22.10.11
오랜만에 수업 듣는 기분!
오늘은 지난시간에 이어서 마저 EDA수업을 들었다.
정리해보자!
아주 엉망이 되었다. 오늘 꽝이다 완전! 이상한 aggfunc 뭐시기 좀 찾아보겠다고 설치다가 시간 다 써먹고 대강 정리했다. 내일 다시 찬찬히 살펴봐야 할 듯... 복습하다가 멘탈이 나갔ㄷ.
여러가지 실습을 해가면서 공부를 해보려 한건 긍정적인데, 방법이 완전히 잘못된듯! 성과가 없었다. 다 포기하거나 실패!
공부할 때 내가 뭘 하고 있는지, 어떻게 하고 있는지 항상 생각하며 하자고 다짐하는데, 안중에도 없게 되었다. 정신이 좀 나갔네?
str 접근자와 정규표현식
str 접근자로 series에 str method를 사용할 수 있었다.
오늘 실습에서는 replace method를 사용하는 것이 나왔다. 이때 인상깊었던 내용이 regex = True 인자를 넣어주어 정규표현식을 사용할 수 있다는 것이었다!
정규표현식에 대해서는 0주차 때 살짝 공부했었고, 곧 또 한다고 한다.
일단 이 정도 기본 문법을 알아두자!
출처 : 위키백과
두 개 이상 변수의 빈도수 보기
- crosstab
- pivot_table
한가지 변수의 빈도를 볼 때에는 value_counts()를 이용했지만, 두 가지 변수에 대해 빈도를 볼 때에는 crosstab이나 pivot table을 사용한다.
비율 구하기
normalize : 전체에 대한 요소의 비율로 나타내는 것.
확진자 중 해외 접촉력이 있는 확진자의 비율을 구하는 실습을 했었다. 우리가 원하는 건 각 지역구별 해외 확진자의 비율이었다.
이를 구하기 위해서 과제할 때 normalize = True를 사용했는데, 그러면 우리가 원하는 거주구별 해외유입 비율을 얻는것이 아니다.
normalize 한 결과 값은 전체에 대한 각 요소의 비율을 나타낸다. 예를 들어 index가 강남구, column이 국내인 요소를 normalize 하면, 전체 요소의 총 합중 해당 요소의 비율을 표시한다.
우리가 원하는 비율을 구하기 위해서는 직접 계산을 통해 얻어내는 방법 밖에 없다! 이렇게!
gu_oversea.loc['비율'] = (gu_oversea.loc['해외'] / (gu_oversea.loc['국내'] + gu_oversea.loc['해외'])) * 100다양한 스타일 적용
.style.background_gradient()
.style.bar()
이건 처음보는 거! 좀 제대로 정리해볼까 싶은데 정리할 것이 딱히 없다.
데이터프레임에 해당 코드들을 사용하면 해당 스타일들을 적용시켜준다. cmap을 지정하여 색상도 변화시킬 수 있다.
시각화
df.plot()
stacked = True -> 여러 컬럼의 값 누적하여 그리기
transpose? x 및 y 지정하는 방법시각화에서는 저걸 찾아보고 싶었다.
df.plot.bar() 해서 그래프를 그리는데, 자꾸 내가 원하는 값이 x가 아닌 다른 값이 x축에 나오고, 어떻게 설정하는지는 모르겠고, 결국 .T하여 그렸었다.
근데 강사님도 .T하여 그려서 x와 y위치 바꾸시더라! 그렇게 해도 되는거라는 안도감을 얻었다.
그래도 좀 찾아봤다. 공식문서
봐도 아무것도 모르겠다..ㅎ 자세하진 않네...
x나 hue 등이 정해지는 원리에 대해 알고싶었는데. 이건 matplotlib을 공부해야 알 수 있을 듯 싶다. 뭐 찾아보면서 공부하기도 어렵네.. 구글링이 능력이라는 이유를 실감한다. 연습하자!
실습하면서 느끼고 정리한 것.
기본적으로는 index를 x축으로 하여 각 컬럼의 값들을 그린다고 생각하면 되겠다. subplots = True를 해주지 않으면, 하나의 그래프 안에 여러 그래프를 겹쳐 그린다.
x나 y값에는 특정 column이 들어갈 수 있다.
지금 내가 그리고 있는 자료가 이건데,

오늘 오후에 배운 것처럼 tidy 한 형태가 아니어서 그리기가 좀 어려운 것이다. 좀 헷갈리고!
tidy 데이터에 대해서는 x에 특정 컬럼이 들어갈 수 있다고 생각하면 되겠다.
x : label or position, default None
Only used if data is a DataFrame.
