오늘부터 velog에 TIL을 제대로 시작한다! 4개월 간 열심히 한 번 해보자!
오늘은 좀 뭐랄까. 정신이 나가있었다. 아침부터 피곤도 했고, 배우는 내용도 훅훅 들어와서 정신을 차릴수가 없었다. 그 만큼 개인 공부 시간이 필요한데.. 가자!
오늘의 회고
사실(Fact): Pandas의 기초적인 사용법에 대해서 마저 배웠고, seaborn을 이용해 데이터를 시각화 하는 방법을 배웠다.
느낌(Feeling): 난이도가 급상승한 느낌이었다. seaborn에서 violin plot을 들을 때부터 정신을 반 놓고 들은 것 같아서 복습을 잘 해야할 것 같다.
교훈(Finding): Anscombe’s quartet 의 예시로 데이터 시각화를 해보며, 데이터 시각화의 중요성에 대해 배울 수 있었다. 중요한 만큼 꼼꼼하게 공부해야겠다.
그럼 정리 시작!
pandas
어제는 pandas에서 DataFrame 자료형이 무엇인지와 관련된 method들에 대해 간단히 배웠었다.
오늘도 이어서 DataFrame 자료형을 활용하는 다양한 방법들에
대해 배웠다! 추가로, groupby를 사용하는 법, series의 accessor, 그리고 pandas의 .plot()을 활용한 간단한 시각화 방법도 알 수 있었다.
DataFrame
- column의 데이터 가져오기
df['col'] 또는 df.col을 사용한다. 이 때, 후자의 경우 column의 이름에 특수기호 등이 있을 경우 error가 발생할 수 있어 추천하지 않는다.
2개 이상의 column의 data를 가져올 경우, 해당 column들의 이름을 담은 list를 이용한다. 다음과 같다. df[["약품명","가격"]]
loc
df.loc[index_name, column_name]으로 사용하는 loc은 명시적인 방법을 사용해 DataFrame의 정보를 가져오는 방법이다.
앞서 df['col']의 방법으로 column(열)의 데이터를 가져왔다면, loc을 이용해서는 주로 index(행)의 데이터를 가져온다. 물론 slicing 등을 사용해 df.loc[ : ,column_name]으로 column의 데이터만 가져올 수도 있다.
loc의 slicing 에서 주의해야 할 점은, [start : stop]에서 일반적인 슬라이싱과 달리 stop index를 가진 값까지 뽑아온다는 점이다.
앞과 마찬가지로 여러 인덱스나 컬럼의 정보를 가져올때에는 해당 인덱스와 열들의 list를 만들어 인자로 주어야 한다.
.iloc
반면 .iloc[index_num,col_num]의 경우 행과 열의 인덱스 번호를 사용해 데이터를 가져온다. 슬라이싱도 일반적인 슬라이싱과 마찬가지로 stop - 1 번째의 값까지만 가져온다.
.set_index()
set_index(column)는 원하는 column을 index로 설정해준다. 이때, 원본 객체의 값을 수정하는 것이 아님에 유의하자!
따라서 inplace = True를 사용하거나, 본인에 다시 할당해주는 작업이 필요하다. 유사하게 .reset_index()는 인덱스를 다시 column으로 바꾸어준다.
del df['col']
어제 .drop()을 사용해서 column을 삭제하는 법을 배웠는데, 파이썬의 기본 함수인 del을 사용해서도 column을 삭제할 수 있다!
boolean indexing
boolean indexing을 활용하여 특정 조건을 만족하는 자료들만 뽑아올 수 있다. 예는 다음과 같다. df[df["가격"] >= 3000]
해당 코드는 전체 df에서 가격 열의 정보가 3000보다 큰 행들만 뽑아온다.
.sort_values(), .sort_index()
df를 정렬할 때 사용하는 method이다.
.sort_values(by, axis, ascending, inplace ...) 로 사용한다.
axis = 0(기본 값) 일 경우 행의 방향으로 정렬, axis = 1일 경우 열의 방향으로 정렬한다.
ascending = True(기본값)일 경우 오름차순, False일 경우 내림차순으로 정렬한다.
