22.10.02
오늘 수업에서는 어제 하던 것에 이어 데이터 수집 강의를 마무리했다. 반복문을 사용하지 않고 데이터를 수집하기 위한 함수와, 수집한 데이터를 처리하는 법을 배웠다.
또한, 새로운 시각화도구를 배웠다. Plotly가 무엇인지와 그동안 사용했던 시각화 라이브러리와의 차이는 무엇인지.
어떻게 사용하는지 배웠다.
그럼 정리를 시작해보자!
복습과 정리를 어떻게 하는게 좋을지 계속 고민 중!
다시 원래 하던대로 바꾸어서 실습파일 위주보다는 내용 위주로 정리해보자! 실습을 하며 배운 내용 위주로!
데이터 수집 및 저장(0206)
우리가 무슨 프로그램을 만들고 있었는지 복기해보자.
서울열린정보광장 중, 다산 콜센터 주요민원 목록 페이지에서 목록에 있는 민원들의 여러 정보를 스크래핑하고, 거기에 추가로 민원들의 상세 링크로 들어갔을 때 얻을 수 있는 두가지 데이터를 수집하는 프로그램이었다.
이를 위해, 목록의 모든 페이지를 반복하며 얻을 수 있는 정보를 스크래핑하는 함수(1)를 만들었었고,
세부 링크에 접속해, 거기에 있는 정보들을 스크래핑 하는 함수(2)도 만들었었다.
남은 것은, (1)에서 얻은 df에 있는 링크를 이용해 (2)를 사용하여, (1)의 결과 df와 (2)의 결과 df를 합쳐주는 것이다.
반복문은 사용하지 않고! 데이터프레임의 모든 요소에 함수를 적용하여! 결과를 얻으려면 어떻게 해야할까.
반복문 없이 모든 요소에 함수 사용하기
- map
- apply
- applymap
위 함수들을 사용한다. 해당 함수들은 list 혹은 Series와 DataFrame같이 여러 자료들이 모여있는 자료형의 모든 요소에 특정 함수를 적용해준다.
사용법은 이렇다.
df['컬럼'].map(함수)
이때, 컬럼의 모든 요소가 함수의 입력값이 되므로, 함수를 쓸때 인자는 전달해줄 필요가 없다.
그리고 위 함수들은 원본 객체를 변화시키지 않는다.
map, apply, applymap 함수 간 사용법의 차이가 있다.
map 함수는 시리즈에는 사용이 가능하고, 데이터프레임에는 불가능하다.
apply 함수는 시리즈와 데이터프레임에 모두 사용 가능하다.
applymap 함수는 시리즈엔 불가능, 데이터프레임엔 가능하다.
추가로, map 함수는 파이썬의 내장함수로 존재하여, 리스트 등에도 사용 가능하다.
사용 예시는 다음과 같다.
df['생산연도'] = df['생산일'].map(lambda x : x[:4])해당 함수는, datafrmae의 '생산일' 컬럼의 모든 요소에 lambda 함수를 적용해준다. 해당 lambda의 기능은 입력의 앞 4글자까지만 슬라이싱 하는 것이므로, '생산일'컬럼에 있는 모든 요소(날짜 형식이다.)의 앞 4자리를 잘라 생산 연도 컬럼에 저장해준다.
우리 실습에서는 이렇게 활용했다. (0206)
view = df['내용번호'].map(get_view_page)어제 혼자 할때는 되게 어려웠는데. map과 apply 함수 사용법을 알고 나니 어렵지 않다.
실습 측면에서 살펴보면, 원래대로라면 반복문을 통해 모든 링크에 대해 접속하며 함수를 돌려 아주 오래걸렸겠지만, map 함수를 사용함으로써 반복문 없이 벡터에 대해 연산함으로써 연산 속도가 아주 빨라진다.
- progress_map, progress_apply (tqdm)
그런데, 위 함수들을 사용할때 진행 상황을 알 수 없어 답답하다. tqdm을 import 하여 progress_map, progress_apply 함수를 사용할 수 있다.
from tqdm.notebook import tqdm
tqdm.pandas()
view_detail = df['내용번호'].progress_map(get_view_page)tqdm.notebook은 tqdm의 예전 버전이다. 그냥 tqdm으로 사용해도 된다.
tqdm.pandas()는 pandas의 객체들에 대해 tqdm 라이브러리의 함수를 사용하겠다고 선언해준다.
그 후, map이나 apply 대신 progress_map을 사용해준다.
