
목표
딥러닝계의 Legend 논문(이론) 중 CNN의 가장 기본 토대가 된 VGGNet과 Inception Net에 대해 배워보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
VGGNet
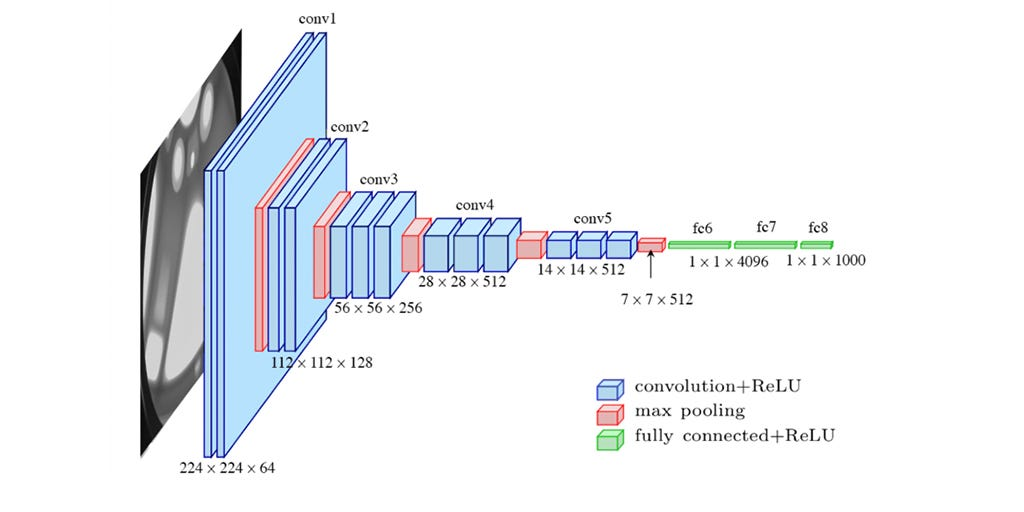 위 그림은 CNN을 배운 사람이라면 누구나 보고, 배웠을 VGGNet이라는 모델이다. 그리고 이 모델은 아래의 그림의 'D'에 해당하는 모델이다!
위 그림은 CNN을 배운 사람이라면 누구나 보고, 배웠을 VGGNet이라는 모델이다. 그리고 이 모델은 아래의 그림의 'D'에 해당하는 모델이다! 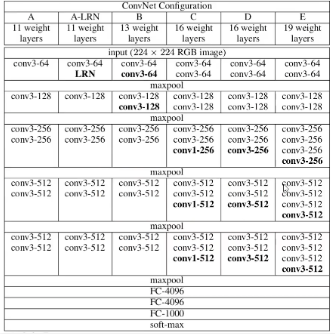 위 모델을 해석하자면 다음과 같다.
위 모델을 해석하자면 다음과 같다.
일단 짜리 RGB image를 넣는다.
이에 대해 conv3d와 maxpool(2)을 계속해서 반복하여 짜리의 CNN Layer를 만들어준다. (이 때, Padding = 1, Stride = 1이라 conv3d에선 행렬의 크기가 바뀌지 않는다!)
그리고 conv3d를 두 번 사용해주면서 5 X 5의 커널 사이즈의 효과를 얻을 뿐만 아니라, 3 X 3 커널 사이즈에서 중복되어서 훑는 부분은 더욱 집중하여 볼 수 있도록 하는 효과를 보였다!
이 다음에 FC Layer로 1000개까지 줄인다! (1000개인 이유는 ImageNet Challenge를 해결하기 위해 나온 모델이기 때문!)
마지막으로 softmax를 통해 정답을 추려낸다.
위의 VGGNet가 Legend가 될 수 있는 의미를 적어보자면 다음과 같다.
- VGGNet은 CNN의 기본적인 이론을 통해 그 당시의 최고 모델이었던 AlexNet을 가뿐히 이긴 모델이다.
- LeLU의 적극적 사용을 통해 Weight 손실을 최소화할 수 있었다!
- 3 X 3의 커널 사이즈를 두 번 사용하므로써 5 X 5와 같은 receptive field를 얻었다!
Inception Net
Inception Net은 GoogLeNet (LeNet에서 따오고 Google에서 만들어서)이라고 불리며 2014년 당시에 VGGNet과 함께 Image Challenge에 나가서 1등을 따낸 모델이다!
Inception Net은 VGGNet과 마찬가지로 CNN의 기본적인 이론을 통해 만든 모델인데, Inception Net을 구성하게 된 가장 큰 원리는 여러 커널 사이즈를 가진 conv layer를 다 통과시켜 보는 것이다!!
VGGNet의 경우에 3 X 3 커널 사이즈를 두 번 통과해서 5 X 5와 같은 receptive field를 얻는데, Inception Net의 경우 1 x 1, 3 X 3, 5 X 5, 7 X 7 등 어떤 커널 사이즈를 써야 효율적일지를 모르기에 모든 커널 사이즈를 다 사용해보는 것으로 Image를 분석하였다!!
