일단 어제 회고부터! 아쉬운 점이 많았다.
어제 아쉬웠던 점
어제 아주 공부하다가 멘탈을 놨다. 늦게까지 했다가 오늘 하루종일 정신도 못차렸다.
방법적 측면
- 침착하지 못함
침착하게 멘탈을 잡고, 차근차근히 공부를 했어야 하는데 그러지 못했다.
모르는 것을 공부하다보면 당연히 깊이, 더 깊이 들어가야만 알 수 있는 것들이 있고, 깊이 들어가다보면 내용도 어렵고 생소해 내가 지금 뭘 공부하는지를 잊고 막 휩쓸려 공부하게 될 수 있다. 그래도 침착하고 내가 무엇을 몰라서 어떻게 공부하고 있는지를 생각하고, 너무 깊이 들어가는 부분은 처음 공부하는거니만큼 이런게 있구나만 받아들이고 넘어갈 수 있어야 했을 것 같다!
- 실습을 하려 해도..
판다스의 시각화나, 피봇테이블의 aggfunc을 어떻게 사용하는지 잘 모르겠어서 코드를 실행해보며 알아보려 했다. 거기까진 좋았다.
근데 너무 막무가내로 진행했다.
내가 무엇을 모르겠어서, 어떤 내용의 코드를 어떻게 짜서 실행해보며 어떤 내용을 파악해보겠다. 를 정해놓고 실습을 진행했으면 좋았을 것 같다.
내용적 측면
- pivot_table은 결국 group by이다. 피봇테이블에 대해 제대로 이해하지 못함!
결국 pivot table은 group by를 멀티 인덱스를 통해 한 후 unstack한 것과 같은 형태이다. 그러니까 size 함수를 어떻게 쓸 수 있는지 궁금하면 groupby 하여 size 함수를 사용해보면 되는것이다. df.groupby(['거주구','요일명']).size() 이 코드가 제대로 동작하는지 확인하고, 동작한다면 피봇테이블에 values 값 없이 size 함수만 써도 빈도수를 제대로 구하는 것임을 알 수 있다. 지금 코드를 돌려 확인해보니, group by 하여 size 함수를 사용하면 각 그룹별로 가장 긴 행의 길이를 알려준다.
그리고 뭐가 문제였을까? size가 count와는 달리 null 값도 포함하기 때문에 size를 써도 될지 고민이었던 건데.. null 값이 있는 데이터도 데이터 아닌가? 어쨌든 pivot table이 만들어졌다는 것은, 피봇테이블 내의 포함된 데이터들은 우리가 그룹화하여 빈도수를 알길 원하는 변수들은 null 값이 아니라는 거다. 그럼 다른 변수에 null 값이 존재하던 존재하지 않던 빈도수엔 포함하는게 맞지 않나? 이렇게 해결이 된 것 같다. 그냥 써도 된다!
그래도 좋은 경험이었다. 모르는게 많으니 열심히 공부해야겠다는 생각이 팍팍 든다!
오늘 수업중에서도 시각화 실습에서 막힌 부분이 있어, 오늘도 간단히 정리하고 시각화를 한번 처음부터 공부해보자.
0304 실습파일(여러 데이터 파일 이용하기)
실습내용
어제에 이어서 전국 신규 민간아파트 분양가격 동향의 분석.
서로 다른 두 데이터파일을 합치기 위한 작업을 한 후 합친다.
실습 과정
<어제에 이이서>
1. 최근 데이터의 처리를 마쳤으니 지난 데이터 파일을 처리해준다. concat을 통해 합칠 수 있도록 컬럼과 그 안에 들어가는 값들을 맞춰준다.
2. 그러기 위해서 melt를 통해 컬럼에 있는 날짜(연월)정보를 연, 월 의 컬럼과 그 안의 데이터들로 바꾸어준다.
3. 합칠때 사용할 컬럼들만 따로 뽑아내어 합칠 준비를 완료한다.
4. concat을 이용해 두 데이터프레임을 합친다.
0305 실습파일(kosis 데이터 EDA)
실습내용
kosis(국가통계포털)에서 받을 수 있는 데이터 하나를 EDA해보는 실습이다.
파일을 읽는것부터, tidy data로 만드는 등의 전처리, 텍스트 전처리 등의 과정과 각종 통계값을 보는 것, 시각화하여 확인하는 것까지 해보았다.
실습 과정
-
파일 읽어오기(glob 이용하여 경로 list 얻어 사용)
-
데이터 확인하기(미리보기, 결측치, 정보확인, 중복확인 등)
-
tidy data로 만들기(melt 이용)
-
텍스트 전처리(텍스트를 정규표현식 이용하여 전처리)
-
특정 컬럼 처리(다른 범주의 두 데이터가 한 컬럼에 들어있어 나누어준다.)
-
기술통계값 확인
-
시각화
오늘 배운 것들
- pandas의 옵션
pd.options.display.max_columns = None 해당 코드를 통해 출력될 컬럼의 최대 개수를 설정할 수 있다. 문서
pd.pd.describe_option()을 실행하면 설정 가능한 다양한 옵션들과 사용법이 출력된다.
컬럼의 개수가 너무 많아 다 표시하기에 메모리상 한계가 있을때 사용하면 좋다.
컬럼을 녹여내려서 데이터프레임 내부의 값으로 만들어주는 함수.
tidy data를 만들기 위해 많이 사용한다. 전에 배웠듯이, tidy data란 각 행이 관측값이고, 각 열이 변수인 데이터를 말한다.
우리 실습에서는 컬럼에 날짜가 들어가있었다. 2018-01 2018-02 ... 이렇게! 이 날짜들을 컬럼으로 두지 않고 '날짜'라는 컬럼의 값으로 두어야 깔끔한 데이터가 될 수 있으며, 최근 데이터와 합칠 수 있기에 melt를 사용했다.
이렇게 사용했다.
df_first_melt = pd.melt(df_first, id_vars = '지역') melt에 들어가는 다양한 인자들 중 가장 중요한 것 몇가지만 살펴보자.
id_vars : 이 인자는 컬럼들을 녹여내릴때, 녹이지 않고 기준열로 남길 컬럼을 의미한다.
value_vars : 해당 인자는 녹여내려서 값으로 만들어줄 컬럼을 의미한다.
melt를 사용하면, 여러 컬럼들을 녹여내려 값으로 만들어주게 되고, 데이터프레임에는 variable 컬럼과 value 컬럼이 만들어지게 된다.
variable 컬럼은 말그대로 변수 컬럼으로, 녹아내린 컬럼들 각각의 이름들이 값으로 들어간다.
value 컬럼은 값들이 들어가는 컬럼으로, 녹아내린 각 컬럼에 포함되어있던 값들이 여기에 들어간다.
결국 그럼 variable 컬럼과 value column 에는 녹아내린 컬럼의 개수 * df의 행의 개수 만큼의 행이 생겨 녹아내린 값들을 모두 표시해줄 것이라 생각할 수 있다.
그림으로 이해하면 쉽다.
