
1. Background
- The relational model:
1) Uses the concept of a mathematical relation (like a table of values) as its basic building block, and
2) Has its theoretical basis in set theory (집합 이론) and first-order predicate logic (1차 술어 논리).- First-order logic: Predicates are only applied to individuals not functions or other predicates.
E.g., “Socrates is mortal.” (O) “Being beautiful is good.” (X)
- Values의 table 같은 Mathematical relation을 사용
- set theory(집합 이론)과 first-order predicate logic(1차 술어 논리)에 theoretical basis를 둔다.
- First-orde logic : 술어는 function이나 다른 술어가 아닌 개별 개체에만 적용된다.
2. Relational Model Concepts
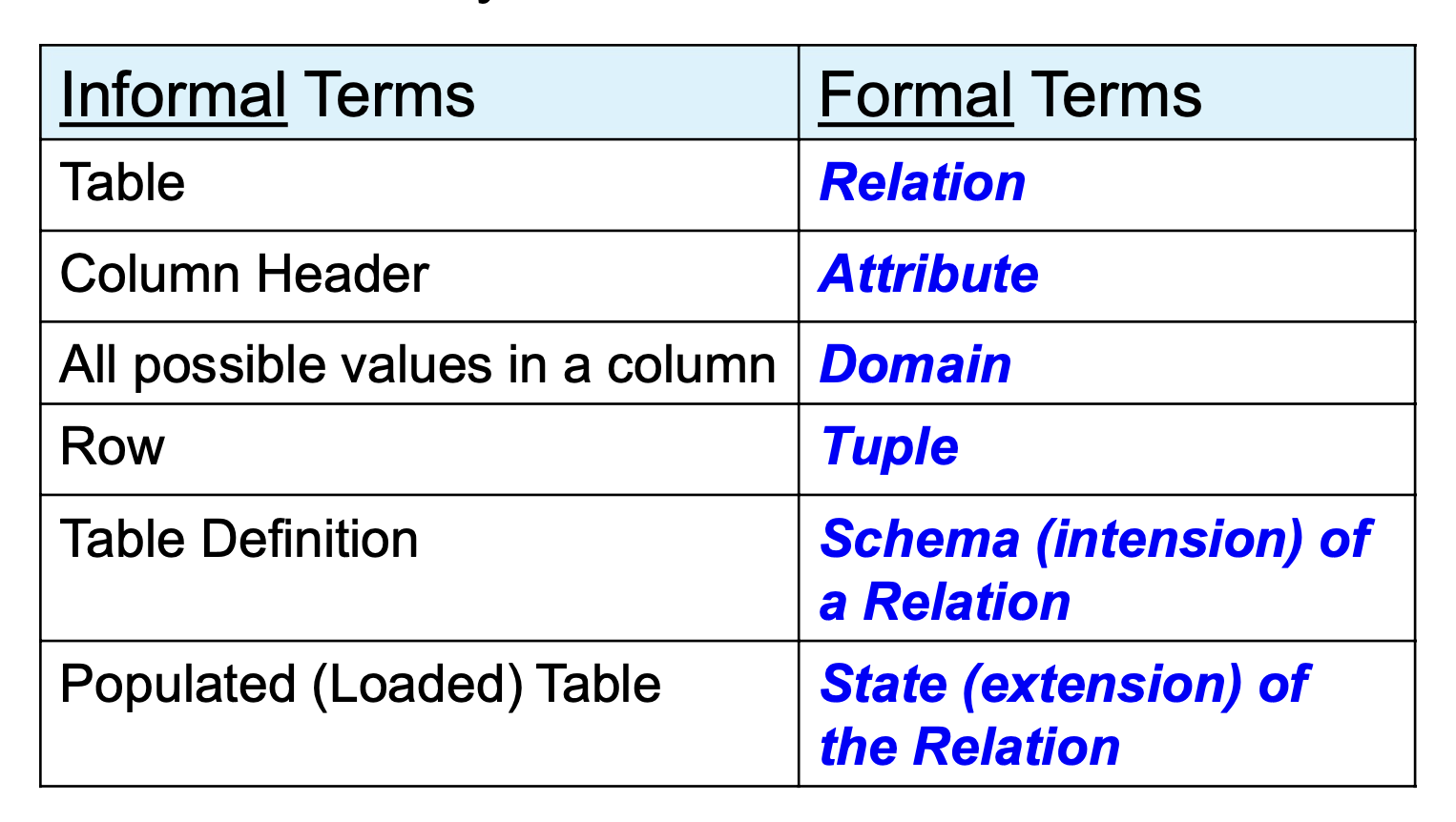
2-1. Relations Model Concepts: "Informal" Definitions
Relation : A mathematical concept based on the ideas of sets.
관계는 set의 idea에 base를 둔 수학적 concept이다.
Relational model에서 database는 관계의 collection이라고 한다.
- A relation looks like a table(informal) of values, or a flat file of records (because of its flat structure)
관계는 값들의 table(informal) 또는 records의 flat file처럼 보인다.
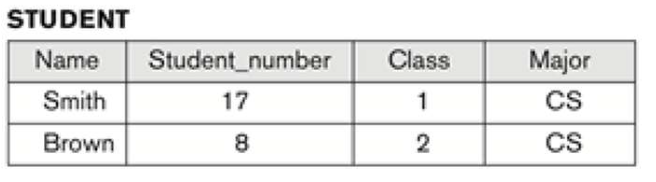
- A relation typically contains a set of rows (informal).
- relataion은 일반적으로 rows(informal)들의 set을 포함한다.
- 각 row는 entity 또는 relationship에 상응하는 fact를 나타낸다.
- Formal한 모델에서는 row를 tuple이라고 부른다.
- Each Column has a column header (informal), delivering the meaning of the data items in that column
- 각 column은 해당 column에 저장되는 data items의 의미를 전달하는 column header를 가진다.
- formal model에서는 column을 attrubte라고 부른다.
Formal model - Relaion, Tuple, Attribute
Informal - Table, Row, Column header
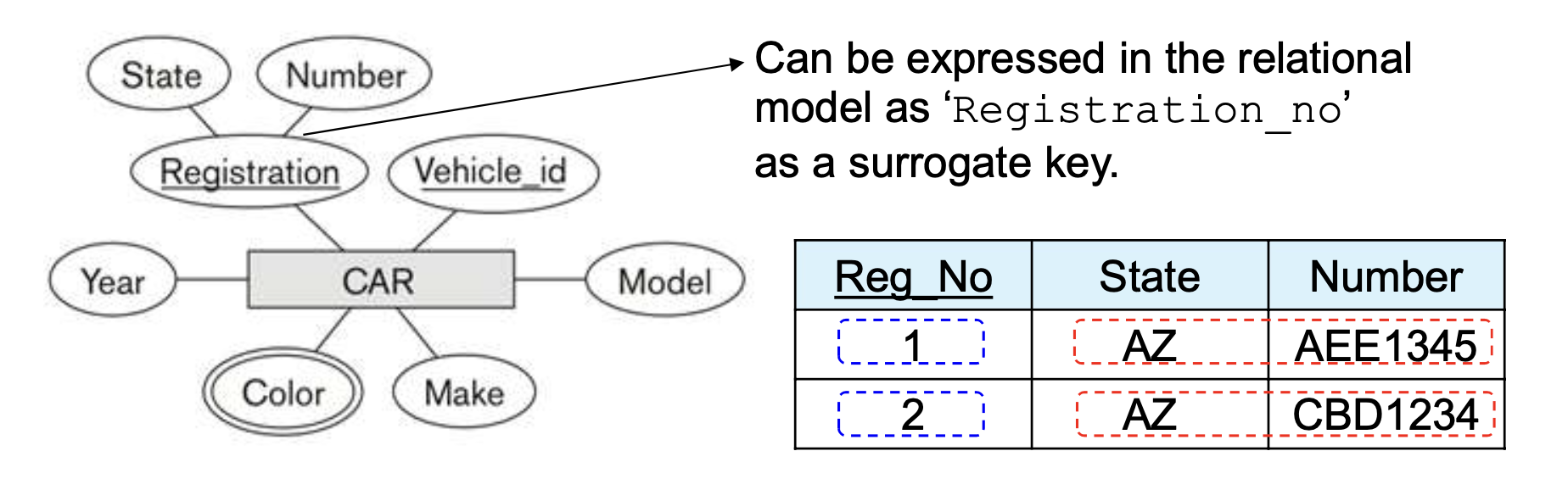
Key of a relation
- 각 Row는 table에 존재하는 row를 유일하게 구분하는 data element의 값을 가지고, 이를 key라고 부른다.
- 가끔식 row id나 sequential number를 키로 사용하는데 이를 surrogate (or artificial) key라고 부른다. 간단하게 table 안에서 row를 식별하기 위한 용도이다.
