plotly
수치형 변수의 시각화
line
가장 기본적인 plot
px.line(df_tsm['Change'],title = "전일비")연속적인 수치형 변수들에 대한 그래프를 그릴 때 적절하겠다.
area
line plot에서 축과 그래프의 사이를 색칠한 것.
px.area(df_ratio,facet_col = 'company',facet_col_wrap = 2)역시 마찬가지로 연속적 수치형 변수에 적절할 듯 하다.
facet_col 옵션을 통해 서브플롯을 나누어 그릴 기준을 정해줄 수 있다.
범주형 변수가 있다면 해당 변수를 넣어주어도 되겠고, df의 모든 변수(각 컬럼)에 대해 나누어 그리고 싶다면 columns.name을 설정한 후 그 이름을 넣어준다.
scatter
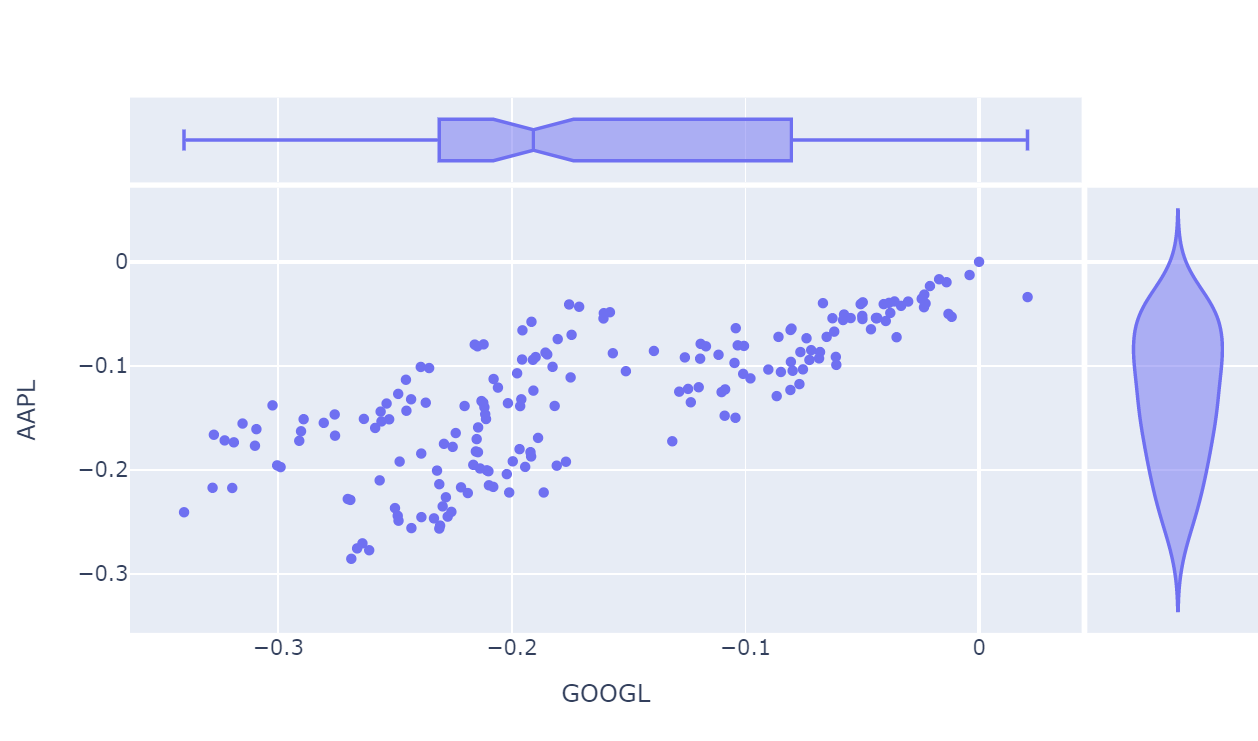
scatter는 연속적 수치형 변수와 연속적 수치형 변수 간의 관계를 표현할 때 사용한다.
px.scatter(df_ratio, x='GOOGL',y="AAPL",marginal_x = 'box', marginal_y = 'violin')marginal 옵션을 통해 그래프 바깥쪽에 또 다른 그래프를 그려줄 수 있다. marginal_x, marginal_y를 각각 설정해줄 수 있다.