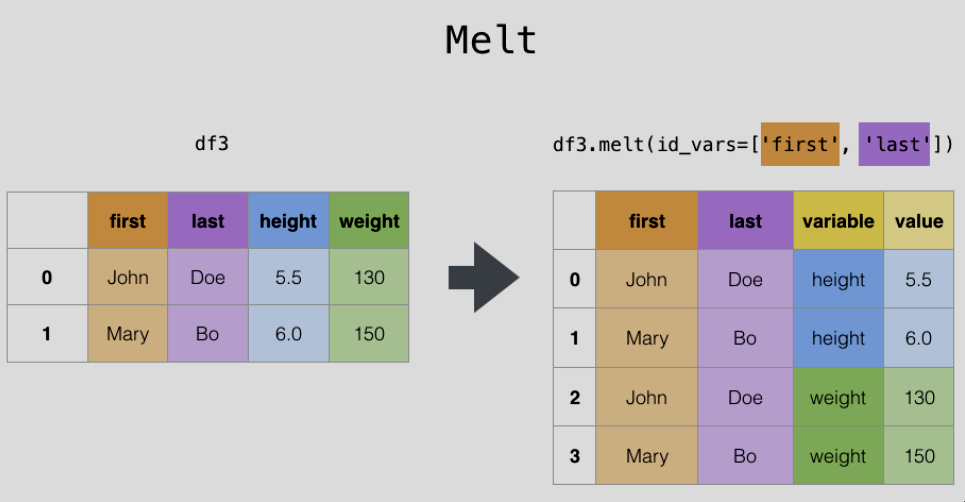
판다스 공식 문서에서 melt를 설명하고 있는 그림이다. first와 last를 기준 열로 하여 height와 weight라는 컬럼을 값으로 녹였고, 따라서 variable 컬럼에는 height와 weight라는 고유값이, value 컬럼에는 각 컬럼에 포함되어있던 값들이 들어가게 된다.
이때, variable와 value 컬럼의 이름을 melt 에서 지정해줄 수도 있다. 아래 인자들을 사용한다.
var_name, value_name 아래와 같이 사용한다.
df = pd.melt(raw, id_vars = cols, var_name = '연월', value_name = '달러')여기서 또 유의깊게 볼 점은, cols라는 변수에 melt 후 사용할 컬럼들을 리스트로 저장해두었다는 점이다. 컬럼을 리스트에 저장해 사용하면 편한 경우가 은근히 많은 것 같다!
melt에 대해서 확실하게 이해하고 넘어가자!
melt하면 여러 컬럼들을 데이터프레임의 값으로 바꿔준다.
이때 melt의 결과로는 두개의 컬럼이 생기는데 variance 컬럼에는 녹아내린 각 컬럼들의 이름이, value 컬럼에는 값들이 들어가게 된다.
이때, 원래 데이터프레임에서 표시하고 있던 원래 값들이 사라지지 않고 모두 생길 수 있도록 var과 value에 값이 생긴다. 따라서 한개의 컬럼만 녹아내린다면 원래의 데이터프레임과 행의 개수가 똑같겠지만, 두개의 컬럼이 녹아내리면 행의 개수가 두배가 된다.
결국 열을 녹여서 행을 추가하는 느낌의 함수이다.
언제 사용한다고? 주로 tidy data를 만들기 위해서 많이 사용한다.
- 파생변수 만들기
0304 실습에서는 melt로 녹여내린 날짜들을 연, 월로 분리해주며 파생변수를 만들었다.
이 외에도 이전까지 실습중에서 파생변수를 만드는 실습을 많이 했었다.
어떻게 했었는지 생각해보자.
- apply, map 등 이용하여 특정 컬럼에 함수 적용하여 파생변수 만들기
- loc를 활용해 조건에 따라 특정 값을 가지는 파생변수 만들기
- 접근자를 활용해 특정 컬럼(시리즈)에 함수 적용하여 파생변수 만들기
위와 같은 방법으로 만들어 본 것 같다. 세 방법 모두 활용할 수 있어야겠다.
먼저 apply나 map을 이용하는 방법이다.
0304에서의 예를 들어 이해해보자.
2018년12월 과 같은 형태를 띄고 있는 '날짜' 컬럼을 '연'과 '월' 컬럼으로 나누어야 한다.
이를 위해 날짜 컬럼에 apply를 통해 함수를 적용해주어 파생변수(연,월)을 만든다.
df_first_melt['연'] = df_first_melt['날짜'].apply(lambda x : int(x.split('년')[0]))
df_first_melt['월'] = df_first_melt['날짜'].apply(lambda x : int(x.split('년')[1].replace('월','')))위와 같이 apply와 lambda를 이용하여 만들 수 있다.
두 번째는 loc를 활용한 방법이다. 여기서는 적합하지 않고, 특정 조건에 따라 특정 값을 넣어주어야 할때 활용하면 좋다. 예로 전 실습에서 해외유입이라는 파생변수를 만들어 접촉력 column의 값에 따라 (bool) 해외 혹은 국내라는 값을 가지게 해 주었다.
세 번째는 접근자를 활용한 방법이다. 이 방법을 오늘 많이 연습한 것 같은데, 은근히 헷갈리는 부분이 많았다. 접근자를 활용해 특정 컬럼 전체에 메소드를 적용하고 이를 통해 새로운 컬럼을 생성하는 방법이었다.
이번 실습(0304)에서는 특정 문자(2018년12월 등)를 연과 월로 구분해야하니 문자열 메소드, str 접근자를 사용하여 이를 해낼 수 있었다.
다음과 같이 진행한다.
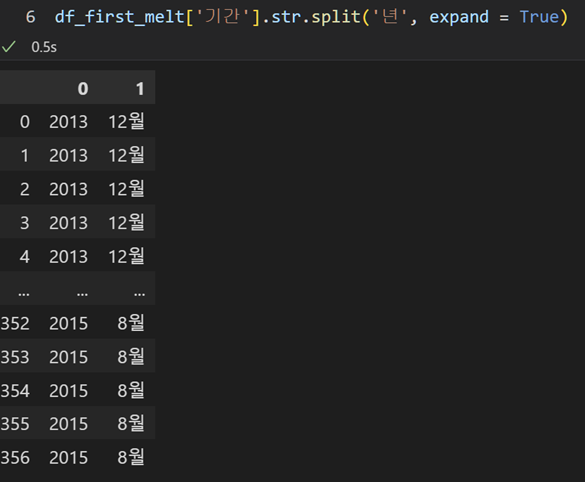
df_first_melt['연도'] = df_first_melt['날짜'].str.split('년',expand = True)[0]
df_first_melt['월'] = df_first_melt['날짜'].str.split('년',expand = True)[1].str[:-1]실수하기 쉬운 부분이 있었다. 바로 split의 expand 관련한 부분인데, expand = True를 넣어주지 않으면 위와 같이 동작하지 않는다. 이를 이해하기 위해 위 코드가 어떻게 동작한 건지를 이해해야 한다.
날짜라는 컬럼이 문자열(2018년12월 등)을 가지고 있는 컬럼이기에, 이를 '년'을 기준으로 split하여 연과 월의 컬럼을 만들고자 하였다. 따라서 str 접근자와 split을 이용한 것이 이해가 된다.
