⭐복습퀴즈
❓ 범주가 적은 값을 피처로 만들어주면 생기는 문제
❗ 과대적합
❓ 너무 희소한 값이라면 one-hot-encoding할 때 어떤 전처리를 할 수 있을까?
❗ ordinal과 one-ho encoding으로 이산화, '기타' 등으로 data binning, 결측치로 처리
❓ 표준 정규분포 형태로 만들기 위해서는 스케일링 VS 로그변환 중 어떤게 먼저일까?
❗ 로그변환
❓ 왜 데이터를 정규분포 형태로 만들어주면 머신러닝이나 딥러닝에서 더 나은 성능을 낼까?
❗ 너무 한쪽에 몰려있거나 치우쳐져 있을 때보다 고르게 분포되어 있으면 데이터의 특성을 더 고르게 학습할 수 있음
❓ 음수인 값이 너무 뾰족하거나 치우쳐져 있어서 로그를 취하기 위해서는 어떻게 전처리를 해야 할까?
❗ 모든 값이 양수고 1보다 작은 값이 있을 때는 1을 더함
❓-1️⃣ 너무 큰 음수값이 있을 때, 예를 들어 -1000이라면??
❗-1️⃣ 최솟값이 1이 되게 더해주면 됨 ex) 1001을 더해줌
❓ -1000에서 1001을 더해서 로그변환을 해준 후 원래 값으로 다시 복원하려면 어떻게 해야 할까?
❗ 지수 함수로 변환하고 -1001
ex) np.exp(x) -1001
- exp를 먼저 하고 m1 으로 1을 나중에 빼줌
✅cut, qcut:
-이 방법은 RFM 기법에서도 종종 사용되는 방법으로 비즈니스 분석에서 다룰 예정
-Recency, Frequency, Monetary => 고객이 얼마나 최근에, 자주, 많이 구매했는지를 분석할 때 사용
-연속된 수치 데이터를 군간화 하면 머신러닝 알고리즘에 힌트를 줄 수 있음
-트리모델이라면 너무 잘게 데이터를 나누지 않아 일반화 하는데 도움이 될 수 있음
-> 데이터를 나누는 기준이 중요한데 EDA를 통해 어떻게 나누는 것이 예측에 도움이 될지 확인
-> 연속된 수치데이터를 나누는 기준에 따라 모델의 성능에 영향을 줌
-> 오히려 잘못 나누면 모델의 성능이 떨어질 수 있음!!
- 범주형 데이터 -> 수치형 데이터(0~N 숫자로 바꾼다면 Ordinal, 해당되는 것만 1로 만들어준다면 one-hot)
✒ iris 꽃의 품종이 3가지인데 이 값을 label로 지정할 때 버전이 업데이트 되면서 범주값을 그대로 입력해도 잘 동작
❓ LabelEncoder, OrdinalEncoder 의 입력값의 차이?
❗ Ordinal Encoding은 Label Encoding과 달리 변수에 순서를 고려한다는 점에서 큰 차이를 가짐. Label Encoding이 알파벳 순서 혹은 데이터셋에 등장하는 순서대로 매핑하는 것과 달리 Oridnal Encoding은 Label 변수의 순서 정보를 사용자가 지정해서 담을 수 있음.
-> LabelEncoder 입력이 1차원 y 값, OrdinalEncoder 입력이 2차원 X값
🔷 X => 독립변수, 시험의 문제, 2차원 array 형태, 학습할 피처
y => label, target, 정답, 시험의 답안, 1차원 벡터

✒️ X는 보통 2차원으로 대문자로 표기하고 y는 소문자로 표기하는것이 꼭 그렇게 써야된다는 아니지만 관례처럼 사용
feature_names : 학습(훈련), 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아줍니다.
label_name : 정답값
X_train : feature_names 에 해당되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 데이터셋 예) 시험의 기출문제
X_test : feature_names 에 해당되는 컬럼만 test에서 가져옵니다.
예측에 사용할 데이터셋 예) 실전 시험문제
y_train : label_name 에 해당 되는 컬럼만 train에서 가져옵니다.
