Prologue
대표적인 1 stage detector의 SOTA detector다. 2 stage detector는 2개의 subnetwork가 bbox를 찾고 그 안에 있는 object를 분류했지만 YOLO계열 detector는 bbox와 object classfication을 한 방에 예측한다.
1 stage detector
그래서 이런 detector를 1 stage detector라고 부른다. backbone이 만드는 feature map안에 detection에 필요한 정보가 다 들어있기 때문인데 feature map의 channel방향에 들어있는 정보들은 anchor box coordinate(), objectness score(), class score()가 들어있다. 그래서 feature map의 channel은 이렇게 결정된다.
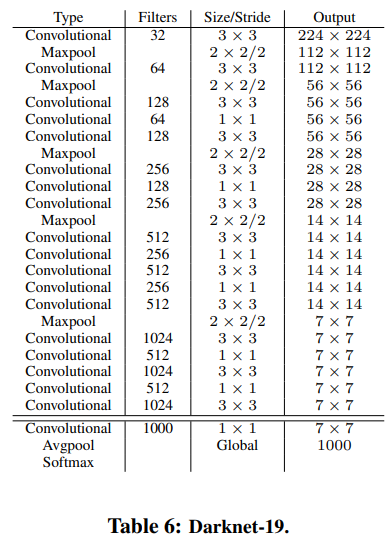
Backbone
VGGNet처럼 Conv layer로 feature를 추출하고 pooling layer로 spatial dimension을 줄인다. 이전 연구와는 다르게 fc layer를 버리고 Batch Norm과 anchor를 도입했다.
작은 object에 대한 성능을 높이기 위해 출력 stage와 그 직전의 stage를 dimension과 channel을 맞춰서 concatenate한다.
How is anchor defined?
RPN에서는 aspect ratio 개, scale 개를 정해서 anchor마다 개의 anchor box를 찾게 했다면 여기에서는 전체 data에서 자주 나타나는 height, width쌍 개를 찾는다. 이렇게 찾은 anchor 개를 가지고 k-means알고리즘을 활용해서 gird cell마다 몇 개의 anchor뿌릴지 정했다.

일반적으로 k-means는 data point의 거리를 최소로하는 집합 개를 구하는 알고리즘이다. 이 연구에서는 data point의 거리 대신 IoU를 활용했다.
그래프에서 가 를 넘어가는 시점부터 기울기가 완만해진다. 동시에 anchor box가 일때 recall도 높게 할 수 있었다.
Offset
기본적으로 RPN과 YOLOv2가 를 찾는 방법은 크게 다르지 않다.
RPN
RPN에서는 anchor box의 의 비율로 를 ground truth에 최대한 가깝게 한다. 일반적인 경우 변동폭이 크지 않지만 극단적인 경우에는 subsample을 벗어날 수 있다고 우려했다.
YOLOv2
연구에서는 이 점을 지적해서 가 확실하게 grid cell에 들어있게 하기 위해 offset function을 이렇게 바꿨다.

ground truth가 속한 grid cell의 upper left corner, 가 속한 grid cell의 upper left corner를 구하면 를 알 수 있다. 은 이므로 는 노란 grid cell에만 넣어둘 수 있다는 점에서 RPN보다 안정적으로 bbox의 위치를 예측할 수 있다고 주장하고 있다.
Loss function
후속연구에서 패러다임이 바뀌지 않았으므로 YOLOv1과 같은 loss function을 쓴다.

Epilogue
-
RPN에서는 입력 이미지 위에 anchor를 뿌리게 되어있는데YOLOv2에서는 feature map위에 anchor를 뿌리게 되어있다. 그러면 입력 이미지와 feature map의 비율을 계속 추적해야하지 않나 싶다. -
2 stage detector는 bbox와 classification을 따로 하기때문에 전체적인 context를 읽는 능력이 떨어지지만 YOLO같은 1 stage detector는 전체 이미지를 보기때문에 비교적으로 context를 읽는 성능이 좋다고 주장하고 있다.
-
YOLOv3에서는 그냥 backbone을 바꾸면서 약간 튜닝하는 것만으로 SOTA detector를 만들어냈다.