그런데 이때, series에 str.split을 적용할때 expand라는 인자를 줄 수가 있었다.
expand = False로 준다면 시리즈에 split을 적용한 결과는, 리스트들이 담겨있는 시리즈가 된다.
위에서는 [2018, 12월]등이 담겨있는 시리즈가 되는 것이다.
expand = True로 주면, 시리즈에 split을 적용했을때 나눠진 각 값들이 데이터프레임의 컬럼을 이루도록 한다. 위에선 0컬럼엔 연도 값들이, 1컬럼엔 월 값들이 모두 들어있는 데이터프레임이 split의 반환값이 되는 것이다.
따라서 [0]이라는 인덱싱을 통해 연도 값들이 들어있는 컬럼을 '연도'에, [1]이라는 인덱싱을 통해 월 값들이 들어있는 컬럼을 '월'에 저장한다. 그런데 이때, '월'이라는 글자를 다 빼주기 위해 월 컬럼은 str의 slicing으로 마지막 글자를 제외한다.
코드 실행결과는 다음과 같다.
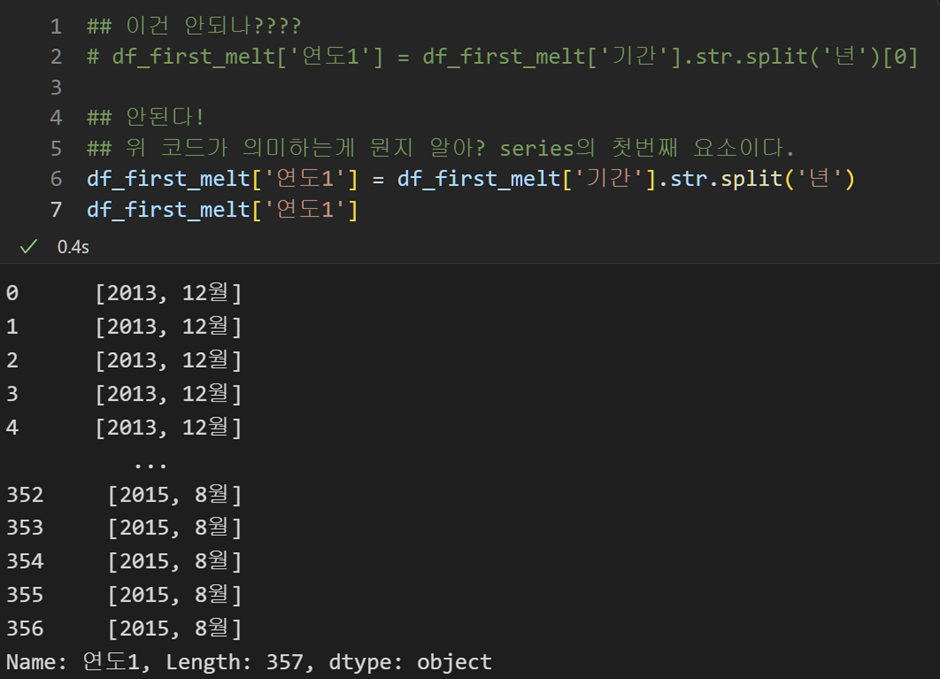
expand를 사용하지 않고 df_first_melt['연도1'] = df_first_melt['기간'].str.split('년')[0] 이렇게 쓴다는 것은, list들이 담겨있는 시리즈의 첫번째 요소, 즉 첫번째 리스트 [2018,12]를 선택하는 것 뿐이다.
그렇다면 expand = True를 사용하지 않으려면 어떻게 해야할까?
이렇게 하면 된다고 한다. 어떻게 이런 생각을 하지?
df_first_melt['연도'] = df_first_melt['날짜'].str.split('년').str[0]
df_first_melt['월'] = df_first_melt['날짜'].str.split('년',expand = True).str[1].str[:-1]expand를 사용하지 않아 시리즈의 각 요소들이 [연, 월] 형태의 리스트임을 인지하고, '연' 값들만 모두 가져오기 위해 접근자를 사용하여 시리즈 전체에서 각 행의 첫번째 요소만 가져오게 한 것이다.
접근자를 사용하지 않았을때의 인덱싱은 시리즈의 몇번째 인덱스를 가져올지 고르는 것에 불과했지만, 접근자를 사용하여 .str[0]을 함으로써 시리즈의 모든 요소의 첫번째 값을 선택, 결과가 시리즈가 되는 인덱싱을 할 수 있다.
- pivot table은 group by이다.
피봇테이블은 그룹바이를 편하게 사용하기 위해 만들어진 것이다.
따라서 그냥 그룹바이 기능 자체로도 사용할 수 있었다. 큰 의미는 없지만, 피봇테이블의 동작 방식을 이해하는데 좀 도움이 된 것 같다.
피봇테이블에서 index는 정해주고, column은 정해주지 않으면 오류가 날까? 아니다. 그냥 index에 대해서 그룹바이 한 결과를 출력한다.
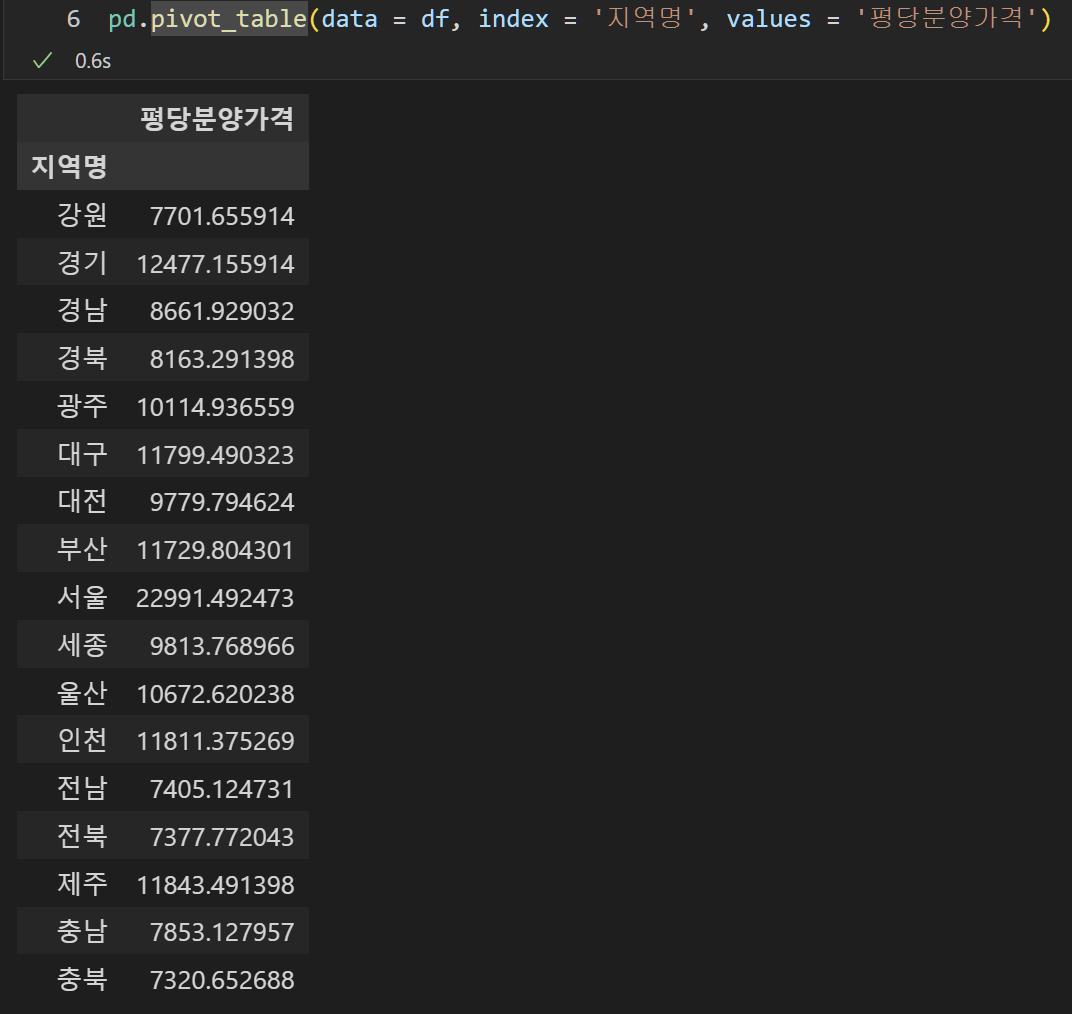
멀티 인덱싱 역시 가능하다.