여러 값을 기준으로 정렬할 수도 있다. 역시 리스트 형태의 인자를 사용한다. 예시는 다음과 같다.
df.sort_values(by = ["가격","약품명"], ascending = [False,True])
df.head() , df.tail()
dataframe의 상위 혹은 하위 몇 개의 자료들만 가져오는 method이다. 인자로 숫자 값을 추면 그 개수만큼의 자료들만 가져온다.
df.sample()
DataFrame에서 임의로 몇개의 행만 뽑아오는 method이다. 인자로는 개수, frac이나 random_state 가 들어간다.
개수를 넣어 주면 해당 개수만큼의 sample만 추출하고,
frac은 전체에서 추출할 sample의 비율을 의미한다.
random_state는 랜덤 시드값으로, 해당 값을 고정하면 추출되는 값 역시 고정된다. 참고로, 주로 42를 사용한다.(관습적)
-
.unique: 해당 열의 고유값들을 반환한다. -
.corr()
여러 column들 사이의 상관계수를 반환한다. 상관계수의 기본값은 pearson 상관 계수로, 이는 공분산을 표준편차의 곱으로 나누어준 값이다.
해당 값은 -1 ~ 1 까지의 범위를 가진다.
.value_counts()
특정 열의 도수를 구해준다. 이때, normalize = True의 인자를 넣어주면, 합이 1인 비율로 정규화되어 나타난다.
- 파일로 저장하기 / 파일 읽어 df에 저장하기
DataFrame 자료형을 파일로 내보낼 수 있다. to_csv(filename), to_excel() 등의 함수를 사용한다. 이때, 인자로 index = False를 넣어주어야 임의 생성된 index가 함께 저장되는 걸 방지할 수 있다.
파일을 읽어 df에 저장하기 위해서는 pandas의 pd.read_csv()나 pd.read_excel() method를 사용한다.
오늘의 멘붕 1. Encoding
뭐지 사람들이 다 인코딩에 대해 잘 아시더라! 난 하나도 모르는데...!
그래서 멍하니 듣고만 있었다. 그리고 지금 한번 공부해보려 한다!
수업 때 들은 내용을 복기해보면, 일반적인 인코딩 형식은 UTF-8 인데, 한국의 윈도우에서 사용하는 인코딩 형식이
한글 완성 문자인 EUC-kr이어서 파일을 다운받아 엑셀로 열어봤을 때에 문제가 생겼다.
이는 한글 조합 문자 인코딩 형식인 cp949가 11,722자를 지원하는데 비해 EUC-kr은 2350자 밖에 지원하지 않아 생기는 오류라고 한다.
따라서 이를 해결하기 위해 파일을 읽을 때와 쓸 때 encoding = "cp949" 코드를 추가하여 쓴다!
그건 그렇고, 그래서 encoding이 뭘까!
문자 인코딩이란, 문자열 데이터를 2진 데이터로 변환하는 것을 의미한다.
이때, 문자열을 binary로 변환시키는 규칙이 있을 것인데, 그걸 정의해 놓은 것이 바로 EUC-kr 등의 인코딩 방식이다.
각 인코딩 방식 별로 사용하는 문자와 이에 해당하는 숫자 정리한 '문자 집합'을 정의해, 문자를 숫자로, 2진 코드로 변환한다.
몇 비트로 인코딩 할 것인지, 어떤 문자 집합을 사용할 것인지 등으로 여러 인코딩 방식이 나뉘어지며,
대표적인 인코딩 방식은 UTF-8, EUC-kr, CP949 등이 있는 듯 하다.
사실 몇 개 글만 읽고 정리한거라 정확한 정보는 아니고 틀린 것도 있을 것 같지만.. 시간이 부족하다! 어렵네 어려워.
일단 인코딩은 그냥 저런거구나 하고 넘어가야겠다.plot()
뒤의 seaborn 실습 도중, seaborn에서는 pie chart가 없다며 pandas의 plot기능을 잠시 보여주셨다. 그럼 한번 찾아봐야지...