해당 코드의 결과로는 함수를 몇 퍼센트나 적용시켰는지 진행 상황이 표시된다.
이제 실습에서 모든 정보를 얻었고, 두개의 데이터프레임이 존재하므로 이를 열 방향으로 합쳐줘야한다. 두개의 데이터 프레임을 합쳐주자.
데이터프레임 병합
데이터프레임을 병합하는 방법으로는, 아래 세개의 함수를 사용하는 것이 대표적이다.
- concat
- merge
- join
concat
concat의 경우, 데이터프레임을 이어붙인다(concatenate).
다음과 같이 사용한다.
pd.concat()인자로는 시리즈나 데이터프레임을 요소로 갖고 있는 sequence 자료형이 들어간다. 우리 실습에서는 주로 df를 여러개 담고 있는 list에 대해 concat을 사용했다.
이때, parameter axis를 0으로 주면(기본값) 행 방향으로 데이터프레임을 이어붙인다. axis = 1이면 열 방향(옆)으로 데이터프레임을 이어붙인다.
ignore_index = True로 주면, 이어 붙이는 방향의 인덱스를 초기화해준다. 행방향으로 붙이면 인덱스가 초기화되고, 열 방향으로 붙이면 column 이름들이 초기화된다.
join 옵션을 줄 수도 있다. 기본값은 outer이다.
merge
merge함수와 join 함수는, 데이터프레임을 병합, 합쳐준다.
두개의 데이터프레임에 겹치는 요소가 있어 그것을 중심으로 합칠때 사용한다.
사용법은 다음과 같다.
pd.merge(left,right,on,how)
# 또는
df_left.merge(right,on,how)pd.merge로 함수로 사용할 수도 있고,
df.merge로 메소드처럼 사용할 수도 있다.
인자로는 합쳐줄 데이터프레임을 받는다.
on parameter에는 양쪽 데이터프레임에 모두 존재하는 컬럼명을 주면 된다. 두 개 이상의 컬럼도 들어갈 수 있다. 만약 on 값을 주지 않으면, 자동으로 두 데이터프레임에 모두 존재하는 컬럼을 찾아 사용한다.
만약, 값은 같지만 이름은 다른 컬럼에 대해 병합할 경우, left_on과 right_on 을 사용하여 각각 컬럼의 이름을 넣어주면 된다.
how parameter에는 join할 방식을 넣어준다.
left, right, inner, outer의 옵션을 줄 수 있다.
left와 right는 왼쪽 또는 오른쪽에 존재하는 것만,
inner는 양쪽 모두에 존재하는 것만,
outer는 둘 중 하나라도 존재하는 것을 병합해준다.
기본값은 inner이다.
join
join은 merge함수와 유사하다. 하지만 행 방향을 기준으로 겹치는 인덱스에 대해 병합해준다는 차이가 있다. 추가로 pandas의 함수가 아닌 데이터프레임 자료형의 메소드이다.
다음과 같이 사용한다.
df.join(df_other, on=None, how='left')join의 경우, 행 방향으로 겹치는 인덱스를 기준으로 데이터를 병합해준다.
join의 how parameter의 기본값은 'left' 이므로, 따로 옵션을 주지 않으면 기본적으로 원 데이터프레임의 인덱스만 모두 출력된다.
on parameter에 컬럼 값을 주면, 해당 컬럼의 값들을 기준으로 하여 행 기준으로 병합한다. 그 컬럼의 값 중 병합될 컬럼의 인덱스가 있으면 옆으로 붙는다!
이렇게 데이터 수집에 대해서 모두 배워보았다.
아주 여러가지 실습을 했었던 것이 기억에 남는다.
table 태그는 pandas의 pd.read_html()로 훨씬 쉽게 스크래핑 할 수 있다는 것, 반복문을 사용하지 않고 apply나 map을 이용해 모든 요소에 함수를 적용할 수 있다는 것이 기억에 남는다.
데이터프레임을 찢고, 돌리고, 합치며 조작해봤던 것도 기억에 남는다.
그리고, 모든 데이터에 대해서가 아니라 일부 데이터에 대해 코드를 짜며 확인해보는 습관!을 가져야겠다. 꼭! time.sleep()도 해주고!
이제 EDA에 대해 배운다. 이번주에는 EDA 중 데이터 시각화에 대해 주로 배울 것 같다.
Plotly 데이터 시각화(0301, 0302)
데이터 시각화
데이터를 시각화하여 살펴보는 방법은 아주 옛날부터 존재해왔고, 아주 중요하다.