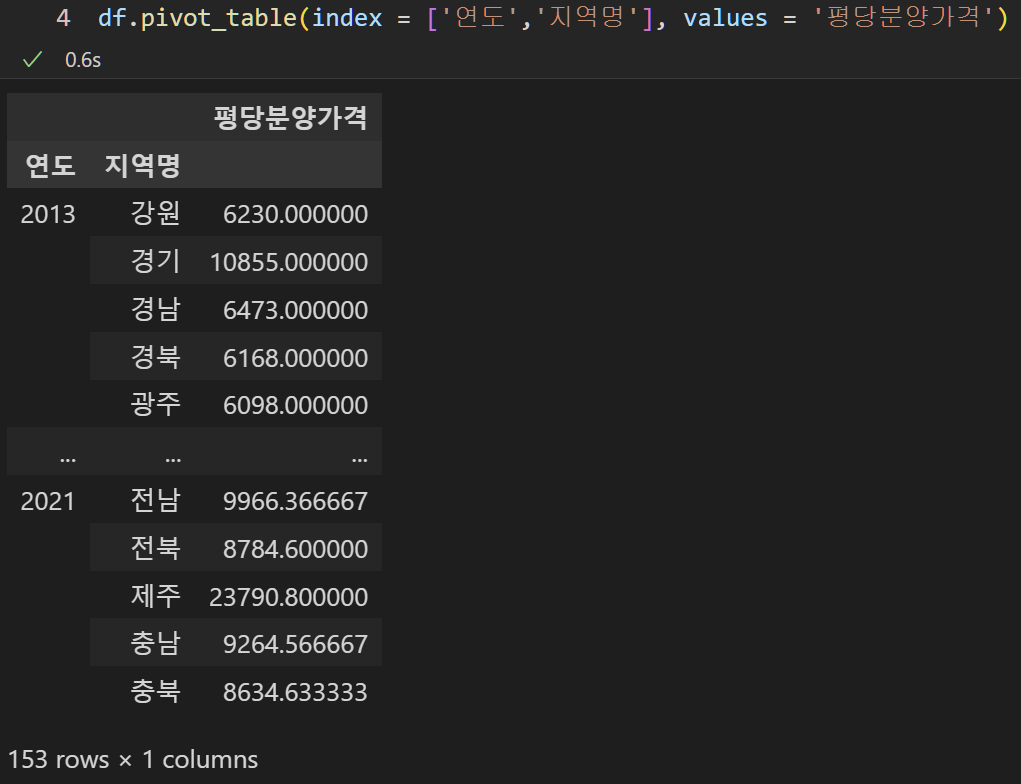
- pivot table의 시각화
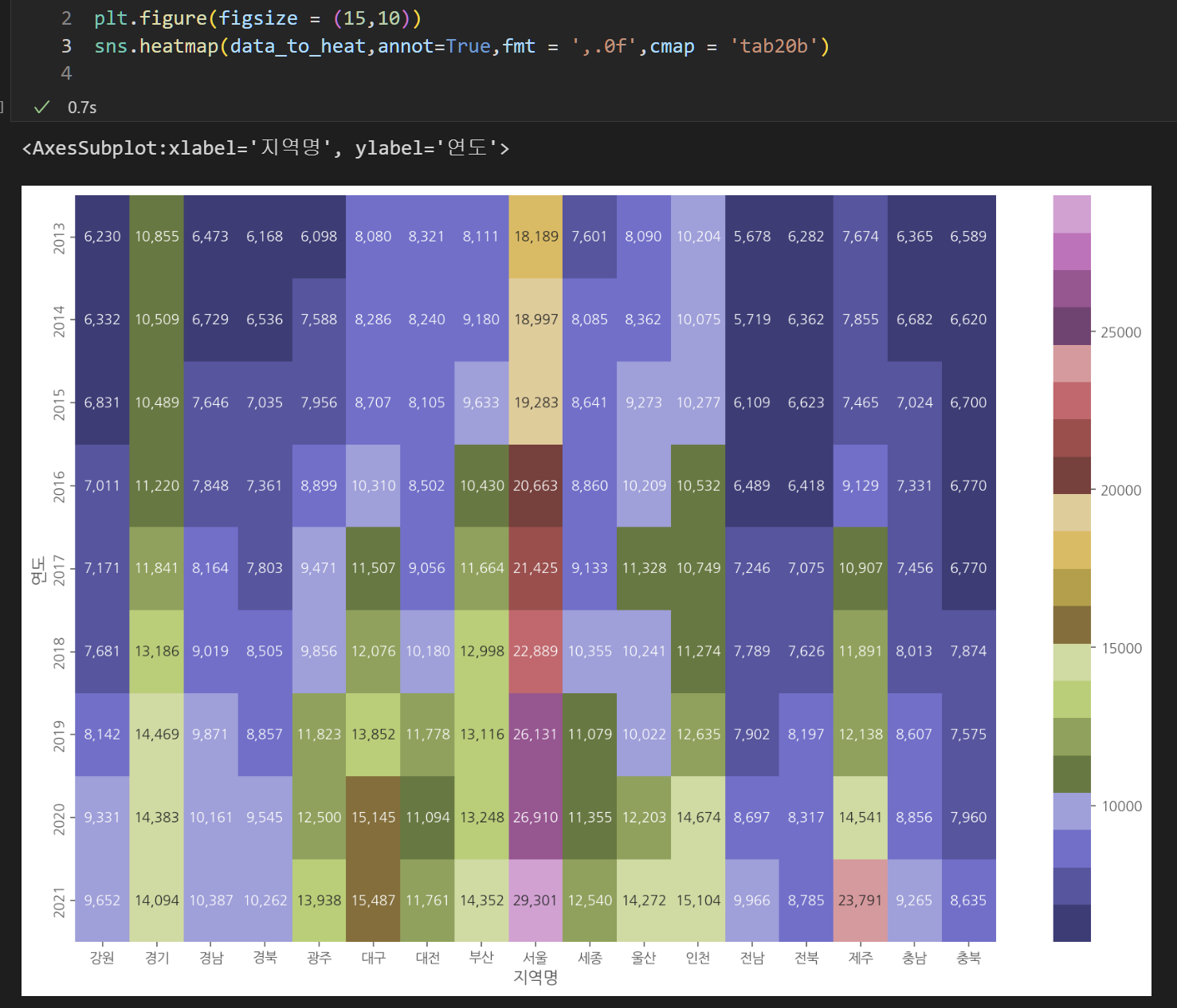
피봇테이블은 두 범주형 변수에 대해 빈도수를 체크하는 기능이었다. 따라서 피봇테이블을 시각화하기에 가장 적절한 기능은 바로 heatmap 이다.