- Key attribute라고 무조건 의미있는 attribute를 사용할 필요는 없다.
2-2. Relational Model Concepts: "Formal" Definitions
2-2-1. Schema
The schema of a relation:
Relation을 묘사하기 위해 R(A1,A2, ... , An) 으로 표현힌다.
Relation R의 degree (or arity) : R의 attributes의 수

Example
CUSTOMER (Cust-id, Cust-name, Addr, Phone#)
- What's the relation name ?
Customer - Defined over the four attributes: what ?
(Cust-id, Cust-name, Addr, Phone#) - What's the degree of relation ?
4
Each attribute has a domain (to be discussed soon) of a set of valid values.
• E.g., The domain of Cust-id: 6 digit numbers. (C.f. the domain of unsigned int: 0 ~ (2^32-1))
각 attributes는 valid한 values 집합의 domain을 가진다.
Cust-id의 domain은 6개 digit number를 가진다. -> 6자리 숫자만 취급
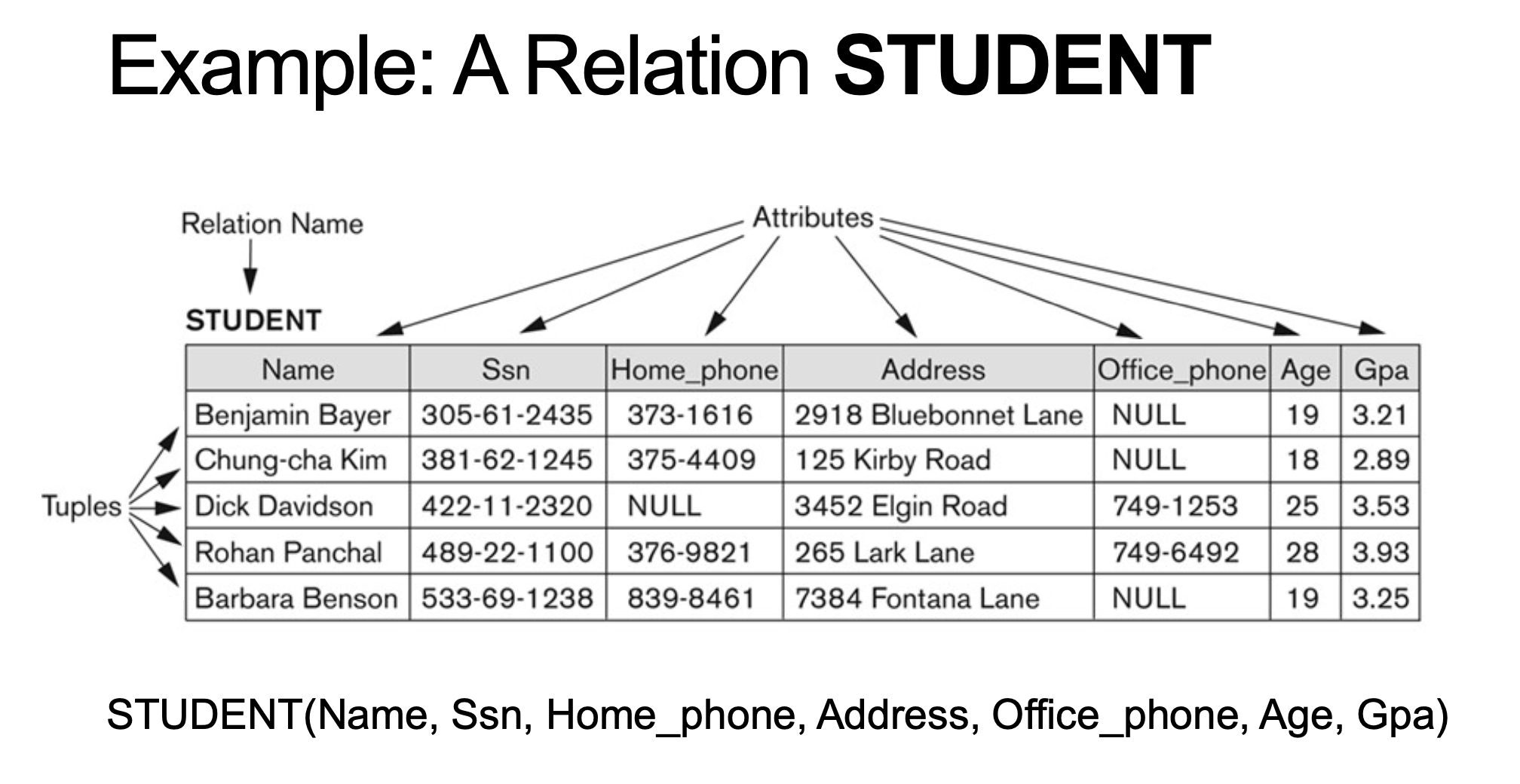
2-2-2. Tuple
What's a tuple ?
- An ordered set of values : enclosed in angled brackets '< ... >'
relation schema를 따르고 있는 instance이자, 값들의 ordered set이다. '<...>'으로 표기한다.- Each value of the tuple is derived from an appropriate domain.
Tuple의 각 값들은 적절한 domain으로부터 파생되었다.
- A tuple (row) in the CUSTOMER relation (table) looks like:
• <632895, “홍길동”, “대구 북구 대학로 80 IT-5 41566", “053-950-6372">
• Called a 4-tuple: Why?
4개의 attribute(relation degree)를 가지고 있어서 4-tuple이라고 부른다
- A relation (table) is a set of such tuples (rows).
relation은 그러한 tuple들의 set이다.
2-2-3. Domain
A domain (say, D) : a set of atomic (indivisible) values.
- Has a logical definition or name
E.g., "Korea_cell_phone_numbers"는 일반적으로 11 digit phone numbers의 집합으로 나타낸다. 010으로 시작하면서 한국에서 유효하다.
- Has a data type or a data format defined for it
EX) "Korea_cell_phone_numbers"는 (010)-dddd-dddd 형식을 따른다.
EX) Dates는 year, month, date에 대해 yyyy-mm-dd, or dd/mm/yyyy 등 여러 형식을 가진다.
The attribute (Column) name plays a role for a domain in a relation (table).
- Attribute (Column) name은 관계에서 Domain을 알려주는 역할을 한다.
- Attribute에 해당하는 data elements의 의미를 해석하는데 사용된다. 따라서 구체적인 attribute name을 지정해야 한다.
E.g., Domain Date는 "Invoice-date" or "Payment-date"와 같은 서로 다른 의미를 정의하는데 사용될 수 있다.
2-2-4. State
The relation state: a subset of the Cartesian product1 of the domains of its attributes
해당 attributes의 도메인의 Cartesian product의 부분집합.
즉, Attribute들의 domain을 만족하는 모든 value들의 집합은 relation에 저장이 가능한데 이를 realation state라고 한다.
각 도메인은 attribute로 저장할 수 있는 모든 가능한 값들의 set을 포함하고 있다.
- EX1) The attribute, “Cust-name”: defined over the domain of character strings of maximum length, say 30.
• dom(Cust-name):varchar(30)
• The role played by these strings in the CUSTOMER relation is that of the name of a customer. - EX2) The attribute, “Cust-id”: defined over the domain of 4-byte integers
• dom(Cust-id):int
• The role played by these numbers in the CUSTOMER relation is that of the id of a customer.
2-2-5. Summary

2-2-6. Example
attribute가 2개이기 때문에 2-tuple

2-2-7. Definition Summary
2-3. "Characteristics" of Relations
Ordering of tuples in a relations
- Tuples는 정렬의 대상이 아니다. 그들은 단지 tabular form 으로 나타내진다.
- Tuple의 순서는 relation definitio의 부분이 아니다. 관계는 논리적/추상적 수준에서 facts를 표현하려고 하기 때문이다.
Considered to be identical as the one before
위의 Relation과 비교했을 때 이전과 동일한 것으로 간주된다.

2-3-1. Ordering of attributes in a relation schema R (and of values within each tuple)
- The attributes in R(A1, A2, ... , An)
관계 스키마 R 내의 속성들은 특정한 순서대로 나열된다.
예를 들어, R(A1, A2, ..., An)는 속성 A1, A2 등이 특정 순서로 나열된 것을 의미한다. - The values in a tuple ti, or <v1, v2, ..., vn>
각 튜플 내에서 값들도 순서가 있다.
만약 튜플 ti가 있다면, 그 안에는 v1, v2, ..., vn과 같이 순서대로 나열된 값이 포함되어 있다.
Considered to be ordered.
관계 스키마의 속성과 각 튜플 내의 값들은 특정한 순서를 가지고 있어야 한ek.
- By the definition of a relation, an n-tuple is an ordered list of n values
(or a sort of tensor).