현재 기업에서도 tableau, power BI 등 다양한 시각화 툴을 이용해 시각화를 진행하고 있다.
파이썬에도 데이터를 시각화하는 라이브러리들이 상당히 많이 존재한다.
파이썬의 데이터 시각화 라이브러리는 크게 두가지 분류로 나눌 수 있다.
- 정적인 시각화 (matplotlib 기반)
- matplotlib
- seaborn
- pandas
- plotline
- 동적인 시각화 (JavaScript 기반)
- plotly
- bokeh
- Altair
pandas를 이용한 시각화
먼저, 원래 seaborn을 주로 사용했었는데, pandas를 이용한 matplotlib 기반의 시각화를 배웠다.
한글 폰트 설정
원래 아주 번거로운 과정을 거쳐야하지만, 라이브러리를 사용하여 한번에 해결한다.
Koreanize-matplotlib 을 이용한다.
!pip install koreanize-matplotlib
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'이렇게 해주면 한글 폰트 설정이 끝이다. 간단하다!
matplotlib 그래프 스타일 설정
import matplotlib.pyplot as plt
print(plt.style.available)
plt.style.use('ggplot')그래프에 적용할 수 있는 다양한 스타일을 볼 수 있고, 적용할 수 있다.
주의할 점 : 폰트를 적용시켜주는 스타일을 사용하면 한글 폰트가 깨질 수 있다!
pandas로 시각화하기
10 minutes to pandas에서 해봤었는데, 오늘 더 자세히 배웠다.
.plot()을 이용한다!
df.plot(figsize=(12,4))
plt.legend(bbox_to_anchor=(1,1)) #그래프 바깥쪽에 범례를 표시!
plt.axhline(0,c='r') # x = 0에 수직선 그어줌, 빨간색!.plot()을 이용하여 그래프를 그릴 수 있다.
()안에 다양한 인자를 넣어주어 그래프의 크기 등 다양한 요소를 설정할 수 있다. subplots =True를 통해 가장 쉽게 서브플롯을 표시할 수도 있다.
그래프를 그린 후 plt.legend등으로 그래프와 관련된 다양한 요소에 대해 설정할 수 있다.
df의 일부 컬럼에 대해서만 그래프를 그리려면 다음과 같이 사용한다.
df[['삼성전자','LG화학']].plot()그래프의 값의 scale차이가 너무 많이 날 경우, 두번째 축을 설정해주어 값을 잘 볼 수 있게 만들어준다.
df[['삼성전자','LG화학']].plot(secondary_y='LG화학')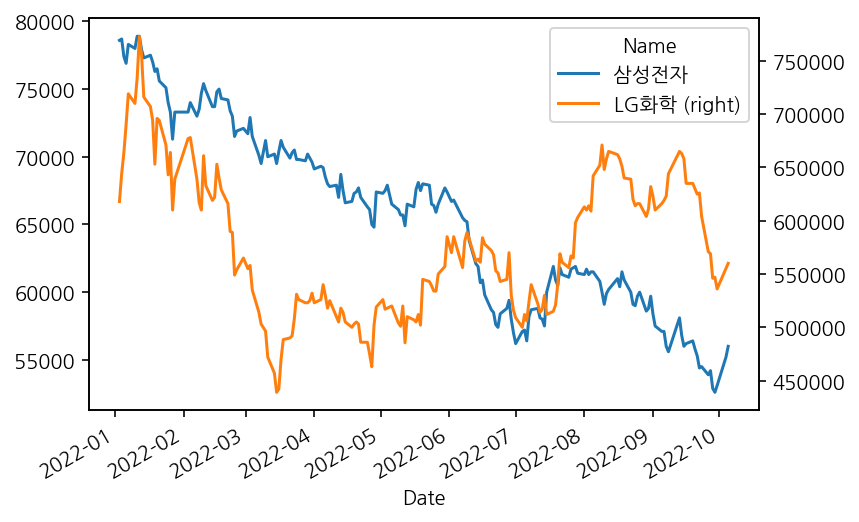
다양한 종류의 그래프를 그릴 수 있다.
