
목표
앙상블 모델의 의미를 이해하고 이를 적용하여 만들어진 부스팅(Boosting), 배깅(Bagging), 스태킹(Stacking)에 대해 알아보자!
앙상블 (Ensemble)
앙상블은 '조화'를 의미하는 프랑스어로 음악에서 협주를 하는 것을 앙상블이라고도 부른다.
우리가 음악 무대를 보면 독무대를 설 때, 잔실수를 하면 크게 눈에 띄고 좋은 점수를 받기 어렵다. 하지만 앙상블 무대에서는 잔실수를 해도 다른 사람들에 묻혀서 크게 눈에 띄지 않고 점수를 받기 쉽다. 이러한 음악의 앙상블은 딥러닝의 앙상블 기법과도 유사한 느낌을 가지고 있다.

(출처 : https://www.nytimes.com/2023/11/10/arts/music/review-american-composers-orchestra.html)
앙상블 기법 (Ensemble learning method)
앙상블 기법은 사전적으로 여러 개별 모델들을 조합하여 최적의 모델로 일반화하는 방법을 말한다.
이를 우리가 배운 기본적인 머신러닝 이론에 빗대면 다음과 같다.
한 모델을 만들고, 모델에 대해 다양한 방법으로 학습을 한다! 그리고 이를 활용하여 하나의 더 강력한 모델로 만드는 기법을 말한다!
예를 들자면, 분류 학습에 대해 여러 알고리즘으로 모델을 가중치가 다르게 학습을 시킨다. 그리고 그 모델들이 내놓은 결과들을 모두 받아서 가장 많이 선택한 결과를 최종 결과로서 내놓는다!
그리고 이것이 바로 앙상블 기법 중 하나인 보팅(Voting)의 대표적인 예시이다.
앙상블 기법은 대표적으로 세 가지로 나뉘는데, 이는 다음과 같다.
-
배깅(Bagging)
하나의 같은 알고리즘으로 데이터를 각각 다른 모습들로 학습시켜두고 이를 가지고 결과를 결합해 최종적인 답을 내는 것. -
부스팅(Boosting)
여러 성능이 낮은 모델을 순차적으로 학습시키면서 이전 모델이 틀린 부분에 가중치를 더 크게 부여하여 다음 차례의 모델이 그 부분을 더 잘 예측하도록 하는, 마치 모델들이 하나의 '결합(Combination)'처럼 느껴지게 하는 것! -
스태킹(Stacking)
서로 다른 알고리즘을 사용하는 모델들이 내놓은 결과들을 하나의 메타 모델(Meta Model)에 입력으로 제공해, 최종적으로 더 좋은 답으로 만드는 방법이다.
마치 모델들 결과들이 하나의 '선형(Linear)' 관계를 이루는 것과 같다!
이 외에도 위에 소개했던 보팅(Voting), 스태킹과 비슷하지만 Train Data에서 Validation Data를 뽑아내어 이를 메타 모델의 입력에 사용하는 블렌딩(Blending), 스냅샷(Snapshot), 네거티브 코릴레이션 학습(Negative Correlation Learning) 등이 있다!
우리는 이 많은 앙상블 기법들 중에서 위의 배깅, 부스팅, 스태킹에 대해 자세히 알아보도록 하겠다!!
배깅(Bagging)
배깅은 Bootstrap Aggregating의 준말로 직역하면 '초기 단계(샘플링)의 것들을 집계한다.' 라는 의미로 여러 Weak 모델들을 학습하고 이를 집계하여 Strong 모델의 성능으로 향상시키는 앙상블 기법이다.