첫 날인가 강의에서. pandas 내부에도 matplotlib이 있다는 말씀을 강사님이 하신 적이 있는데. 이게 바로 그걸 사용하는 것이다.
df.plot() 의 method로 사용하여, DataFrame을 시각화하는 그래프를 그려준다. 내부에 kind 라는 인수에 따라 그래프의 종류가 달라지는데, kind에는 bar, pie, hist, kde, box, scatter 등이 올 수 있다.
df.plot()으로 그래프를 생성하고, plt.tilte() .xlabel() .ylabel() 등 의 속성을 정해줄 수도 있다.
자세히는 잘 모르겠고.. 일단 이 정도만 알고 있자!
.groupby()
DataFrame의 groupby method를 사용하면,
split -> apply a function -> combining the result!
라는 세 가지 동작을 한번에 해낼 수 있다. 아주 중요!
그림으로 이해하면 다음과 같다.
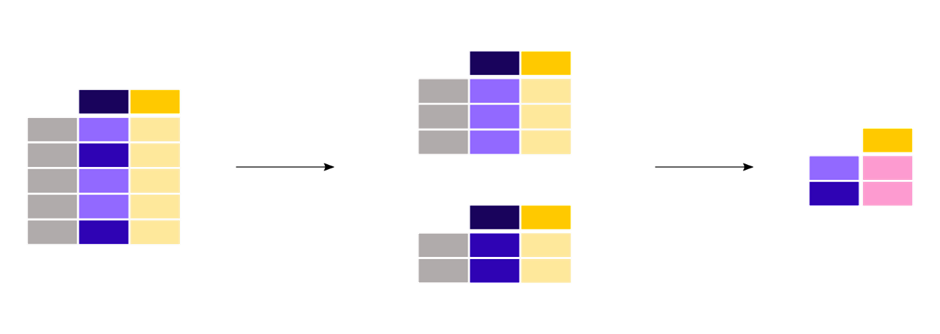
말로 대강 이해해보자면, column에 대해 groupby를 적용할 시,
해당 column의 unique 값들에 대해 데이터들이 묶인다.
음.. 동일한 값들을 모두 group화 시켜 하나로 만든다고 할 수 있겠다!
그 후 각 그룹에 대해 다양한 집계함수, 혹은 aggregation 및 filtaration, transformation과 같은 기능을 수행 한다.
그리고 그 값을 dataframe을 통해 쉽게 볼 수 있게 해준다!
라고 이해했다. 이는 고유값마다 하나씩 subset을 만들어 집계함수를 적용하는 등의 방법에 비해 아주 간단하며 효과적인 방법이다.
사용 예시를 보자면, df.groupby("dataset").[["x","y"]]mean()
: dataset 열에 대해 그룹화하여, 각 그룹별로 x 와 y column의 평균을 내는 기능을 한다!
아 groupby 역시 원본 객체를 수정하는 것이 아니므로 재할당이 필요하다. groupby에 관한 내용은 오늘은 여기까지!
Series - Accessor
오늘의 두 번째 멘붕
Accesor
어디서 나왔느냐면, df의 한 열이 특정 문자를 포함하는지 아닌지 찾아 subset을 만들어 보는 실습에서 나왔다!
.str.conatins() 였고, .str. 이라고 사용한 것이 신기했는데, 이게 series에서 정의된 accessor라고 한다!
한 번 찾아보자.
공식 문서에는 이렇게 나온다.
pandas provides dtype-specific methods under various accessors.
These are separate namespaces within Series that only apply to specific data types.무슨 뜻일까..? 대강 특정 dtype에 대해 accessor를 사용해 그 dtype의 method를 사용할 수 있다는 말 같다! 우와...!
접근자(accessor)라는 것이 생소해 이게 pandas에서만 쓰이는 개념인지 질문을 남겨 다음과 같은 답변을 받았다.
파이썬 class의 method를 접근하기 위해서도 접근자를 사용하며 다른 언어에서도 비슷한 이유로 사용합니다! 아직 class가 뭔지도 잘 모르고 해서 찾아봐도 이해는 잘 안 되지만... 종종 사용하는 개념이라는 것을 알았다. 언젠가는 이해가 되겠지. 공부 열심히 하자!