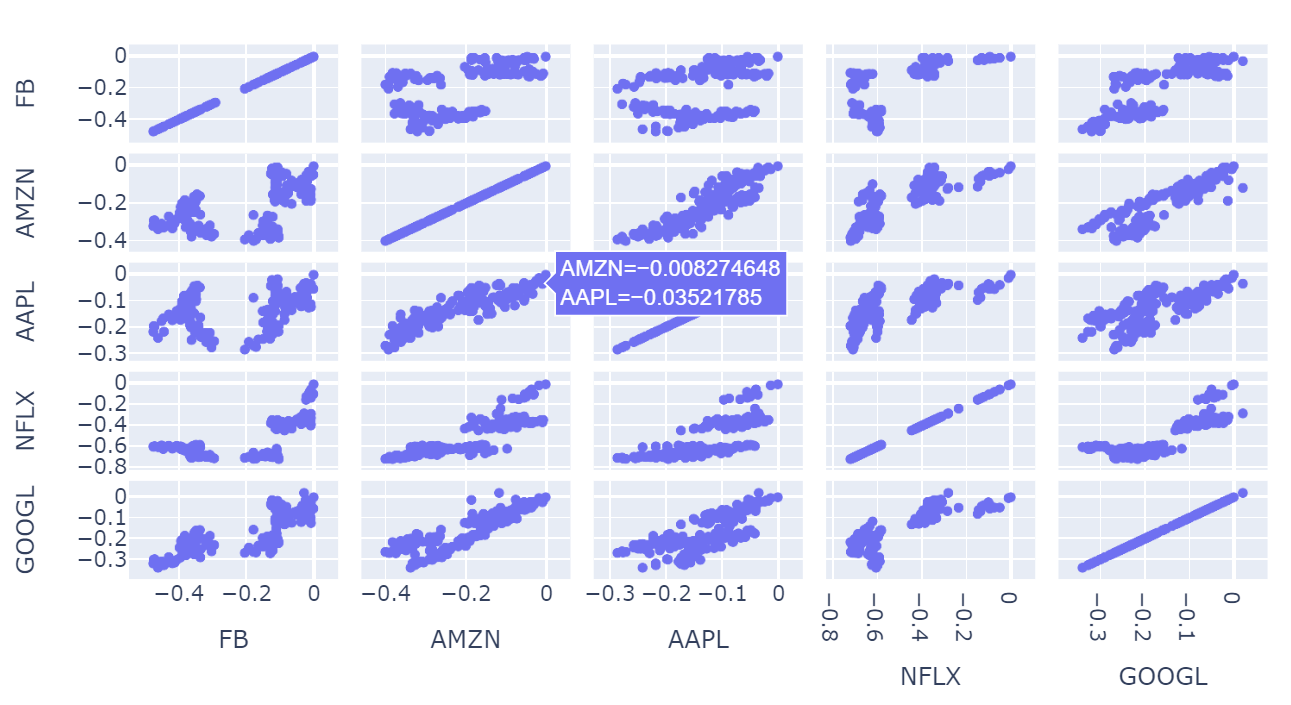
scatter_matrix도 존재한다.
px.scatter_matrix(df_ratio)seaborn의 pariplot같은 느낌인 것 같다. 모든 변수 사이의 관계를 그려준다.
box
수치형 변수의 분포를 그려주는데, 사분위 값 등 다양한 값을 이용해 그려준다.
px.box(df_ratio,notched = True, points = 'all')points 옵션을 추가해 점을 통해 데이터의 분포를 나타낼 수 있다. strip plot과 합쳐진다고 보면 될 듯
violin
boxplot과 kdeplot을 합쳐놓은 그래프. 수치형 변수의 분포를 아주 잘 표현한다.