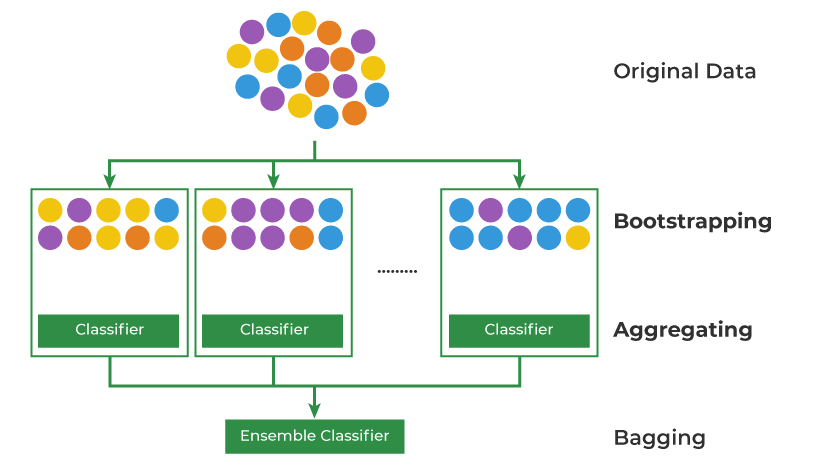
(출처 : https://www.geeksforgeeks.org/ml-bagging-classifier/)
배깅은 특히 모델의 분산을 줄여 과적합을 방지하고, 더 안정적이고 보편적인 예측을 가능하도록 만든다!
배깅의 기본 아이디어는 같은 데이터를 여러 번 무작위로 샘플링한 후, 각 샘플에 대해 모델들을 각자 학습시켜 모두 다른 가중치를 가지도록 만들고, 이들의 결과를 평균내거나 다수결 투표하는 것에서 발전되었다!!
※ 여기서 보팅(Votting)과 다른 점은 보팅은 '같은' 데이터에 '여러' 알고리즘을 사용하고, 배깅은 '데이터의 샘플링' 결과를 '같은' 알고리즘에 사용한다는 것!!
배깅의 주요 특징
- 부트스트랩 샘플링(bootstrap sampling) 사용
이 특징은 배깅이 원본의 데이터셋에서 '중복을 허용하는 무작위적인 샘플링(bootstrap)'을 만드는 것을 의미한다.
이는 원본 데이터셋 개와 동일한 크기의 훈련 데이터셋을 만드는데, 원본 데이터셋에서 중복된 데이터를 뽑는 것을 허용하여 데이터셋을 구성한다는 특징이 있다. 그러므로 일부 데이터는 여러 번 선택될 수 있고, 일부 데이터는 전혀 선택되지 않을 수 있다.
이 데이터셋들을 통해 만들어진 모델들은 저절로 서로 다른 특징을 가지게 된다!
- 개별 모델 학습
위의 각 부트스트랩 샘플로 독립적인 모델로서 학습을 시킨다는 특징이다. 이 때, 동일한 알고리즘을 사용하거나, 때에 따라 다른 알고리즘을 사용할 수도 있다!
배깅에서 자주 사용하는 모델은 '결정 트리(Decision Trees)'이며, 이따가 다룰 배깅의 대표적인 알고리즘인 '랜덤 포레스트(Random Forest)'는 여러 개의 결정 트리를 가지고 만든 모델이다!
※ 결정 트리(Decision Trees)
결정 트리란 간단하게 보자면 트리 구조로서 분기점마다 내부 노드에서 특정 조건에 따라 왼쪽, 오른쪽으로 나누며 결국 리프 노드에서 클래스(이진 분류면 0 or 1, 다중 분류면 여러 가지 리프 노드로!)를 반환하는 모델을 의미한다.
- 결과 결합
배깅에서 이제 최종적으로 여러 모델의 결과들을 특정 방식으로 결합해 답을 내린다!
- 회귀 문제의 경우 : 각 모델의 예측값을 평균하여 최종 결과를 만든다.
- 분류 문제의 경우 : 각 모델의 예측값에 대해 다수결로 최종 결과를 만든다.
배깅의 장단점
- 장점
- 과적합 방지
배깅은 데이터 샘플이 다양하므로 과적합을 줄이는 데 효과적이다! 특히 작은 변화에도 민감하게 변할 정도로 Train 데이터에 의존적인 모델일수록 배깅이 과적합을 줄이는 데 큰 도움이 된다.
- 모델의 분산 감소
배깅은 모델의 분산을 줄여주는 장점이 있다!
특히, 결정 트리와 같이 데이터에 의해 민감하게 반응하는 모델의 경우, 단일 결정 트리 모델보다 배깅을 사용한 앙상블이 훨씬 좋다.