관계의 정의에 따라, n-튜플은 n개의 값들로 이루어진 순서대로 나열된 목록이라는 것을 의미한다.
이것은 어떤 관계를 표현하는 방식 중 하나로, 순서가 중요하다.C.f. However, there exists no order in a “more general” alternative definition, including the name and the value for each of the attributes as a pair

더 일반적인 대체 정의에서는 속성의 이름과 값이 각각 쌍(pair)으로 표현되며, 이 정의에는 순서가 없다는 것을 비교하고 있다.
Identical, when the order of attributes and values is not part of relation definition.
위의 Tuple은 동일하다. 이는 relation의 정의에 따라 Ordering이 포함되지 않기 때문이다.
The tuples are "self-describing", why ?
Name과 Value가 함께 존재하기 때문에 "Self-describing"이라고 한다.
관계에서 속성과 값들의 순서가 중요하지 않고, 속성의 이름과 값을 쌍으로 가지고 있어서 각 튜플이 자체적으로 설명 가능하다는 것을 의미한다.
즉, 튜플의 내용을 이해하려면 순서를 고려할 필요가 없으며, 각 속성과 값이 이름과 함께 묶여 있어 명확하게 이해할 수 있다는 것을 나타낸다.
2-3-2. Values in a tuple
All values are considered atomic.
- 모든 값은 원자적으로 간주된다.
관계형 모델에서 "원자적"이란, 각 튜플의 값이 더 이상 분해되거나 나뉘지 않는다는 것을 의미한다.
각 값은 나뉠 수 없는 단일 단위로 취급- 복합 및 다중 값 속성은 허용되지 않는다.
나중에 배울 first normal form assumption에 기반을 둔 flat relational model이라고 부른다.
Composite attributes -> simple attributes
Multi-valued attributes -> separate relations- 각 Tuple 내의 각 값은 해당 열의 속성 도메인에서 가져와야 한다.
특정 열에 속한 값은 그 열의 정의된 도메인 내에서 유효한 값이어야 한다.- Tuple t = <v1, v2, ..., vn>이 R(A1, A2, ..., An)의 관계 스키마 R 내의 관계 상태 r의 튜플(행)이라면, 각 vi는 dom(Ai)의 도메인에서 가져온 값이어야 한다.
특정 관계 스키마 R의 관계 상태 r에서 튜플 t가 특정 속성 Ai의 도메인 dom(Ai)에서 가져온 값으로 이루어져 있어야 한다.
2-3-3. NULL values in certain tuples
- Unknown (e.g., Don't know)
- 어떤 값이나 정보가 알려지지 않았거나 알 수 없는 경우에 사용 (어떤 개인의 주소를 모르는 경우)
- Not availbale (e,g., Don't have a home phone number)
- 데이터가 없는 경우에도 사용 (어떤 개인이 집 전화번호를 가지고 있지 않는 경우)
- Inapplicable (e.g., Female vs male for body check)
- 특정 Context에서 어떤 값이 적용되지 않는 경우에도 사용, '성별' 정보를 기록하는 경우 일부 상황에서는 성별이 적용되지 않을 수 있다.
EX) '홍길동' -> 'gender', Fax_Number', "State'
Gender = Unknown
Fax_Number = Not available
State = Inapplicable
2-3-4. Notation
- R.A : R이라는 Relation(관계)에서 Attribute(속성) A의 이름을 가리킨다.
- EX) "STUDENT.Name"은 "STUDENT" 관계에서 "Name" 속성을 나타낸다.
- 그러나 특정 관계 내에서 모든 속성 이름은 서로 달라야 한다. 이것은 관계형 데이터베이스에서 모든 속성이 서로 중복되지 않는 고유한 이름을 가져야 함을 의미
- 튜플 t의 구성 요소 값들을 t[Ai] 또는 t.Ai로 표기한다.
- 이것은 튜플 t의 Ai 속성의 값인 vi를 나타낸다.
- 비슷하게, t[Au, Av, ... , Aw] 또는 t.(Au, Av, ... , Aw)는 t 내에서 속성 Au, Av, ... , Aw의 값들을 포함하는 하위 튜플을 나타낸다.
- 이 하위 튜플은 t의 일부분으로 Au, Av, ... , Aw 속성에 해당하는 값들을 포함한다.
t[Name] = Benjamin Bayer
t[Ssn, Gpa, Age] = <305-61-2435, 3.21, 19>

3. RELATIONAL MODEL CONSTRAINTS AND RELATIONAL DATABASE SCHEMAS
3-1. Constraints (제약 조건)
Database의 일관성, 무결성을 유지하기 위해 사용되는 조건으로 DB에 저장되는 값들에 대한 filter와 비슷한 역할을 수행
1) 어떤 값들이 허용되는가 ?
2) 어떤 값들이 DB에 들어올 수 없는가 ?
3 main categories
- Inherent or implicit constraints (내재 또는 암시적인 제약 조건)
- 데이터 모델 자체를 기반으로 하는 제약 조건
- 예를 들어, 관계형 모델은 어떤 속성에 대한 값으로 목록을 허용하지 않는 등 데이터 모델이 자체적으로 정한 규칙에 따라 값이 허용되거나 제한된다.
- Schema-based or explicit constraints (스키마 기반 또는 명시적인 제약 조건)
- 데이터 모델 스키마 내에서 직접 표현되는 제약 조건
- 예를 들어, 고유한(unique) 제약 조건이나 엔터티-관계(ER) 모델의 전체 또는 일부 참여 및 최소/최대 기수 비율과 같은 제약 조건이 여기에 해당된다.
- Application-based or semantic constraints (or business rules) (애플리케이션 기반 또는 의미적인 제약 조건)
- 이러한 제약 조건은 데이터 모델로 기술할 수 없으며 애플리케이션 프로그램에 의해 강제되어야 한다.
- 예를 들어, 만약 나이(age)가 65보다 크고 근무 시간(hours)가 40보다 크면 총 급여(total wages)는 두 배가 되어야 한다는 비즈니스 규칙이 이 범주에 속한다.
3-2. Category 2: Relational Integrity Constraints
Constraints are conditions that must hold on “all” valid relation states. (NO exception)
제약 조건은 관계형 데이터 모델에서 모든 유효한 관계 상태에서 성립해야 하는 조건이다.
제약조건은 데이터베이스의 무결성을 유지하고 데이터의 정확성을 보장하는 데 중요
Main types of constraints in the relational data model
- Key constraints (키 제약조건):
- Unique constraints (유일 제약조건)
- 특정 속성(또는 여러 속성의 조합)의 값은 모든 튜플(행)에서 고유해야 한다.
- Key attribute를 가지는 tuple들은 절대로 중복될 수 없다. (key value의 중복 불가)
- 즉, 중복된 값을 가질 수 없다. 이는 특정 속성을 식별자(키)로 사용할 때 주로 적용된다.
- Entity integrity constraints (엔티티 무결성 제약조건)
- 관계의 기본 키(primary key) 속성에 관련이 있다.
- 기본 키 속성은 모든 튜플에서 고유한 값을 가져야 하며, NULL 값을 허용하지 않는다.
- 즉, 모든 행은 식별자를 가져야 하며 이 식별자는 NULL이 아니어야 합니다.
- Referential integrity constraints (참조 무결성 제약조건)
- 이 제약조건은 관계 사이의 관계를 정의하며, 한 테이블(관계)의 외래 키(foreign key) 속성이 다른 테이블의 기본 키와 연결될 때 적용된다.
- 참조 무결성 제약조건은 다음을 보장한다.
- 외래 키의 값은 참조하는 테이블의 기본 키 값과 일치하거나 NULL이어야 한다.
- 참조하는 Tuple이 존재해야 한다. (FK가 참조하는 PK와 상관없는 값을 가지면 안 된다.)
- 부모 테이블의 값이 변경되거나 삭제되면 자식 테이블에서도 해당 값을 수정 또는 삭제해야 한다.
- Domain Constraints (도메인 제약조건)
- 도메인 제약조건은 각 속성의 값이 해당 속성의 도메인(허용되는 값의 범위 또는 타입)에서 와야 한다는 제약을 나타낸다.
- 즉, 각 속성에 저장되는 값은 그 속성의 정의된 유효한 값의 범위 내에 있어야 한다.
- 값이 NULL이 될 수 있는 경우, 이도 도메인 제약 조건의 일부이다.
3-2-1. Key Constraints
By definition, all tuples in a relation must be distinct.
• Because a relation is a “set” of tuples, meaning no same element.
모든 관계의 튜플은 서로 달라야 한다. (Unique)
관계형 데이터베이스 모델에서, 모든 관계(relation) 내의 튜플(tuples)은 서로 고유해야 한다.
즉, 중복된 튜플이 포함되어서는 안 된다.
이것은 관계가 집합(set)의 성질을 가지고 있다는 것을 의미한다.