학습(훈련)에 사용할 정답 값 예) 기출문제의 정답-> 공식문서 용어
Q. 인코더 3가지의 공통점
A. 범주형 데이터 -> 수치형 데이터
🎈코드
train_ohe = ohe.fit_transform(train[["MSZoning", "Neighborhood"]]).toarray()
test_ohe= ohe.transform(test[["MSZoning", "Neighborhood"]])
pd.DataFrame(train_ohe, columns=ohe.get_feature_names_out())
-> 오류나는 코드
`ohe = OneHotEncoder(handle_unknown = 'ignore')`
-> 수정 코드❓ 구분이 잘 안 되는 값에 대해 power transform 을 해주기도 하는데 반대로 너무 차이가 많이 나는 값을 줄일 때 사용할 수 있는 방법은?
❗ 꼭 정답이 있다기 보다는 EDA를 해보고 어떤 스케일링을 하면 머신러닝 모델이 값을 학습하는데 도움이 될지 고민해보면 좋음
✒️ root, log transform 도 해볼 수 있지만 변환이 정답은 아님. 성능이 올라가고 안 올라가고는 EDA 등을 통해 확인해 보고 왜 점수가 오르고 내리는지 확인해 보는 습관을 길러보세요.
- 범주형 변수 중에 어느 하나의 값에 치중되어 분포되어있지 않은지 확인
for col in train.select_dtypes(include="O").columns: col_count = train[col].value_counts(1)*100 if col_count[0] > 90: print(col)
-> 치우친 값은 드롭하거나 처리해주면 좋음
⭐0702
- test와 train 데이터의 concat
장점: 전처리를 한번만 하면 된다
단점: test에만 등장하는 데이터를 피처에 사용하면 안되는 대회 정책이 있을 때 정책 위반이 될 수 있다.
- 현실에서는 불가능한 방법(대회에서만 사용 가능)
- 다양한 변수의 타입을 확인해보고 hist를 활용해 카테고리형 변수와 연속형 변수를 구분
- 분류해준 연속형 변수를 hist를 통해서 분포를 확인
- 왜도와 첨도를 확인하여 분포가 치우쳐진 연속형 변수를 확인
(모델 학습 결과를 더 끌어올리기 위해서) - 분포가 치우쳐진 변수를 확인 후 추출하여 로그 변환을 진행
🔷 이 대회의 목적은 피처 엔지니어링을 다양하게 해보는데 있음
- aspect: plotly의 width와 같은 의미로 그래프의 너비, 가로 길이를 의미
🎈결측치
-
결측치 수와 비율을 함께 보고 싶다면 합계와 비율을 구해서 concat으로 합친다
-
concat 에서 axis=0 은 행, axis=1은 열을 의미
-
메서드체이닝을 할 때는 도움말 보기가 잘 동작하지 않기 때문에 도움말을 보기 위해서는 변수에 할당하고 사용하는 것도 좋다.
-
결측비율이 높은 값들을 제거
isna_mean[isna_mean > 0.8].index
df = df.drop(null_feature, axis=1) -
어떤 피처가 삭제되었는지 확인하기 확인
set(test.columns) - set(train.columns) -
수치형 변수를 모두 중앙값으로 대체
-
수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의
-
중앙값 외에도 평균값 등의 대표값을 대체할 수 있음
df[feature_num] = df[feature_num].fillna(df[feature_num].median())
🎈집 값과 상관계수가 높은 데이터
- SalePrice와 상관계수가 특정 수치 이상인 데이터만
df.corr()['SalePrice'][abs(df.corr()["SalePrice"])>0.5] - SalePrice와 상관계수가 특정 수치 이상인 변수의 인덱스
df.corr()['SalePrice'][abs(df.corr()["SalePrice"])>0.5].index
🎈파생변수
df['TotalSF'] = df['TotalBsmtSF'] + df['1stFlrSF'] + df['2ndFlrSF']
- 최빈값
fill_mode = ['MSZoning', 'KitchenQual', 'Exterior1st', 'Exterior2nd', 'SaleType', 'Functional'] df[fill_mode] = df[fill_median].fillna('mode')
🎈데이터 타입 바꾸기
-
수치 데이터의 nunique 구해서 어떤 값을 one-hot-encoding 하면 좋을지 찾기
-
수치 데이터를 그대로 ordinal encoding 된 값을 그대로 사용해도 되지만 범주 값으로 구분하고자 하면 category 나 object 타입으로 변환하면 one-hot-encoding 할 수 있음
-
ordinal encoding => one-hot-encoding 실습 목적
-
코드
num_nunique = df.select_dtypes(include='number').nunique().sort_values() num_nunique[num_nunique<10]
-> 성공이 높아진다는 보장은 없다!!!