※ 분산이 줄어드는 것이 왜 장점인가?
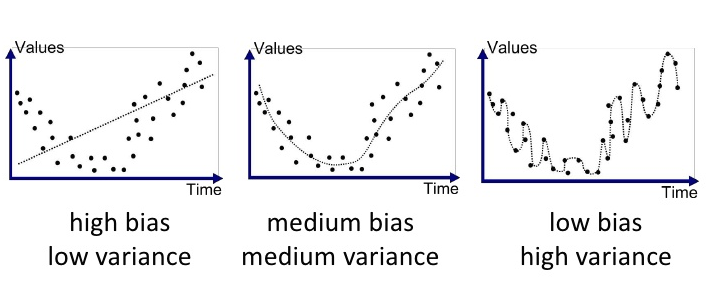
(출처 : https://www.opentutorials.org/module/3653/22071)
위 그림의 경우를 보면 variance(분산)이 크면 데이터에 대해 모델 그래프가 요리조리 움직이는 모습을 볼 수 있다. 이 경우 다른 정답 데이터가 왔을 때, Loss가 커지는 과적합을 볼 수 있다!!
추가로 bias(편향)이 크면 그래프는 일정하지만, 데이터에 대해 Loss가 커지는 것을 볼 수 있다!
- 단점
- 계산 비용 증가
여러 모델을 학습하고, 예측을 결합하는 모든 과정에서 단일 모델에 비해 계산 비용(용량, 시간 등...)이 높다!
특히 데이터셋이 크거나, 모델이 복잡할수록 학습 시간이 엄청 크게 증가할 수 있다.
- 편향은 줄이지 못한다.
위를 보면 분산과 편향이 둘 다 모델에게 중요한 것을 볼 수 있는데, 배깅은 편향을 줄이기는 어렵다.. 즉, 모델 자체의 구조적 한계로 발생하는 Loss는 배깅도 해결 못한다. 그저 이미 좋은 모델에서 성능을 올려주는 것...!
랜덤 포레스트(Random Forest)
랜덤 포레스트는 배깅의 대표적인 예로 여러 결정 트리 학습, 그리고 그 결과를 분류 or 회귀 분석에 따라 적절하게 앙상블하여 최종 예측을 하는 방식이다.
특히 랜덤 포레스트는 Train 데이터를 무작위 중복 가능으로 뽑는 것 뿐만 아니라, 모델들의 각 트리를 학습할 때 사용되는 특성도 무작위로 선택한다. 이것을 통해 트리 간의 상관관계를 줄이고 다양성을 증가시킨다!
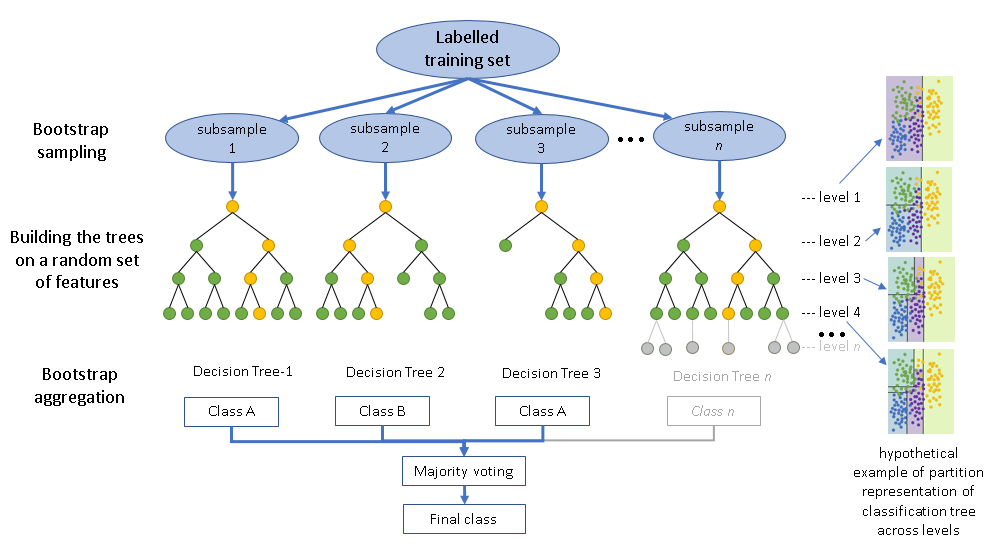
(출처 : https://medium.com/nerd-for-tech/random-forest-sturdy-algorithm-d60b9f9140d4)
부스팅(Boosting)
부스팅 또한 배깅처럼 Weak 모델들을 가지고 더 좋은 모델로 발전시키는데, 부스팅의 특징은 각 모델들을 순차적으로 학습하며, 이전 학습기의 오류를 보완하는 방식으로 개선한다는 앙상블 기법이라는 것이다.
