Lecture 2
Image Classification
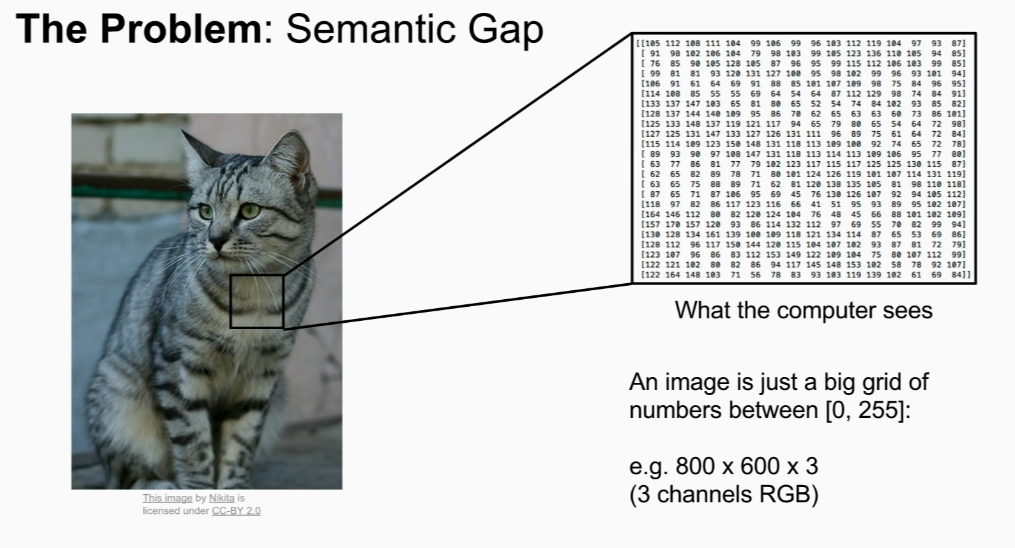
image -> pre determined set (categori label) => find one!
challenges: Viewpoint variation, Illimination, Deformation, Occlusion, Background Clutter, Intraclass variation,

attempts to write high-end coded rules
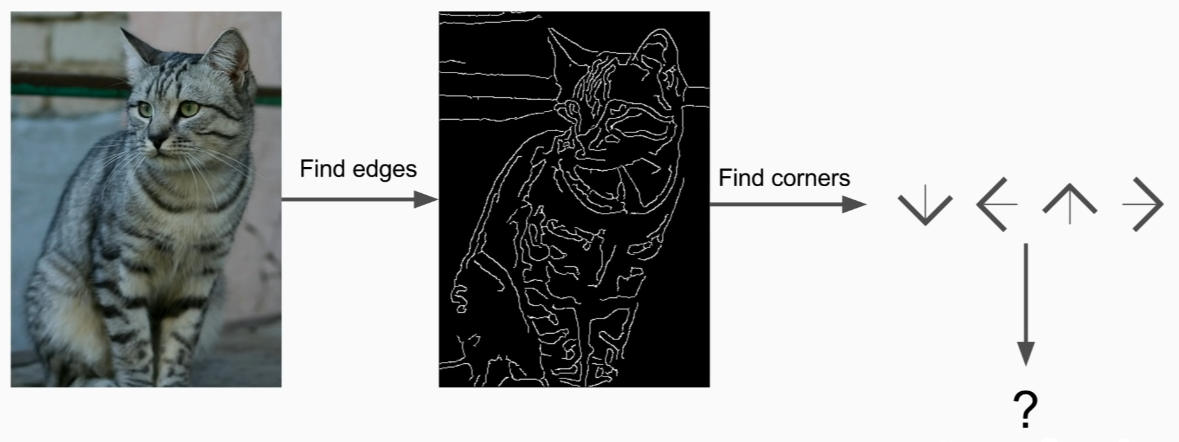
but super brittle and need to make new rules for new object
=> Data Driven Approach