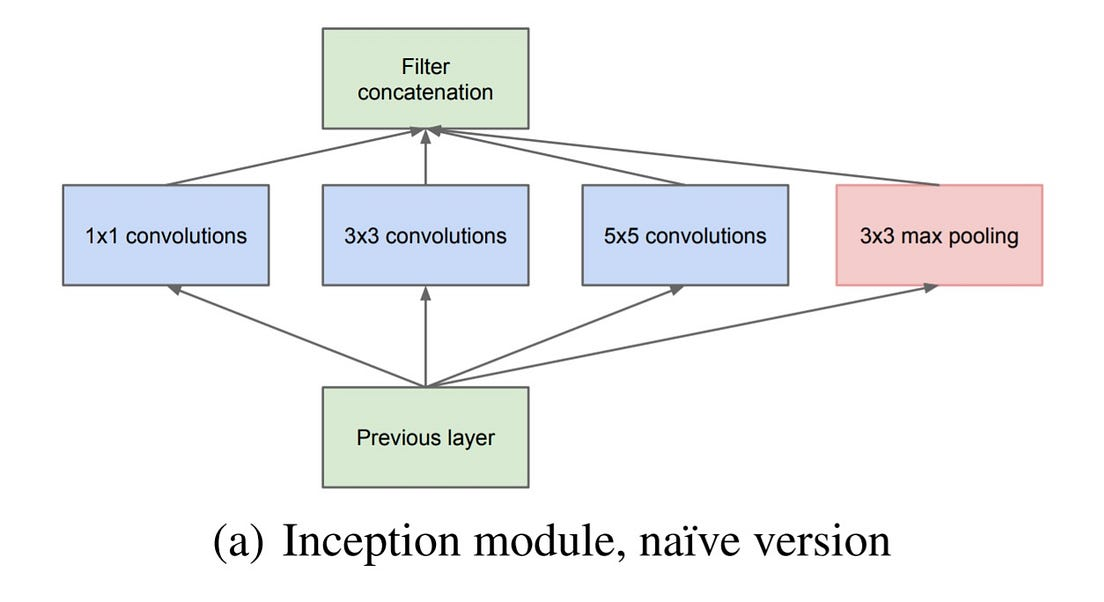 Inception Net은 위와 같이 여러 Conv와 Maxpooling을 적용하고, 이렇게 얻은 feature map들을 depth 방향으로 concat하여 기본적인 모델링을 진행하였다.
Inception Net은 위와 같이 여러 Conv와 Maxpooling을 적용하고, 이렇게 얻은 feature map들을 depth 방향으로 concat하여 기본적인 모델링을 진행하였다.
다만, 위와 같이 모델링을 하기 위해선 사이즈를 똑같게 맞춰주는 것이 중요한데, 이를 위해 Inception Net에선 Stride를 모두 1로 고정하며, Padding을 적절히 조절하여 구현하였다!
위의 그림에서 1 X 1 conv의 경우 S = 1, P = 0으로,
3 X 3 conv의 경우 S = 1, P = 1로,
5 X 5 conv의 경우 S = 1, P = 2,
3 X 3 Maxpooling의 경우 S = 1, p = 1로 진행하였다!
하지만, 위의 모델로는 여러 커널 사이즈로 Conv(Maxpooling)를 진행하기에 파라미터 수가 생각보다 많았었는데, 이에 Inception Net은 파라미터 수를 줄이기 위해 1 X 1 conv를 활용하는 방법을 사용하였다!!
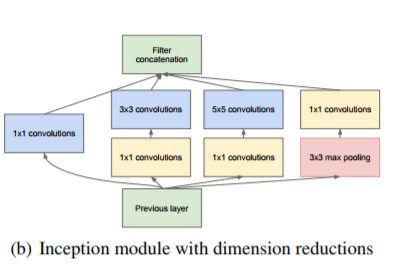 위의 그림을 보면 1 X 1 conv를 사용한 다음에 여러 커널 사이즈로 conv를 하는 것을 볼 수 있는데, 이렇게 하는 이유는 다음과 같다.
위의 그림을 보면 1 X 1 conv를 사용한 다음에 여러 커널 사이즈로 conv를 하는 것을 볼 수 있는데, 이렇게 하는 이유는 다음과 같다.
3 X 3 conv를 예를 들었을 때, Inception Net은 192개의 채널 사이즈를 128개의 사이즈로 바꾸는데, 이는 개의 파라미터 수가 나오게 된다.
하지만 중간에 1 X 1 conv를 하게 되면 192 96 128이 되므로 (1 X 1 conv을 통해 절반으로 사이즈를 줄여주고 128로 가는 것!) 이 때의 연산은 이 된다! 이를 통해 후자의 연산이 전자의 연산보다 두 배 정도 줄어들 수 있어 1 X 1 conv를 넣어주는 것이 더욱 효율적이다!!
※ 그렇다면 1 X 1 conv를 뒤가 아니라 굳이 앞에 두는 이유는?
사실상 성능에선 1 X 1 conv를 뒤에 두나 앞에 두나 비슷한데, 앞 쪽에 두는 이유는 더 파라미터 수가 작게 나오기 때문이다. 실제 연산을 해보면 앞에 두었을 때 가 나오고, 뒤에 두면 이 나오게 된다.
1 X 1 conv를 앞에 두었을 때의 파라미터 수가 더 적게 나오기에 앞에 두는 것이 더 효율적인 것이다!!
※ 그러면 3 X 3 max pooling에선 왜 1 X 1 conv가 뒤에 있나?
그 이유는 3 X 3 max pooling의 경우 어디에 1 x 1 conv가 있던지 파라미터 수에 영향을 주지 않기 때문이다. 또한 성능적으로 생각하자면, 아래의 전체 Inception Net 모델을 보았을 때, 마지막에 GAP를 진행하게 되는데, 만약 3 X 3 max pooling이 뒤에 있다면 3 X 3 max pooling 후에 GAP를 진행하기에 정보의 소실이 너무 클 수 있기에 위와 같이 사용하는게 나았을 것이다..!