다시 본론으로 돌아와, 결국 pandas에서는 특정 dtype에 관한 method를 사용할 수 있게 하는 accessor라는 기능이 있다!
accessor의 종류로는, dt,str,cat,sparse가 있다고 한다.
dt : datetime으로, dt.date, dt.time 등 을 이용 가능
str : string으로, str.upper(), str.contains() 등
cat : categorical 이라고 한다...!
sparse : sparse란 희소 행렬(행렬의 값이 대부분 0인 행렬) 이다.
사용할 때, 여러 문서들을 잘 찾아가며 사용하는 습관을 들이자! 꼭!
그래서 실습에서 어떻게 사용했냐면은, 약품명에 vita 가 들어가는 자료를 찾기 위해 다음과 같은 코드를 사용했다.
df["약품명"].str.upper().str.contains("vita|비타")
이때 |는 정규표현식에서or의 의미라고 한다.
이렇게 오늘의 pandas가 끝났고,,,, seaborn 실습을 했다.
seaborn
seaborn이라는 라이브러리로 갑자기 데이터 시각화를 했다. 벌써..?
이 때 부터 정신을 반 쯤 놓고 들었던 것 같다..
Anscombe's quartet
첫 날 이니만큼, 데이터 시각화의 중요성에 대해 알아보기 위해 Anscombe's quartet을 사용해 간단한 데이터 시각화를 해보는 실습을 했다.
Anscombe's qurtet 이란, 기술통계 값은 모두 유사한 형태를 보이나, 시각화를 해보면 전혀 다른 4개의 데이터 셋(각각 11개로 구성)이다. 데이터 시각화의 중요성을 보여주는 대표적인 예시라고 할 수 있다.
seaborn이란
seaborn은 matplotlib기반의 파이썬 데이터 시각화 라이브러리이다. high-level interface를 가지고 있어 matplotlib의 고수준 버전이라고 생각할 수 있다. (색상과 통계 기능 추가)
또한 seaborn은 내부적으로 통계적 연산 기능을 보유하고 있다. 따라서 데이터 셋을 따로 계산한 후 시각화 할 필요가 없이 바로 연산하며 시각화 할 수 있다는 장점이 있다.
추가로, seaborn에는 연습용 샘플 데이터셋 몇 개도 내장되어 있어 사용할 수 있다. iris, titanic, tips, anscombe 등이 있다.
데이터 사이언스 스쿨 참고!
이거도 참고하자!
seaborn 사용법
-
import seaborn
import seaborn as sns로 사용한다. 우리가 사용하는 별칭들은 모두 각 라이브러리의 공식문서 예제에서 사용하는 별칭들이다! -
data load
sns.load_dataset("dataset")으로 내장 데이터셋을 가져오거나,df = pd.read_csv("csv파일")과 같이 직접 데이터 파일을 불러온다.
seaborn 시각화
너무 많다...! 이해도 안되고..! 오늘 다는 못하겠고. 오늘은 수업 내용 위주로 해야겠다...
범주형 데이터에 대한 그래프
countplot(data, x or y)

dataframe에 대해 지정해준 column의 도수를 계산하여 표시해준다.
barplot(x, y, data, estimator, ci)
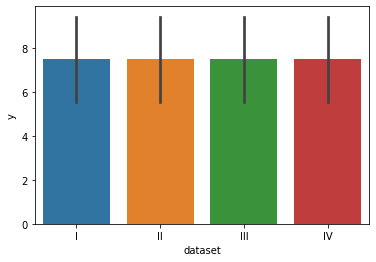
dataframe에 대해, 지정해준 column들에 대해 연산을 수행하여 막대그래프를 그려준다!
기본 연산은 평균이다. 이는 estimatro = np.sum등으로 변경하여 사용할 수 있다.
error_bar 혹은 ci(구버전)의 경우 기본 값은 신뢰구간을 결정하는 신뢰도 값 95이다. 이를 sd등으로 바꾸면 error bar가 신뢰구간이 아닌 표준편차를 표시한다. 그런데, 이 ci 를 계산하기 위해 표본을 추천하는 nboot등이 오래걸려 None으로 빼는 것을 추천한다.
barplot은 수치형 데이터에도 사용하긴 하지만, 막대의 개수가 너무 많아질 경우 사용하지 않는다.
수치형 데이터에 대한 그래프
boxplot(x,y,data)
boxplot은 사진을 통해 이해하자!