Nearest Neighbor
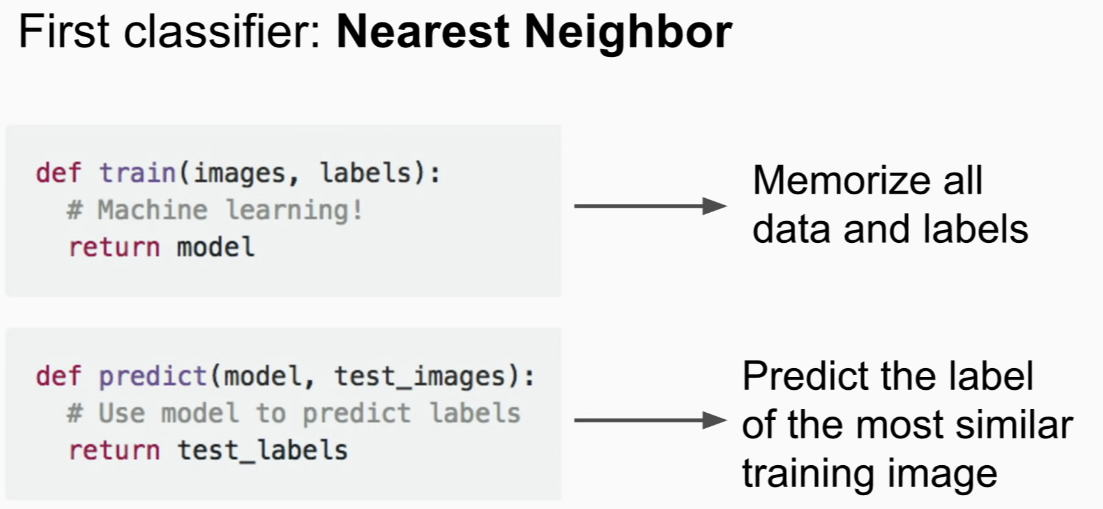

give test image=> find similar images from train images=> check label
how do we actually compare them?
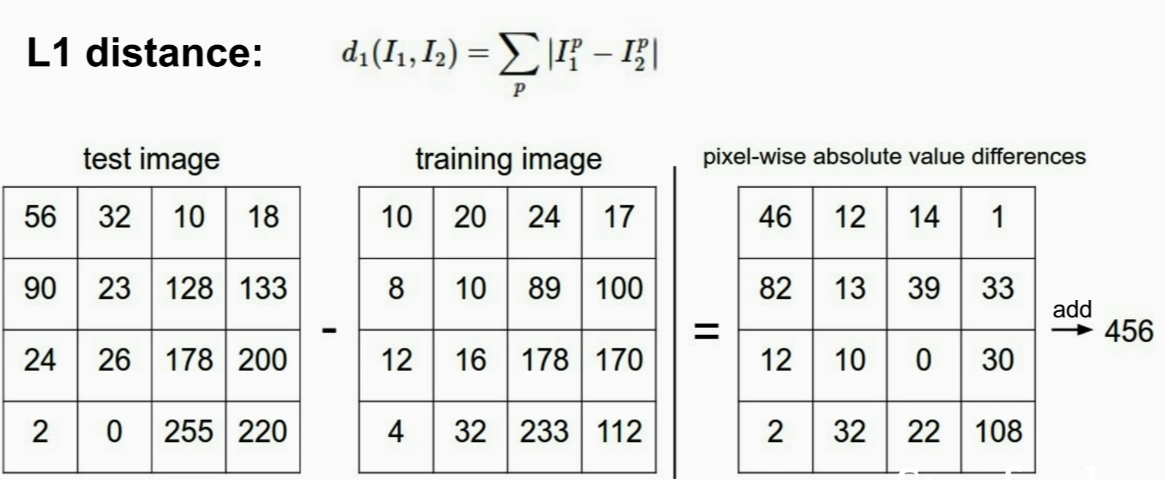
L1 Distance(Manhattan Distance)
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self,X,y):
self.Xtr=X
self.ytr=y
def predict(self,X):
num_test=X.shape[0]
Ypred=np.zeros(num_test,dtype=self.ytr.dtype)
for i in range(num_test):
distances=np.sum(np.abs(self.Xtr-X[i,:]),axis=1)
min_index=np.argmin(distances)
Ypred[i]=self.ytr[min_index]
return Ypredif N examples in training set how fast the training and predicting to be?
Training => O(1)
Predicting => O(N)
BAD
we prefer slow training, fast predicting!