Superkey of a relation R?
- Superkey는 관계 R 내의 어떤 속성(attribute)들의 부분 집합인데, 다음 조건을 충족하는 경우이다.
- uniqueness property : 어떤 유효한 관계 상태 r(R) 내에서 두 개의 튜플이 동일한 superkey 값을 가지지 않아야 한다.
- 즉, superkey는 관계 상태 내의 tuple을 고유하게 식별할 수 있어야 한다.
- 예를 들어, SK는 {Student ID, Student Name}와 같이 정의될 수 있으며, 이것은 동일한 Student ID 및 Student Name 값을 가지는 두 개의 tuple이 관계 상태 내에서 없어야 함을 의미한다.
relation R의 key
- A “minimal” superkey (최소 superkey)
- 어떤 superkey K에서 하나의 속성을 제거하면 더 이상 superkey가 아니게 되는 경우를 말한다.
- 해당 relation의 tuple들을 unique하게 식별하지 못하게 된다.
- Superkey만으로 모든 tuple을 unique하게 식별할 수 있다.
superkey를 구성하는 어떤 attribute는 다른 tuple의 attribute와 중복된 값을 가질 수 있다.
하지만 key는 다른 tuple의 attribute와의 중복된 값을 허용하지 않는다.예를 들어, 고객 데이터를 담고 있는 관계에서 Superkey는 {고객 ID, 이름}일 수 있으며, 이는 동일한 이름을 가지는 고객이 여러 명일 수 있기 때문에 중복 값을 가질 수 있다.
그러나 Key는 {고객 ID}일 수 있으며, 이것은 각 고객을 고유하게 식별하며 중복이 없어야 합니다.
[Question] Is a superkey a key?
NO !
superkey에 unique하지 않은 attribute가 포함되어 있을 수도 있다.
Example
Consider the CAR relation schema
CAR (State, Reg#, VIN*, Make, Model, Year)
1. [Q] CAR has two superkeys. What are they?
Skey1 = {State, Reg#}
예를 들어, "AZ" 주(State)와 "6280" 등록 번호(Reg#)를 가진 자동차는 SKey1을 사용하여 고유하게 식별할 수 있다.
Skey2 = {VIN}
예를 들어, "VW12345" VIN을 가진 자동차는 SKey2를 사용하여 고유하게 식별할 수 있다.
2. [Q] Is {VIN, Make} a key, a superkey, or both?
Superkey, 이것은 자동차를 식별하는데 사용할 수 있는 속성 조합 중 하나이지만 최소한의 속성을 포함하지 않으므로 key는 아니다.
3. [Q] Is {State, Reg#} a key, a superkey, or both?
key, 최소한의 속성만을 포함하고, 관계에서 중복을 허용하지 않는 유일한 식별자로 사용할 수 있다.
*vin = Vehicle Identification Number
In general,
- Any key is a superkey (but NOT vice versa).
- 어떤 키(key)는 항상 수퍼키(superkey)이지만 그 역은 성립하지 않습니다:
- 키(key)는 튜플을 고유하게 식별하기 위한 속성의 집합으로, 튜플 간 중복이 없어야 한다.
- superkey는 튜플을 식별할 수 있는 속성의 집합이지만, 중복이 허용될 수 있다.
- 따라서 모든 key는 동시에 superkey이지만, 모든 superkey가 key는 아니다.
- Any set of attributes that includes a key is a superkey
- 키를 포함하는 어떤 속성 집합은 항상 superkey이다.
- 어떤 속성 집합이 키를 포함한다면, 그 속성 집합은 튜플을 고유하게 식별할 수 있는 superkey이다.
- 이것은 키가 포함된 속성 집합이 관계의 모든 튜플을 식별할 수 있음을 의미한다.
- A minimal superkey is also a key.
- Minimal Superkey는 항상 key가 된다.
- 최소한의 superkey는 key인데, 이것은 튜플을 식별하는 데 필요한 최소한의 속성을 가지며 중복이 없어야 한다.
- a relation schema may have many keys, each of which is called a candidate key and one of them is “arbitrarily” chosen as the primary key.
- 관계 스키마는 여러 개의 키를 가질 수 있으며, 이 중 하나는 주키(Primary Key)로 선택될 수 있다.
- 주키는 튜플을 식별하는 데 사용되며 관계 스키마에서 기본적으로 선택된 주요한 키가 된다.
- 다른 키들은 후보 키(Candidate Key)라고도 불린다.
- 후보 키 (Candidate Key): 후보 키는 테이블(관계)에서 튜플(행)을 고유하게 식별할 수 있는 속성(또는 속성의 조합)이다.
- 기본 키(primary key)로 선택되지 않은 후보 키를 의미.
- 데이터베이스 설계 시 여러 후보 키가 식별될 수 있고, 그 중 하나가 기본 키로 선택된다.
KEY attribute + Attribute => Superkey
The primary key value is used to
- Uniquely identify each tuple in a relation: Providing the tuple identity.
- 관계 내의 각 튜플을 고유하게 식별: 기본 키는 관계(테이블) 내의 각 튜플(행)을 고유하게 식별하기 위한 값으로 사용된다.
- 이것은 동일한 기본 키 값을 가지는 튜플이 관계 내에 중복되지 않도록 보장한다.
- Reference the tuple from another tuple; specified as a foreign key in the referencing relation
- 다른 튜플에서 특정 튜플을 참조: 기본 키는 종종 다른 관계(테이블)에서 참조할 때 사용된다.
- 한 관계의 기본 키가 다른 관계에서 외래 키(foreign key)로 사용되면 두 관계 간의 관계가 설정되며 데이터 무결성을 유지하기 위해 중요한 역할을 한다.
General rule about key:
- Choose as primary key the smallest of the candidate keys in terms of
size─ the number of attributes.- 속성 수(속성의 개수) 면에서 가장 작은 후보 키를 기본 키로 선택: 일반적으로 후보 키 중에서 가장 속성 수가 적은 후보 키를 기본 키로 선택하는 것이 좋다.
- 이는 저장 및 인덱싱 요구 사항을 최소화하는 데 도움이 됩니다.
- 그러나 기본 키 선택은 디자이너의 판단에 따라 달라질 수 있으며, 특정 상황에서는 데이터베이스와 애플리케이션의 요구 사항에 따라 다른 후보 키가 기본 키로 선택될 수 있음을 염두할 필요가 있다.
4. RELATIONAL MODEL CONSTRAINTS AND RELATIONAL DATABASE SCHEMAS
4-1. Relational Database Schema
What is a relational database schema then?
하나의 데이터베이스 스키마는 하나의 데이터베이스에 속하는 여러 관계(table) 스키마의 설계를 나타낸다.
이 스키마는 데이터베이스 내의 모든 관계 스키마와 이러한 관계 스키마 간의 데이터 무결성을 유지하기 위한 규칙을 포함한다.
- A set of S of relation schemas that belong to the same database. (동일한 DB에 있는 relation 스키마 S의 set)
- S: the name of the whole database schema (전체 데이터 베이스 스키마의 이름)
- S = {R1, ..., Rn} and a set of Integrity Constraints (ICs)
- S는 전체 데이터베이스 스키마의 이름을 나타내며, 데이터베이스에 포함된 모든 관계 스키마와 무결성 제약 조건의 집합을 포함한다.
- IC: constraints that must be preserved for consistency/integrity in database
- DB의 일관성과 무결성을 보존하기 위해 지켜져야 하는 제약조건
- Key, Not-Null, domain, and two other types
- R1, R2, ..., Rn은 개별 관계 스키마의 이름을 나타내며 ICs는 무결성 제약 조건(예: 키 제약, Not-Null 제약, 도메인 제약)의 집합
- R1, R2, ... , Rn are the names of the individual relation schemas within the database S.
- R1, R2, ..., Rn은 데이터베이스 스키마 내에서 개별 관계(테이블) 스키마의 이름을 나타낸다.
- 각 관계 스키마는 특정 데이터 유형을 나타내며 데이터베이스 내의 데이터를 저장.