다음과 같이 사용할 수 있다.
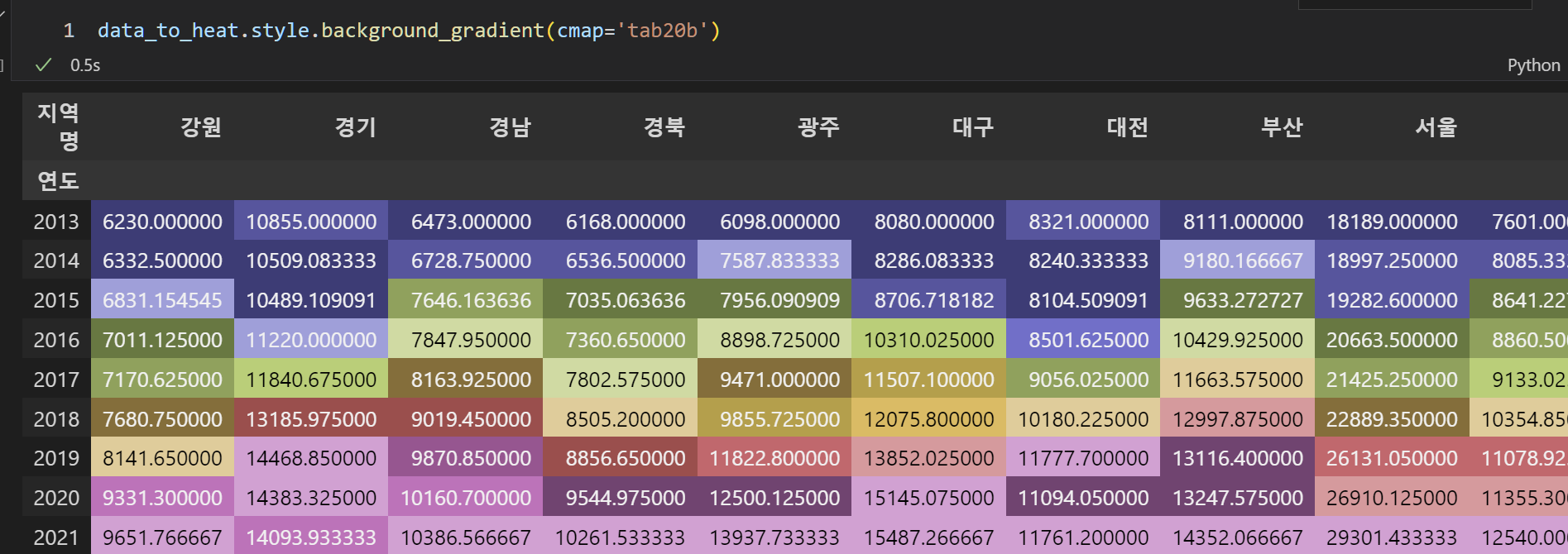
혹은 지난시간에 배운 바와 같이, style.backgroud_gradient()로도 시각화 한다고 생각할 수 있겠다.
- 어떤 그래프가 좋을까?
그때 그때 무슨 변수인지를 잘 생각하며 어떤 그래프로 시각화하는 것이 좋을지 고민해야함.
데이터의 분포를 보기 위해서는 violin plot을 가장 추천!
- 결측치 찾기
isnull().sum()으로 결측치의 개수를 확인할 수 있으나,
컬럼이 너무 많아서 어떤 컬럼에 결측치가 있는지 확인할 수 없을 때!
다음과 같이 사용할 수 있다.
raw.isnull().sum().sum() # 결측치의 총 개수 확인
sns.heatmap(raw.isnull(),cmap ='Greys') # 시각화하여 결측치 위치 확인
null_sum = raw.isnull().sum()
null_sum[null_sum > 0] # 결측치가 있는 컬럼 확인(boolean indexing 활용)
개인적으로 boolean indexing을 활용해 어떤 컬럼에 몇개의 결측치가 있는지 확인하는 세번째 방법이 인상깊었다. 조금만 생각하면 할 수 있을 것 같은데! 저런 생각을 해낼 수 있느냐가 문제!
- 정규표현식을 이용한 텍스트 전처리
공부하자면 끝이 없을 내용이라고 한다!
정규표현식을 텍스트 전처리에 사용할 수 있다.
정규표현식의 다양한 메타문자에 대해서는 다음을 참고하자. 이것도!
일단 기본적인 메타문자정도만 익히고, 실전에서 사용하며 점차 알아가는게 좋을 것 같다.
기본적으로 0주차에 공부했듯이, []는 안에 들어있는 문자열의 패턴을 의미하며, [0-9a-zA-Z]와 같이 사용하면 숫자 혹은 영어 문자가 매칭된다.
*은 0개 이상의 반복, +는 1개 이상의 반복을 의미한다.
^는 문자열의 시작, $는 문자열의 끝을 의미한다.
메타문자를 문자 그 자체로써 사용하고 싶다면 escape 문자 \를 사용한다.
어떠한 패턴을 문자 그 자체로 사용하겠다면 [문자열]이런식으로 사용하면 된다.
실습에서 한 예제를 살펴보면, 텍스트 컬럼에서 [$]라는 문자열을 제거해주고 싶다.
이때, replace의 regex = True로 하고, 정규표현식의 예외처리(escape 문자 사용)를 통해 어떻게 하는지를 해보았다.
df['항목'].str.replace('액\[[$]]','', regex = True)이렇게 하면 된단다!
사실 아주 여러가지 방법이 있고, 나왔다. 슬라이싱만 해도 되고, regex = False로 할 수도 있고,, 정규표현식을 연습하며 다양한 방법을 익혔다!
- 컬럼명 변경하기(rename)
드디어 rename으로 컬럼명을 변경해보았다. 여태까지는 컬럼 대부분의 이름을 바꾸었으므로 df.columns = [list]를 통해 다 바꾸어주었었다.
