11/14~11/16 앙상블 모델 종류
⭐1. 앙상블
- 정의: 여러 머신 러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
→ 강력한 하나의 모델을 사용하는 대신 보다 약한 모델 여러 개를 조합하여 더 정확한 예측에 도움을 주는 방식
- 앙상블 학습 유형
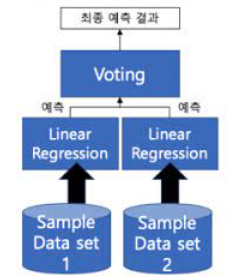
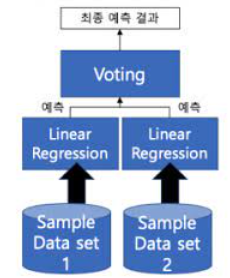
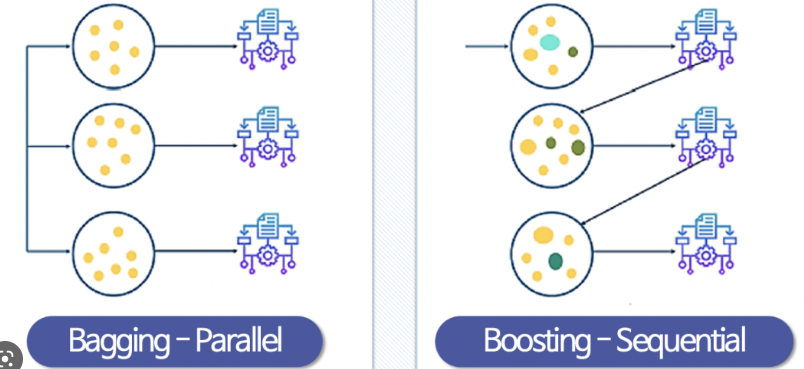
🎈1. voting
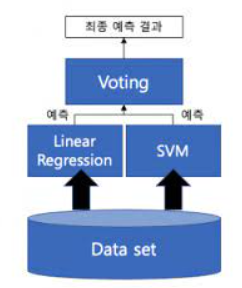
• 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
• 서로 다른 알고리즘을 여러 개 결합하여 사용
🔷 하드 보팅: 다수의 분류기가 예측한 결과값을 최종결과로 선정
🔷 소프트 보팅: 모든 분류기가 예측한 결정 확률 평균을 구한 뒤 가장 확률이 높은 레이블 값을 최종 결과로 선정
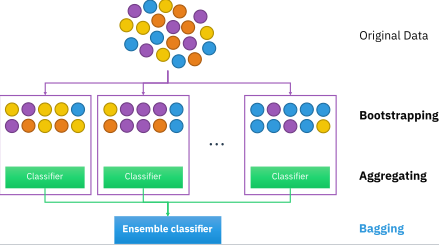
🎈2. bagging
• 데이터 샘플링(Bootstrap) 을 통해 모델을 학습시키고 결과를 집계(Aggregating) 하는 방법
• 모두 같은 유형의 알고리즘 기반의 분류기를 사용
🔷 Categorical Data: 다수결 투표 방식으로 집계
🔷 Continuous Data: 평균 값 집계
• 대표적인 배깅 : 랜덤 포레스트 알고리즘
🎈3. boosting
• 여러 개의 분류기가 순차적으로 학습을 수행
• 이전 분류기가 예측이 틀린 데이터에 가중치를 부여하면서 학습과 예측을 진행
• 대표적인 부스팅 – XGBoost, LightGBM
⭐2. 랜덤 포레스트
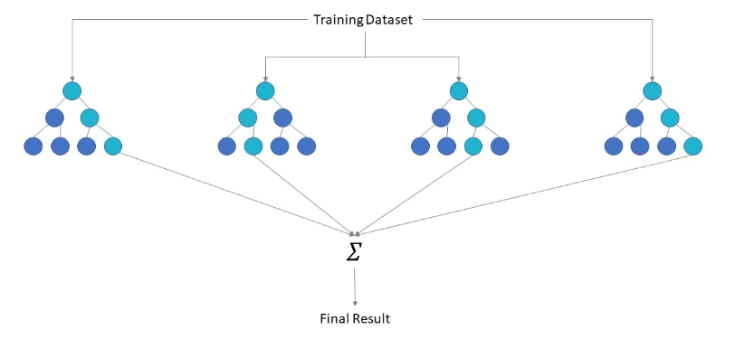
🎈1. 정의
Decision Tree의 특정 데이터에만 잘 작동할 가능성이 크다는 단점을 극복하기 위해 만들어진 알고리즘으로, 같은 데이터에 대하여 Decision Tree를 여러 개 만들어, 그 결과를 종합해 내는 방식
🎈 장점
일반화 및 성능 우수
파라미터 조정 용이
데이터 scale 변환 불필요
overfiting이 적음
🎈 단점
개별트리 분석이 어렵고 트리 분리가 복잡해질 수 있음
차원이 크고 희소한 데이터는 성능 미흡
🎈2. Random Forest Regressor 코드
#sklearn 공식 문서 예시
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, n_informative=2,
... random_state=0, shuffle=False)
regr = RandomForestRegressor(max_depth=2, random_state=0)
regr.fit(X, y)
RandomForestRegressor(...)