🎈왜도
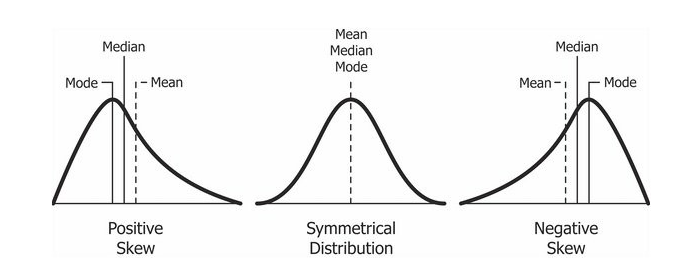
- Positive Skewness는 오른쪽 꼬리가 왼쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 Mode보다 큰 것
- Negative Skewness 왼쪽 꼬리가 오른쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 Mode보다 작은 것
❓ 왜도와 첨도의 정확한 수치까지 알아야 할까?
❗ 정확한 수치까지는 모르더라도 시각화를 해보면 알 수 있다.
-> 왜도와 첨도는 변수가 수백개 될 때 전체적으로 왠도와 첨도가 높은 값을 추출해서 전처리 할 수 있음
✒❗데이터 시각화는 우리가 데이터 인사이트를 더 쉽게 찾을 수 있도록 도와주지만, 데이터 시각화에 의해 데이터를 잘못 해석하기도 하기 때문에 항상 주의해야함❗❗
🎈로그변환
- 같은 변수에 담아줄 때 로그 변환이 여러번 되지 않도록 셀 실행을 여러번 하지 않는 것에 유의
- 실수를 할 것 같다면 다른 변수에 담아주어도 된다
num_cate_feature = df[log_features].nunique()
num_cate_feature = num_cate_feature[num_cate_feature < 20].index
num_cate_feature
num_log_feature = list(set(log_features) - set(num_cate_feature))
num_log_feature
df[num_log_feature] = np.log1p(df[num_log_feature])
df[num_log_feature].hist(figsize=(12, 8), bins=100);❓ 수치데이터의 결측치를 0으로 채우면 안되는 값?
(현실세계에서 0이면 이상한 값)
❗ 키, 몸무게, 나이, 집 평수, 혈당, 인슐린수치, 혈압
-> 화장실 수, 2층 면적, 주차장 면적 -> 해당 시설이 없다면 0이 될 수 있음
✒️plt.show()는 그래프를 보여주는 역할
✒ 기존 주피터 에서는 그래프를 보여주는게 기본값이 아니었는데 마지막 줄에 그래프를 그리는 코드가 있다면 보여주는 것이 기본 값으로 변경
✒ plt.show()를 했을 때 주피터 버전에 따라 중복 출력이 될 수도 있는데 이때는 plt.show()를 지우면 됨
🎈squared features
squared_features = ['YearRemodAdd', 'LotFrontage',
'TotalBsmtSF', '1stFlrSF', '2ndFlrSF', 'GrLivArea','GarageArea']
df[squared_features].hist(figsize=(12, 8), bins=50)
df_square = df[ squared_features] ** 2
df_square.hist(bins=100);-> 값을 강조해서 구분해서 보고자 할 때 주로 사용
🎈범주형 변수
- 범주형 변수 중에 결측치가 있는지 확인을 해보고 어떤 범주형 변수를 선택해서 모델에 사용할지 의사결정을 하게 됨.