이제 전체 모델을 보면 다음과 같은 모습으로 진행된다. 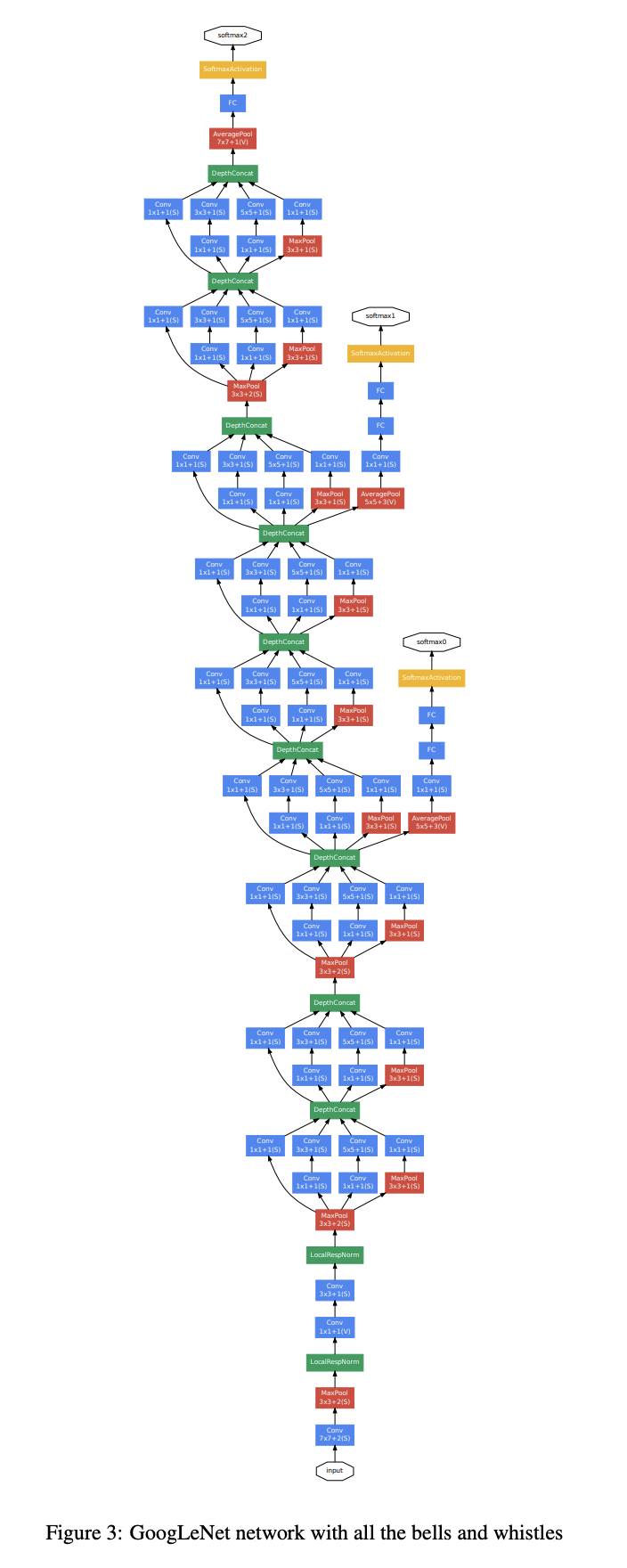 실제 위 그림을 처음 보았을 때, 너무 길고 복잡해보여서 당황스러워했는데,, 하나씩 뜯어서 살펴보면 쉽게 이해할 수 있다!!
실제 위 그림을 처음 보았을 때, 너무 길고 복잡해보여서 당황스러워했는데,, 하나씩 뜯어서 살펴보면 쉽게 이해할 수 있다!! 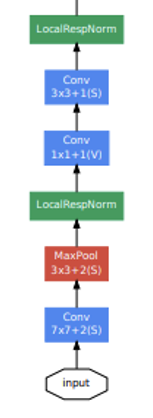 일단 아래 부분을 먼저 분석해보겠다!
일단 아래 부분을 먼저 분석해보겠다!
일단 각 레이어의 의 형태에서 는 커널 사이즈, 는 Stride를 의미한다.
그렇다면 괄호 안에 있는 S와 V는 무엇인가?
둘 다 Padding에 관련된 내용인데, S는 Same으로 Padding을 원래 사이즈와 같게, 또는 딱 절반이 되도록 한다는 의미이고, V는 Vaild로 Padding을 0으로 맞추겠다는 의미이다.
그리고 LocalRespNorm은 Local Response Normalization(LRN)이며 AlexNet에서 처음 제안되었고, 정규화를 통한 성능 향상을 위해 사용하였다. 다만 현재는 Batch Normalization과 같은 더 좋은 정규화 기술이 많기에 실제 잘 사용하진 않는다. 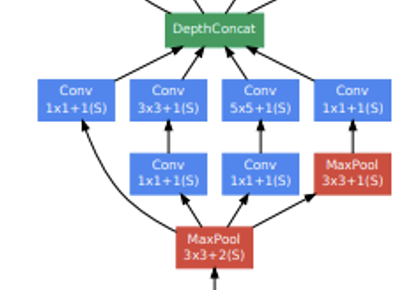 위 그림에 나오는 모델의 핵심 부분인 Inception module의 경우 위에서 설명했으니 생략하겠다.