히스토그램은 다음과 같이 그린다.
df_norm.hist(bins = 50, figsize=(15,10));
## cell 실행시 주석 안나오게 하려면 변수에 대입해주거나, ;찍거나 plt.show()쓰거나!
## pandas에서 막대형 그래프는 범주형 그래프라는 것을 전제로 함.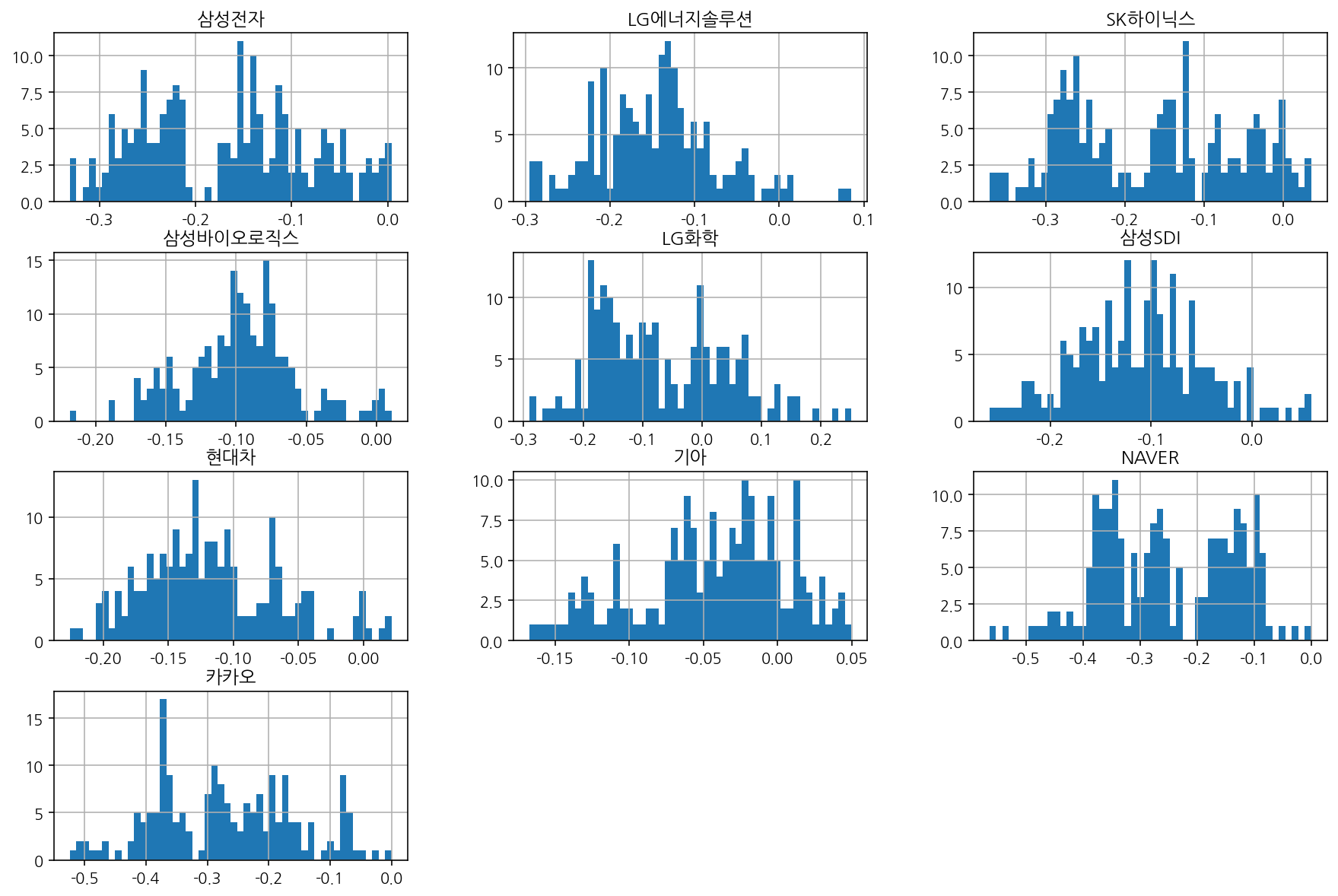
plotly
이번 실습부터는 동적인 시각화 라이브러리 중 하나인 Plotly에 대해서 배워본다.
Seaborn 처음 배울 때 정말 머리가 너무 아팠는데, 지금은 그래도 적응이 되었으니까! Plotly도 할 수 있을 거라고 생각하자!
- plotly란
앞에서 언급했듯이, JS 기반의 시각화 라이브러리이다. matplotlib이나 seaborn이 연산을 통해 그래프를 그려 이미지 형태로 출력해준다면, plotly는 이미지 파일이 아닌, 자바스크립트로 만들어진 그래프를 출력한다. 해당 그래프는 인터랙티브한 형태로, 개별 값 표시, 확대, 이동 등 다양한 기능이 있다.
matplotlib 기반 라이브러리와 달리 한글 폰트가 깨지지 않아 추가 설정을 해줄 필요가 없기도 하다.
matplotlib 기반 라이브러리로 시각화 한 것과 비교해보면, 훨씬 보기 좋고 직접 범위를 변경하거나 확대하며 볼 수 있어 좋다. 하지만 많은 양의 데이터에 대해 시간이 오래걸린다는 단점이 있다.