4-2. A Refined ER Schema for the COMPANY Database
COMPANY = {EMPLOYEE, DEPARTMENT, DEPT_LOCATIONS, PROJECT, WORKS_ON, DEPENDENT}
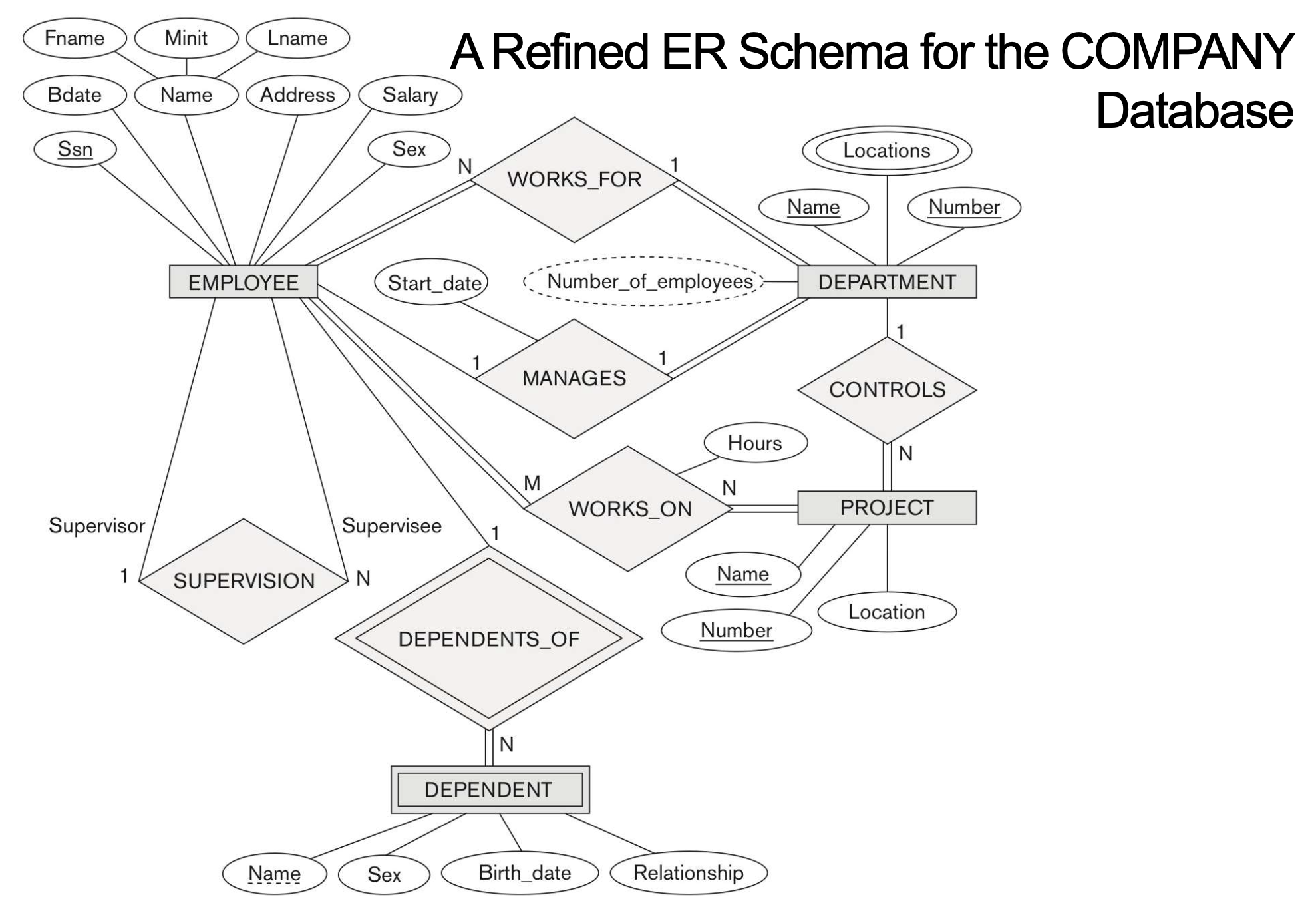
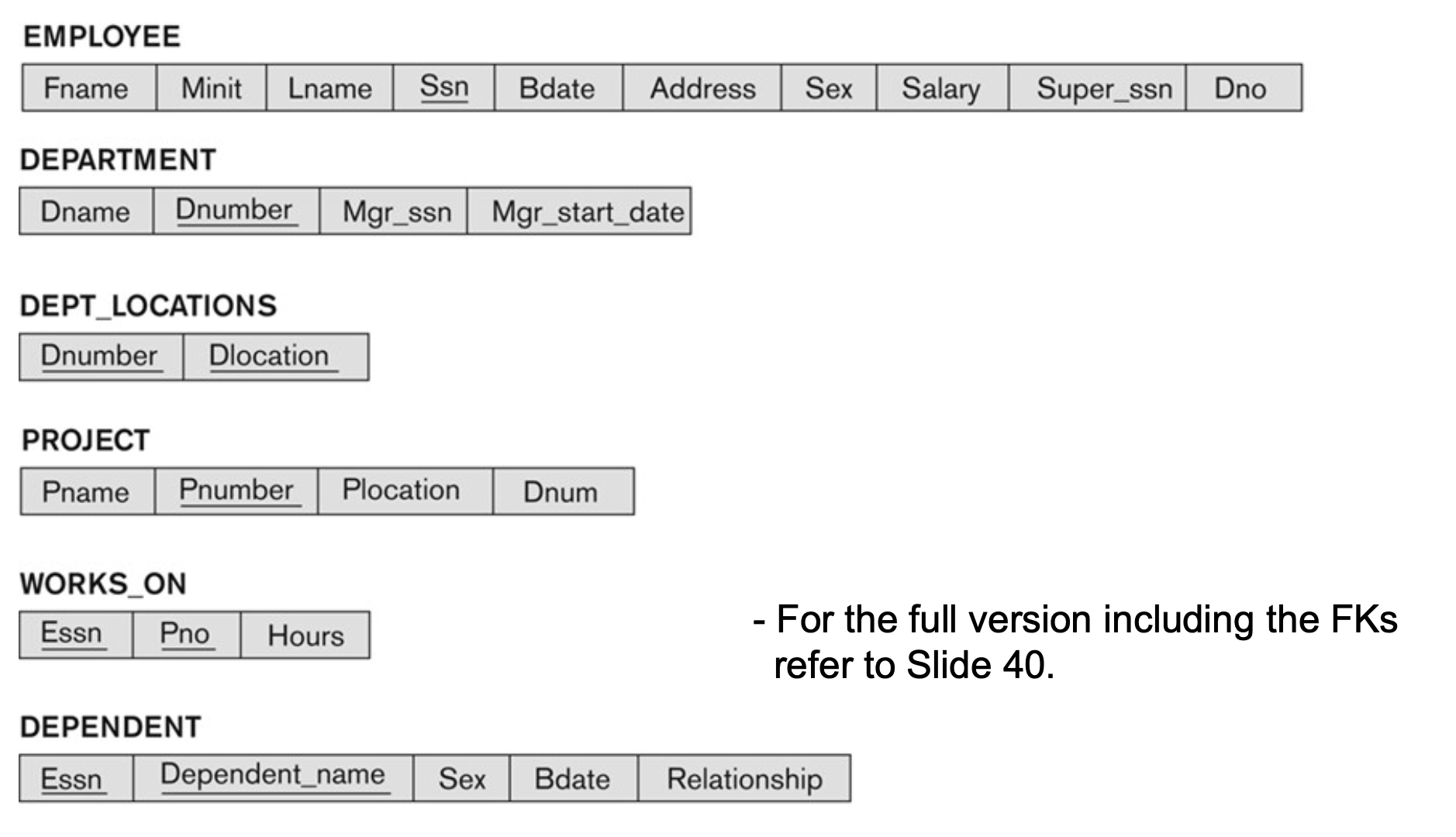
4-3. Schema Diagram for the COMPANY Relational Database Schema
4-4. Relational Database State
공식적으로 관계형 데이터베이스 스키마 S의 관계형 데이터베이스 상태 DB는 다음과 같이 정의된다.
- A set of relation states, DB = {r1, r2, ..., rm} such that
- 각 ri는 Ri의 상태로 정의. 이때, Ri는 스키마 S 내의 하나의 관계 스키마(테이블)를 나타sosek.
- ri 관계 상태는 IC(무결성 제약 조건)에서 지정된 무결성 제약 조건을 충족한다.
- A relational database state is sometimes called a relational database snapshot (or instance).
- 그러나 "Instance"라는 용어는 단일 튜플에도 적용되므로 사용하지 않는다.
- snapshot을 찍는 것처럼 특정 시점의 상태를 보여주기 때문에 이와 같이 칭한다.
- 그러나 "Instance"라는 용어는 단일 튜플에도 적용되므로 사용하지 않는다.
- A database state that doesn’t meet the constraints is said invalid.
- 무결성 제약 조건을 충족하지 않는 데이터베이스 상태는 "무효(invalid)"로 표현된다.
4-5. Populated Database State
- 각 관계(테이블)은 현재 관계 상태에 여러 개의 튜플(행)을 가지고 있다.
- 관계형 데이터베이스 상태는 모든 개별 관계 상태의 결합이다.
- 데이터베이스가 변경될 때(즉, 튜플이 수정, 삽입, 삭제될 때) 새로운 state가 생성된다.