위 그림에 나오는 모델의 핵심 부분인 Inception module의 경우 위에서 설명했으니 생략하겠다.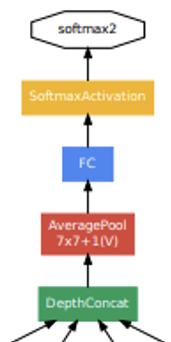 이 그림은 전체 모델의 가장 마지막 부분인데, 최종 softmax2(Classifier)에 들어가기 전에 AveragePool이 있는 것을 볼 수 있다. 이는 GAP(Global Average Pooling)으로 이전의 Feature Map을 각각 평균하여 1차원 벡터로 나타내는 것이다. 그리고 다음으로 FC Layer를 적용하는 것을 볼 수 있다.
이 그림은 전체 모델의 가장 마지막 부분인데, 최종 softmax2(Classifier)에 들어가기 전에 AveragePool이 있는 것을 볼 수 있다. 이는 GAP(Global Average Pooling)으로 이전의 Feature Map을 각각 평균하여 1차원 벡터로 나타내는 것이다. 그리고 다음으로 FC Layer를 적용하는 것을 볼 수 있다.
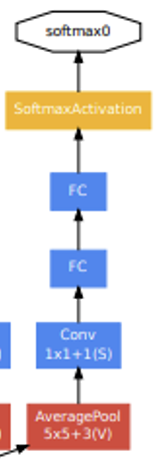 중간중간에 있는 softmax0과 이어지는 부분(softmax1과 동일)은 깊어지는 모델의 Gradient vanishing 문제를 막기 위해 나타난 개념이다. 이를 Auxiliary classifier이라고 부르며, layer 중간중간에 위치하여 중간 정도 왔을 때의 정보를 잃지 않고 추가적인 역전파를 일으키는 용도로 사용한다. 실제 모델에선 그래도 마지막 softmax2의 결과가 중요하기에 너무 큰 영향을 끼치지 않기 위해 0.3의 비율을 곱해주어 사용하였다.
중간중간에 있는 softmax0과 이어지는 부분(softmax1과 동일)은 깊어지는 모델의 Gradient vanishing 문제를 막기 위해 나타난 개념이다. 이를 Auxiliary classifier이라고 부르며, layer 중간중간에 위치하여 중간 정도 왔을 때의 정보를 잃지 않고 추가적인 역전파를 일으키는 용도로 사용한다. 실제 모델에선 그래도 마지막 softmax2의 결과가 중요하기에 너무 큰 영향을 끼치지 않기 위해 0.3의 비율을 곱해주어 사용하였다.
이를 통해 Loss는 다음과 같은 형태로 나오게 된다.
이는 Training 과정에서만 사용하였고, 실제 Test에선 만 사용하여 계산하였다. 하지만, 이는 실제 모델의 입장에서 성능을 억지로 제한하는 꼴이 되어버리기 때문에 나중에 v4로 넘어가면서 Auxiliary classifier은 사라지게 된다.
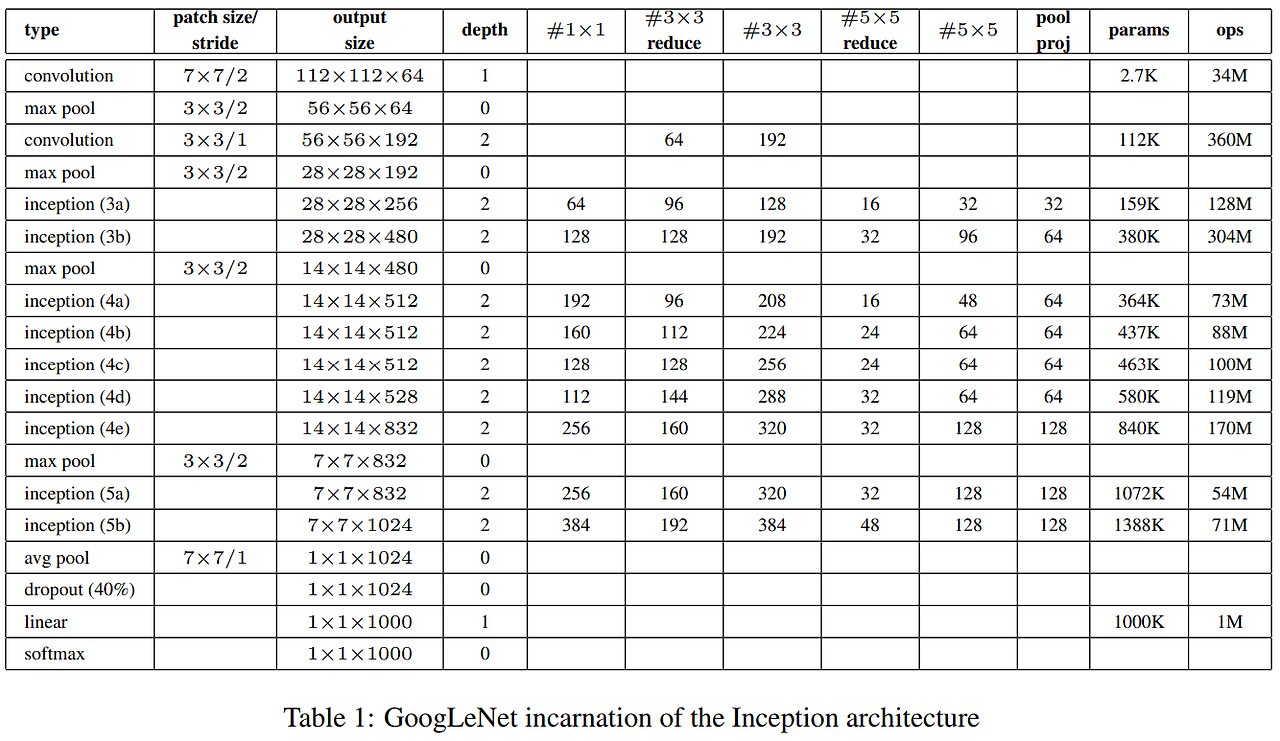 위의 그림은 Inception Net의 전체 구조를 표로 나타낸 것이다.
