12/5
⭐복습
Q. 레이어 층만 보고 회귀 모델이라는 것은 어떻게 알 수 있을까?
A. loss에 손실함수를 작성하면 알 수 있다
-> 분류에서도 activation function을 지정하지 않으면 출력층을 Dense(1 or 3 ...등)로 입력할 수 있음
✒ 분류 문제는 binary인지 멀티클래스인지 명시적으로 지정해주는게 좀 더 코드를 읽고 해석하기 좋음! -> 혼란을 줄이기 위해 가능하면 지정해주자
Q. 분류에서 출력층 활성함수를 시그모이드로 한다면 출력층 유닛은 2로 하면 될까?
A. X
-> sigmoid는 1개로 해주어야 확률값으로 출력을 받아 특정 임계값보다 크냐 작냐로 binary 값을 만들어서 판단한다.
-> 분류에서 units가 2개라면 softmax로 반환받는게 맞고, 이때는 둘 중에 확률 값이 높은 값을 선택해서 사용한다.
Q. 멀티클래스 예측값이 나왔을 때 가장 큰 인덱스를 반환하는 넘파이 메서드는 무엇?
A. argmax
-> np.argmax()를 통해 가장 큰 값의 인덱스를 반환받아 해당 클래스의 답으로 사용
Q. [0.1, 0.1, 0.7, 0.1] 이렇게 예측했다면 np.argmax() 로 반환되는 값은 무엇일까?
A. 2(0.7)
Q. softmax와 sigmoid의 차이는?
A. sigmoid는 이진 분류에 사용하고 softmax는 다중 클래스 분류에 사용
softmax는 n개의 확률값을 반환하고 전체의 합은 1이된다. 2개 중에 하나를 예측할 대는 softmax를 사용할 수 있지만 보통 sigmoid를 사용. sigmoid 는 1개의 확률값이 반환되는데 그 확률값이 임계값보다 큰지 작은지를 판단
✒ 복습을 해본다면, 출력층, compile 의 loss 를 보면 분류인지 회귀인지, 이진분류인지, 멀티클래스인지 판단해 볼 수 있도록 계속 연습해 보자!!!!
Q. learning_rates란?
A. 학습률을 의미하며, 경사하강법에서 한 발자국 이동하기 위한 step size를 의미. 학습률이 클수록 손실함수의 최솟값을 빨리 찾을 수 있으나 발산의 우려가 있고 너무 작으면 학습이 지나치게 오래걸리는 단점이 있다. 최적화된 가중치 값을 찾기 위해 설정하는 학습률
-> 적당하게 설정해주는게 좋음
⭐CNN
❗ 오늘의 핵심 내용: 합성곱 층을 만드는 방법 ❗
Q. DNN과 CNN 사용할 때 입력의 차이는? (이미지 높이, 이미지 너비, 컬러 채널)
A. flatten이 필요 없다(DNN 입력은 1차원으로 입력), dense가 아님

🔷 Conv2D와 MaxPooling2D 층의 출력은 (높이, 너비, 채널) 크기의 3D 텐서
🔷 높이와 너비 차원은 네트워크가 깊어질수록 감소하는 경향을 가진다
🔷 마지막에 Dense 층 추가
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))💥 합성곱 신경망(Convolutional Neural Network, CNN) 의 핵심 키워드! Conv, Pooling(Max)!
CNN + DNN 💥
✅합성곱 층 만들기
model = models.Sequential()
model.add(layers.Conv2D(filters = 32, kernel_size=(3, 3),
activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters = 64, kernel_size=(3, 3), activation='relu'))🔷 filters, kernel_size 등과 같이 알아보기 쉽게 어떤 parameter의 argument인지 지정하기
🎈 Input shape가 mnist오 비교했을 때 어떻게 달라졌는지??
cifar10: input_shape=(32, 32, 3)
MNIST: input_shape=(28, 28, 1)
-> MNIST는 3차원
✅하이퍼 파라미터
🔷 합성곱 신경망의 별명 => 피처 자동 추출기 그러면 어떻게 피처를 자동으로 추출할까?