이번 실습에서는 두개 컬럼의 이름만 바꾸었고, rename을 다음과 같이 사용했다.
df = df.rename(columns={"국가및권역별": "국가권역", "전산업·소재부품장비산업별":"산업"})음.. 컬럼의 일부 이름만 바꿀 때에 rename 을 사용하면 좋을 것 같다!
- nlargest()
난 어제 처음봤는데, 강사님이 지난번에 한 적있다고 하셔서 당황했던 코드. 언제 했던걸까? 어쨌든 어제는 cheat sheet에서 본거였지만, 오늘은 직접 써보았다!
문서
컬럼에 사용하면 컬럼의 값 중 큰 n개만 보여준다. 유사하게 nsmallest도 존재한다.
정렬하고 head로 개수를 정해주는 번거로운 과정이 필요 없다!
- 데이터 처리 시 주의사항
평균을 구할 때에는 데이터 사이에 소계 등의 종합치가 끼어있지는 않은지 주의한다. 심각한 왜곡이 일어날 수 있다!
비슷하게, 우리 0305파일에서 국가권역이라는 컬럼 안에, 다양한 국가명도 존재하지만, 아시아등의 권역명도 존재한다.
이상태에서 국가권역에 대해 시각화를 하여 보게 된다면, 당연히 권역에 대한 값이 훨씬 크고, 다른 값들은 작아보이는 왜곡이 일어나게 된다.
따라서 데이터를 살펴볼때, 두 종류를 나누어 봐야한다.
실습에서 우리는 권역의 list를 만들어 boolean indexing을 이용해 두개의 데이터프레임으로 나누어 살펴봤다!
continent = ['아시아', '중동', '유럽', '북미', '중남미', '아프리카', '오세아니아',
'기타지역', 'EU(27)', 'OECD', 'ASEAN', 'LAIA', '선진국', 'OPEC', '개발도상국']
df_world = df[df['국가권역'].isin(continent)]
df_country = df[~df['국가권역'].isin(continent)]이렇게! 시각화를 할 때든, 상위 몇개 값을 볼때에든 분리하여 봐야 왜곡을 줄일 수 있다.
시각화
이게 영 안되네!
일단 시각화를 하는 데이터에 대해 좀 생각을 해볼 필요가 있겠다.
간단하고 작은 데이터 프레임 자체를 시각화 할 수도 있고,
데이터가 너무 많은 경우 여러 통계를 내어 그 통계를 시각화하는 경우가 있을 것이다!
이 두가지를 구분하지 않고 아무렇게나 시각화를 하려고 해서 안되었던 것도 있는 것 같다.
통계를 내어 시각화를 하려면, seaborn이나 plotly의 경우 그래프 자체에서 통계를 내어주는 기능을 하는 것도 있지만, pandas로 시각화를 하려는 경우 직접 통계를 내는 연산을 한 후 그 자료를 시각화해주어야 한다.
예를 들어, 0304파일에서 지역별 평당분양가격을 시각화한다고 하였을때, 어떻게 해야할까?
일단 생각을 해봐야겠다. 데이터프레임 자체가 연도별, 월별, 지역별, 평당 분양가격을 나타내고 있다.
따라서 지역별 평당분양가격을 시각화하기 위해 df.plot.bar(x='연도', y='평당분양가격')을 한다면... 각 월별, 지역별 모든 데이터를 표시하게 되어 알아볼 수 없는 데이터가 나오게 될 것이다. 애초에 데이터의 개수도 너무 많다.
다르게 생각하면, 연도라는 것 자체가 범주형 변수이다. 범주형 변수에 대해 그래프를 그리겠다는 것 자체가, 집계함수를 이용해 특정 통계값을 알아내어 그걸 그래프로 그리겠다는 것이다.
따라서 지역별로 평당분양가격의 평균을 그리겠다고 결정하게 될 것이다. 판다스를 이용해 그래프를 그리겠다면, 지역에 따라 그룹화를 해준 후 평당분양가격에 대해 집계함수로 mean을 이용한 데이터프레임을 이용해 그릴 수 있다. 다음과 같다.
df.groupby('지역명')['평당분양가격'].mean().sort_values(ascending = False).plot.bar(rot = 0, title = "2013년도 ~ 평균 평당분양가격")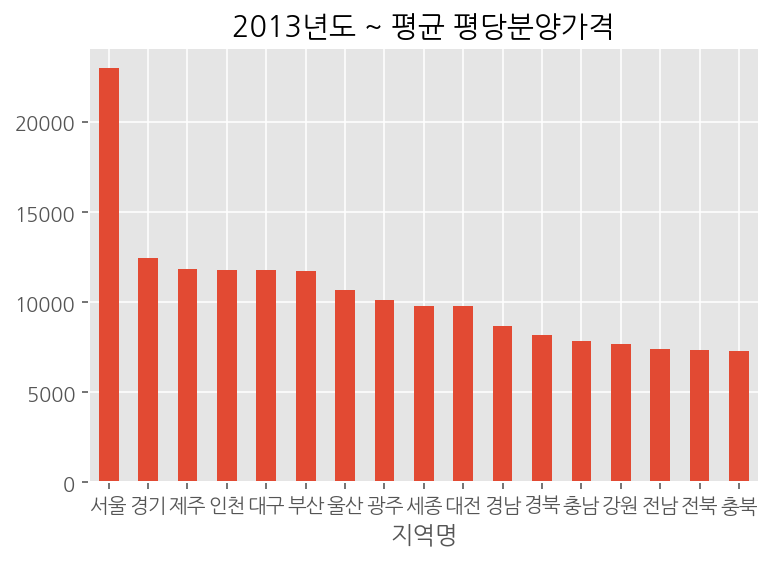
데이터를 시각화해 그릴때, 정렬되어 있는 순서대로 그려짐 역시 기억하자.
seaborn을 이용하면 통계함수를 그래프 내에서 적용하므로 쉽게 그릴 수 있다. barplot을 이용한다.
sns.barplot(data=df, x='지역명',y='평당분양가격',ci = None)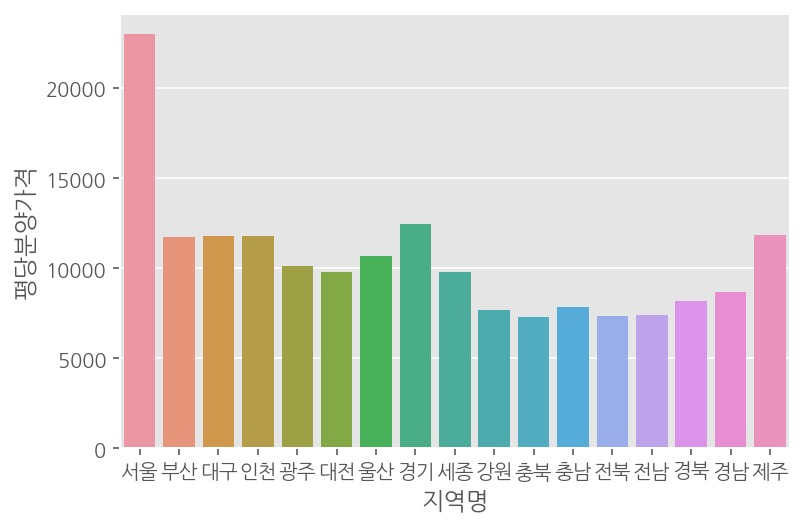
plotly를 이용해도 마찬가지이다. px.histogram을 이용한다.