px.violin(df_ratio,points='all')histogram
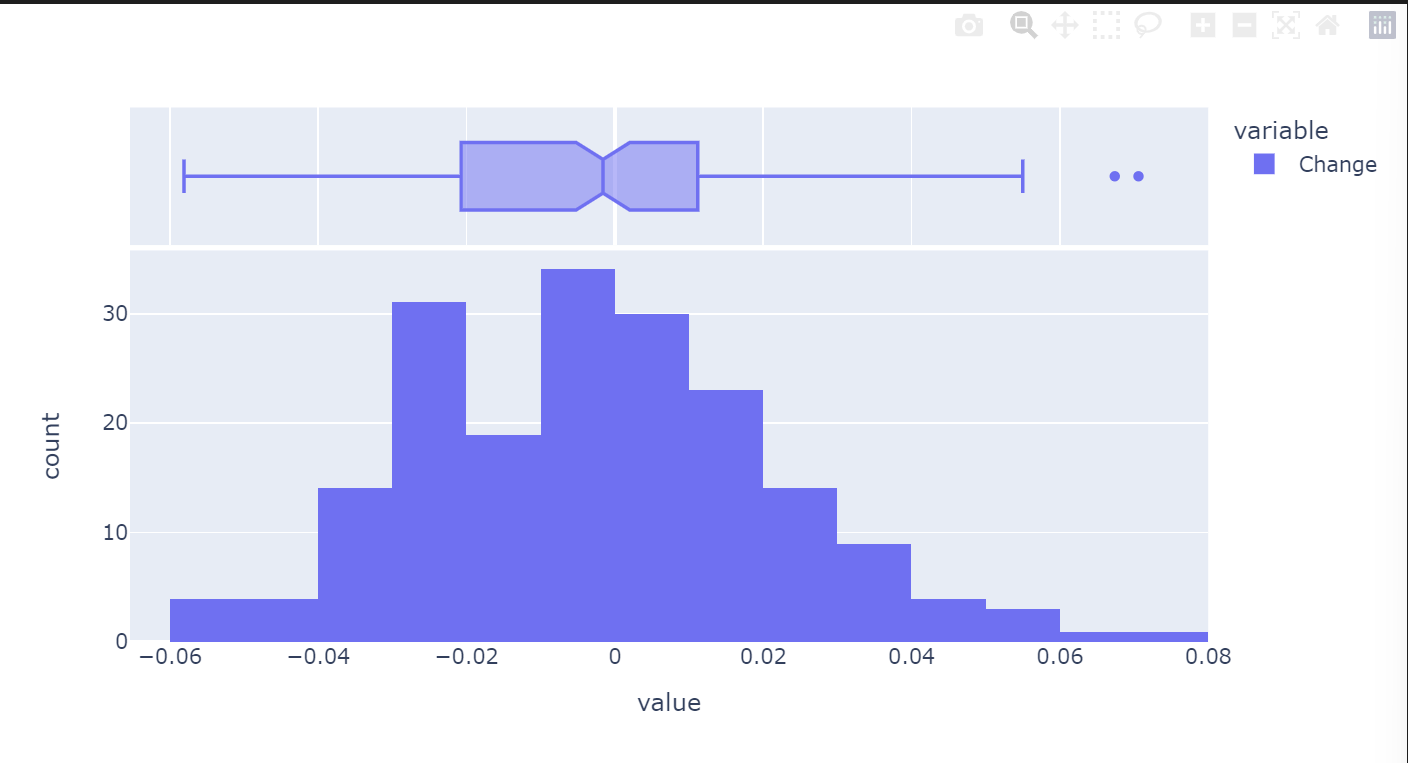
histogram은 수치형 변수의 분포를 나타내는데, 몇개의 범주로 잘라 해당 분포에 해당하는 도수를 표시한다.