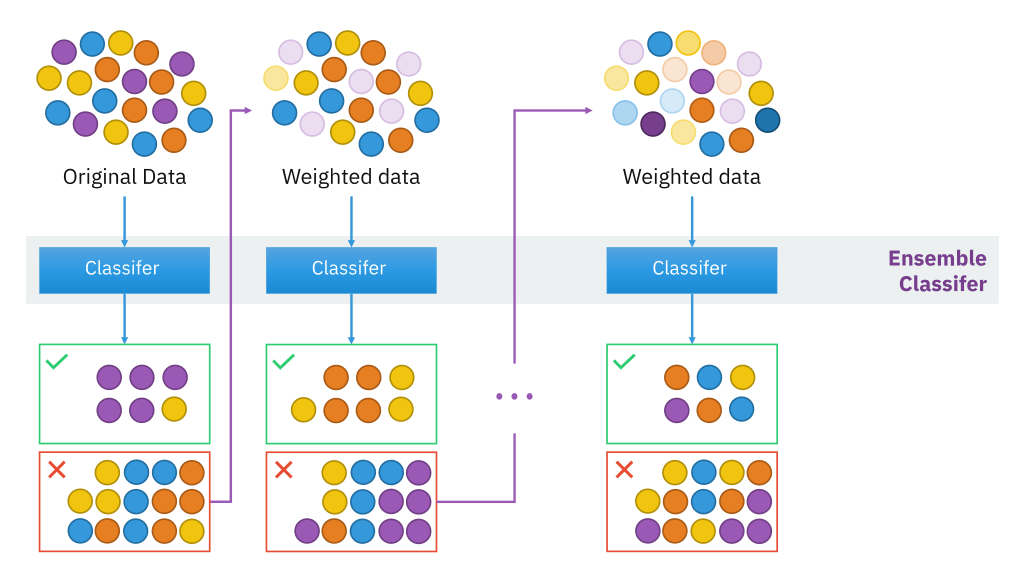
(출처 : https://sonsnotation.blogspot.com/2020/11/4-boosting.html)
부스팅의 핵심 아이디어는 잘못 예측된 데이터에 가중치는 더 주는 것으로 새로운 학습기가 그 데이터를 더 잘 학습하도록 만드는 것이다!! 마치 문제를 풀 때, 정답은 놔두고 틀린 문제만 반복해서 풀며 공부를 해나가는 공부법과 같다고 볼 수 있다.
부스팅의 주요 특징
- 순차적 학습
부스팅은 Weak 모델을 단계별로 순차적으로 학습한다. 그리고 각 모델은 전 모델의 error에 더 집중하여 개선된 예측을 하도록 시도한다.
- 학습기 결합
각 학습기의 예측 결과는 가중치가 부여된 방식으로 결합되어 최종 예측을 만든다. 잘 학습된 모델에 더 큰 가중치를 주고, 학습이 잘 안 된 모델에는 가중치가 낮게 설정된다.
- 규제 사용
부스팅은 모델이 순차적으로 학습되며 오류 집중 공략하기에 에러율이 낮은데, 이 말은 과적합의 위험이 있다는 말과 같다. 그래서 부스팅은 과적합을 피하기 위해서 규제(term)를 필수적으로 사용한다. 규제는 부스팅을 하기 전에 Hyperparameter로 모든 모델에 적용하는 기법들을 의미한다. 주요 규제 기법에는 학습률, 트리 복잡도 제한, 정규화 항 등이 있다.
