
참고 자료
Understanding C++ Compute Shader Dispatch and RDG in Unreal Engine - Ghislain Girardot
Compute Shader Overview - Microsoft
GPU Performance Background User's Guide - NVIDIA
3. GPU Architecture
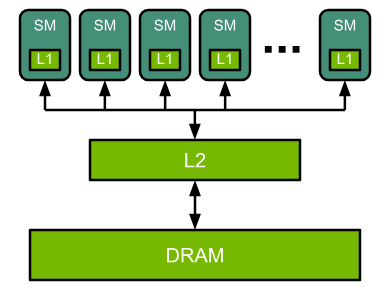
Compute Shader를 이해하기 위해서는 GPU가 어떤 메모리 구조를 통해 데이터를 처리하는지 이해할 필요가 있다.
GPU는 대량의 데이터를 병렬로 처리하기 위한 다양한 메모리 계층 구조(Memory Hierarchy)를 함께 가진다.
특히
- 데이터를 어디에서 읽는가
- 어떤 메모리를 공유하는가
- 메모리 접근 비용이 얼마나 발생하는가
에 따라 성능 차이가 크게 발생할 수 있다.
따라서 GPU Architecture에서 사용되는 메모리 구조를 이해하는 것은 Compute Shader의 병렬 처리 방식과 성능 최적화를 이해하는 데 매우 중요하다.
3-1. DRAM
DRAM(Dynamic Random Access Memory)은 GPU에서 가장 큰 용량을 가지는 메모리 영역이다.
일반적으로 우리가 VRAM(Video Memory)이라고 부르는 영역이 여기에 해당하며, GPU는 이 공간에 대량의 데이터를 저장한 뒤 연산에 사용한다.
예를 들어
- Texture
- Buffer
- Render Target
와 같은 대부분의 GPU 리소스는 DRAM 영역에 저장된다.
GPU는 Compute Shader를 실행할 때 필요한 데이터를 DRAM에서 읽어오고, 계산 결과 역시 다시 DRAM에 기록하는 방식으로 동작한다.
다만 DRAM은 용량은 매우 크지만 GPU 내부의 Shared Memory나 Cache에 비해 접근 속도가 상대적으로 느리다.
따라서 Compute Shader에서는 동일한 메모리를 반복적으로 읽거나, 불규칙한 위치의 데이터를 계속 접근하는 경우 메모리 접근 비용이 증가하게 되며 이는 곧 성능 저하로 이어질 수 있다.
3-2. L2 Cache
GPU는 DRAM에 저장된 데이터를 직접 계속 접근하는 대신, 중간에 Cache 계층을 사용하여 메모리 접근 비용을 줄인다.
그중 L2 Cache는 GPU 전체에서 공유되는 공용(Cache Shared) 메모리 계층이다.
L2 Cache는 여러 SM(Streaming Multiprocessor) 사이에서 공유되며, 반복적으로 사용되는 데이터를 임시 저장하는 역할을 한다.
따라서 동일한 데이터를 여러 Thread가 반복 접근하는 경우, DRAM까지 다시 접근하지 않고 L2 Cache에서 데이터를 가져올 수 있어 메모리 접근 비용을 줄일 수 있다.
3-3. Streaming Multiprocessor
SM(Streaming Multiprocessor)은 GPU에서 실제 연산이 수행되는 핵심 처리 유닛이다.
GPU는 여러 개의 SM으로 구성되어 있으며, Compute Shader에서 생성된 Thread Group들은 이러한 SM에 분배되어 실행된다.
각 SM 내부에는
- 연산 유닛(Execution Core)
- Register File
- Shared Memory
- L1 Cache
등이 함께 존재한다.
SM 내부에서는 여러 개의 Thread Group이 실행된다.
이 때문에 같은 Group 내부의 Thread들은 Shared Memory를 통해 데이터를 빠르게 공유할 수 있으며, Synchronization 역시 효율적으로 수행할 수 있다.
예를 들어 Compute Shader에서는 여러 Thread가 반복적으로 사용하는 데이터를 Shared Memory에 임시 저장한 뒤 재사용함으로써 DRAM 접근 횟수를 줄이는 방식이 자주 사용된다.
다만 Shared Memory와 Register는 SM 내부에 제한된 크기로 존재하기 때문에, 하나의 Thread Group이 너무 많은 메모리를 사용하는 경우 동시에 실행 가능한 Group 수가 감소할 수 있다. 이는 GPU Occupancy 감소로 이어질 수 있으며, 결국 전체 병렬 처리 효율에도 영향을 미치게 된다.
3-4. L1 Cache
1 Cache는 각 SM(Streaming Multiprocessor) 내부에 존재하는 고속 Cache 메모리이다.
앞서 설명한 L2 Cache가 GPU 전체에서 공유되는 Cache였다면, L1 Cache는 각 SM 내부에서만 사용되는 더 가까운 Cache 계층이라고 볼 수 있다.
특히 Compute Shader에서는 인접한 메모리를 반복적으로 접근하는 경우가 많다.
예를 들어
- 주변 픽셀 샘플링
- Blur 연산
- 연속적인 Buffer 접근
- Grid 기반 계산
과 같은 작업에서는 비슷한 위치의 데이터를 여러 Thread가 반복적으로 읽게 된다.
이 경우 이미 읽어온 데이터가 L1 Cache에 저장되어 있다면 DRAM까지 다시 접근하지 않고 더 빠르게 데이터를 가져올 수 있게 된다. 따라서 메모리 접근 비용이 줄어들고 전체 연산 성능 역시 향상될 수 있다.
반대로 Thread들이 서로 멀리 떨어진 위치의 데이터를 불규칙하게 접근하는 경우에는 Cache 효율이 낮아질 수 있다. 이런 상황에서는 Cache Miss가 증가하게 되고, 결국 다시 DRAM 접근이 많아지면서 성능 저하로 이어질 수 있다.