위의 그림은 Inception Net의 전체 구조를 표로 나타낸 것이다.
조금 표가 복잡하게 되어있지만 이를 각각 해석하자면 다음과 같다.
일단 #3 X 3 reduce와 # 5 X 5 reduce는 conv에 붙은 1 X 1 convolution을 의미한다.
그리고 pool proj는 3 X 3 maxpooling 뒤에 붙은 1 X 1 conv의 채널 수를 의미한다.
output size에 있는 숫자는 행, 열, 채를 의미한다. (요즘엔 개, 채, 행, 열로 적는데, 과거엔 이렇게 적었었다.)
그리고 #1 X 1, #3 X 3, #5 X 5, pool proj를 모두 더하면(concat) output size의 채널 수가 된다!
그리고 끝부분에서 dropout까지 진행하는 모습도 볼 수 있다. (이 때, 괄호 안의 퍼센트는 죽일 확률이다.)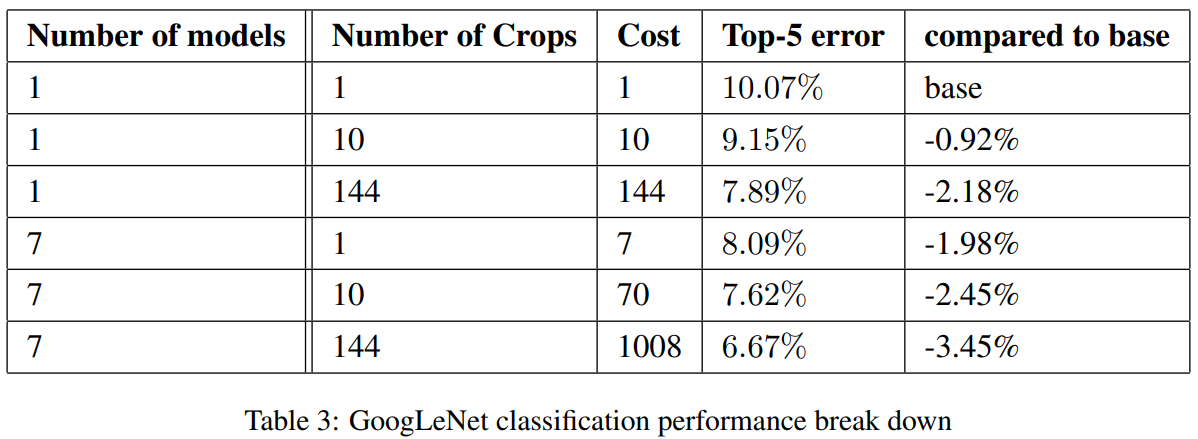 위의 그림은 Inception Net 모델을 사용하였을 때 모델의 수와 Crop 수를 다르게 하여 base보다 더 좋은 성능을 내는 것을 찾은 표이다.
위의 그림은 Inception Net 모델을 사용하였을 때 모델의 수와 Crop 수를 다르게 하여 base보다 더 좋은 성능을 내는 것을 찾은 표이다.
가장 성능이 좋은 것을 보았을 때, 모델의 수는 앞서 사용한 Inception Net 모델과 동일한 사이즈 6개에 더 큰 모델 1개를 가지고 앙상블하여 나타낸 것이다. 이 때, 6개의 모델은 구조와 초기 웨이트 값이 같은 채로 하였고, 단지 data 보는 순서만 다르게 하였다!
Crop의 수는 144개로 여러가지 resize, crop 방법으로 144개의 이미지로 변형하였다는 것을 의미한다. 이를 통해 144 * 7 = 1008개의 출력을 평균내서 나타낸 것이라고 볼 수 있다!!
이는 일종의 TTA(Test Time Augmentation)을 한 것으로 볼 수 있다.
※ Test Time Augmentation
앙상블의 한 기법으로 여러 변형을 적용하고 이를 가지고 평균을 내어 최종 예측을 하는 것이다. 이 방법으로 Test 시에 모델은 다양한 이미지의 변환에 적응하여 결과를 낼 수 있다!
위의 Inception Net가 Legend가 될 수 있는 의미를 적어보자면 다음과 같다.
- 여러 사이즈의 커널을 사용한 후 concat을 하며 성능을 크게 향상시켰다.
- 위로 인해 나타날 수 있는 모델이 너무 커지는 문제를 1 X 1 conv를 통해 해소시켰다.
- Auxiliary classifier를 통해 Gradient Vanishing 문제를 해결하고자 하였다.