-> 위에서 대부분의 결측치를 채워줘서 결측치가 거의 없지만 여전히 남아 있는 것도 있음
🎈피처 만들기
- label_name 변수에 예측에 사용할 정답 값 지정하기
ex)
1) 2억=> 4억으로 예측한 집값
2) 100억 => 110억으로 예측한 집값
중 어디에 더 패널티를 줄 것인가? - MAE => 1) 2억 차이 2) 10억 차이
-> 오차의 절대값 - MSE => 1) 4억 차이 2) 100억 차이
-> 오차가 크면 클수록 값은 더 벌어짐 - RMSLE => 1) np.log(2) = 0.69 2) np.log(10) = 2.30
-> 로그값은 작은 값에서 더 패널티를 주고 값이 커짐에 따라 완만하게 증가
-> 로그값이 작은 값에서 더 패널티를 주는 것은 로그 그래프를 떠올려 보기
🔷 append VS extend
1. append: 봉지과자를 통째로 넣음
a=[] a.append([1,2,3])
[[1,2,3]]
- extend: 봉지과자를 뜯어서 낱개로 넣음
a=[] a.extend([1,2,3])
[1,2,3]
✒️ 과자봉지 = iterable 혹은 컨테이너
🎈one-hot-encoding
- get dummies를 활용하면 자동으로 원핫인코딩이 됨
df_ohe = pd.get_dummies(df[feature_names])
🎈머신러닝 모델 구현
- RandomForestRegressor 모델을 사용해 KFold로 cross validation함
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)- cross_Val_score과 cross_val_predic로 점수 구하기
y_valid_predict = cross_val_predict(model, X_train, y_train, cv=kf, n_jobs=-1)🎈RMSE(원래는 RMSLE인데 이미 위에서 로그를 적용해줘서 RMSE 구함)
방법 1.
(((y_valid_predict - y_train) ** 2).mean()) ** 0.5
방법 2.
np.sqrt((np.square(y_train - y_valid_predict)).mean())
방법 3.
from sklearn.metrics import mean_squared_error mean_squared_error(y_train, y_valid_predict) ** 0.5
🎈r2_score
- 다른 오차측정 방법은 작을수록 오차가 적음을 의미하지만 r2_score는 1에 가까운 큰 값일 수록 오차가 적다
`from sklearn.metrics import r2_score
r2_score(y_train, y_valid_predict)`
--윗 줄까지 모의고사 풀어봄--
🎈실전
-
학습과 예측
y_predict = model.fit(X_train, y_train).predict(X_test) -
제출 파일 양식
submit = pd.read_csv('data\\house\\sample_submission.csv') -
정답 옮겨 적기
submit['SalePrice'] = np.expm1(y_predict)
🔷 리더보드에 있는 점수와 동일한 스케일 점수를 미리 계산해 보기 위해서는 로그 적용한 값으로 계산해주지만
🔷 제출할 때는 지수함수를 적용해서 원래 스케일로 복원하여 제출해야함
❗❗❗ 내부에서 평가할 때는 제출받은 값에 로그를 취해서 점수를 평가하지만 제출할 때는 지수함수를 적용해서 제출해야함❗❗❗ -
csv 파일로 저장하기
submit.to_csv(file_name, index=False)
🎈정리
💥 수치형 데이터에 할 수 있는 전처리
-> 결측치 대체
=> 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지 주의
-> 스케일링: standard, Min-Max, Robust
-> 변환: log
-> 이상치(너무 크거나 작은, 범위를 벗어나는 값) 제거 혹은 대체
-> 오류값(잘못된 값) 제거 혹은 대체
-> 이산화: cut, qcut
💥 범주형 데이터에 할 수 있는 전처리
-> 결측치 대체
-> 인코딩: label, ordinal, one-hot-encoding
-> 범주 중에 빈도가 적은 값은 대체하기
⭐0802 실습(회귀모델)