쉬운것 같은데 왜 이렇게 느낌이 안 올까!
px.histogram(df_tsm['Change'],marginal = 'box')seaborn 등에서는 bins를 사용했지만, plotly에선 nbins를 사용한다.
marginal 옵션을 통해 그래프 바깥쪽에 또 다른 그래프를 그려줄 수 있다. 여기서는 box plot을 그려주어 데이터의 4분위 값도 파악할 수 있게 해주었다.
범주형 변수의 시각화
bar
범주형 변수의 분포를 파악하기 위해 그리는 그래프이다.
px.bar(df_ratio, facet_col = "company",facet_col_wrap=1)strip
범주형 변수 내 자료들의 분포를 표시해준다.
이게 이해가 잘..! 흠..
특정 범주형 변수에 대해, 각 범주들에 포함되는 데이터들이 다른 수치형 변수에 대해서 어떻게 분포되어있는지를 표시해준다.
사실 bar plot도, violin plot도 똑같다. 범주형에 넣었어야하나 싶다.
px.strip(df_ratio)Pandas EDA
데이터프레임 확인하기
df_01.head()
df_01.tail()
df_01.sample()
df_01.shape먼저 데이터프레임을 확인한다. shape로 행과 열의 수를 보고, 몇개의 데이터만 추출하여 어떤 컬럼에 어떤 값들이 들어있는 데이터인지 확인하는 과정을 거친다.
요약 및 기술통계 값 확인하기
df.info()
df.describe()
df.describe(include = 'object')df.info()를 통해 데이터프레임의 요약 정보를 확인한다.
다양한 기술통계값을 살펴본다.
빈도수 확인하기(범주형 변수)
df['퇴원현황'].value_counts()
pd.crosstab(index, columns, values)범주형 변수의 경우 꼭 확인해야하는 값으로 도수가 있다.
value_counts()로 한개의 변수에 대한 도수를 구한다.
crosstab으로 두개의 변수에 대한 빈도수를 구한다.
normalize = True 옵션을 추가해 정규화하여 비율을 볼 수도 있다.
기타 정보 살펴보기
df['퇴원현황'].unique()
df['퇴원현황'].nunique()
df.dtypes()
df.columns()
df.index()필요하다면 고유값이나 dtype 등 다양한 정보를 살펴볼 수 있다.
데이터프레임 정렬하기
df.sort_index()
df.sort_values()데이터프레임을 정렬해준다. 인덱스 혹은 값에 대해 정렬할 수 있다.
시각화할때, 정렬된 순서대로 그래프에 나타나게 되므로 정렬한 후 시각화한다.
진짜, 최후의 수단으로. 정렬을 원하는데 그 기준에 맞추어 정렬할 수 없을때!
원하는 순서대로 인덱싱한다. df = df[[1,3,2]] 이렇게! 이거 꼭 기억하자.
썼었는데 왜 날아갔지?
결측치 보기 및 처리
df.isnull().sum() # 결측치의 개수(합계)
df.isnull().mean() # 결측치의 비율
df.dropna() # 결측치 제거
df.fillna() # 결측치 처리isnull() 기능을 이용해 결측치를 확인한다.
결측치를 제거하거나 다른 값으로 바꾸어주기 위해 dropna나 fillna를 사용할 수 있다.
중복 제거하기
df[df.duplicated()]
df.drop_duplicates().duplicated()로 중복값을 확인할 수 있다.
drop_duplicates()로 중복값을 제거한다.
데이터 타입 변경하기
df_all_day['확진수'] = df_all_day['확진수'].astype(int)astype()을 사용하여 컬럼 전체의 dtype을 변경한다.
df['확진일'] = pd.to_datetime(df['확진일'])이렇게 to_datetime 함수를 사용해 날짜 데이터로 바꾸어줄 수도 있다.
파생 변수 만들기
df['연도'] = df['확진일'].dt.year
df['연도월']=df['확진일'].astype(str).str[:7]이런 방식으로 쉽게 파생변수를 만들 수 있다.