아 뭐지 되게 헷갈리네... df를 시각화할 일이 뭐가 있지 보통 어떤 형태의 데이터프레임을 시각화하는걸까?
생각해보기 위해 실습을 해보았다.
pivot table로 월, 요일에 대해 환자 수와 사망 수를 나타내는 df를 만들었다.
사망한 환자를 나타내기 위해 사망 컬럼을 추가하여 퇴원여부 = 사망인 경우에만 True로, 나머지는 Null이 되게 하였다.
이것도 고난이었는데, 강사님이 오늘 파생변수 만드실 때 사용한 코드를 응용할 수 있었다.
df.loc[(df['퇴원현황'] == '사망'),"사망"] = "사망"
df.loc[~(df['퇴원현황'] == '사망'),"사망"] = np.nanpivot_table을 통해 df를 만들었다.
test = pd.pivot_table(data = df,index = df['연도'], columns = df['요일'], values = ['환자','사망'], aggfunc = 'count')melt를 이용해 원하는 형태의 데이터로 만들었다.
melt 아직 안배워서 찾아보며 해보자..
test = test.stack()아아 안된다... 컬럼이 멀티인덱스네 무슨..
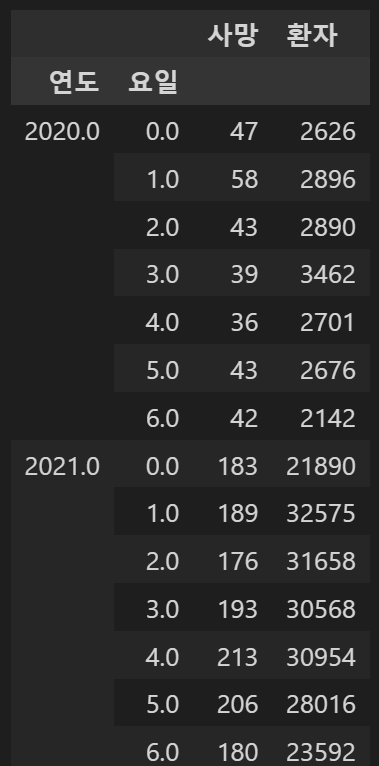
아 못하겠다 일단 포기... 나중에 마저 하자.. 나중이 언제일까,,?
오늘 공부 망했네! ㅋㅋㅋ
저거 말고 원래 그래프 그리던 위에 자료를 melt로 월을 컬럼으로 만들 수 있을까? 아 다른 인덱스가 있어서 안되겠다. 피봇테이블 말고 다른 데이터프레임이 없나?????
0106 실습파일로 돌아왔다. mpg 를 pandas로 시각화해보자.
그냥 하니까, 위에서 말했던 것과 같이 x축에는 index가 들어가고 각각의 column들은 그래프로 그려진다. 이렇게까지는 꽉 잡아놓자. 헷갈릴 것 없다.
y에 특정 컬럼을 지정하면 모든 index에 대해 그 컬럼 값만 그려진다. 당연하지! series를 그리는 거랑 같은거다.
x에 특정 컬럼을 지정하면? 그 컬럼의 데이터 들에 해당하는 값들이 x 축에 나오고 해당 데이터에 해당하는 다른 컬럼 값들이 그래프로 그려진다.
x와 y에 각각 컬럼을 지정하면? x 컬럼에 해당하는 y 컬럼의 값이 그려진다.
이렇게 그려지는 것이다! 뭐한거지? 잘 모르겠는데 흠.. 어쨌든 조금 이해가 되었다. x나 y에 특정 컬럼을 지정할 수 있다는 것!
맨 위에서 우리가 피봇테이블을 그래프로 그렸을때에는 각 월(1,2,3,,,12)가 컬럼인 데이터 형태였기에 그리기 편하지는 않았던 것!
인덱스인 연도(2020,2021)이 x축에 나왔고! 근데 보기에 편하지 않았으므로 transpose로 x축에 나오는 값을 월들(column들 -> transpose하여 index가 됨 -> x축에 표시)가 x축에 나오게 해주었고!
여기서 transpose 하지 않고 x축에 들어갈 데이터를 지정해주는 방법으로 우리가 원하던 그래프를 그리는 방법은 없었다!
이해가 조금 된 것 같다. 다행!
group by
멀티 인덱스 사용 가능
unstack으로 컬럼으로 바꿀 수 있다.tidy data
행이 관측치, 열이 변수의 형태로 되어있는 데이터.
분석 및 시각화를 하기에 적합하다.
long-form 형태와 wide-form 형태의 데이터 중 long-form서로 다른 데이터셋 연결하기
다양한 처리를 해준 후 연결한다.
