머신러닝 복습 1
⭐들어가기 전
머신 러닝: 인공지능을 구현하는 방법 중 하나, 유용한 함수를 사용하여 학습하는 것
ex) 암 진단, 자율주행자동차를 운행하는 데 있어서 안전도를 검증
- 과거의 AI: Knowledge Engineering
-> 지식을 잘 조직해서 유용한 함수 만들기(사람이 함수를 직접 코딩) - 최근의 AI: Machine Learning
-> 함수의 기본적인 형태를 컴퓨터에게 알려주고 training하는 과정에서 최종적인 좋은 함수를 컴퓨터 스스로 학습
✒ 딥러닝도 머신러닝의 일종, 머신러닝의 하위 알고리즘
-> AI 비서, 오케이 구글 등의 데이터들을 모델링하는데 사용
⭐개념정리
1. 인공지능: Artificail Intelligence
사람의 인지하고 의사결정을 하는 일련의 인지능력들을 컴퓨터 알고리즘으로 모사해서 현실 문제 해결에 활용하는 기술들의 총 집합
2. 머신러닝: Machine Learning
인공지능 구현의 한 가지 방법, 데이터를 이용해서 유용한 함수를 학습하는 방법
3. 딥러닝: Deep Learning
머신러닝의 하위 분야, 인간의시각능력. 언어적 능력, 음성, 오감 등과 관련된 인지능력들을 모델링 하는데 있어 좋은 성능을 보임
🔷 사람의 인지능력, 지적능력을 모사하는데 있어 좋은 성능을 보이고 이러한 것들이 현실 문제를 해결하는데 있어서 중요한 역할을 함
-> 딥러닝 외에도 linear regreesion, decision tree 등등이 머신러닝 방법 중 하나
✒️ 완벽한 머신러닝 알고리즘은 없다!
⭐왜 머신러닝?!
-
우리는 빅데이터 시대에 살고 있다
-> 머신러닝 = 데이터를 활용한 방식이기에 빅데이터 시대에 머신러닝이 각광을 받는 것들은 당연지사!
ex) 항공산업, 석유 추출 및 생산, 마트 및 편의점 등에서의 리테일링 서비스, 운송 서비스 등에 적용 -
많은 양의 데이터를 효율적이고 빠른 계산이 가능한 장비의 등장
: GPU computing 기술 -> 연산 장비 존재
-> 분산해서 빠르게 쉬운 계산들을 처리
✒️ 우리가 쓰는 일반적인 환경은 CPU -
함수를 학습하는 계산이 가능하다는 것을 알게됨
❓ 그렇게 해서 만들어진 함수들이 유용한가?
❓ 실질적인 의미를 가지는가?
-> 구글, 넷플릭스, 페이스북 등의 회사들은 함수를 유용하게 사용하혀 가치를 만드는가?
-> YES
⭐머신러닝
- 정의: 컴퓨터 알고리즘에 대한 학습 과정, 일련의 연규의 결과물
- 컴퓨터 프로그램
: 자기 스스로 어떤 경험들에 의해 스스로를 발전시켜나갈 수 있는 일련의 컴퓨터 프로그램 체계를 학습하는 학문
- 구성
🎈1) 환경
: 머신러닝 알고리즘이 적용되는 환경
-> 머신러닝 알고리즘에 경험(=data)을 제공함(학습시키는 것)
🎈2) 데이터
: 환경과 상호작용을 하면서 얻어진 기억들의 패턴들이 녹아져 있는 일련의 저장의 결과
== 우리가 기억해야 되는 활동의 저장 결과
🎈3) 모델
== 함수
: 함수에 데이터를 넣어 함수를 학습시킴
🎈4) 퍼포먼스
: 좋은 함수가 어떤 것일까?