- 제조 데이터는 보통 생산 공정 센서 데이터를 주로 사용(온도, 습도, 위치, 환경 등에 대한 데이터가 있음)
- 센서 데이터는 해당 센서 제품에 따라 로그를 기록할 때 DB에 기록하기도 하고 파일로 기록하기도 함
🎈선형 회귀
: 종속 변수 y와 한 개 이상의 독립변수 X와의 선형 상관 관계를 모델링하는 회귀 분석 기법
-> 선형 예측 함수를 사용해 회귀식을 모델링하고 알려지지 않은 파라미터는 데이터로부터 추정
- 주요 파라미터
- fit_intercept: 절편을 계산할지 여부(False로 설정하면 계산에 절편 사용X)
- n_jobs: 계산에 사용할 스레드 수
- 특징
- 다른 모델들에 비해 간단한 작동 원리
- 학습 속도 매우 빠름
- 조정해줄 파라미터가 적음
- 이상치에 큰 영향
- 데이터가 수치형 변수로만 이뤄져 있을 경우, 데이터의 경향성이 뚜렷할 경우 사용하기 좋음
🎈One-Hot-Encoding
- handle_unknown = 'ignore' train에는 등장하지만 test에는 없다면 무시하지만 train으로 피처의 기준을 만드는데 test에 train에 없는 값이 있다면 그 값은 피처로 만들지 않음
- fit은 train에만 함. test에는 fit을 하지 않음. train을 기준으로 삼기 위해서.
- test는 transform만 함
- onehotencoder는 전체 데이터를 변환하기 때문에 범주가 아닌 수치 데이터도 모두 인코딩하기 때문에 범주값 데이터만 다로 넣어 인코딩 해줘야 함
- pd.get_dummies()의 장점: 이런 전처리 없이 범주 데이터만 onehotencoding 한다
`from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='if_binary', handle_unknown='ignore')
train_ohe = ohe.fit_transform(train.select_dtypes(exclude='number'))
test_ohe = ohe.transform(test.select_dtypes(exclude='number'))
print(train_ohe.shape, test_ohe.shape)`
🔷 반환값이 np.array 형태이기 때문에 데이터 프레임으로 별도의 변환이 필요
- 인덱스
: csv 파일을 불러올 때 index_col='Id'를 했기 때문에 index값을 변경해줘야 한다.
🔷 사이킷런으로 인코딩 하면 numpy array 형태로 반환이 되는데 여기에는 index 정보가 없음
df_train_ohe.index=train.index df_test_ohe.index=test.index
- df_train과 기존의 train 값을 합치는 과정
(인코딩된 피처와 기존의 수치 데이터를 병합해 주는 과정)
df_train= pd.concat([df_train_ohe, train.select_dtypes(include='number')], axis=1)
-> train과 인코딩 된 df_train의 행 수가 같은지 확인하고 칼럼이 늘었는지도 확인
🎈데이터 셋 나누기
- cross validation 말고 hold-out-validation을 사용
- train_test_split 기능을 사용해서 train, valid를 나눔
- valid를 만드는 이유는 제출하기 전에 어느 정도의 스코어가 나올지 확인해보기 위함
- hold-out-validation은 cross validation에 비해 속도가 빠름/ 신뢰도는 낮음
X = df_train.drop(columns='y') y = df_train['y']
- train_test_split를 사용하기
X_train, X_valid, y_train, y_valid = train_test_split(
X,y,test_size=0.2, random_state=42)
X_train.shape, X_valid.shape, y_train.shape, y_valid.shape🎈선형회귀 모델
종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관계를 모델링하는 회귀분석 기법
- 특징
- 다른 모델들에 비해 간단한 작동 원리를 가지고 있다.
- 학습 속도가 매우 빠르다.
- 조정해줄 파라미터가 적다.
- 이상치에 영향을 크게 받는다.