속도를 개선하기 위한 방법으로, 대표값을 표시해야 한다면, 그래프에서 계산하지 않고 미리 계산해서 시각화하기가 있을 것이다.
- 사용법
plotly를 사용하는 방법은 두가지가 있다.
하나는 plotly.express를 사용하는 것이고, 하나는 plotly.graph_objects를 사용하는 것이다.
plotly express가 사용법이 seaborn과 유사하고 비교적 간단한 반면, 시각화의 다양성이 조금 떨어진다.
하지만 공식적으로도 plotly express 사용을 추천하고 있다고 한다!
따라서 plotly express를 다음과 같이 사용한다.
import plotly.express as px
# graph objects는 다음과 같이
import plotly.graph_objects as go- 내장 데이터셋
seaborn과 마찬가지로, 몇개의 데이터셋을 내장하고 있다.
df = px.data.stocks()- 선 그래프 그리기!
.line() 함수를 이용해 선 그래프를 그릴 수 있다.
px.line(df,x = "date",y="GOOG",title="일별 시세")- 막대 그래프 그리기
.bar() 함수를 이용해 다양한 방법으로 그릴 수 있다.
px.bar(df_1, x= df_1.index, y="GOOG")
px.bar(df_1,y="GOOG")
px.bar(df_1["GOOG"])첫번째는 정석적인 방법으로, 데이터, x축에 들어갈 값, y축에 들어갈 값을 지정했다.
두번째는 데이터와 y축값만 주고, x축에는 기본값인 index가 들어가게 해주었다.
세번째는 y축에 들어갈 데이터만 전해주었다.
- 서브플롯 그리기
seaborn과 달리, 개별 함수가 각각 모두 FacetGrid 기능을 포함하고 있다. Facet_col을 이용한다.
이때, Facet_col을 이용하기 위해 사전 작업이 하나 필요하다. 컬럼의 이름을 지정해주어야 한다.
Facet_col
facet_col: str or int or Series or array-like
