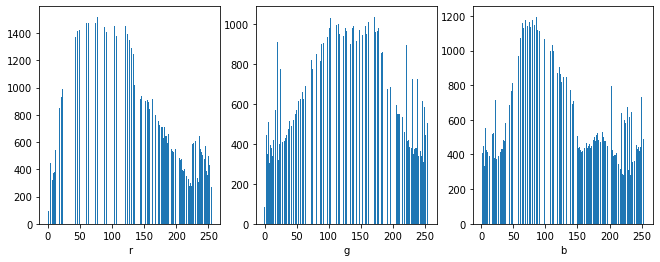
원본 히스토그램보다 rgb값의 분포가 균일해졌다.


사과라는 건 좀 흐릿해졌지만 병든 부분은 좀더 선명하게 드러났다. 주변은 마스크로 가리고 사과부분만 하면 좀더 정확할 것 같다.
By OpenCV
opencv에서는 equalizeHist()라는 함수 하나만으로 똑같은 결과를 만들 수 있다.
out = np.zeros_like(sooty_rgb)
for i in range(out.shape[-1]):
out[:, :, i] = cv.equalizeHist(img[:, :, i])훨씬 편하고 빠르다.
Epilogue
오픈 라이브러리를 쓴다고 무조건 나쁜 게 아니라 오히려 생산성을 높여줄 수 도 있겠다고 느꼈다. 대신 오픈 라이브러리를 썼을 때 언제, 왜 쓰는지 뿐만 아니라 내부적으로는 어떤 원리로 돌아가는 건지 알아두면 좀더 공부가 되는 것 같다.