혹은 함수를 적용해서 파생변수를 만들 수도 있다. map이나 apply등을 사용한다.
df['요일명'] = df['요일'].map(find_dayofweek)시각화하기
.plot() 기능을 이용해 다양한 그래프를 그릴 수 있다.
subplots = True로 subplot을 그릴 수도 있고,
다양한 옵션을 설정하여 그래프를 커스텀할 수 있다.
예를 들면, rot = 0으로 글자의 회전을 설정해준다.
year_month.plot(kind='bar',grid= True, title = '연도월 확진 수')
# 다음과 같은 코드다
year_month.plot.bar(grid= True, title = '연도월 확진 수')
df.hist(figsize=(12,10), bins=40)Series 인덱스 변경하기
가끔 인덱스에 들어가는 값들을 바꾸어주어야 하는 경우가 있다. 0123456으로 표시되어 있는 값을 '월화수목금토일'로 바꾸고 싶다면 다음의 코드를 이용한다.
weekday_list = list("월화수목금토일")
weekday_count.index = weekday_list간단하게 index를 변경할 수 있다.
수업하며 배운 것들!
0302(주가 시각화)
오늘의 실습 내용
- fdr을 이용해 미국 주식 하나의 시세를 수집한 후 시각화
- FAANG 일별 수익률 시각화(여러 종목의 시각화)
실습 진행 과정
- FAANG의 ticker List 생성
- List Comprehension으로 fdr을 이용해 시세(종가) list 생성
- 열 방향으로 concat하여 데이터프레임으로 병합
- 데이터 살펴보기(describe, info)
- 데이터프레임을 변형하여 수익률 계산
- 다양한 그래프로 시각화
(line, area, bar, histogram, scatter, scatter_matrix, box, violin, strip)
배운 것들
- secondary_y
선 그래프를 그리며, secondary_y를 추가하고 싶어
이것저것 찾아보며 시도해봤지만, 실패했다.
더 찾아보니 plotly express 만으로는 안된다고 한다.
At this time, Plotly Express does not support multiple Y axes on a single figure.
To make such a figure, use theplotly.make_subplots()function in conjunction
다음에 그래프를 그려볼 기회가 있을 때 시도해봐야겠다.
- 사소한 오류
faang_list = [fdr.DataReader(stock, "2022")['Close'] for stock in FAANG]
# 2022 에 ""를 감싸주지 않아 오류가 났었다.fdr을 사용할 때 '2022' 대신 2022로 썼더니, 2022-09-06, 지금으로부터 한달 전 정보부터 뽑아오더라. 2022년의 정보를 제대로 뽑아오기 위해 '2022'를 사용하자.
- 컬럼명 쉽게 바꿔주기
df_faang = pd.concat(faang_list,axis = 1)
df_faang.columns = FAANGconcat한 후, 컬럼들의 이름이 모두 Close였는데, 컬럼의 개수와 길이가 같은 list를 df.columns = name_list로 바꾸어주니 이름이 쉽게 바뀌었다.
rename 이런거 안써도 되네. rename이라기 보다는 column 자체를 그냥 통째로 바꾸어준 느낌인 것 같다.
- df의 연산
df_ratio = (df_faang / df_faang.iloc[0]) - 1어제와 마찬가지로, 위와 같은 코드를 사용했다.
참 헷갈린다. 함수를 적용시킬 때에는 map이나 apply를 꼭 적용시켜야 하지만, 수치 연산을 할 때에는 그냥 df 자체에 연산을 해주면 모든 요소에 대해 연산이 진행된다.
- color(hue)
seaborn에서 색상을 다르게 나누어 주는 기준 변수를 hue 인자에 넣어주었다면, plotly에서는 더 직관적인 color를 사용한다.
- 수치형 변수만 뽑아내기
px.box(iris.select_dtypes(include='number'))select_dtypes(include = 'number')로 수치형 변수만 골라 box플롯을 그려주었다.
반대로 select_dtypes(exclude = 'number')도 가능하겠다.
- 문서나 설명을 보는 습관 들이기
당연히 모든 함수의 기능과 작동법을 외우고 사용하지 않는다. 공부할 때 도움말을 보며 한번 살펴보고, 사용해보고. 실제로 사용할 때 도움말을 보며 사용하면 된다.