컬럼의 이름을 맞춰주고, dtype들도 맞춰주고, 들어가는 값들도 맞춰주고!타입 변경하기
astype을 사용할 수도 있고,
error를 무시하기 위해서는 수치형으로 변경시 pd.to_numeric을 사용한다.
astype의 errors 는 coerce가 없고, ignore가 있어서 강제로 에러를 무시하고 수치형으로 변경할 수가 없다. astype을 사용하려면 에러가 날만한 데이터들을 전처리해준 후 사용해야 한다.컬럼 삭제하기
drop을 사용한다.
column 삭제시 .drop(columns = ' ')와 같이 사용실습파일 0303
실습 내용
0303 파일의 나머지에서 실습한 내용들은 다양한 전처리 및 pandas의 api들을 사용해 서울시 코로나 19 발생동향 데이터에 대해 EDA를 해보는 내용이었다.
실습 과정
- 거주지를 전처리하여 빈도수를 파악하고 시각화.
- 두 개의 변수에 대해 빈도수 구하기
- boolean indexing 이용해 특정 조건에 대한 값 찾기
- 파생변수로 새로운 컬럼 만든 후 두 개의 변수에 대한 빈도 구하기
- group by 사용하여 데이터 살펴보기
이다.
배운 것들
- 데이터 정제하기(?)
뭐라고 표현해야할까? 값 들 중 양옆에 이상하게 공백이 붙어있거나 특수문자 등이 끼어있어 데이터를 제대로 살펴보지 못하는 경우에, 공백이나 특수문자를 제거하는 등의 방법으로 처리를 해준다.
EDA에서 가장 중요한 것 중 하나인 것 같다. 이런 전처리를 하며 데이터를 잘 살펴보는게 EDA인 것 같고!
우리 실습에서는, 거주지 column의 타시도라는 값이 양 옆에 공백이 있는 값, 없는 값 등 여러개로 나누어져 있었고, 기타라는 값까지 존재해 같은 범주가 여러개의 범주로 나누어져 있었다.
따라서 이를 처리해주기 위해 새 column을 만든 후 처리한 데이터를 넣어주었다.
df["거주구"] = df['거주지'].copy()
df['거주구'] = df['거주구'].str.strip()
df['거주구'] = df['거주구'].str.replace('타시도','기타')
이렇게!
- 두 개의 변수에 대한 빈도수 구하기
crosstab, pivot_table, groupby를 사용할 수 있다. 사실 셋이 거의 근본적으로는 동일한 기능이다.
crosstab의 경우 빈도수를 파악하기 쉬우며, pivot_table의 경우 집계함수를 적용한 값을 보기 쉽다.
group by는 멀티 인덱스 형태로 데이터프레임을 볼 수 있게 해주기도 한다.
두 변수에 대해 빈도수를 구한 후에, 시각화를 할때에 transpose 등을 이용해 알아보기 쉬운 형태로 시각화하자!
이렇게!
year_month.T.plot(kind = 'bar', rot = 0);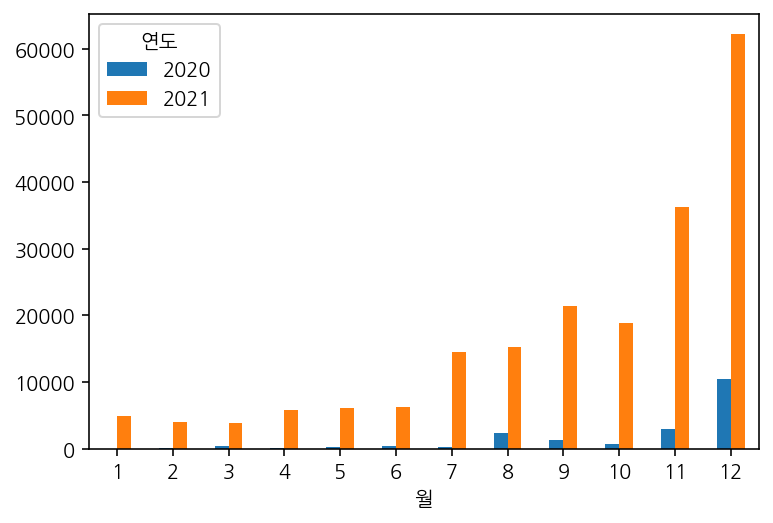
기본적으로 index인 연도가 x축으로 되어있었으나, 시각화의 목적에 맞게 한눈에 알아보고 비교하기 쉽도록 transpose하여 시각화 해주었다.
crosstab이나 pivot_table 등의 경우 .style을 통해 여러 스타일을 적용할 수도 있다.