- 실제 대회에서 VGGNet보다 10배 이상 적은 파라미터 수를 가지고 1등을 차지하였다!!
Inception Net v2, v3
Inception Net v2와 v3는 2015년에 한 논문에서 동시에 공개된 New 모델이다!
Inception Net v2는 VGGNet의 획기적인 아이디어였던 receptive field를 활용한 모델이고, v3는 여기서 여러가지 새로운 아이디어들을 붙여서 만든 모델이다!!
-
Factorizing Convolution
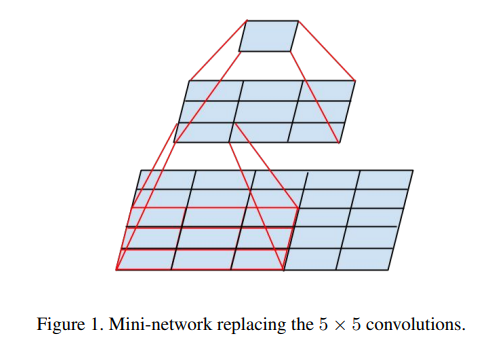 위는 VGGNet의 receptive field인데, 이는 3 X 3을 두 번 사용하면서 연산량을 줄이고자 한 것이다.
위는 VGGNet의 receptive field인데, 이는 3 X 3을 두 번 사용하면서 연산량을 줄이고자 한 것이다.
그리고 Inception Net v2(v3)는 아래의 그림과 같은 방법으로 응용하여 Inception Net v2(v3)만의 receptive field를 구현하였다!
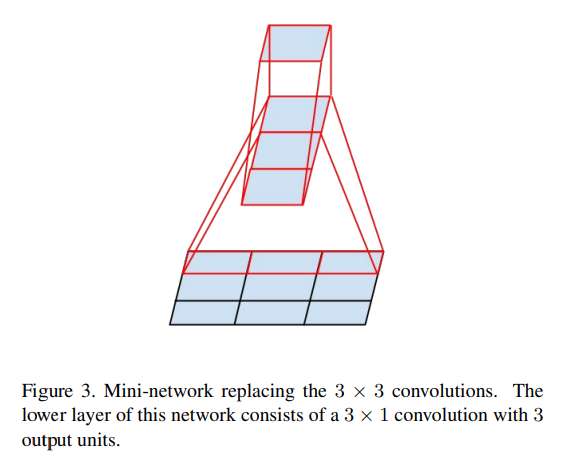 이를 적용한 모델을 보자면 다음과 같다.
이를 적용한 모델을 보자면 다음과 같다.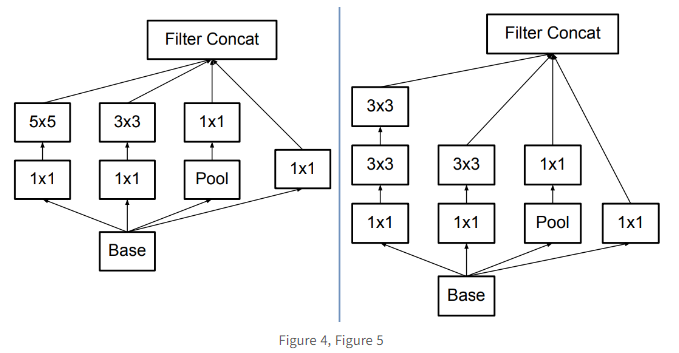 위의 그림을 보면 Figure 4는 기존의 모델이고, Figure 5는 개선된 모델인데 5 X 5를 3 X 3 두 번 사용하는 것으로 바꾼 것을 볼 수 있다.
위의 그림을 보면 Figure 4는 기존의 모델이고, Figure 5는 개선된 모델인데 5 X 5를 3 X 3 두 번 사용하는 것으로 바꾼 것을 볼 수 있다.
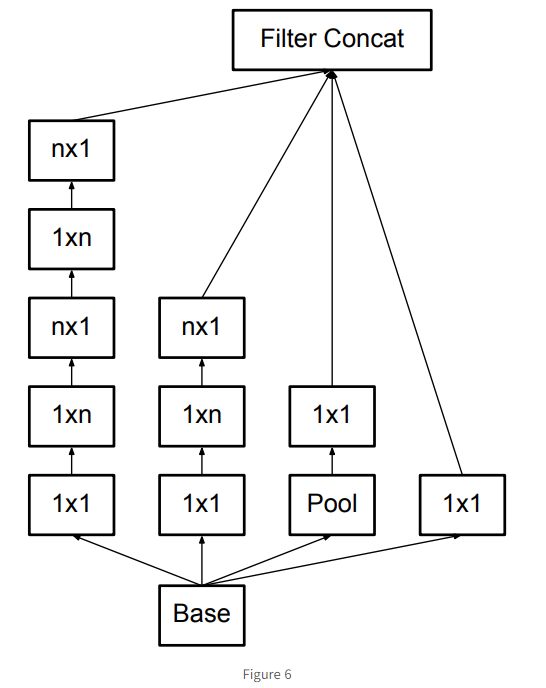 Figure 6는 3 X 3을 1 X 3 + 3 X 1로 쪼개는 것을 반영한 것이다!!
Figure 6는 3 X 3을 1 X 3 + 3 X 1로 쪼개는 것을 반영한 것이다!!