=> 필터(filters)를 랜덤하게 여러 장 만듭니다. 각 필터의 사이즈는 kernel_size 로 정한다.
=> 필터를 이미지에 통과시켜서 합성곱 연산을 하여 결과가 나오면 그 결과로 특징을 추출.
=> 필터에는 랜덤하게 만들다 보면 1자 모양도 있을 수 있고 / 모양도 있을 수 있고 O, ㅁ 이런 여러 패턴을 랜덤하게 만들 수 있다.
=> 그 패턴을 통과시켜서 그 패턴이 얼마나 있는지 확인해 볼 수 있음.
이런 패턴을 여러 장 만든다 => filters => 각 필터의 사이즈 kernel_size라 부른다.
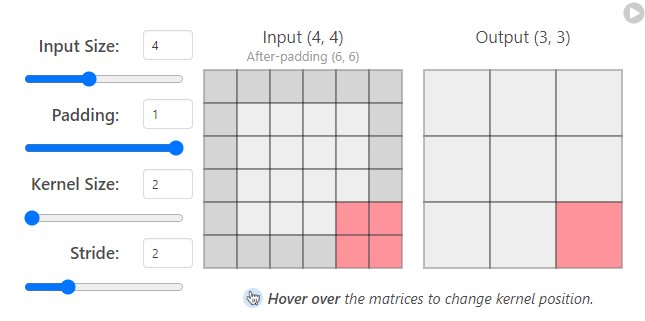
🔷 pading: input값이 (7,7)일 때 패딩은 (9,9)가 되고 ouput값은 (8,8)이 된다
: 입력의 공간 크기를 보존하는데 도움을 줄 수 있음
🔷 kernel_size: 필터라고도 불리며 슬라이딩 윈도우의 크기를 나타냄
: 커널 크기가 작을수록 레이어 크기가 더 작아지므로 더 깊은 아키텍처가 가능
: 큰 커널 크기는 더 적은 정보를 추출하므로 레이어 차원이 더 빨리 줄어들고 성능이 저하되는 경우가 많음
💥 패딩을 사용하는 이유: 이미지 가장자리 모서리 부분의 특징을 좀 더 학습할 수 있다
: 패딩을 1로 커널사이즈를 3x3 으로 사용하면 입력과 출력값이 같아지게 된다
🔷 stride: 한 번에 이동해야 하는 픽셀 수
:모든 후속 작업에 대해 한 픽셀씩 오른쪽으로
-> stride가 CNN에 미치는 영향은 kernel_size와 동일
: stride가 감소할수록 더 많은 데이터가 추출되기 때문에 더 많은 기능이 학습되며, 더 큰 출력 레이어로 이어짐
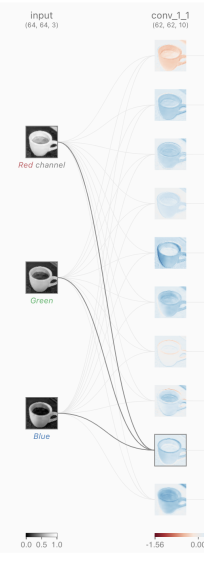
필터의 개수 = 10개 = conv_1_1
kernel_size = 3,3
🔷 (64, 64) => (62, 62) 된걸로도 유추 가능도 하다
ex) 64 - 62 +1 + 패딩값
-> 용어가 정리된 표
🔷 10장의 피처가 나온 것 = 피처맵
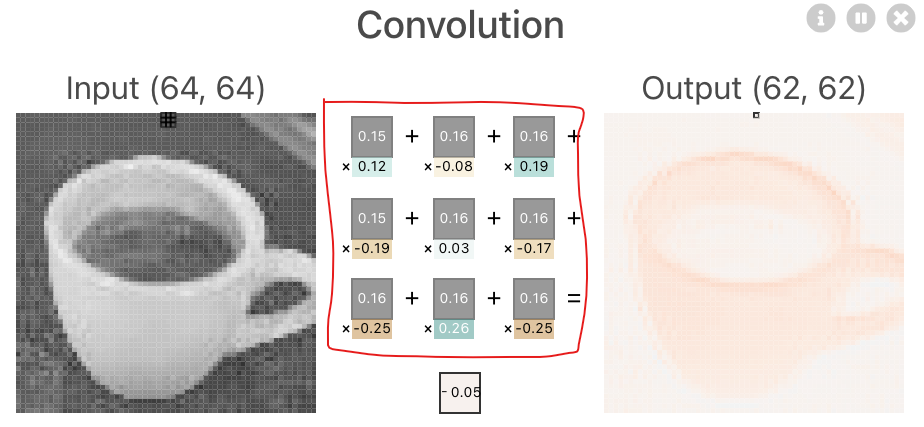
-> 컨볼루션 결과로 나온 output
🔷 피처맵이 relu 활성화 함수를 통과한 것 = activation map


-> 활성화 함수를 통과한 것
🔷 max pooling
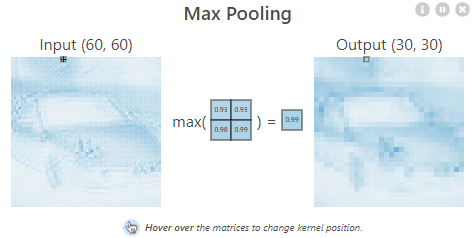
-> 어떤 효과가 있을까?
-> 과대적합을 예방하고 용량도 줄여준다(이미지의 사이즈가 줄어듬), 계산의 효율성이 높아진다.