※ 여기서 규제는 배깅과 스태킹에도 사용할 수 있지만, 이들은 과적합의 위험이 부스팅에 비해 적기에 덜 중요하다.
부스팅의 장단점
- 장점
- 오류 보완
부스팅은 이전 모델의 오류를 보완하는 방식으로 학습을 진행하기에, 학습 단계가 지날수록 오류가 줄어들며 더 나은 모델로 발전한다.
- 높은 성능
계속해서 오류를 없애기에 복잡한 데이터에서 매우 높은 예측 성능을 발휘한다.
- 단점
- 느린 학습 속도
부스팅은 모델이 순차적으로 학습되기에 배깅과 비교했을 때 학습 속도가 더 느리다. 특히 데이터셋이 크면 클수록 더 오래 걸린다.
- 과적합의 위험성
대표적인 AdaBoost와 같은 몇몇 부스팅 기법들은 과적합의 위험이 높다. 그러므로 정규화와 같은 규제가 필수적인 것이다!
- 파라미터 튜닝의 복잡성
부스팅은 규제를 필수적으로 사용하기에 하이퍼파라미터의 수가 많다. 하이퍼파라미터가 많으면 이들에 따라서 성능이 떨어질 수 있기에 모델의 복잡성을 높인다.
AdaBoost (Adaptive Boosting)
부스팅의 가장 기본적인 알고리즘으로 잘못 예측한 데이터에 가중치를 높여 다음 모델에 전달한다. 그리고 최종적으로 각 모델의 예측 결과를 가중치에 따라 결합하여 최종 예측을 만든다.
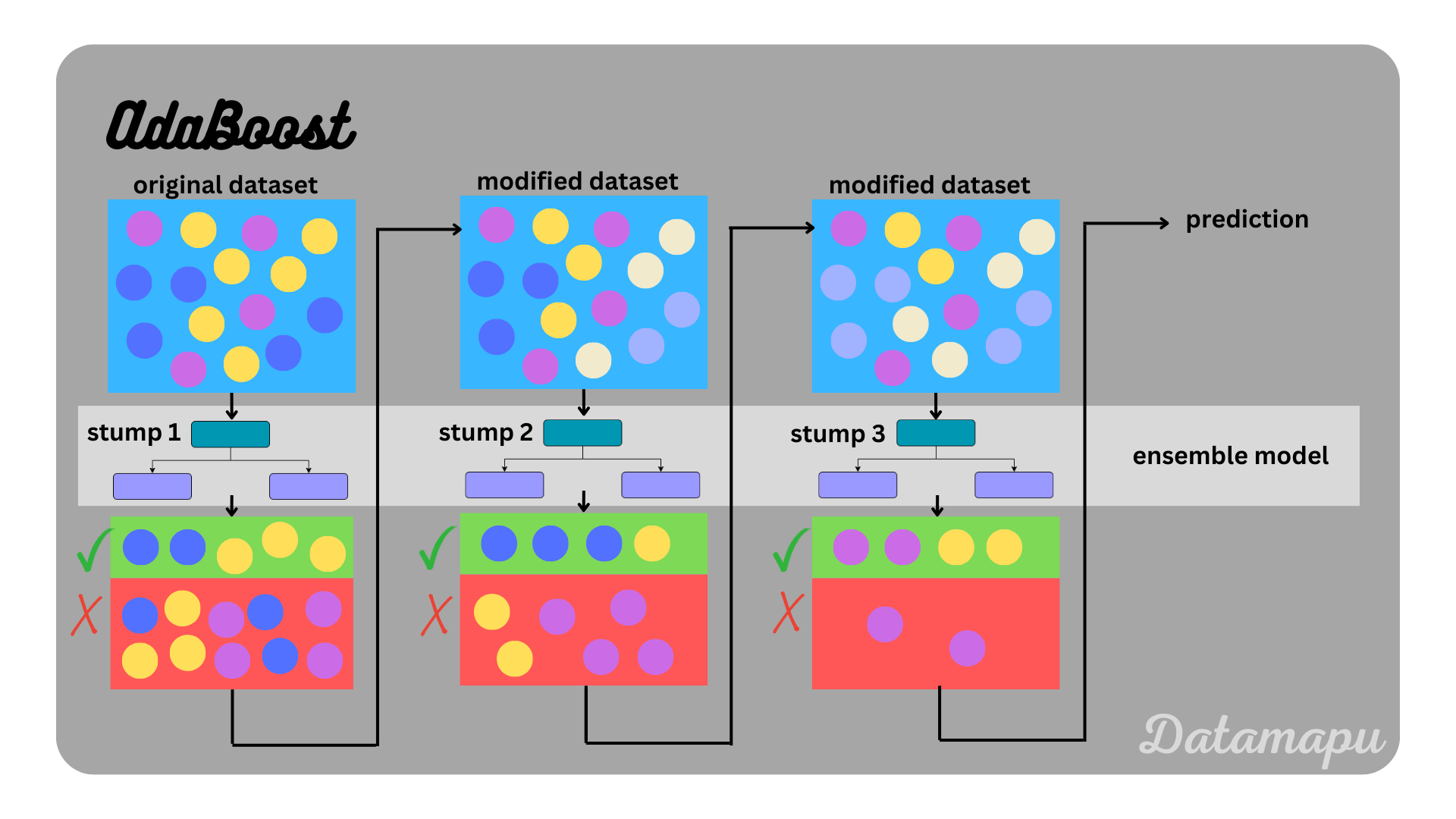