- 관계형 데이터베이스를 변경하는 데 사용되는 기본 operation
- INSERT: 관계(테이블)에 새로운 튜플을 추가
- DELETE: 관계(테이블)에서 기존의 튜플을 삭제
- MODIFY 또는 UPDATE: 기존 튜플의 속성을 수정
SQL의 DML(데이터 조작 언어) 문은 이러한 작업을 지원한다.
4-6. A Possible DB State for COMPANY
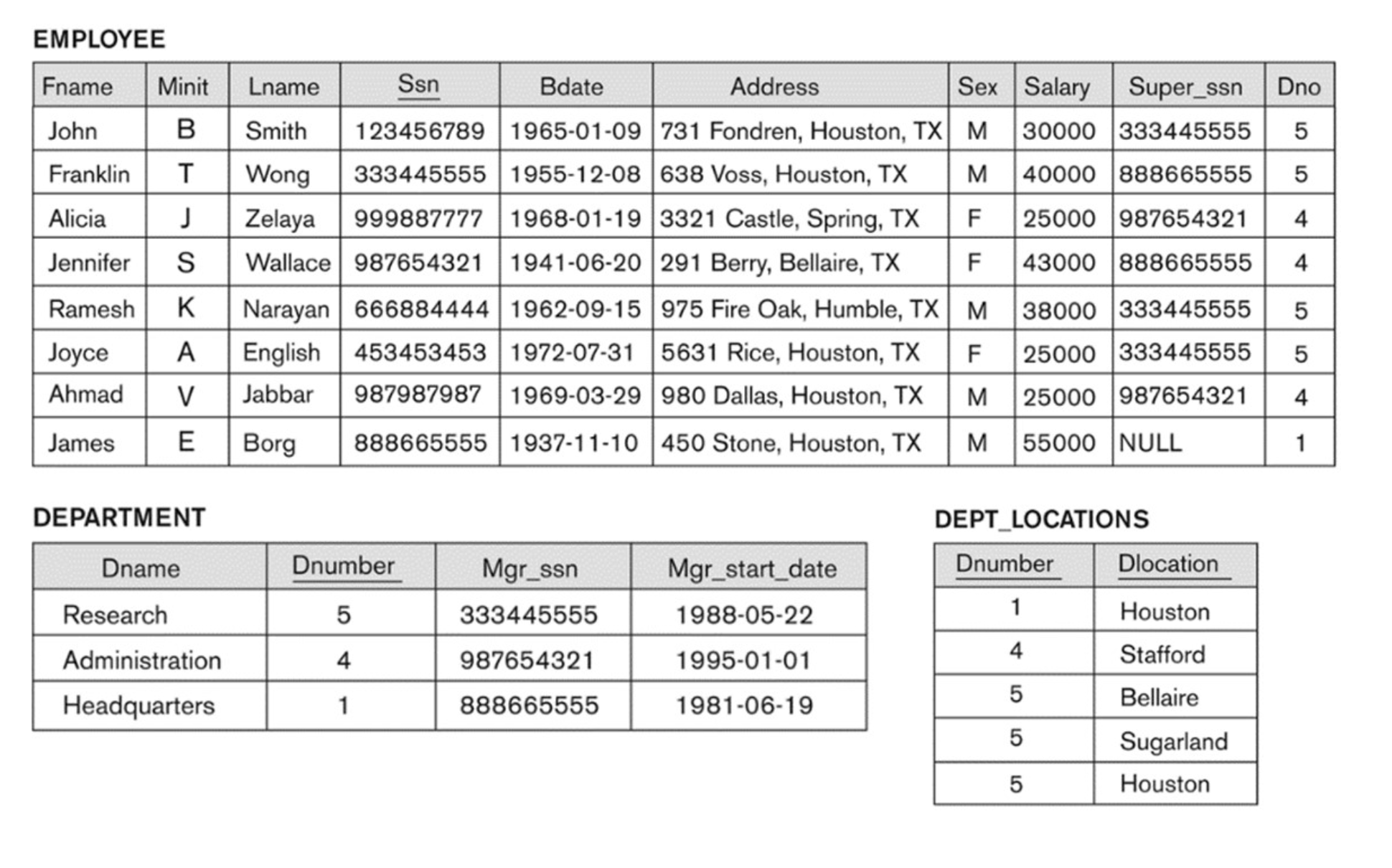
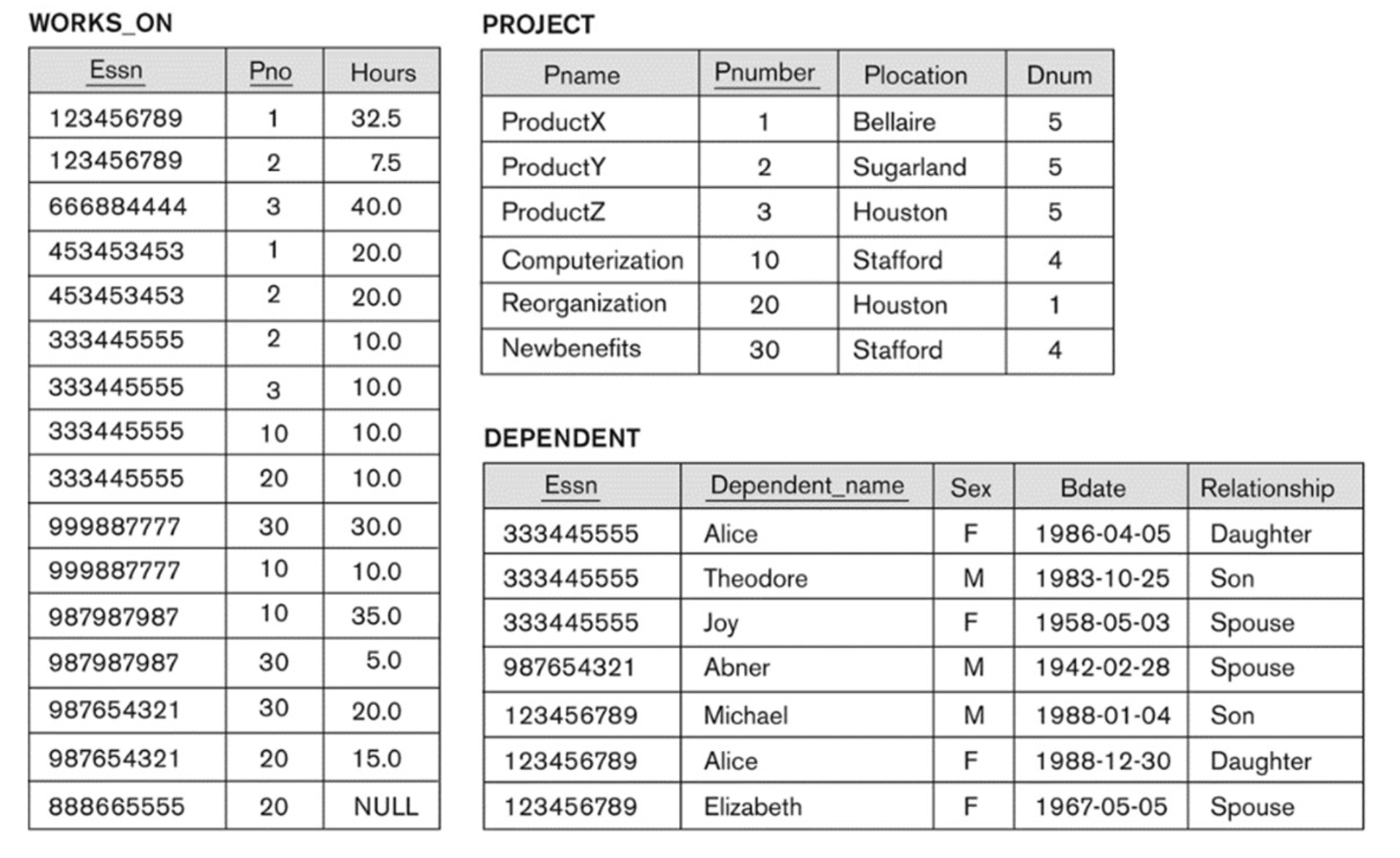
4-7. Entity Integrity Constraint
개체 무결성 제약조건
Database schema에 존재하는 각 relation schema R의 PK는 어떠한 tuple에서도 NULL값을 가질 수 없다.
-> Unique를 만족하기 위해
- No primary key value can be NULL
- t[PK] != null for any tuple t in r(R)
- If PK includes several attributes, NULL is NOT allowed in any of
them.
- PK가 여러 속성을 포함하는 경우, 그 중 어느 하나에도 NULL이 허용되지 않는다. - Why ?
- 주 키 값이 개별 튜플을 식별하는 데 사용되기 때문이다. 주 키 값이 NULL이면 어떻게 될 지 생각해보자.