Either a name of a column indata_frame, or a pandas Series or array_like object. Values from this column or array_like are used to assign marks to facetted subplots in the horizontal direction.
Facet_col에 들어가는 값에 대해 subplot을 그려주기 때문에, df의 column에 대해 각각 subplot을 그려주고 싶다면, column에 이름을 붙인 후 Facet_col에 넣어준다.
df_1.columns.name = 'company'
df_1.columns
>>>
Index(['GOOG', 'AAPL', 'AMZN', 'FB', 'NFLX', 'MSFT'], dtype='object', name='company')px.area(df_1,facet_col='company',facet_col_wrap = 2)

- hover_data
hover_data 속성을 지정하여 그래프에 마우스를 대었을 때 나오는 데이터의 출력 속성도 지정할 수 있다.
px.line(df,hover_data={'date': "|%Y-%m-%d"})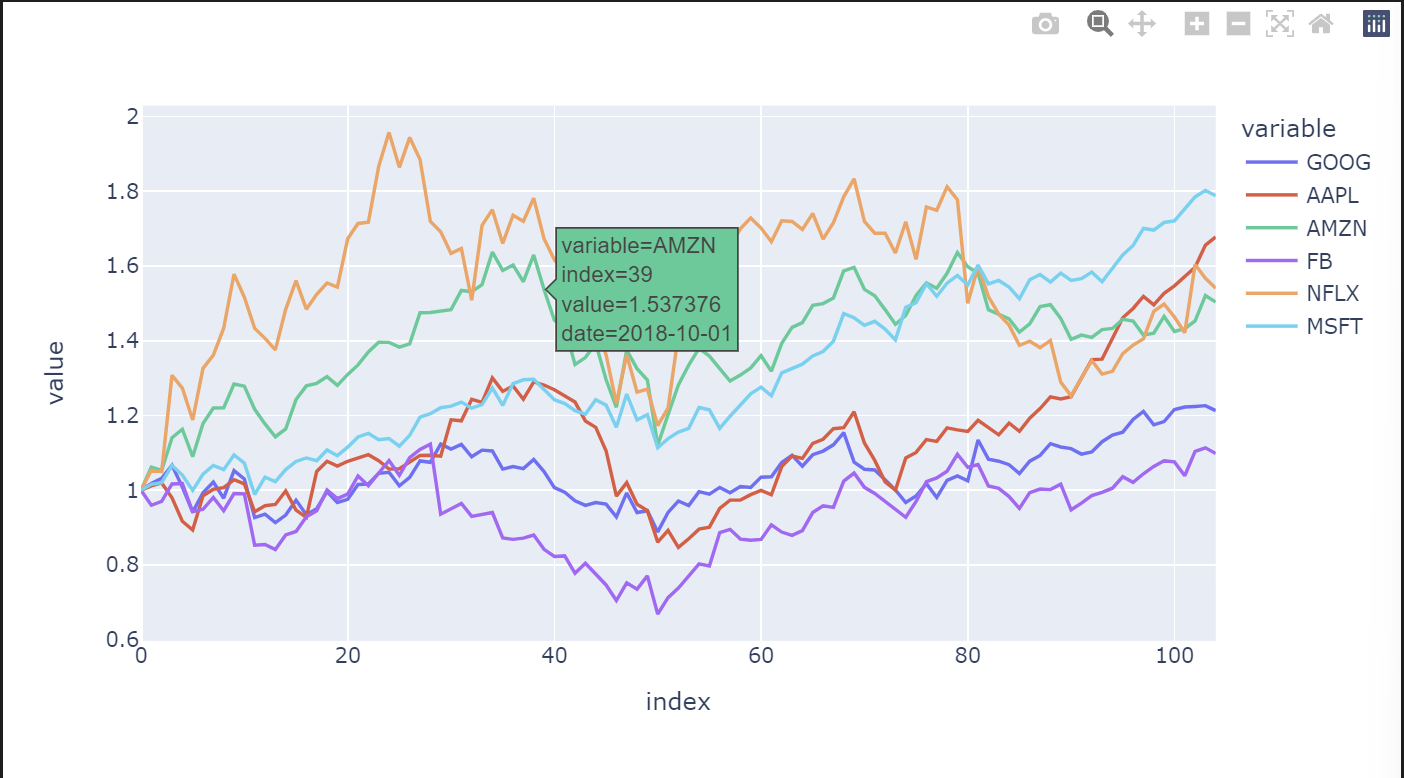
- Range Slider
그래프에 Range Slider가 나타나게 해줄 수도 있다.
다음의 코드로 사용한다.
fig = px.line(df_1['GOOG']) ## rangeslider를 이용하기 위해 fig에 저장
fig.update_xaxes(rangeslider_visible=True) ## rangeslider를 이용하기 위한 코드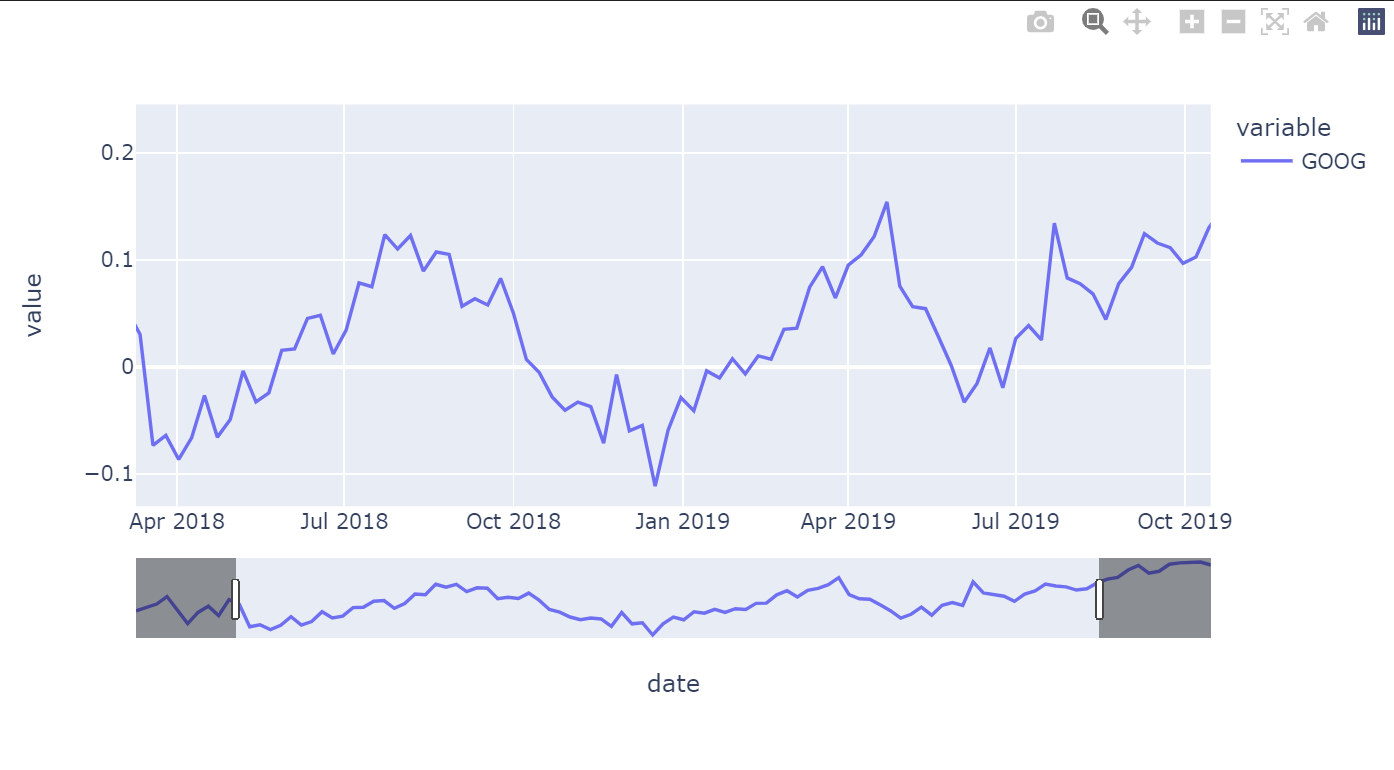
- candlestick 그리기(graphic_objects 이용)