-> 크기가 줄어드는 것을 잘 보자!!
-> (height, width, filters)
💥 MaxPooling 은 가장 큰 값을 반환
💥 AveragePooling 은 평균 값 반환
💥 MinPooling 은 최솟값 반환
💥 Pooling: 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지해 주기도 한다. 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지된다
✅조은님이 해주신 용어 정리
1) Convolution 연산을 하면 필터(filters, kernel_size에 해당하는 filters 개수만큼)를 통과시켜서 filters 개수만큼 피처맵을 생성
=> CNN 의 별명이 피처자동추출기. 비정형 이미지를 입력했을 때 이미지를 전처리 하지 않고 그대로 넣어주게 되면 알아서 피처맵을 생성. 피처맵은 피처가 어떤 특징을 갖고 있는지를 나타내고 선이 있는지, ), O, 1, , 다양한 모양을 랜덤하게 생성해서 통과 시키면 해당 특징이 있는지를 학습하게 하는게 Convolution 연산
2) 피처맵 Output에 Activation Function (활성화함수)을 통과시켜서 액티베이션맵을 생성
=> relu 등을 사용하게 되면 출력값에 활성화 함수를 적용한 액티베이션맵을 반환
3) Pooling 에는 Max, Average, Min 등 여러 방법이 있는데, 보통 MaxPooling 을 주로 사용
흑백이미지에서는 MinPooling 을 사용
MaxPooling 은 가장 큰 값을 반환, AveragePooling 은 평균 값 반환, MinPooling 은 최솟값 반환
Pooling => 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지해 주기도 함. 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지된다
4) VGG16, VGG19 등은 층을 16개, 19개 만큼 깊게 만든 것을 의미. 30~50층까지 쌓기도 하고 100층 정도 쌓기도 한다. 층의 수를 모델의 이름에 붙이기도 한다.
=> 과거에 비해 GPU 등의 연산을 더 많이 지원하기 때문에 연산이 빨라진 덕분이기도 합니다.
5) TF API 는 다음의 방법으로 사용.
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))6) Padding, Stride 등을 사용해서 입력과 출력사이즈를 조정한다든지, Stride는 필터의 이동 보폭을 조정하기도한다.