- 데이터가 수치형 변수로만 이루어져 있을 경우, 데이터의 경향성이 뚜렷할 경우 사용하기 좋다
- 선형 회귀 모델의 단점을 보완한 모델
- Ridge
- Lasso
- ElasticNet
ex) ''아버지의 키가 크면 아들의 키도 큰가'' 를 알아보는 것
✅LinearRegression
LinearRegression(
*,
fit_intercept=True,
normalize='deprecated',
copy_X=True,
n_jobs=None,
positive=False,
)
from sklearn.linear_model import LinearRegression
model = LinearRegression(n_jobs=-1)
model.fit(X_train, y_train) -> 학습 *R2 score 정확도 출력
model.score(X_valid, y_valid)
💥💥정리
-선형회귀보다 트리계열 모델을 사용하면 같은 데이터셋임에도 훨씬 나은 성능을 보임
-이상치도 포함되어 있음. 회귀모델을 이상치에 민감하기도 하고 다른 수치데이터에 대해 전처리가 많이 필요함
-선형회귀는 간단하고 이해하기 쉽다는 장점이 있음.
-선형회귀에 맞는 데이터셋을 사용한다면 좋은 성능을 낼 수 있음
💥 원핫인코딩을 범주형 변수에 해주고 수치데이터와 합치는 과정을 배움
💥 ordinal 인코딩 방법 학습
💥 concat -> 인덱스 값이 맞지 않으면 제대로 병합되지 않을 수 있기 때문에 인덱스 값에 유의가 필요
💥 기존에는 cross validation을 이용했지만 0801에서는 hold-out-validation 사용
💥 hold-out-validation 은 속도가 빠르지만 신뢰가 떨어짐
💥 train, valid, test => train, test split은 train과 test만 나눔
-> train을 다시 train, valid로 나눠줌
⭐0802 - 배깅
🎈결정트리
- 장점
- 결과를 해석하고 이해하기 쉽다
- 자료를 가공할 필요가 거의 없음
- 수치 범주 자료 모두에 적용 가능
- 화이트박스 모델
- 안정적
- 대규모의 데이터 셋에서도 잘 동작
- 주요파라미터
criterion: 가지의 분할의 품질 측정
max_depth: 트리의 최대 깊이
min_samples_split: 내부 노드를 분할하는데 필요한 최소 샘플 수
min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
max_leaf_nodes: 리프 노드 숫자의 제한치
random_state: 추정기의 무작위성 제어
🎈이상치 확인
sns.scatterplot(data=train, x=train.index, y='y')
🎈이상치 제거
train = train[train['y']<200].copy()
🎈인코딩
ohe = OneHotEncoder(handle_unknown = 'ignore')
train_ohe = ohe.fit_transform(train.drop(columns='y'))
test_ohe = ohe.transform(test)
train_ohe.shape, test_ohe.shape🎈학습, 검증 세트 나누기