take K Neighbors and take a vote
How to compare pixels?
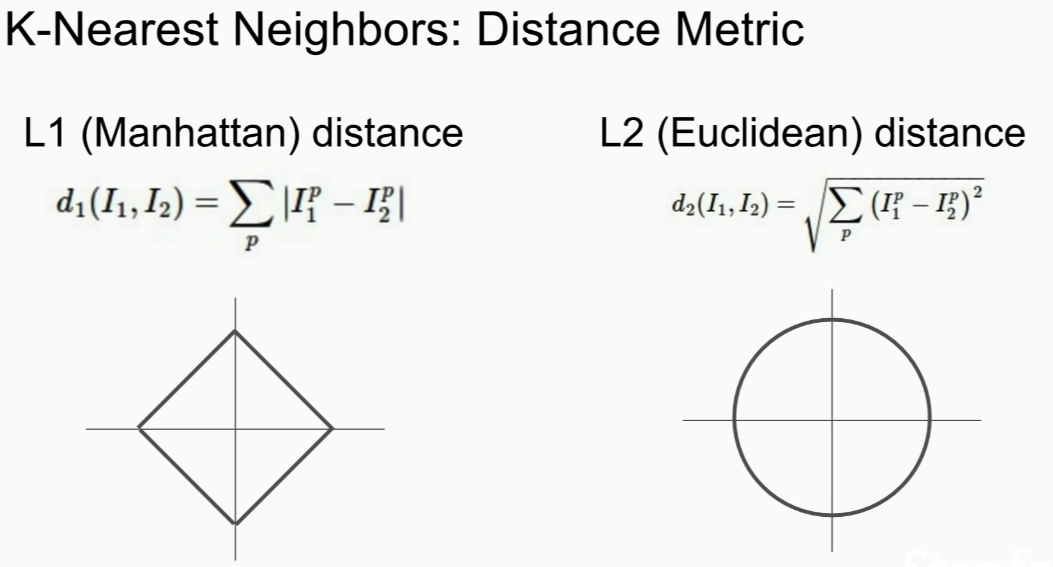
L1 depends on coordinate but L2 does not

Red,blue,yellow == all the same L1 distance
green= L2 distance!
if input feature vectors have individual meanings (ex. height,weight), L1 might be better. but if you don't know what they mean, L2 is better!