- 그러나 주 키가 아닌 속성에 대해서는 NULL 값을 허용하거나 허용하지 않을 수 있음에 유의해야 한다.
4-8. Referential Integrity Constraint
참조 무결성 제약조건
두 개 이상의 관계(table)와 관련된 제약조건
- Used to maintain the “consistency” among tuples in the two relations.
- 제약 조건은 두 관계(테이블) 간의 튜플 간 일관성을 유지하는 데 사용
- 예를 들어, "EMPLOYEE"의 Dno(Department Number)는 각 직원이 근무하는 부서 번호를 나타낸다.
-> "EMPLOYEE" 튜플의 각각의 Dno 값은 "DEPARTMENT" 관계(테이블) 내의 어떤 튜플의 Dnumber 값과 일치해야 한다.
- 제약 조건은 두 관계(테이블) 간의 튜플 간 일관성을 유지하는 데 사용
- Used to specify a relationship among tuples in two relations
- 이러한 제약 조건은 두 관계(테이블) 내의 튜플 간의 관계를 지정하는 데 사용
- 참조 관계(Referencing Relation): 관계형 데이터베이스에서 이 관계(테이블)에 대한 특정 속성이 참조 관계를 설정하는 관계다. 이 관계의 튜플이 다른 관계의 튜플을 참조한다. EX)EMPLOYEE
- 참조된 관계(Referenced Relation): 참조 관계(Referencing Relation)에서 참조되는 관계(테이블)다. 다른 관계의 튜플을 참조하는 관계다. EX)DEPARTMENT
참조 관계(Referencing relation) R1에 존재하는 tuples은 FK(=foreign key attribute)를 가지고 이러한 외래 키 attribute는 참조된 관계(Referenced relation) R2의 PK를 참조한다.
- A tuple t1 in R1 is said to reference a tuple t2 in R2, if t1[FK] = t2 [PK]
- 참조 관계 R1의 튜플 t1이 참조 관계 R2의 튜플 t2를 참조한다고 할 때, 이는 t1[FK] = t2[PK]라는 조건을 만족하는 경우
- A referential integrity constraint can be displayed in a relational database schema as a directed arc:
- 참조 무결성 제약 조건은 관계형 데이터베이스 스키마에서 화살표를 사용하여 나타낼 수 있다. 이 화살표는 다음과 같이 표현된다.
- From R1.FK to R2.PK (e.g., R1: EMPLOYEE, R2: DEPARTMENT, FK: Dno, PK: Dnumber)
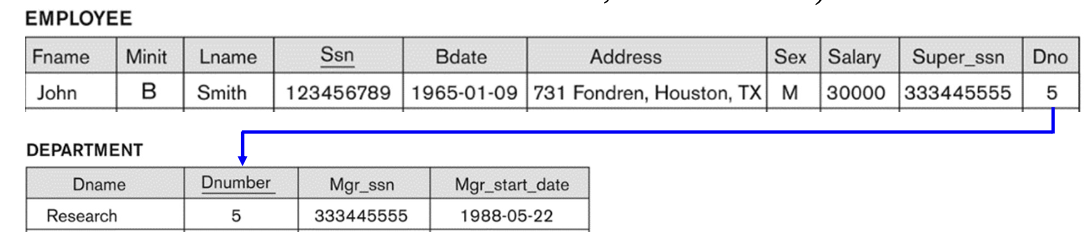
Foreign Key (Referential Integrity)
Referencing relation R1에 있는 FK는 두 가지 값을 가질 수 있다.
- t1[FK] = t2[PK]
- FK의 값은 참조 관계 R2의 기본 키(PK) 속성 중 하나의 기존 기본 키 값을 나타낸다.
- 즉, 참조된 관계 R2의 기본 키 값 중 하나를 참조하고 있다.
- referenced relation R2에 있는 기존의 primary key value (PK에 해당하는 값이 존재해야 함)
- a null
- If FK is null (as seen in case (2)), then the FK in R1 should NOT be a part of its own primary key.
- 만약 FK가 null인 경우 FK는 자체의 기본 키 일부로 포함되어서는 안 된다.
- 즉, R1에 있는 FK는 PK에 속해서는 안 된다.
- 그렇지 않으면, 이것은 엔터티 무결성 제약 조건을 위반할 수 있다.
4-9. Example: Referential Integrity Constraints for COMPANY
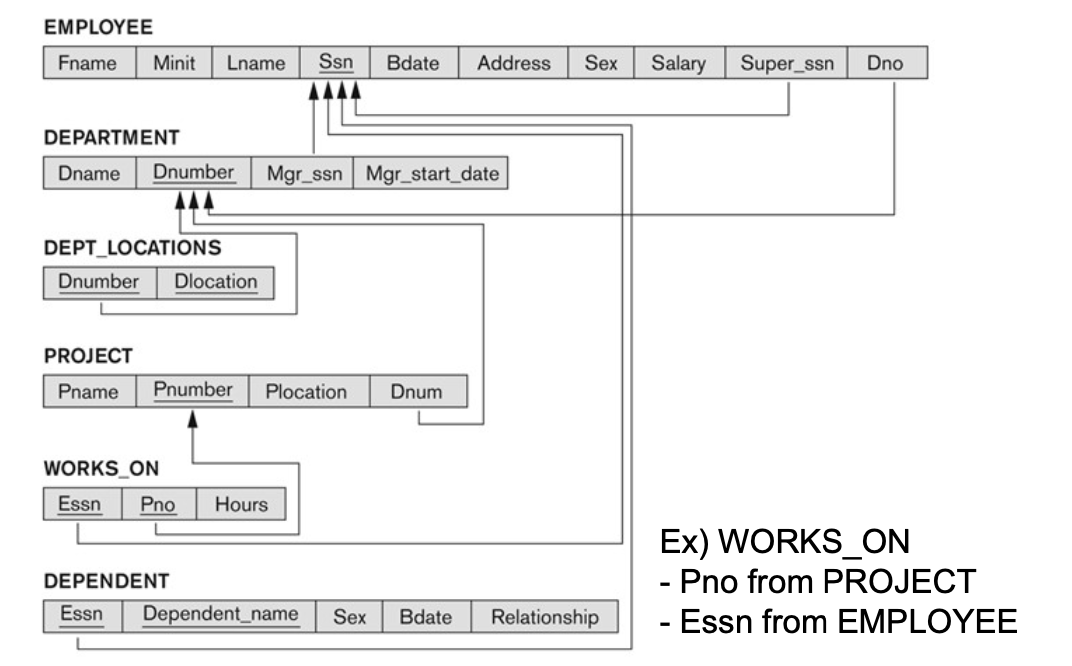
4-10. Other Types of Constraints
Semantic Integrity Constraints (의미 무결성 제약 조건)
- Based application semantics
- Data model로 표현될 수 없다.
- EX) "한 직원이 일하는 모든 프로젝트의 주당 최대 근무 시간은 52시간으로 제한됩니다." 이러한 종류의 제약 조건은 데이터 모델로 표현하기 어렵다.
- using a general-purpose constraint specification language (제약 조건은 응용 프로그램 내에서 명시적으로 지정될 수 있다.)
- CREATE TRIGGER 및 CREATE ASSERTION 문과 같은 SQL-99의 트리거 및 확인을 위한 일반 목적의 제약 조건 명세 언어를 사용하여 강제할 수 있다.
- CREATE TABLE 문을 사용하여 다양한 제약 조건을 선언할 수 있다.
- (i) keys, (ii) candidate keys (unique constraint), (iii)
NOT NULL, (iv) entity integrity, (v) foreign keys, (vi) referential integrity, etc.
5. UPDATE OPERATIONS AND DEALING WITH CONSTRAINT VIOLATIONS
5-1. “Update” Operations on Relations
(1) INSERT, (2)DELETE, or (3) MODIFY(UPDATE) a tuple.
- 이러한 작업이 적용될 때, 관계형 데이터베이스의 integrity constraints(무결성 제약 조건)을 위반해서는 안 된다.
즉, 데이터베이스의 일관성과 무결성을 유지하기 위해 업데이트 작업은 주의 깊게 처리되어야 한다.- 여러 개의 업데이트 작업을 그룹화되어 실행될 수 있다.
- Updates는 자동적으로 다른 update를 유도할 수도 있다.
- integrity constraints를 유지하기 위해서 필요할 수 있다.
- 예를 들어, 새 직원이 추가되면 직원의 총 수가 하나 증가하게 된다. 이러한 경우 데이터베이스의 일관성을 유지하기 위해 업데이트가 자동으로 전파될 수 있다.
In case of integrity violation, roughly 4 actions can be taken
- Cancel the operation, causing the violation.
- 무결성 위반을 발생시키는 연산을 취소합니다.
- RESTRICT (실행 취소) 또는 REJECT 옵션
- 많은 데이터베이스 관리 시스템(DBMS)에서 사용중.