px.histogram(df, x='지역명', y='평당분양가격', histfunc = 'avg')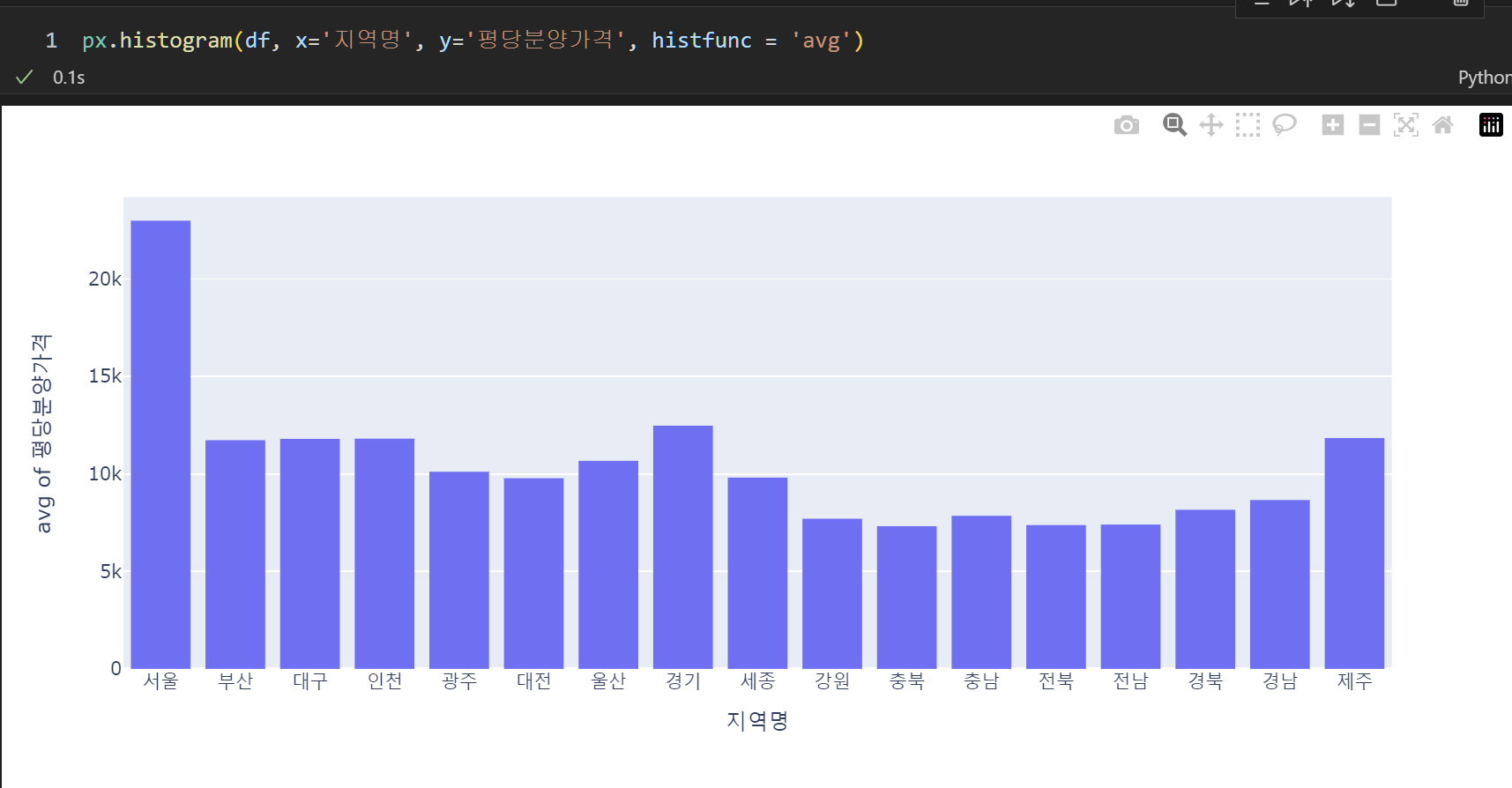
아직 멀티인덱스에 대해 그리기는 좀 어려우므로, 이중으로 그룹바이한 데이터의 경우 unstack 하여 그래프를 그려줄 수 있겠다. 다음과 같다.
df.groupby(['연도','지역명'])['평당분양가격'].mean().unstack()[['서울','경기','인천','제주']].plot.barh()연도가 index, 각 지역명들이 column으로 들어있는 데이터프레임 형태이다. pandas로 시각화를 할때, 기본적으로 index가 x축에 들어가고, 각 컬럼의 그래프들은 따로따로 한 그래프 안에 표시되었음을 생각하자. 너무 많은 컬럼들을 표시하면 잘 알아볼 수 없으므로 원하는 컬럼들만 선택하여 그래프를 그렸다. 결과는 다음과 같다.
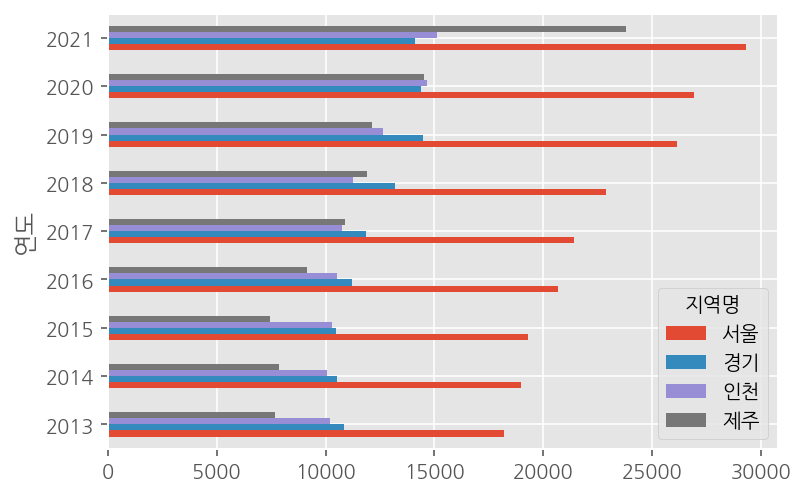
오 조금은 감이 오는 것 같기도 하고! 일단 시각화를 할 때 통계함수를 적용하여 시각화할 것인지, 그냥 데이터 자체를 시각화할 것인지에 대해 먼저 생각해봐야겠다! 데이터가 너무 많거나, 범주형 변수에 대해 시각화 한다면 통계함수를 적용하여 시각화 해야할 것이다!
음 몇몇 함수의 사용법에 대해 살펴보자.
- pandas로 box plot 그리기..!