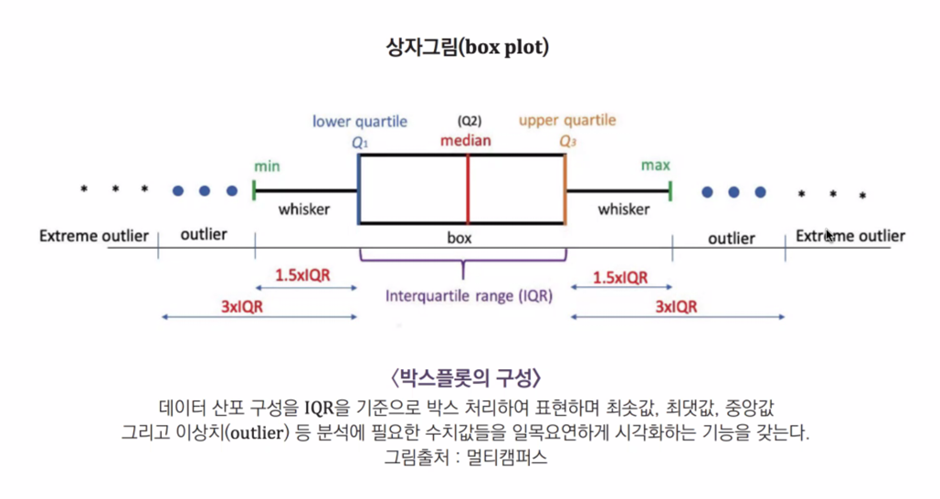
1사분위 값, 3사분위값으로 이루어진 박스 안에 2사분위 값을 표시하고, outlier까지 처리해 줄 수 있는 형태의 그래프이다.
데이터의 구성과 특징을 한 눈에 이해하는데 자주 사용한다!
.hist(bins)
히스토그램이란, 수치 변수에 대한 분포를 bin의 개수를 다르게 하여 막대로 표시한 그래프이다.
.kdeplot(data,x,hue)
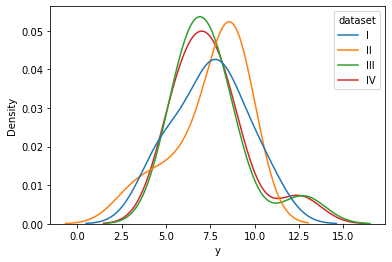
kde plot은 kde(커널 밀도 추정)의 방법을 사용해 얻은 histogram의 밀도를 나타내는 그래프이다! histogram이 수치 자체를 나타냈다면, kde는 밀도(상대적)를 나타낸다는 차이가 있다.
.displot(data, x, col, kind, hue,,,)
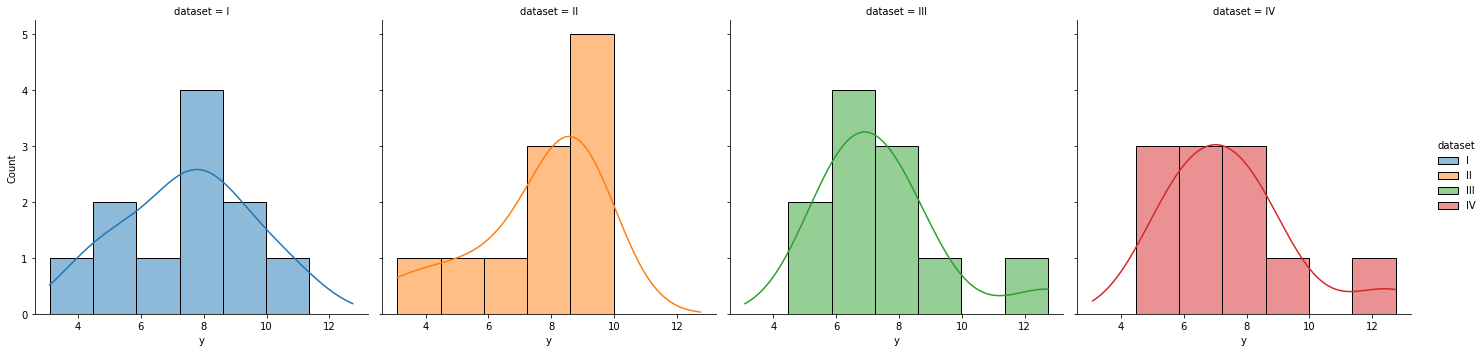
displot은 hist, kde, rug, ecdf plot 등 을 통합하여 그릴 수 있는 그래프이다.