- Perform the operation but inform the user of the violation.
- 연산 수행 및 사용자에게 위반 알림: 연산을 수행하지만 사용자에게 무결성 위반을 알린다.
- consistency(일관성)가 깨지기 때문에 대부분의 DBMS가 이렇게 처리하지 않는다.
- Trigger additional updates so the violation is corrected.
- 추가 업데이트 트리거: 무결성 위반을 수정하기 위해 추가 업데이트를 트리거
- CASCADE (갱신이 전파됨), SET NULL 또는 SET DEFAULT 옵션: 참조된 관계에서 참조 관계로 데이터가 전파되거나, NULL로 설정되거나, 기본값으로 설정될 수 있다.
- Execute a user-specified error-correction routine.
- 사용자 지정 오류 수정 루틴 실행: 사용자가 정의한 오류 수정 루틴을 실행한다.
- 이 경우 프로그램을 작성하여 오류 수정 작업을 수행해야 한다.
5-2. Possible Violation Cases for INSERT Operation

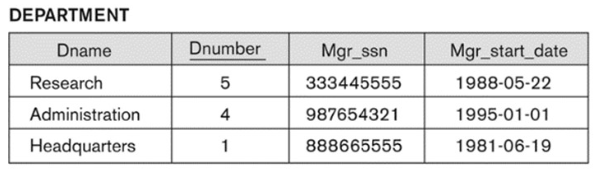
- Insert into EMPLOYEE <‘Cecillia’, ‘F’, ‘Kolonsky’, NULL, ‘1960-04-05’, ‘6357 Windy Lane, Katy, TX’, ‘F’, 28000, NULL, 4>
- Any problem? If any, which constraint is violated?
- PK인 Ssn에 NULL값을 insert하려고 하여, Entity integrity constraint를 위반
- Insert <‘Alicia’, ‘J’, ‘Zelaya’, ‘999887777’, ‘1960-04-05’, ‘6357 Windy Lane, Katy, TX’, ‘F’, 28000, ‘987654321’, 4> into EMPLOYEE.
- Problem?
- PK인 Ssn이 중복되어 Key constraint를 위반
- Insert <‘Cecilia’, ‘F’, ‘Kolonsky’, ‘677678989’, ‘1960-04-05’, ‘6357 Wind, Katy, TX’, F, 28000, ‘987654321’, 7> into EMPLOYEE.
- Problem?
- EMPLOYEE의 FK인 Dno에 존재하지 않는 DEPARTMENT의 PK를 insert하려고 하여, referential integrity constraint가 위반
- domain constraints가 위반되지 않는 한 데이터 삽입이 허용될 수 있다.
5-3. Possible Violation Cases for DELETE Operation
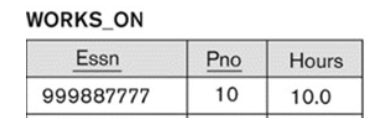
- Delete the WORKS_ON tuple with Essn = ‘999887777’ and Pno = 10.
- Delete the EMPLOYEE tuple with Ssn = ‘999887777’.
- 2 options
- reject due to many tuples referencing the tuple
- 많은 Tuples이 해당 tuple을 referencing하고 있이게 operation reject
- deleting it and then cascading the deletion to WORKS_ON.
- 해당 tuple을 삭제하고 WORKS_ON으로 deletion을 전파
- reject due to many tuples referencing the tuple
- 2 options
- Delete the EMPLOYEE tuple with Ssn = ‘333445555’.
- Worst case as many tuples are affected
- 위에 기재한 사진을 볼 것
5-4. Possible Violation Cases for DELETE Operation: Summary
DELETE는 오직 referential integrity constraint(참조 무결성 제약조건)만을 위반할 수 있다.
- 삭제될 tuple은 FK로 database에 있는 다른 tuple을 참조하고 있기 때문이다.
- 이는 삭제되는 튜플이 데이터베이스의 다른 튜플에서 참조된다는 것을 의미
- RESTRICT option
- reject the deletion.
- 제한 옵션 : 삭제를 거부한다.
- 즉, 삭제 연산이 참조 무결성 제약 조건을 위반할 경우 삭제를 허용하지 않는다.
- CASCADE option
- do the deletion of the tuple followed by the deletion of the tuples that referencing the tuple being deleted.
- CASCADE(전파) 옵션: 삭제된 튜플을 삭제한 후, 해당 튜플을 참조하는 튜플들도 순차적으로 삭제
- 즉, 삭제 연산이 연쇄적으로 전파
- SET NULL or SET DEFAULT option
- set the foreign keys of the referencing tuples to NULL or default values after the deletion.
- SET NULL 또는 SET DEFAULT 옵션: 삭제된 튜플을 참조하는 다른 튜플들의 외래 키 값을 NULL 또는 기본값으로 설정
One of the above options must be specified during logical database design for each foreign key constraint.
이러한 옵션 중 하나는 논리적 데이터베이스 설계 과정에서 각 foreign key constraint에 대해 지정되어야 한다.Ex) In SQL, CREATE TABLE products (p_id numeric(10) not null, s_id numeric(10) not null, FOREIGN KEY (s_id) REFERENCES supplier(s_id) ON DELETE CASCADE);
5-5. Possible Violation Cases for UPDATE Operation
- Update the salary of the EMPLOYEE tuple with Ssn = ‘999887777’ and 100000.
- Problem?
- What if the salary cannot exceed 99999?
- 급여가 99999를 초과해서 100000으로 업데이트된다면, salary domain 제약 조건을 위반
- Update the Dno of the EMPLOYEE tuple with Ssn = ‘999887777’ to 7.
- Problem?
- Dno이 존재하지 않는 부서 번호(7)로 업데이트된다면, 참조 무결성 제약 조건을 위반
- 즉, 이 직원이 참조하는 부서가 존재하지 않을 수 있다.
- Update the Ssn of the EMPLOYEE tuple with Ssn = ‘999887777’ to ‘987654321’.
- Problem(s)?
- 만약 Ssn이 이미 다른 직원의 식별 번호로 업데이트된다면, 데이터 중복성이 발생할 수 있다.
- 즉, 이러한 업데이트는 다른 직원과의 중복된 Ssn을 생성할 수 있다.
- Update the Ssn of the EMPLOYEE tuple with Ssn = ‘999887777’ to NULL.
- Problem(s)?
- 만약 Ssn이 NULL로 업데이트된다면, 주 키(primary key) domain 제약 조건
- 주 키는 고유한 값을 가져야 하며 NULL을 가질 수 없다.
5-6. Possible Violation Cases for UPDATE Operation: Summary
- UPDATE는 attribute를 수정하면서 (i) domain constraint와 (ii) NOT NULL constraint를 위반할 수도 있다.
- Domain Constraint : 업데이트된 값이 허용된 도메인 범위를 벗어날 경우 도메인 제약 조건을 위반
- NOT NULL constraint : 업데이트된 값이 NULL로 설정될 수 없는 속성인 경우, NOT NULL 제약 조건을 위반.
- Any of the other constraints may also be violated, depending on the attribute being updated.
- 업데이트 작업에 따라 해당 속성이 기본 키(PK)이거나 외래 키(FK)인 경우 다른 제약 조건도 위반될 수 있다.
- 만약 업데이트 대상 속성이 기본 키 (PK) 속성이라면, 이는 기존 튜플을 삭제하고 새로운 튜플을 삽입하는 것과 유사한 작업이 될 것이다.
- DELETE와 유사한 옵션을 적용해야 한다.
- 만약 업데이트 대상 속성이 외래 키 (FK) 속성이라면, 참조 무결성 제약 조건을 위반할 가능성이 높다.
- DELETE와 유사한 옵션을 적용해야 한다.
- 업데이트 대상 속성이 기본 키나 외래 키가 아닌 경우,
- 주로 도메인 제약 조건이나 NOT NULL 제약 조건을 위반할 수 있다.
- 이 경우 간단하게 업데이트를 거부할 수 있다.
5-7. Transaction Concept(compared to a query)
- 데이터베이스 응용 프로그램은 일반적으로 하나 이상의 트랜잭션을 실행
- Transaction : Atomically 수행되어야 하는 데이터베이스 작업(쿼리, 삽입, 삭제 및/또는 업데이트) 시리즈를 포함
- EX) 은행 송금 작업은 하나의 트랜잭션으로 볼 수 있다.
- 대부분의 상업용 응용 프로그램은 관계형 데이터베이스를 대상으로 하며, 온라인 트랜잭션 처리 (OLTP) 시스템에서 실행 중이다.
- 이러한 응용 프로그램은 초당 수백 건 또는 수천 건에 달하는 속도로 트랜잭션을 실행한다.
Reference
Database System Concepts | Abraham Silberschatz
데이터베이스 시스템 7th edition