== 특정 지표를 이용한 평가
- 오차(오차가 작은게 좋은거)
: 실제 값과 추정 값의 차이
MSE (Mean Squared Error)
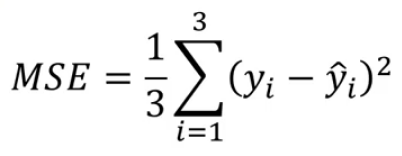
-> MSE_A = 1/3{(10-11) 2 + (5-4) 2 + (7-8) ** 2
=> 오차가 작은게 유리
💥 머신러닝을 통해 궁극적으로 알고 싶은것: 입력되는 것과 그 다음에 출력되는 것 사이의 상관관계를 알고 싶다
-> 그 둘을 이어주는 함수를 찾고 싶다.
⭐학습한다는 것은 무엇인가??
- linear regression(머신러닝 방법론)으로 알아보자
-> input과 oupt간의 관계가 선형적
X는 변수, y는 최종적인 출력값
- 우리가 찾아야 할 것: 선형 관계가 있는 건 알겠는데
얼만큼의 배수로 영향??
-> 손실함수(loss function)
✅손실함수
: 모형이 출력한 값과 실제 값의 차이를 구해서 제곱을 취해주면 됨
(제곱을 안하면 오차가 양수 음수가 나와서 더해버리면 상쇄가 됨)
-> MSE
✅최적화 단계
-> 오차를 가장 줄여주는 베타를 찾겠다
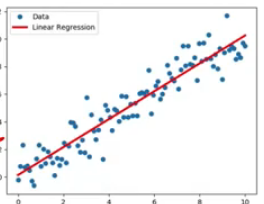
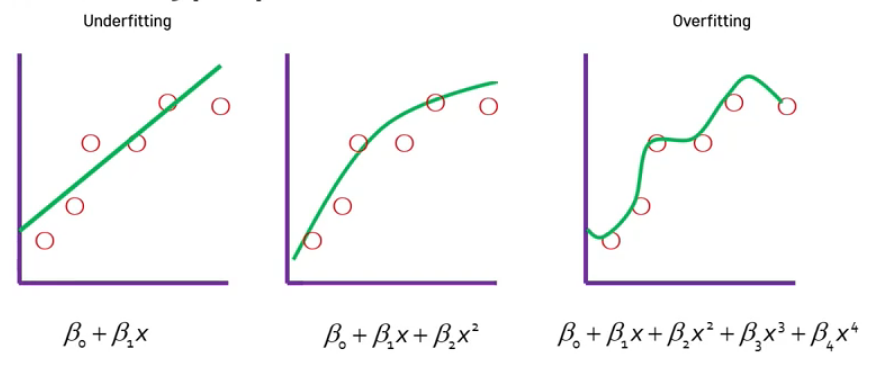
=> 최종적으로 붉은색 함수를 얻을 수 있음
⭐예시
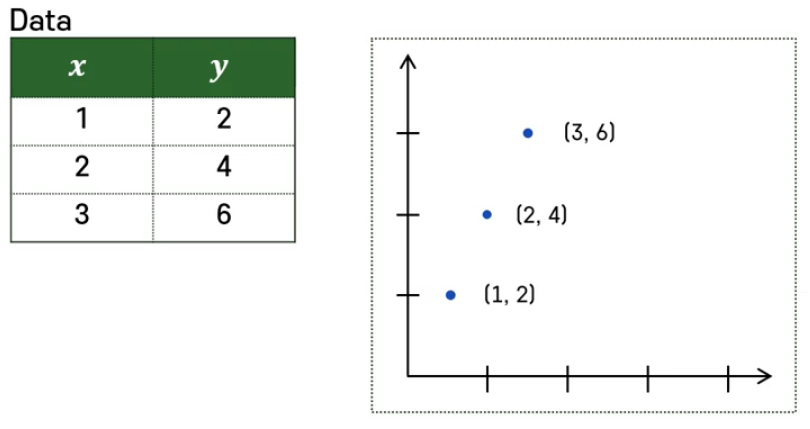
🎈1. 모델의 대략적인 형태 알려주기: basic function
-> 함수의 정확한 형태와 최종적인 결과는 모르지만 함수가 가정하고 있는 바에 따라서 대략적으로 세워져있는 변수를 이용해 구성된 함수를 컴퓨터에게 알려주기
가정:‘input하고 output하고 선형적인 관계가 있을 것이다. 그런데 그 input에 β라고 하는 아직 미지의 변수를 곱한 형태로 이 둘의 관계가 결정되는 것일 거다.