역시 transpose를 통해 적절한 형태로 표현하자.
- boolean indexing
데이터프레임에 조건을 걸어 특정 데이터들을 가져오고 싶을때, loc을 이용할 수도 있고 안하고 그냥 인덱싱할수도 있다.
loc을 이용할 경우, .loc[조건, 열]의 형태로 조건에 맞는 컬럼만 표시하기에 적합하고 빠르다.
시간은 코드 앞에 %timeit을 써주어 측정할 수 있다.
- pivot_table의 aggfunc
추가 공부하며 과제에서 틀렸던 걸 알게 되었다!
틀린게 아닌가보다! 어렵다! 아주!
일단 이걸 알기 위해서는
size, len, count 세 함수가 어떻게 다른지 알아야겠다.
df.count() 의 경우, 데이터프레임에 적용되어 각각의 column 또는 행에 대해 non-NA값을 세어준다. 시리즈에도 적용할 수 있다.
len(df)의 경우, 다양한 sequence 객체들, 심지어 series나 데이터프레임에도 적용되어 NA값을 포함한 총 길이, 요소의 총 개수를 세어준다. 실험해봤더니, 가장 긴 컬럼의 길이를 세어준다!
df.size의 경우, 메소드가 아닌 attribute 인 듯하다. Return the number of rows if Series라고만 나와있다. null 값을 포함하여 세는지, 안세는지 알아보기 위해 해봤더니 포함한다. null 값을 포함한 총 길이이다. numpy 에는 size() 라는 함수가 있다.
돌아와서! pivot table을 만드는 실습과제에서 이렇게 했었다.
df.pivot_table(index = '거주구',columns = '해외유입',values = '환자', aggfunc = 'count')수업에서 강사님도 이렇게 하셨다.
과제할 때에는 이게 뭔가 불편해서 다른 방법도 찾아보았다.
df.pivot_table(index = '거주구',columns = '해외유입',aggfunc = 'size')어디선가 본 피봇테이블의 예시에서 이렇게 values를 지정해주지 않고, aggfunc를 size로 하여 도수를 구하길래 나도 그렇게 해보았다.
그런데 위에서 함수들의 기능을 살펴본 지금 생각해보자. 만약, 해외유입 컬럼에 NULL 값이 있다면? 그럼 size function의 경우 NULL 값을 포함해서 세주고, count는 그렇지 않을텐데 도수가 달라지는게 아닌가?
근데 실습을 해보니, 아니다 안달라진다.
columns를 해외유입으로 했지만, aggfunc를 size로 했을 때, 피봇테이블의 컬럼에 Nan이 생기지 않는다!
-> 피봇테이블에서 size를 aggfunc로 사용할 때, NaN값은 세지 않는다!
그럼 당연히 다른 column들의 size는 size로 할 때나, count로 할때나 동일할테니, 결과에 영향을 미치지 않는다.
결론적으로, pivot table을 도수를 구해 보기 위해 사용할 때,values 지정 없이 aggfunc = 'size'로 지정해주어도 된다.
근데 적당한 values 지정하고 count로 aggfunc 하는것이 마음이 편하겠다..!
아니 그냥 두개 변수에 대한 도수 볼때는 crosstab 쓰련다..!
머리가 아프다...!
추가. len으로 하다 발생한 오류에서 aggfunc는 DataFrameGroupBy에 대해 적용되는 함수임을 알았다. 거기 적용되는 size 함수에 대해 찾아보았다. 함수가 있다! 링크 뭔소린지는 잘 모르겠다 ㅠㅠ
내가 뭘 하고 있는거지..? 정신차리자!
함수 설명을 보니 그룹화된 각 그룹들에 대해서 true이거나 false 인 값들을 세준다. 라고 나와 있다.
그럼 중요한건... NaN값이 피봇테이블의 컬럼으로 들어가기도 하느냐 마느냐의 문제!인걸로 하고싶지만.. 막 찾아보다가 이상한 소리를 한 것 같고... 관련해서 데이터프레임에 컬럼에는 nan 값이 들어갈 수 없는가? 를 해봤는데 들어가진다! 더이상 모르겠어요 포기할게요... 너무 늦었어요... 할게 많아요...
column에 ['해외유입', np.nan]을 넣어보았는데 에러가 나오는 걸로 보아 피봇테이블의 컬럼에는 nan 값이 들어가지 않는다!
그렇다면 nan 값도 세주어 문제가 될 뻔 했던 size() function을 aggfunc로 넣어주어도 도수를 세는데 문제가 없다!