(출처 : https://datamapu.com/posts/classical_ml/adaboost/)
Gradient Boosting
AdaBoost가 틀린 문제에 대해 더욱 강조하여 주의를 주는 것(= 가중치를 주는 것)이라면 Gradient Boosting은 틀린 문제를 다시 풀어보는 것(= 잔차를 학습 목표로 삼는 것)과 같다.
Gradient Boosting은 이전 모델의 오류(잔차)를 다음 모델이 직접 학습하여 최종적으로 보완된 모델로 만드는 것을 말한다.
Gradient Boosting의 경우 오류를 계속 학습하기에 계속해서 개선되는 효과가 있고, 기여도를 해석하기 쉽다. 다만 규제에 더욱 민감하게 받아들이는 편이라 규제에 따라 성능이 많이 갈린다.
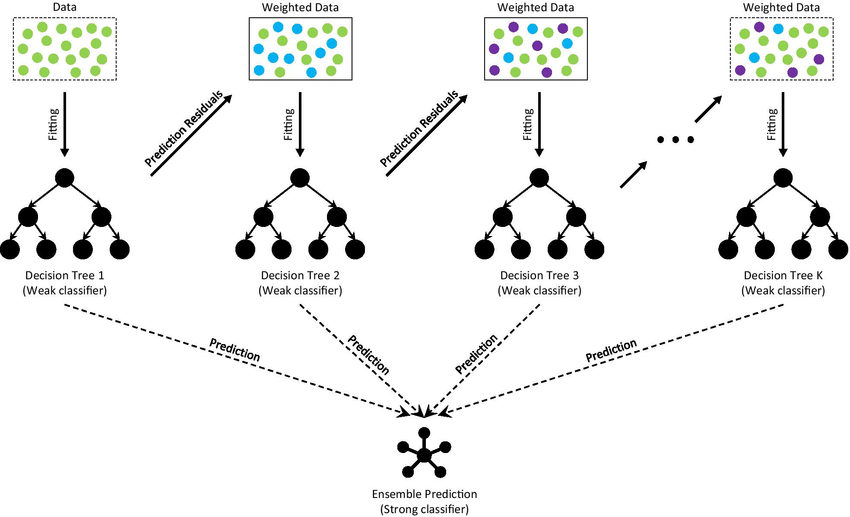
(출처 : https://www.researchgate.net/figure/The-architecture-of-Gradient-Boosting-Decision-Tree_fig2_356698772)
스태킹(Stacking)
스태킹은 실제 캐글 대회나 서비스에서 주로 사용될 정도로 고성능 모델을 설계하는데 유용한 기법이다.
스태킹은 기본적으로 여러 개의 서로 '다른' 알고리즘이나 하이퍼파라미터 설정을 가진 모델을 가져온다. 그리고 '동일한' 데이터셋을 학습해 각각 '독립적인' 예측을 수행한다.