주식 차트에 많이 사용하는 차트도 그릴 수 있다. 빨간색이 하락, 초록색이 상승이라고 한다.
import plotly.graph_objects as go
import pandas as pd
from datetime import datetime
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/finance-charts-apple.csv')
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()위와 같은 형식의 코드를 사용하여 그릴 수 있다.
- OHLC(Open-High-Low-Close)
주식 차트를 그릴때 사용하는 다른 종류.
시가와 종가는 각각 왼쪽과 오른쪽에 튀어나와있고, 가운데 긴 막대가 저가부터 고가까지 이어져있다.
역시 graphic_objects 를 이용하여 그린다.
fig = go.Figure(data=[go.Ohlc(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()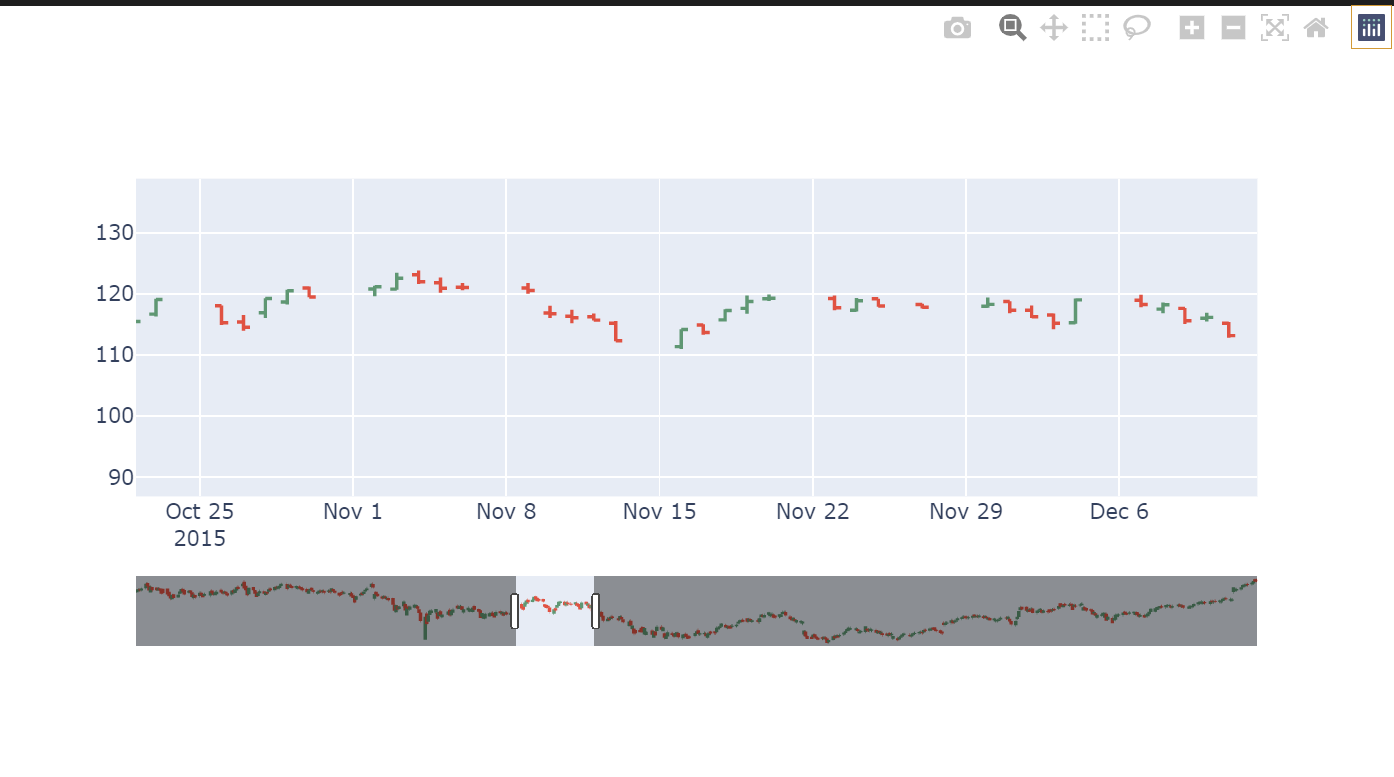
이렇게 graphic objects를 이용하면 더 많은 종류의 그래프를 그릴 수 있음을 알 수 있다.
fig.update_layout(xaxis_rangeslider_visible=False) 코드를 추가해, range slider가 안나오게 할 수도 있다.
0301 실습파일
-> financeDataReader Library의 공식 튜토리얼 실습을 기반으로 함!
- 네이버 증권에서 시가총액 상위 10개 종목에 관한 정보를 스크래핑.
- fdr을 이용해 해당 종목들의 일별 시세를 스크래핑.
- 시각화를 통해 해당 종목들의 수익률 비교.
- 특이사항
- 일별 시세엔 종목코드가 필요하나, 시가총액으로 긁어온 테이블엔 종목코드가 없어 fdr로 구해야함(전체 종목에 대해 표시)
- 종목코드 를 구한 테이블과 원래 시가 상위 테이블을 merge한 후, 이름과 종목코드만 사용하도록 설정.(시가 상위의 이름과 종목코드만 구함)