이 때, 그냥 2 X 2 두 번으로 쪼개는 것과 비교를 하자면 1 X 3 + 3 X 1은 가 나오게 되고, 2 X 2 두 번은 가 나오게 된다.
위 두 개를 비교하면 전자가 정도 더 효율적이기에 전자의 방법을 쓰는 것이다!!
Figure 6를 보면 3 X 3이 모두 1 X N + N X 1로 표현된 것을 볼 수 있고, 논문에선 n=7로 제안하였다! (즉, 7 X 7을 1 X 7 + 7 X 1로 바꾸자는 것으로 제안하였고, 아마 n=7이었을 때 제일 결과가 잘 나와서 이렇게 정했다고 추측할 수 있다.)
추가로 논문에서 말하길 Figure 6 모듈은 입력되는 feature map의 size가 작을 때 효과가 좋았어서 초반에는 Figure 5를 사용하고, 중반부터 Figure 6 모듈을 사용하는 것을 보여주었다!
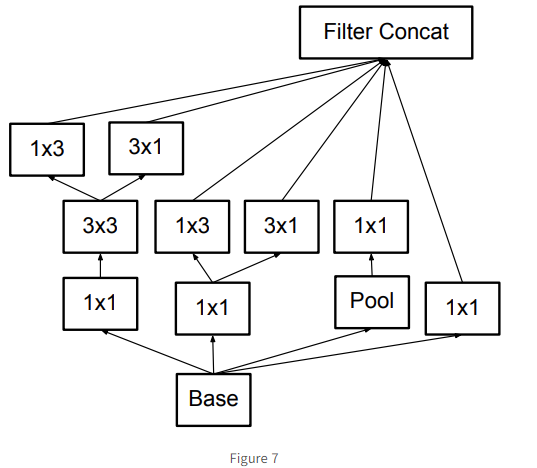 마지막으로 grid size가 가장 작을 때 (후반에) 이 모듈까지 사용하여 총 세 가지의 모듈로 Inception Net v2(v3)를 구현하였다!!
마지막으로 grid size가 가장 작을 때 (후반에) 이 모듈까지 사용하여 총 세 가지의 모듈로 Inception Net v2(v3)를 구현하였다!! -
Innovatory Downsizing
이렇게 모듈을 다 구현을 하였는데, Inception Net에선 하나의 아쉬운 부분이 있었다. 바로 모듈의 수행 후에 있는 MaxPooling인데, Filter Concat으로 된 정보를 냅다 Maxpooling 하였을 때, 병목현상(representational bottleneck)이 발생한다는 문제가 있었다. 이로 인해 정보량이 급격하게 소실되어 모델의 효율을 낮추는 단점이 존재하였다.
그래서 이를 막기 위해 아래의 그림의 오른쪽처럼(기존은 왼쪽) Conv와 Pooling의 순서를 바꾸면 병목현상은 피하지만 연산량이 3배 이상 늘어난다는 또 다른 단점이 있었다..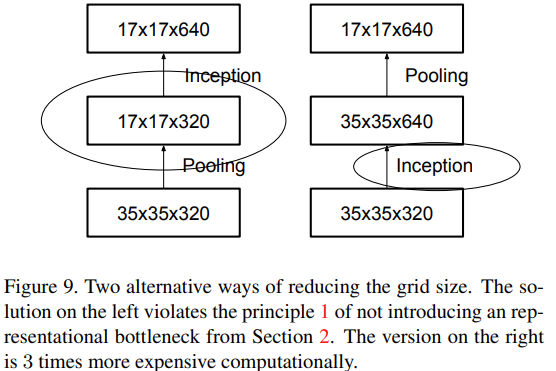 그래서 다르게 제안한 방법은 바로 stride를 2로 하여 concat을 하는 방법이었다! 이를 통해 Inception module을 통과하며 down sizing까지 가능하였다!! 그리고 이 방법은 후에 ConNeXt에서 똑같이 병목현상을 해결하기 위해 등장한 개념이다.
그래서 다르게 제안한 방법은 바로 stride를 2로 하여 concat을 하는 방법이었다! 이를 통해 Inception module을 통과하며 down sizing까지 가능하였다!! 그리고 이 방법은 후에 ConNeXt에서 똑같이 병목현상을 해결하기 위해 등장한 개념이다.
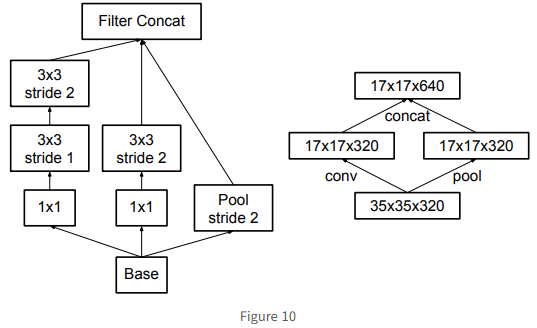
-
Auxiliary classifier
이렇게 병목현상도 해결하였고, 그 다음으로는 v1과 마찬가지로 Auxiliary classifier 또한 추가하였다. (아래 그림 참조) 다만 조금의 차이는 있는데, 바로 하나만 사용했다는 것이다. (실제 성능을 비교한 결과 입력 쪽에 있는 것은 없어도 큰 차이가 없었음!)