그리고 이 모델들의 예측값들을 입력으로 메타 모델(Meta Model)에 넣어 최종 결과를 생성하는 모델이다. 보통 메타 모델에는 선형 회귀, 로지스틱 회귀, 또는 더 복잡한 모델들이 들어갈 수 있다. (전에 배운 랜덤포레스트나 XGBoost와 같은 앙상블 기법을 넣을 수도 있다.)
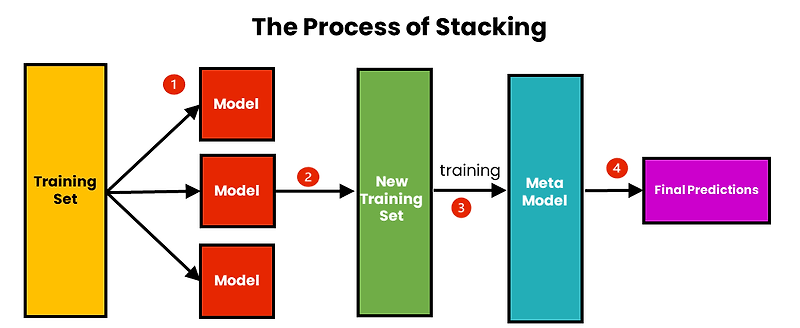
(출처 : https://tiabet0929.tistory.com/50)
스태킹의 주요 특징
- 모델의 다양성
스태킹은 앞의 배깅, 부스팅과는 다르게 서로 다른 알고리즘을 가진 모델들을 결합한다는 특징이 있다. 이 다른 모델들을 조화를 이루어 성능을 높이기에 한 모델의 약점을 다른 모델이 보완할 수 있다는 특징이 있다.
- 계층적 구조
스태킹은 동일 원본 데이터를 학습해 예측값을 생성하는 기본 모델과 앞의 기본 모델의 예측값들을 입럭으로 사용하여 최종 예측을 내는 메타 모델로 나뉜다.
- 데이터 사용 방식
기본 모델과 메타 모델이 같은 데이터로 학습되지 않도록 하기 위해 데이터 분리나 교차 검증을 사용한다.
일반적으로는 교차 검증(Cross-Validation)을 사용하여 과적합 방지 및 일반화 성능 향상을 이끈다.
스태킹의 장단점
- 장점
- 다양성
서로 다른 알고리즘의 장점들을 결합하여 성능을 높이기에 높은 성능을 달성할 수 있다.
- 유연성
스태킹이라는 기본 틀에 기본 모델과 메타 모델에 들어갈 수 있는 모델의 종류가 자유롭다. 예를 들어 기본 모델을 부스팅을 활용한 AdaBoost를 사용하고 메타 모델에 배깅을 활용한 RandonForest를 사용할 수 있다는 것이다. 결국 모델들의 자율성을 높인다.
- 단점
- 복잡성 증가
여러 모델을 따로 계획하고 학습시키고 결합하기에 타 앙상블 기법에 비해 구현과 학습에 시간이 더 걸린다.
- 과적합 위험
메타 모델은 입력값(기본 모델의 예측값)에 대해서 학습하기에 사실상 메타 모델의 입장에선 Single Model과 다름이 없다. 그러기에 Single Model의 입장에선 앙상블이 아니기에 메타 모델의 학습에서 과적합이 일어날 수 있다.
요약
- 앙상블은 기존 딥러닝에 Layer를 따라 학습하며 모델을 완성하는 것과 같이, 여러 모델을 따라 학습해 최종 모델로 학습(보완)하는 방법이다.
- 배깅은 같은 데이터에 대해 샘플링(Bootstrap)을 하여 서로 같은 모델들에 학습한 다음 최종 예측을 내는 기법이다.
- 부스팅은 각 서로 같은 모델들을 순차적으로 학습하며, 이전의 모델의 예측값을 다음 모델에 반영하는 기법이다.
- 스태킹은 같은 데이터에 대해 서로 다른 모델들로 학습하고 이 모델들의 예측값으로 최종 결과를 내는 메타 모델을 구성하는 기법이다.