kind : kde = True로 해주면 kde를 표시하는 등의 기능을 한다.
col 인자를 통해 어떤 column의 데이터를 subset으로 할 지 정해준다.
hue 인자는, 색을 여러가지로 다양하게 표현할 지를 정해주는 인자라고 생각할 수 있다.
.violinplot(data,x,y)
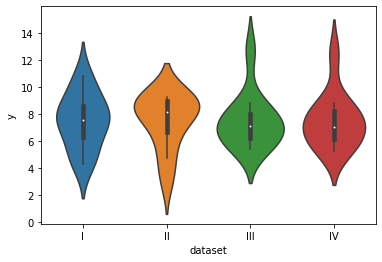
violin plot은 kde plot을 데칼코마니처럼 합쳐 그리고, 그 가운데에 box plot이 들어간 형태라고 볼 수 있다. 따라서 이는 box plot의 장점인 데이터의 구성과 특징을 알아볼 수 있다는 점에, 내부 분포가 달라지는 정도까지 표현할 수 있다는 장점이 있다.
.scatterplot(data,x,y,hue)
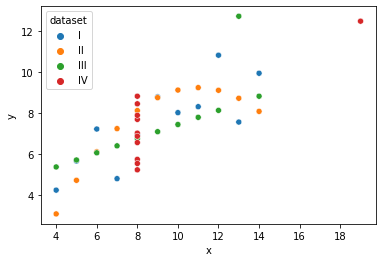
두 개의 수치형 변수간의 관계를 표현할때 그리는 그래프.
.regplot(data,x,y)
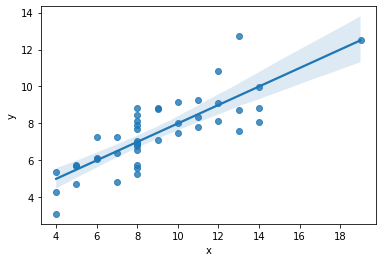
회귀 선을 그릴 수 있는 그래프. regplot에는 hue 인자가 없기에, 다른 색으로 그리려면 lmplot을 사용한다.
.lmplot(data,x,y,hue,col,col_wrap)
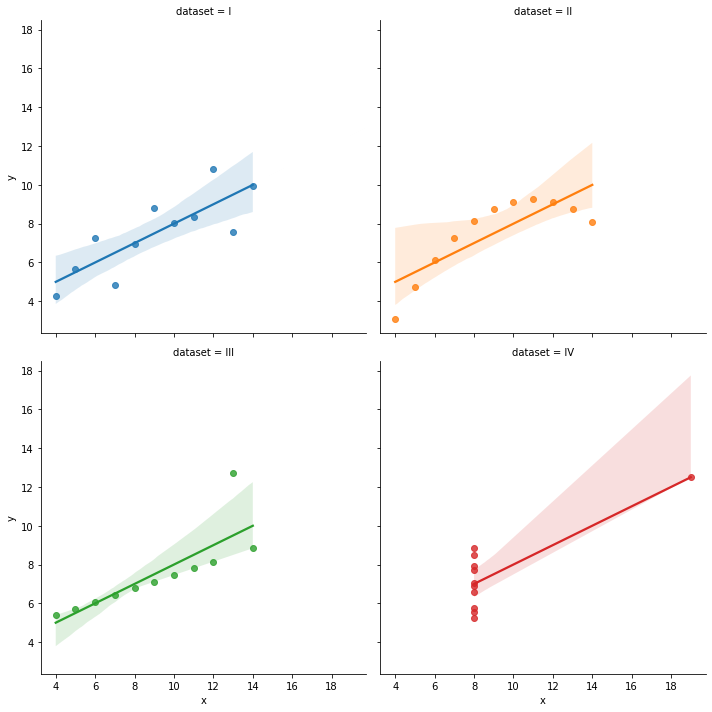
column들 간의 선형관계를 표시할 때 사용하는 그래프. (회귀)
hue 인자를 통해 여러 데이터의 색을 나누어 표시할 수 있으며,
col 인자를 통해 unique값 별로 그래프를 별도로 표시하고,
col_wrap을 통해 한 행에 몇개의 그래프를 표시할 지 선택한다.