일단 할 줄 몰라 오늘 아주 헤맸던, pandas를 이용해 box plot 그리기!
boxplot은 plot.box()를 사용할 수도 있으나, 추가적인 기능인 df.boxplot()을 이용하여 그리는 것이 더 잘 그려진다.
hist도 .hist가 따로 있듯이! 아마 사용하는 인자의 종류가 달라서 아닐까?
by와 column이라는 인자를 사용한다.
by : str or sequence
Column in the DataFrame to group by.
-> x축에 들어갈 값, 즉 그룹화하여 수치의 분포를 볼 대상이 될 컬럼을 by에 넣어준다.
column : str or list of str, optional
Column name or list of names, or vector. Can be any valid input to pandas.DataFrame.groupby().
-> boxplot을 통해 분포를 살펴보고 싶던 수치형 변수를 넣어주면 된다. 리스트로 여러개를 넣어줄 수도 있다.
이렇게 이해하면 되겠다! 이게 끝!
boxplot은 특정 범주형 변수(by)에 포함된 데이터들이, 특정 수치형변수(column) 값을 어떤 분포로 가지고 있는지 살펴보기 위해 사용한다.
seaborn과 비교하면 x가 by, y가 column에 들어가면 된다!
이해했다! 할 수 있겠다!
df.boxplot(column = '평당분양가격',by='연도',figsize = (8,6))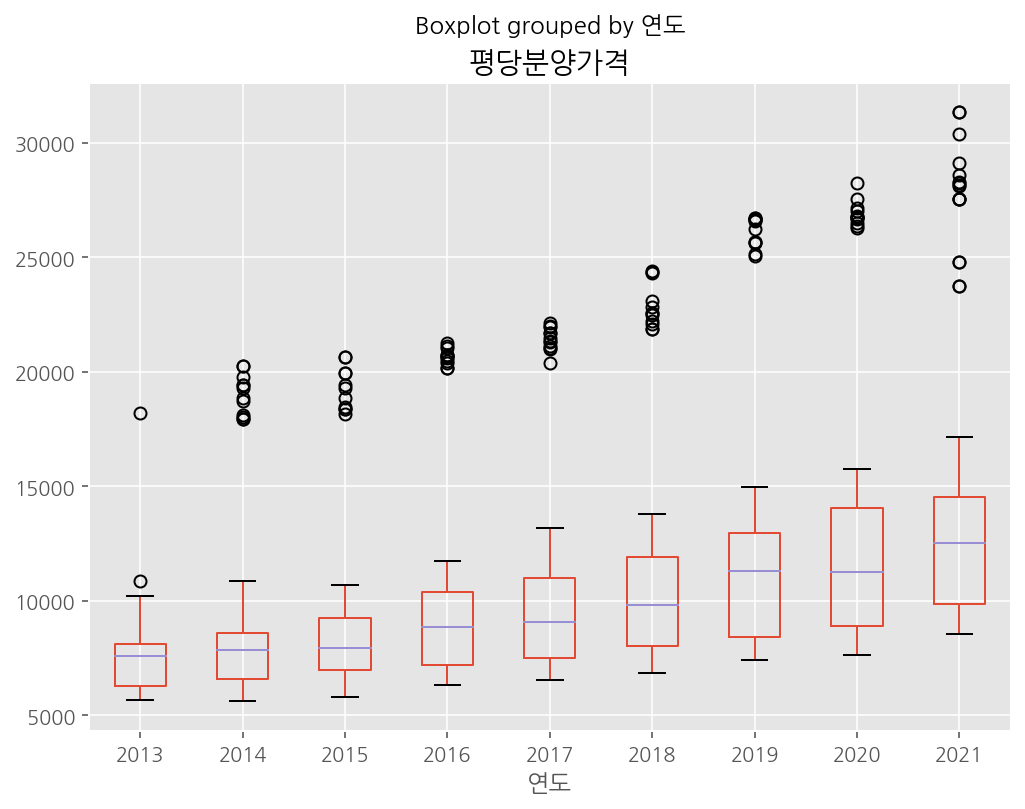
- heatmap 그리기
plt.figure(figsize = (15,10))
sns.heatmap(data_to_heat,annot=True,fmt = ',.0f',cmap = 'tab20b')어렵지 않고 그냥 데이터만 넣어주면 된다. 다양한 옵션을 통해 표시되는 형식을 설정해줄 수 있다.
seaborn 그래프의 크기는 plt.figure(figsize=())을 통해 설정한다.
- sns.pointplot
pointplot은 뭐 이렇게 낯설지? 무슨 그래프인지부터 알아보자.
각 데이터를 점으로 표시하고, 그 점들을 선으로 이어준 그래프!
다음과 같이 사용한다.
plt.figure(figsize = (10,3))
sns.pointplot(data=df,x='연도',y='평당분양가격')estimator의 default 값이 역시 'mean'이다.
- px.histogram
문서
seaborn의 barplot과 유사한 기능! 연산한 값을 바로 시각화해준다. barplot에 estimator가 있다면, histogram에는 histfunc가 있다.
histfunc의 기본값은 y값이 주어지지 않았으면 count, y값이 주어졌다면 sum이다.
plotly에서 평균은 mean이 아니라 avg를 사용한다!
또한 barmode = 'group'으로 하여 stack 되지 않은 형태의 그래프를 그릴 수 있다. 기본값은 relative로, stack하여 그래프를 그린다.
facet_col 또는 facet_row로 서브플롯을 그릴 수 있다.
marginal을 추가하여 옆에 분포를 나타내는 그래프도 그릴 수 있다.
음 그리고 x나 y 중 어느 값에 범주형 변수를 넣든, 자동으로 수치형 변수에 대해서만 연산하여 그려준다! 신기해라
- pandas 시각화
가장 간단
그래프에 통계 연산 기능이 없고, 직접 조작하여 통계값을 낸 후 시각화
subplots= True를 통해 서브플롯을 손쉽게 그릴 수 있음
그릴 수 있는 그래프의 종류가 몇개 안됨(line, bar, barh, hist, box, kde, area, pie, scatter, hexbin)
- seaborn 시각화
그래프에 통계 연산 기능이 있어 데이터와 x축, y축에 들어갈 값만 넣으면 되는 시각화
hue를 이용하여 다른 범주들을 색을 다르게 표현할 수 있음
subplot을 쓰고 싶다면 facetgrid 가 있는 특정 함수들을 사용해야함(rel, cat, dis, lm)
- plotly 시각화
동적인 시각화
역시 연산하여 그릴 수 있는 기능이 있음
hue 대신 color를 사용하고, facetgrid 기능은 facet_col 또는 facet_row로 모든 그래프에서 사용할 수 있음
그나저나 이건 볼때마다 놀랍다. 잘 익히고 되새기자!
데이터사이언스스쿨 - seaborn
데이터사이언스스쿨 - pandas 시각화
이거 꼭 읽어보자! 내일이라도! 지금? 너무 늦었다 ㅠㅠ
seaborn- data의 종류에 따른 시각화
이렇게 오늘 끝!
오늘 사실 걱정이 굉장히 많았는데, 잘 끝낸 것 같아서 좋다!
약간 감도 잡히고 있는거 같고.
어느덧 시작한지 5주째? 슬슬 몸도 정신도 지치는데 잘 버텨내보자. 파이팅!