0303(서울시 코로나 EDA)
오늘의 실습 내용
- 서울시에서 공개했던 코로나 19 발생 동향 데이터를 판다스의 데이터프레임으로 불러와 분석한다. 해당 과정을 통해 EDA를 익힌다.
실습 진행 과정
- 파일 불러와 데이터프레임으로 저장
- 데이터프레임 살펴보기(shape, head, tail, sample)
- 요약 값 및 기술통계 확인(describe, info, nunique)
- 중복값 제거(duplicated(), drop_duplicates())
- 결측치 확인 및 처리(isnull, fillna)
- 데이터타입변경(dtypes, astype, to_datetime)
- 파생변수 만들기(map함수 사용)
- 범주형 변수 빈도수 구하기
- 데이터 시각화(pandas)
- index 재설정, index 값 추가
배운 것들
- glob
from glob import glob
glob("seoul-covid*.csv")
## UNIX 스타일의 라이브러리, 정규표현식을 이용해 파일을 검색할 수 있는 기능
## 와 신기하다. seoul-covid로 시작하고, .csv로 끝나는 파일을 찾아줌.glob은 정규표현식을 이용해 파일을 검색할 수 있는 기능을 제공하는 라이브러리이다.
- 빈도수 확인하기
이걸 왜이렇게 까먹을까! 오늘 실습에서 빈도수를 구해야하는데, 어떻게 할지 한참 고민하다가 groupby해서 count 하게 코드를 짰다. 뭔가 이상하다 생각했는데... value_counts()로 빈도수를 바로 구할 수 있다. 두 개 이상의 기준에 대해선 pd.crosstab()을 이용한다.
범주형 변수는! 빈도수를 구한 후! 시각화한다!
- datetime
pandas의 자료형 중 하나로, datetime 형이 있다. 시간을 나타낸다.
to_datetime을 이용해 날짜처럼 쓰여진 문자열을 실제 날짜 데이터로 변경할 수 있다.
date_range()를 이용해 특정 범위 날짜들의 sequence도 만들 수 있다.
.dt accessor를 사용하면 다양한 메소드나 attribute를 이용할 수 있다. dt.day, dt.week, dt.year, dt.dayofweek 등
- 없는 값 채워주기!
가장 신기했던 부분! 특정 변수에 대해 날짜별로 그 빈도수를 구해 시각화한다고 생각해보자.
만약, 빈도수가 0인 날이 있다면, value_counts()로 구한 빈도수 Series에는 해당 일이 아예 포함되지 않는다.
따라서 그 데이터로 시각화한다면, 그래프에는 빈도수가 0인 날이 아예 표시되지 않아 왜곡된 그래프가 생긴다고 볼 수 있다.
이를 해결하기 위해, 빈도수가 없는 날짜까지 모두 index에 추가하여 새로운 데이터를 만들어야 할 것이다.
어떻게?
-> 전체 날짜를 가지고 있는 데이터프레임을 만들고, 빈도수를 구한 Series와 병합한다. fillna(0)를 이용해 빈도수가 없는 날은 0이 되게 만든다.
코드는 다음과 같다.
day_count = df['확진일'].value_counts().sort_index()
first_day = df.iloc[-1]['확진일']
last_day = df.iloc[0]['확진일']
all_day = pd.date_range(start=first_day, end=last_day)
df_all_day = all_day.to_frame()
df_all_day['확진수'] = day_count
del df_all_day[0]
df_all_day['확진수'] = df_all_day['확진수'].fillna(0).astype(int)
중요한 것 같다! 실제 데이터 분석시 사용할 일이 많을 듯. 특히 이렇게 날짜를 다루고 있는 데이터라면! (이런걸 시계열 데이터라고 하는 것 같다.)
- 요일 알려주는 함수 만들기
datetime의 dayofweek 변수가 월~일을 0~6의 값으로 표시함을 이용해 dayofweek을 받아 요일을 표시해주는 함수를 제작했다.