print(regr.predict([[0, 0, 0, 0]]))
[-8.32987858]🎈3. Random Forest Classifier 코드
#sklearn 공식 문서 예시
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,
... n_informative=2, n_redundant=0,
... random_state=0, shuffle=False)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(X, y)
RandomForestClassifier(...)
print(clf.predict([[0, 0, 0, 0]]))⭐3. Extra Trees 정의 및 예시 코드
🎈1. 정의
극도로 무작위화(Extremely Randomized)된 기계 학습 방법
데이터 샘플 수와 특성 설정까지 랜덤
랜덤 포레스트와 동일한 원리를 이용하기 때문에 많은 특성을 공유함
랜덤 포레스트에 비해 속도가 빠르고 성능도 미세하게 높음
Bootstrap 샘플링을 사용하지 않고 전체 특성 중 일부를 랜덤하게 선택해 노드 분할에 사용 → 무작위 분할 중 가장 좋은 것을 분할 규칙으로 선택
Extra Trees - 임의 분할
Random Forest - 최적 분할
🎈2. Extra Trees Regressor 코드
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.ensemble import ExtraTreesRegressor
X, y = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split
(X, y, random_state=0)
reg = ExtraTreesRegressor(n_estimators=100, random_state=0).fit(
X_train, y_train)
reg.score(X_test, y_test)🎈3. Extra Trees Classifier 코드
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_features=4, random_state=0)
clf = ExtraTreesClassifier(n_estimators=100, random_state=0)
clf.fit(X, y)
ExtraTreesClassifier(random_state=0)
clf.predict([[0, 0, 0, 0]])✅공통점
- 앙상블 알고리즘
랜덤 포레스트는 의사결정 나무를 앙상블하고 엑스트라 트리(Extra Trees)는 엑스트라 트리(Extra Tree)를 앙상블 함
- main 하이퍼파라미터가 동일
✅차이점
- 부스트랩 사용 여부
랜텀포레스트는 부스트랩 샘플과 랜덤한 후보 특성들을 사용해 여러개의 결정트리(Decision Tree)를 앙상블
엑스트라 트리(ExtraTrees)는 bootstrap=False가 기본값
- 노드 분할 방법
램덤 포레스트는 최적의 분할을 선택하고 엑스트라 트리는 무작위로 선택하기에 엑스트라 트리가 더 빠름
- 편향과 분산 발생 차이
엑스트라 트리는 모든 샘플을 사용해 랜덤 포레스트보다 편향이 감소되고 무작위화로 분산이 감소
⭐4. XGBoost
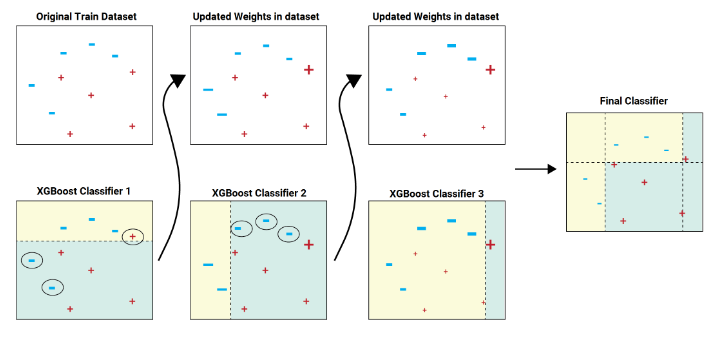
🔷GBM의 문제로 새로운 모델 탄생
-> 느리다, 과적합의 문제가 있다
- 🎈특징
- 속도가 엄청 빠르지는 않지만 gbm보다는 빠름
- 과적합 방지 가능 규제가 있음
- 분류 회귀 둘 다 가능
- 조기 종료 제공
- 가중치 부여를 경사하강법으로 함
⭐5. LightGBM
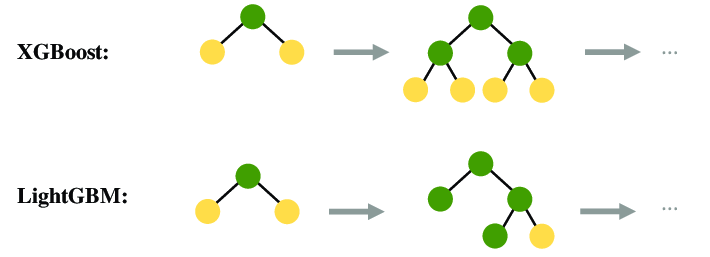
XGBoost는 매우 뛰어난 부스팅 알고리즘이지만, 학습시간이 오래걸림
-> LightGBM: XGBoost보다 학습에 걸리는 시간이 훨씬 적다
또한 메모리 사용량도 상대적으로 적습니다.
- 🎈특징
-
더 빠른 학습과 예측 수행시간
-
더 작은 메모리 사용량
-
카테고리형 피처의 자동변환과, 최적분할(원핫인코딩안하고도 카테고리형 피처로 만듬.)