그리고 Aux classifier에 BN이 추가되었는데, 논문에선 dropout과 BN이 사용되었을 때, 성능이 좋아진다는 것을 보여주었다. 이를 통해 사실상 Aux classifier은 성능을 높여주는 것을 위해서가 아니라 정규화를 통한 Gradient Vanishing을 없애는 것에 초점이 맞춰져 있다는 근거가 되기도 한다..!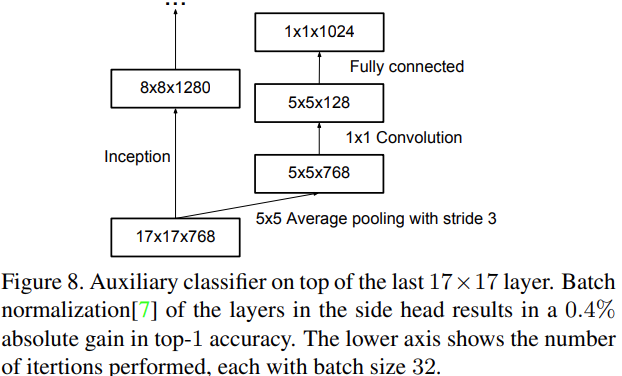
-
Label Smoothing
논문에서 Inception 개선 모델의 또 다른 특징이 있었는데, 바로 Label Smoothing이다. 기존의 one-hot encoding 방법으로 라벨링을 하였을 때에는 정답 이외에는 모두 0이기에 AI에게 직관적인 정답에 대한 확신을 주는 느낌이었다.
그래서 이를 개선하고자 0 대신 작은 값으로 Label을 사용하는 방식을 사용하였다.
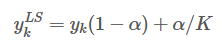
K = 클래스의 개수, = hyperparameter (논문에선 0.1로 두었다.),
= Label의 번째 값, = 기존의 one-hot coding 하였을 때의 값
위와 같이 두었다. 예를 들어 을 대입한다면 0이었던 값은 0.025, 1이었던 값은 0.925가 되어 로 바뀌게 된다!!
이를 통해 이전보다 정답의 확신을 덜 가져 더욱 고심하는 모델로 발전할 수 있었다. 이는 학습 시간은 더 오래 걸리지만 성능이 월등히 향상되는 것을 보여주었다. 그리고 Label Smoothing 방법은 후에 Transformer에도 사용되었다!!
이렇게 단점을 보완하고 여러 특성들을 더한 Inception v2의 모델 구조표를 보면 다음과 같다.
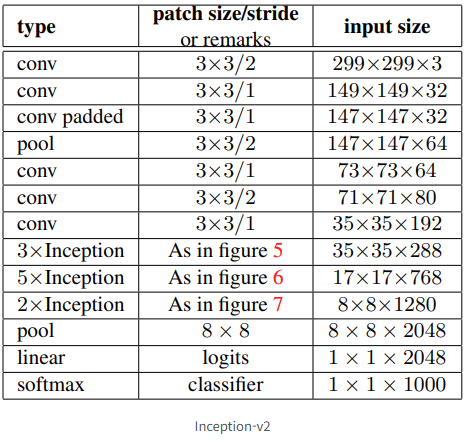 위의 표를 해석하자면 기본적으로 위의 3개의 Inception module들을 사용하며, 각각의 모듈이 N X Inception에서 N번째의 module을 지날때마다 Stride를 2로 하여 downsizing을 진행하였다!
위의 표를 해석하자면 기본적으로 위의 3개의 Inception module들을 사용하며, 각각의 모듈이 N X Inception에서 N번째의 module을 지날때마다 Stride를 2로 하여 downsizing을 진행하였다!
(다만, 마지막 2 X Inception은 Stride = 2로 두지 않았다.)
그리고 3 X Inception 위의 conv는 conv가 아니라 conv padded으로 봐야 맞다..!
위와 같이 모델을 구성하여 총 42층으로 엄청나게 복잡하지만 더욱 효율적인 모델로 발전시킬 수 있었다!!
마지막으로 Inception v3 모델을 보고자 하는데, 사실 v3는 위의 특징들 중에 v2에 적용되지 않은 것들을 싸그리 붙인 모델이다.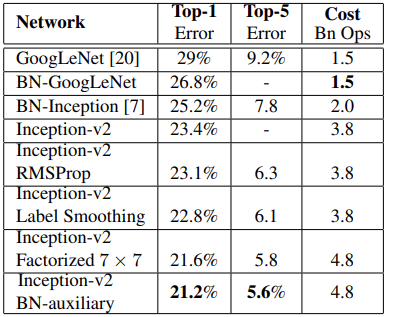 위를 보았을 때 마지막이 v3 모델이고 이는 v2 모델에 RMSProp + Label Smoothing + Factorized 7 X 7, BN-auxiliary를 다 붙인 모델이다!
위를 보았을 때 마지막이 v3 모델이고 이는 v2 모델에 RMSProp + Label Smoothing + Factorized 7 X 7, BN-auxiliary를 다 붙인 모델이다!
위의 Inception Net v2, v3가 Legend가 될 수 있는 의미를 적어보자면 다음과 같다.
- Factorization을 혁신적으로 진행하여 파라미터 수를 최소화하여 같은 receptive field를 얻게 하였다!
- downsizing을 하는 방법 중 병목현상을 피하기 위해 Stride를 2로 주는 방법을 사용하였다! (이는 나중에 ConvNeXt에서 사용됨.)
- Label Smoothing을 제안하였다. (이는 나중에 Transformer에서 사용됨.)
- aux classifier를 한 개로 줄이고 BN을 적용하였다!