다음과 같이 seaborn의 그래프들을 분류할 수 있다.
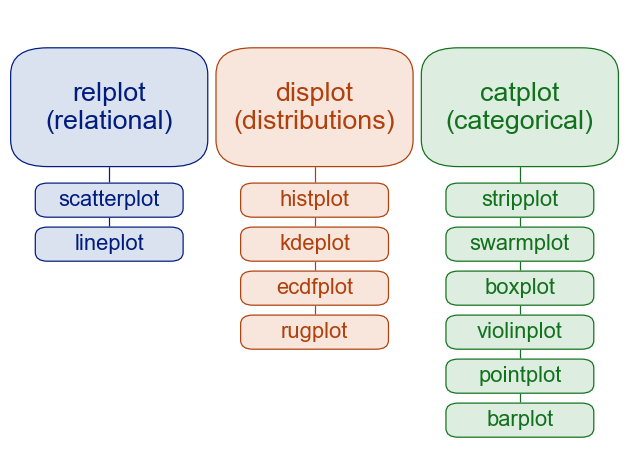
수치형 자료
- rugplot
- kdeplot
- distplot
- jointplot
- pairplot
범주형 자료
- countplot
- heatmap
복합 데이터
- barplot
- boxplot
- pointplot
- violinplot
- stripplot
- swarmplot
relplot : 두 가지 변수의 관계를 나타내기 위해 주로 사용
displot : 변수 하나 혹은 두개의 값 분포를 나타내기 위해 주로 사용
catplot : 범주형 변수와 연속형 변수간의 관계를 나타내기 위해 주로 사용 통계 지식
강사님 필수 추천 도서에 다양한 통계 관련 지식들이 나오는 것 같다.
오늘 몇가지를 설명해주셨다. 꼭 읽어봐야겠다는 생각과, 데이터 분석을 위해 통계 지식을 갖출 필요가 있겠다는 생각이 많이 들었다.
- 자료의 종류
- 수치형 자료
: 측정값으로 나타낼 수 있는 자료 (연속형, 이산형) - 범주형 자료
: 측정 값으로 나타낼 수 없는 자료 (순위형, 명목형)
- 수치형 자료
- IQR
IQR은 기억하자. 어제 배웠던 사분위수. 25% 50% 75% 100% 중 3분위수(75%의 값) - 1분위수(25%의 값)을 해준 것이 바로 IQR이다.
데이터가 얼마나 흩어져 있는지에 대한 정보이다!
boxplot과 연관되어있다.
오늘의 정리 끝!
뭐지... 오늘은 뭔가 공부한 느낌이 안난다. 시간은 시간대로 들었는데? 특히 seaborn쪽이 추가로 공부 한것도 안한것도 아닌 애매한게 되어버렸다.
공부 방법에 대해 다시 한번 생각해봐야 하나 싶다.
혼자 할 때에는 강의 적당히 듣고, 추가적으로 찾아보며 공부하고 정리할 시간이 있었는데. 스쿨을 시작하고 난 후부턴 그게 잘 안된다. 강의 듣고 나면 지치고, 잠깐 쉬고 그날 들은 내용 정리만 해도 잘 시간이다.. 정리가 너무 오래걸리는 건가? 추가로 찾아보기도 해야하고, 심지어는 실습도 해야하는데! 시간이 안난다.
공부 방법을 바꿔야하나? 메소드나 함수 같은 것들은 나중 실습 할때 그때그때 찾아보며 공부하는 걸로..? 모르겠다 고민이 된다. 강의에 들어가는 시간도 많고 강의량도 많으니 공부에 이런 문제가 생기는구나 싶다..ㅠㅠ
어쨌든 실습은 진짜 해야되는데? ㅠㅠ... 목요일 금요일을 잘 활용하자...
조급해하지 말자! 하다보면 적응 되겠지! 파이팅!