🎈2. 손실함수
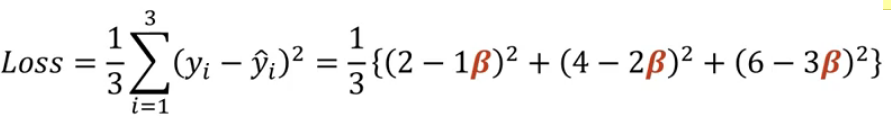
== 1/3{(y1-y1^)²+(y2-y2^)²+(y3-y3^)
-> 여기에 실제 데이터 삽입
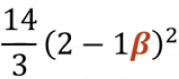
==> 최종적인 로스 함수를 찾음, 베타 값 찾을 수 있음
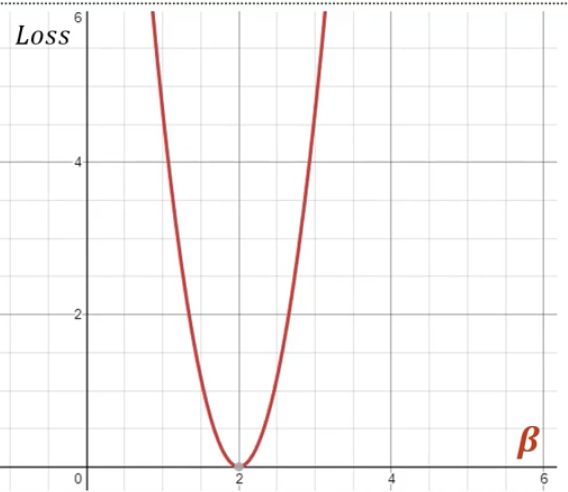
-> 베타가 2가 되면 함수값은 최솟값인 0이 됨
🎈3. 컴퓨터에게 알려주기
위와 같은 방식을 미분해서 알려줌
💥러닝 == optimization(최적화)
: 내가 원하는 가장 최적의 결과를 도출, 이 함수가 내가 원하는 바대로 행동하게 하는 것
✒️ 손실함수는 0이 되지 않을 수 있다! 0에 가깝게끔 최선을 다하자!
⭐종류
✅Supervised Learning: classification, regression
-> 지도학습: y의 형태가 분류인지 회귀인지 구분
🔷 y가 categorical variable(범주형 변수) - 고양이, 배,비행기, 등 : Classification
🔷 y가 continuou(연속형 변수) : Regression -> 위에서 구했던 linear Regression도 y가 연속형 숫자이기 때문에 regression으로 문제를 품
🎈1. 트레이닝 데이터만 이용해 학습
-> 비추천!! 일반화가 되지 않음
🎈2. train, test 데이터 나누기
-> train 데이터에 먼저 학습 훈련 후 가장 좋은 방법을 test에 적용
🔷 hyperparameter 튜닝을 해야함
🎈3. training, validation, testing data로 쪼개기
-> train, validation 데이터에 각자 hyperparameter를 적용하여 여러번 확인
-> 최종적인 모형을 가지고 test데이터에 적용
(validation data는 검증용)
🎈4. Cross-Validation
: 데이터를 test와 train으로 나누고 train안에서 train과 validation을 번갈아가면서 최종적인 모형 결정
-> 데이터가 적을 때 적절
💥 validation을 통해 좋은 모형을 찾고 일반화 오류를 계산하는 절차는 꼭 필요함
💥 학습의 기본, 핵심 == 최적화
❤️출처: K-MOOC 실습으로 배우는 머신러닝