from sklearn.model_selection import train_test_split
X_test = test_ohe
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=0.1, random_state=42)-> test 사이즈를 0.1로 하여 train이 많이 학습할 수 있도록 함
⭐용어
✒️ 앙상블
: 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
1. 랜덤 포레스트
2. 그래디언트 부스팅
✒️ 배깅
: 부스트 트랩을 통해 조금씩 다른 훈련 데이터에 훈련된 기초 분류기들을 결합
: 편향은 그대로 유지하면서 분산은 감소
✒️ 엑스트라 트리 모델
: 극도로 무작위화된 모델
: 약간 더 큰 편향 증가를 희생시키면서 모델의 분산을 조금 더 줄일 수 있음
-
주요파라미터
n_estimators: 숲에 있는 나무의 수
criterion: 분할의 품질을 측정하는 기능
max_depth: 트리의 최대 깊이
min_samples_split: 내부 노드를 분할하는데 필요한 최소 샘플 수
max_features: 최상의 분할을 찾을 때 고려해야할 기능의 수 -
특징
- 분기 지점을 랜덤으로 선택하기 때문에 랜덤 포레스트보다 속도가 빠름
- 1과 동일한 이유로 랜덤포레스트보다 더 많은 특성 고려
- 랜덤포레스트와 동일한 원리를 이용하기 때문에 많은 특징 공유
- 랜덤포레스트와 비교해 성능이 미세하게 우위에 있음
✒️ GBT: 그레디언트 부스팅
- 부스팅: 편향과 분산을 줄여 강력한 트리를 생성하는 기법, 틀린거 위주로 학습
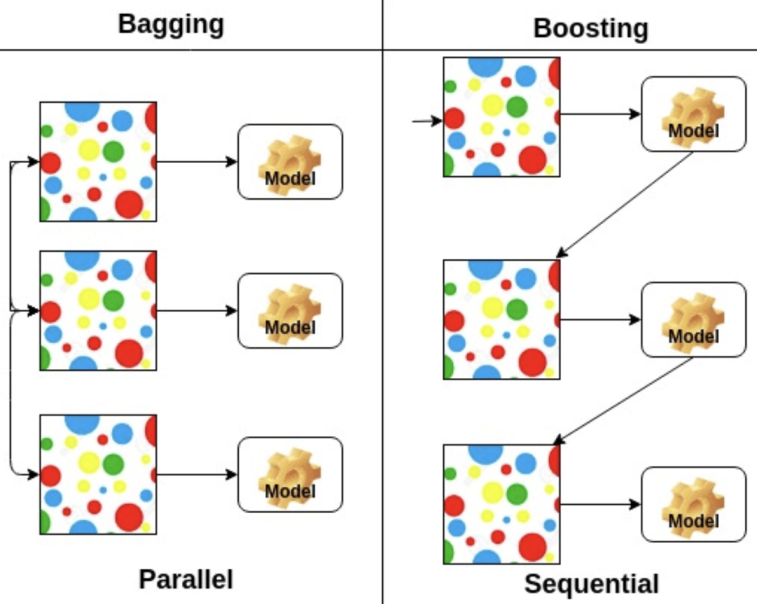
- bagging과 boosting의 차이?
-> 배깅: 데이터 셋 모델마다 독립적/ 부스팅: 앞 모델이 데이터 셋을 정해줌
❓ GBM, XGBoost, LightGBM, 모델이름에 들어가는 G 는 무엇을 의미?
❗ 기울기, 경사
-> 손실함수 그래프에서 값이 가장 낮은 지점으로 경사를 타고 하강. 머신러닝에서 예측값과 정답값간의 차이가 손실함수인데 이 크기를 최소화시키는 파라미터를 찾기 위해 사용
- epoch: n_estimators 와 같은 개념, 학습 횟수
- learning_rate: 학습률을 의미하는데 보폭이라고 번역. 보폭이 너무 크면 대충 찾기 때문에 최소점을 지나칠 수 있음
- Residual: 잔차
✒️ 오차와 잔차 비슷한 의미이지만 다른 의미로 보기도 함
✒️ GMB(Gradient Boosting Machine)
회귀 또는 분류 분석을 수행할 수 있는 예측 모향
- 특징
- 랜덤 포레스트와 다르게 무작위성이 없다
- 매개변수를 잘 조정해야하고 훈련시간이 김
- 데이터의 스케일에 구애X
- 고차원의 희소한 데이터에 잘 작동X
❓ 성능에 고려 없이 GBM에서 훈련 시간을 줄이는 방법
❗ learning_rate == 학습률 == 보폭을 올린다
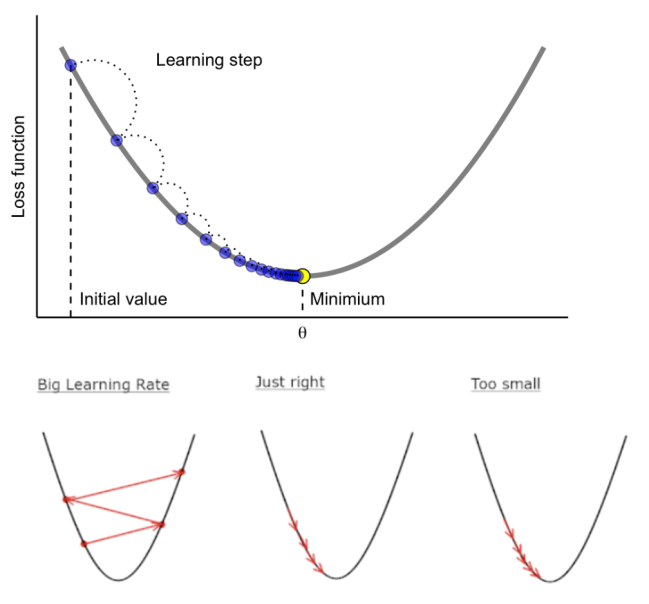
-> 보폭을 크게 하면 훨씬 빨리 걷게 된다. 그렇기 때문에 learning_rate 를 올리면 학습시간은 줄어들지만 제대로 된 loss(손실)가 0이 되는 지점을 제대로 찾지 못할 수도 있다.