Choices in K NN
Hyper parameters!
best is to try and see what works the best
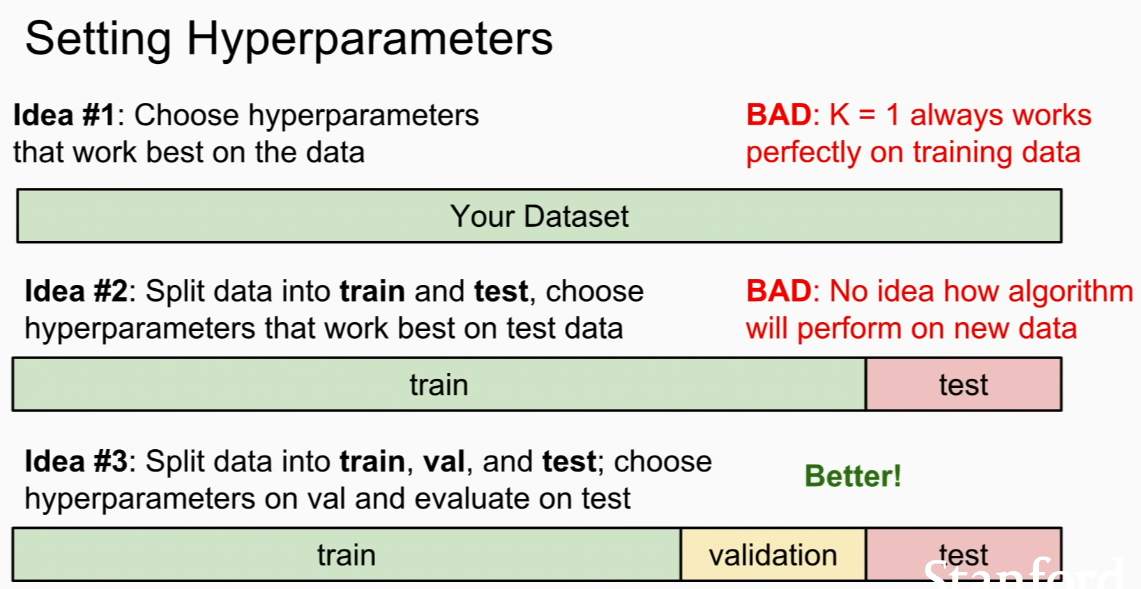
main goal => we want model which well performs on unseen data in training
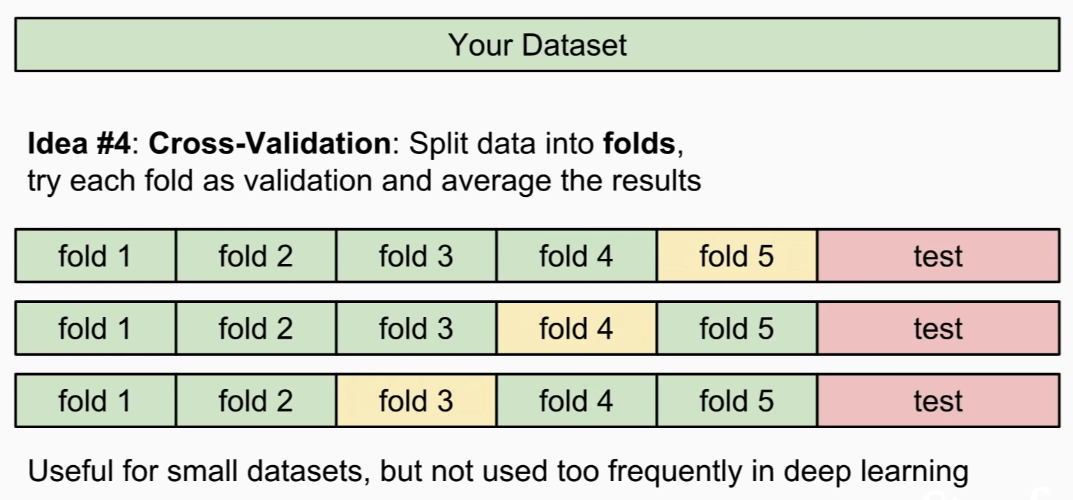
cross validation is commonly used for small data sets, not much used in deep learning
in practice when training large model, it takes too much time, computaional expenses
test data might not represent the whole world problems well, so when splitting a dataset, must consider.
one way is just collect all the data at once => randomly split train,test( not by time or smth)
KNN in Images
NEVER USED!
- Very Slow at test time
- Distance metrics L1,L2 are not really good way to measure in images

- Curse of Dimensionality

to KNN to work well, we need training examples to cover the space densely == need exponentially increasing amount of data as the dimension increases!
Linear Classification
parametric model