- 각 종목에 대해 시세를 구하여 하나의 데이터프레임으로 concat 함(comprehension 이용)
item_list = [fdr.DataReader(sym,"2022")["Close"] for sym in df_10['Symbol']] - 시각화 시, koreanize_matplotlib을 사용하여 matplotlib에서 한국어가 깨지지 않도록 설정
- 시각화 시, secondary_y를 사용해 scale 차이가 많이 나도 비교할 수 있도록 함
plt.legend(bbox_to_anchor=(1,1))로 범례가 그래프 밖에 표시되게 함- 수익률을 비교하고자 각 시세를 첫날의 시세로 나눈 후 1을 빼어 수익률을 표시
- 첫날인 1월 1일에 상장되지 않은 엔솔에 대해선 예외처리 필요 (엔솔의 첫날을 찾아 그 가격으로 나누어준다)
df_norm['LG에너지솔루션'] = (df['LG에너지솔루션'] / df['LG에너지솔루션'].dropna()[0]) -1 - 0302에서 : 전처리가 쉬워지는 형태로 set_index를 자주 사용하기도 한다. date 빼고 모든 컬럼에서 1을 빼주기 위해 유일한 object dtype인 date를 index로 설정해줌.
오늘의 수업 내용은 여기까지이다!
뭔가 정신이 하나도 없네...!
plotly라는 시각화 라이브러리를 처음 접하고 조금 사용해보았다.
복습하면서도 그냥 실습 코드만 실행해본게 아쉬움이 있다. 시간이 더 있었으면 좀 찾아보기라도 했을텐데!
그래도 뭔가 많은 양의 내용이 쏟아진 것 같은데, 복습하면서 머릿속에 조금이라도 들어왔으면 좋겠다.
plotly의 다양한 그래프들을 그려보는 실습을 아마 내일부터 하지 않을까! 열심히 참여하면서 좀 익숙해지기 위해 노력해야겠다.
그럼 과제하러 가야겠다...! 파이팅!
아 plotly로 그린 그래프를 여기에 넣지 못해 아쉽다. 나중에 복습할때 좀 힘들수도 있겠다!