❓ GBM은 왜 랜덤 포레스트와 다르게 무작위성이 없을까?
❗ 이전 오차를 보완해서 순차적으로 추출하기 때문
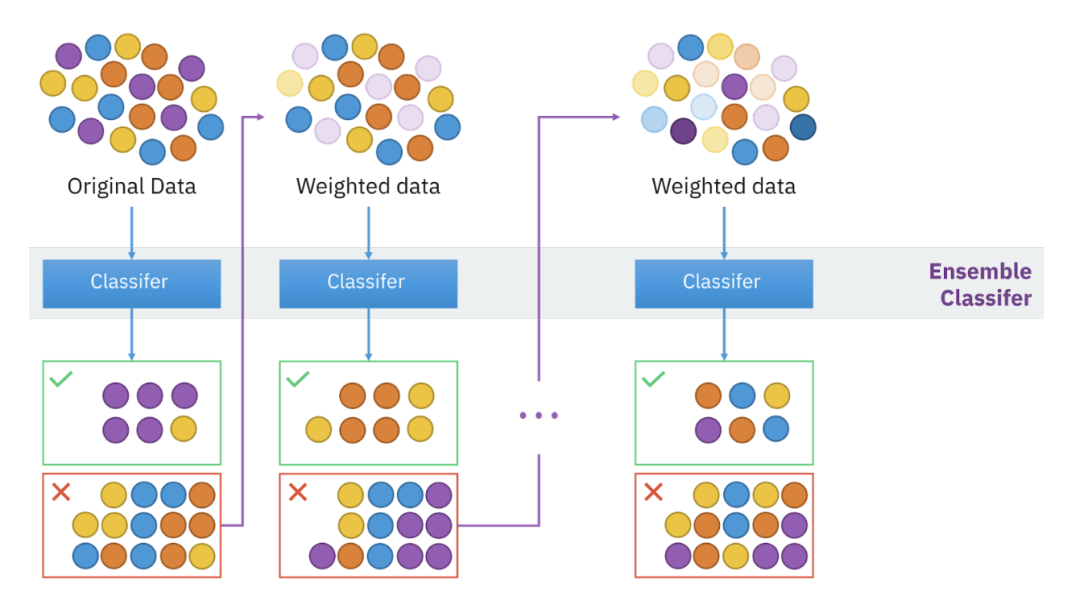
❓ absolute loss 는 지원은 하지만 squared loss 를 더 많이 사용할까?
❗ 기울기가 +, - 방향에 따라 같은 기울기가 나오기 때문에 방향은 알 수 있지만 기울기가 같아서 미분을 했을 때 방향에 따라 같은 미분값이 나와서 기울기가 큰지, 작은지 비교할 수 없다. 그래서 squared loss 를 더 많이 사용
✒️ XGBoost
: 모든 가능한 트리를 나열하여 최적 트리를 찾는 것은 불가능하므로 2차 근사식을 바탕으로 한 손실함수를 토대로 매 iteration마다 하나의 leaf로부터 가지를 늘려나는 것이 효율적
-> 손실함수가 최대한 감소하도록 하는 split point(분할점)를 찾는 것이 목표
- 장점
- 병렬 처리로 GBM 대비 빠른 수행시간
- 과적합 규제
- 다양한 옵션
- 조기 종료 기능
- 단점
- GBM에 비해 좋은 성능, 빠른 속도지만 그래도 학습시간이 느림
- 모델의 overfitting