larger score = label!
deep learning => how to build function f!?!
b= bias data independant preferences for some classes ex. if dataset is unbalance and tehre more dogs than cats, add bias for dogs
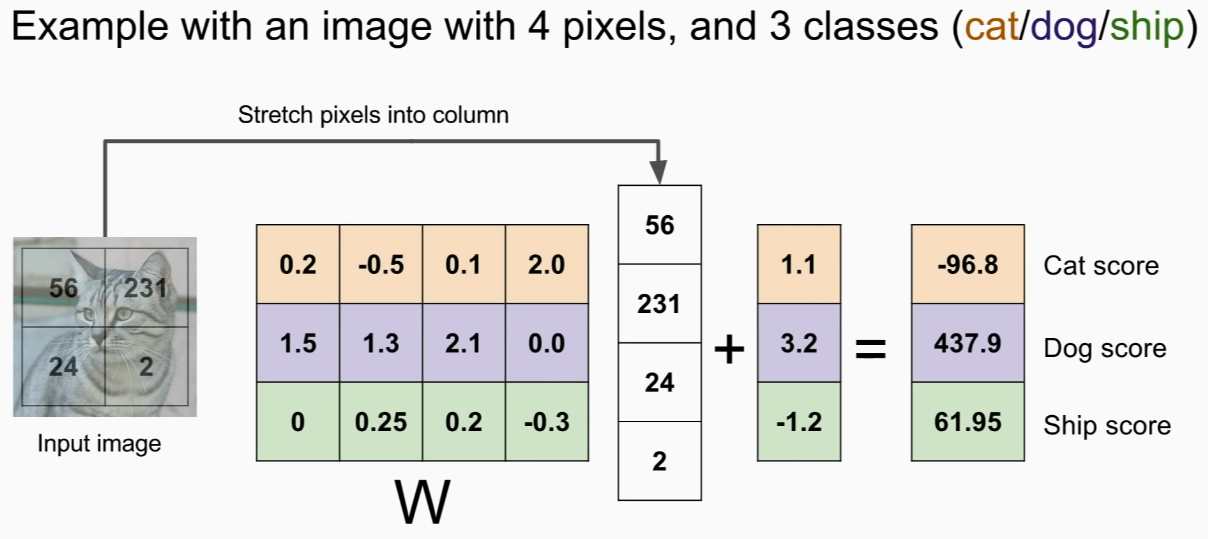
dot product! gives similarity of class!
like template matching

take wieghts of classifier and make it into image!
linear classifier is learning only one template for each class!
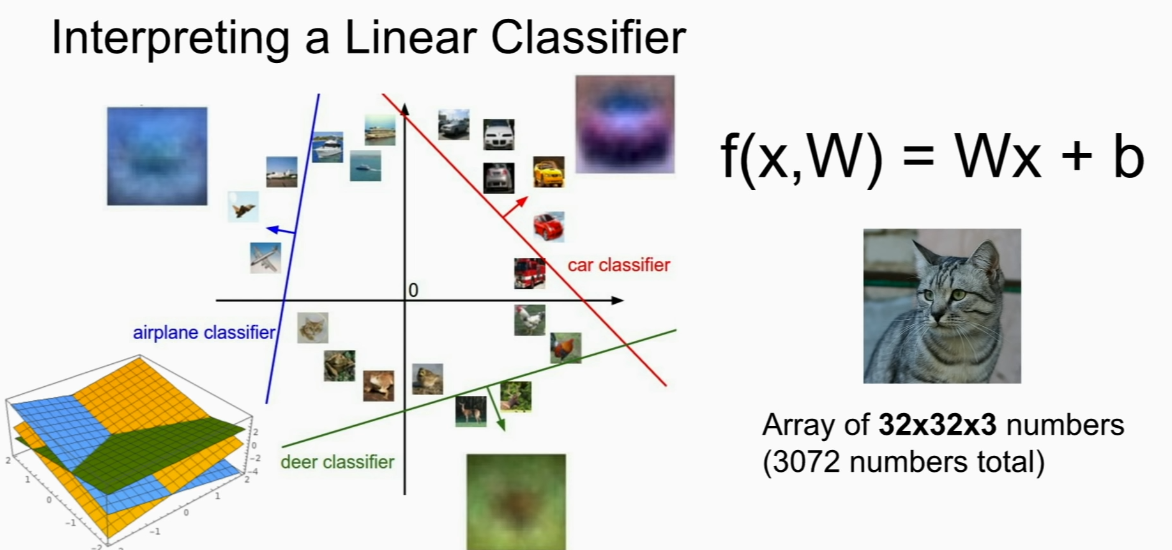
problems of linear classifiers=

cant seperate using one line.