충격적이었다!
dayofweek = "월화수목금토일"
def find_dayofweek(day_no):
return dayofweek[day_no]사실 dayofweek 이라는 변수가 가지는 값의 의미를 생각하면 이렇게 만들 수 있겠지만..! 혼자 해보라고 했으면 생각 못했을 것 같다. 와.. 진짜... 실습 많이 해봐야겠다!
- 정렬에 대하여
실습 도중, 시각화를 하는데 데이터가 내가 원하는 대로 정렬되지 않아 이상하게 그려졌었다. 날짜를 기준으로 정렬했는데, 2021-1 다음이 2021-2가 아니라 2021-10으로 정렬 된 것이다. 그런데 오름차순 정렬이라면 그 정렬이 옳게 된 것이다.
따라서 우리가 원하는대로 날짜 순 정렬을 위해선 날짜를 표기할 때 2021-01 2021-02 2021-10으로 표시할 필요가 있었다.
- 그렇다면 어떻게 만들지?
그렇게 '연도월' 컬럼을 만드려면 어떻게 해야할까?
원래 코드는 이거였다.
df['연도월'] = df['연도'].astype(str) +'-'+ df['월'].astype(str)원하는 것은, df['월'].astype(str)가 두 자리를 차지하게 만드는 것이다. 어떻게 하지? 못하겠는데..?
zfill함수를 사용한다. zfill은 자릿수를 설정해주면 남는 자리를 모두 0으로 채워주는 함수이다. 참고!
df['연도월'] = df['연도'].astype(str) +'-'+ df['월'].astype(str).str.zfill(2)번거롭다! 실습에서 진행한 방법이 낫다.
df['연도월']=df['확진일'].astype(str).str[:7]문자열 슬라이싱을 할 때에도 str 접근자 써주는 것 잊지 말자.
- 원하는 기준으로 정렬할 수 없을 때
충격!! 이었다. '월화수목금토일'의 index를 정렬해주고 싶었으나, 가나다순으로 밖에 정렬이 되지 않아 어떻게 해야할지 고민했다.
굳이 정렬을 하지 않고, 인덱싱을 통해 원하는 순서대로 데이터를 가져온다. 우리가 원하는 순서를 리스트로 만들어 인덱싱에 사용하면 된다. ...!
series[list('월화수목금토일')]와.. 와..와.... 이런걸 할수가 있구나.. 라는 생각밖에 안들더라..!
정렬을 못하겠으면, 인덱싱하자. 기억해놓자!
더 생각해 볼 것?
- 수업 중, wiki에 있는 나스닥 상위 종목 table을 수집해 fdr과 함께 사용하여 시각화하는 등의 예시를 말하셨다. 그런 주제를 찾아내서 실습을 해보고 싶다.
- plotly 혹은 seaborn 등의 Gallery에 있는 그래프들을 둘러보며, 데이터에 원하는 시각화를 정해 실습 연습을 하라고 하셨다. 아주 좋은 것 같다.
- 데이콘이나 캐글 등에 공유되어 있는 EDA 과정을 많이 읽어보며 감을 익히라고 하셨다. 그래야겠다.
- 데이터사이언스스쿨 : 처음에 seaborn 배울때는 이게 뭔지 하나도 이해가 안되었는데, 많이 반복하다보니 이해가 된다. 주말 쯤에 다시 한번 정리하며 어떤 형식의 데이터를 시각화 할때 어떤 그래프를 사용할 수 있는지 익혀야겠다.
끝!
뭔가 많이 배웠다. 오늘은 수업 듣는데 실습이 많아서인지 시간이 그래도 좀 가더라. 근데 정신은 하나도 없었다.
오늘 일찍 시작했는데 왜 또 12시일까!
더 공부해 볼 주제를 강사님이 많이 던져주시는데, 어떻게 시간을 내서 해야할지 고민이다. 복습 시간이 너무 오래든다! 실습을 해봐야 하는데!