정리해서, 결론적으로는 size 함수를 이용해도 두 개의 변수에 대한 도수를 구할 수 있다...!
그런데 그냥 crosstab 사용하자...!
이다!
-
정렬 못하겠을때?
인덱싱하자! 지난주에도 했던 내용 -
group by
group by를 이용해 그룹화 한 후에도 describe를 사용할 수 있다. 사실 똑같이 데이터프레임이니 당연하겠다!
실습파일 0404
실습 내용
전국 신규 민간아파트 분양가격 동향에 대한 EDA를 진행한다. 이때, 데이터가 두개의 데이터파일로 나누어져 있는데, 두 데이터의 구조가 아예 달라 합치는 방법을 배운다.
실습 과정
1) 예전 데이터 : 2013~2015 연도와 월을 컬럼으로 만들어줍니다. (최근 데이터와 같은 형태로)
2) 최근 데이터 : 제곱미터당 평균 분양가격을 3.3 제곱미터당 가격으로 변경하고, 전용면적을 전체만 사용한다.
3) 두 데이터를 concat으로 병합하여 하나로 만든다.
4) 분석한다.
배운 것들
- glob
지난 주에도 배웠듯이, 정규표현식을 사용하여 파일의 경로를 찾아주는 라이브러리. 파일을 불러올때 이름을 직접 다 치다보면 오타가 나는 등의 오류가 발생하는 경우가 많다.
따라서 파일 경로에 대한 변수를 하나 만들고, glob을 이용하여 변수에 정보를 담아준뒤 파일을 읽으면 좋다.
from glob import glob
file_paths = sorted(glob('data/apt*.csv'))
df_last = pd.read_csv(file_paths[1], encoding = 'cp949')-
데이터 타입 변경
astype 뿐 아니라 pd.to_numeric 으로 수치형으로 바꿀 수도 있다. error를 무시하고 진행하기에는 pd.to_numeric이 편하다. 이거 때문에도 수업시간에 한참 애먹었었다!
astype의 errors = 'ignore'의 경우 오류가 나는 것들은 변환시키지 않는다.
to_numeric의 errors = 'coerce'의 경우 오류가 나면 nan 값으로 바꾸어준다! -
컬럼 이름 바꿔주기
단순히 컬럼의 이름을 바꾸는 것이 아니라, 메모리를 효율적으로 쓸 수 있도록 변경한다. 예를들어 규모구분 컬럼의 값들이 전용면적 몇 이하, 전용면적 몇 이상 등으로 모두 전용면적이라는 단어를 포함하고 있다면, 전용면적이라는 컬럼을 만든다. 그리고 str 접근자를 사용하여 값들에서 전용면적이라는 단어를 삭제하여 그 값을 전용면적 컬럼에 저장한다.
그 후 규모구분 컬럼은 삭제한다.
다음과 같다.
df_last['전용면적'] = df_last['규모구분'].str.replace("전용면적|제곱미터이하", "", regex = True)
df_last['전용면적'] = df_last['전용면적'].str.replace("제곱미터초과","~")
df_last['전용면적'] = df_last['전용면적'].str.replace(" ","")
df_last[['규모구분','전용면적']]더 알아볼 것들
- pandas의 시각화에 대해서 더 생각해보고, 실습을 꼭 해보자. 실습! 실습! 실습! (어떤 때에 사용하는지, 어떤 데이터에 대해 사용하는지, 어떻게 사용하는지.......)
뭐지... 망했다..! 다 못했다...!
피봇테이블의 aggfunc에 size를 넣어도 될지 찾아보느라 엄청 오래걸렸다. 결론은 내렸는데, 근거가 없다...! 뭐지 내가 뭘 하고 있는지도 모르겠고 파이썬이고 판다스고 너무 어렵구만 ㅠㅠ
나머지 정리는 내일 해야할 듯 싶다ㅠㅠ
아니다 일단 대강이라도 오늘 끝내고 자자.. 대강 끝냈다.
총평? 망했다. 몇몇 내용 공부 하느라 전체적으로 꼼꼼한 복습을 못했다. 심지어 몇몇 내용도 횡설수설에 완결짓지 못했다. 최악인데? 슬픈건 복습 열심히 했다고 생각하는데 멘탈이 나가니까 여태껏 공부했던 내용도 하나도 모르겠다는 것..! 특히 시각화 ㅠㅠ
그래도 열심히 찾아보고 코드도 쳐보며 공부하려 했다는 것.. 긍정! 긍정! 긍정! 원래 공부 열심히 하다보면 멘탈 나가는 날도 있고 그런거 아니겠어! 크게 보자! 그래도 나름 해야될건 다 했다!