Q. DNN을 이미지 데이터에 사용했을 때의 단점
A.
1) flatten() 으로 1차원 벡터 형태로 주입을 해야 하기 때문에 인접 공간에 대한 정보를 잃어버리게 된다
2) 1차원 형태로 주입을 해주게 되면 입력값이 커서 계산이 오래 걸린다
- DNN의 단점을 보안한 CNN의 특징
1) Conv과 Pooling 연산을 하게 되면 데이터의 공간적인 특징을 학습하여 어떤 패턴이 있는지를 알게 된다
3) Pooling 을 통해 데이터를 압축하면 데이터의 용량이 줄어들며, 추상화를 하기 때문에 너무 자세히 학습하지 않게 되며 오버피팅을 방지한다.
💥
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3),
activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))Q. 피처맵의 개수: 32개
Q. 이미지의 채널 수: 3개
-> RGB 3개의 값이 입력되기 때문에
-> input_shape=(32,32, 3)
-> (image_height, image_width, color_channels)
-> 흑백이면 1, 컬러면 3
💥 CNN과 DNN의 가장 큰 차이는 바로 1차원으로 flatten해서 넣어주는 것이 아닌, Conv, Pooling 연산을 통해 특징을 학습하고 압축한 결과를 flatten해서 DNN에 넣어주는 것
✒️ kernel_size는 주로 홀수
✒️ padding = 'same'으로 지정해주면 값이 줄어들지 않음(줄이고 싶지 않은 층에다 매번 작성해줘야함)
-> 가장자리 데이터 학습
💥 필터는 이미지에서 특징을 분리해 내는 기능을 하고,
필터를 이미지에 통과해서 합성곱 연산을 하는데, 이 합성곱에 사용되는 커널의 크기를 kernel_size
12/6
⭐복습
- relu를 통과한 피처맵: 액티베이션 맵
- maxpooling을 하게되면 가로세로의 길이가 줄고 일정한 영역에서 가장 큰 값만 남음(과대적합 방지, 처리속도 향상)
- softmax가 결과를 처리하는 법: 출력값이 확률로 나옴
- softmax: 전체 합이 1, 출력값이 n개의 확률로 나옴, 멀티클래스 분류에 주로 사용됨(가장 큰 확률 값을 클래스의 답으로 사용 -> np.argmax)
- binary 분류에는 출력 activation으로 무엇을 사용? : sigmoid(0-1사이의 확률값을 반환하며 임계값을 기준으로 분류)
⭐이미지 classification
-> 해당 튜토리얼은 ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] 꽃 5가지 이미지를 학습하고 분류하는 예제
-
이미지 데이터를 분류할때도 전처리가 중요함 -> 좋은 데이터를 넣어주어야 학습결과가 좋게 나옴
-
이미지 사이즈가 다 다르면 계산을 할 수 없기 때문에 사이즈도 맞춰줄 필요가 있음
-> 사이즈 맞추는 코드
batch_size = 32
img_height = 180
img_width = 180
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)-> image_size 설정
- 이미지 사이즈를 크거나 작게 만들면 이미지의 왜곡이 일어날 수 있다.
- 사이즈를 작게 하면 계산이 빨라지고 사이즈를 크게 하면 계산이 늘어나지만 학습량이 많아져 성능이 좋아진다
💥 보통 계산편의를 위해 정사각형 형태로 만들어줌
🔷 이미지 사이즈도 하이퍼 파라미터처럼 조정을 하면 성능이 달라지고 Conv, Pooling도 성능에 영향을 준다.
-> 어떤 식으로 레이어를 구성하냐에 따라 보안이 가능하기도 함
✅레이어 구성
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)) -> 일일이 정규화하지 않아도 레이어에서 rescaling을 하면 정규화 된다
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(filters = 16, kernel_size = 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(units = 128, activation='relu'),
layers.Dense(num_classes)
])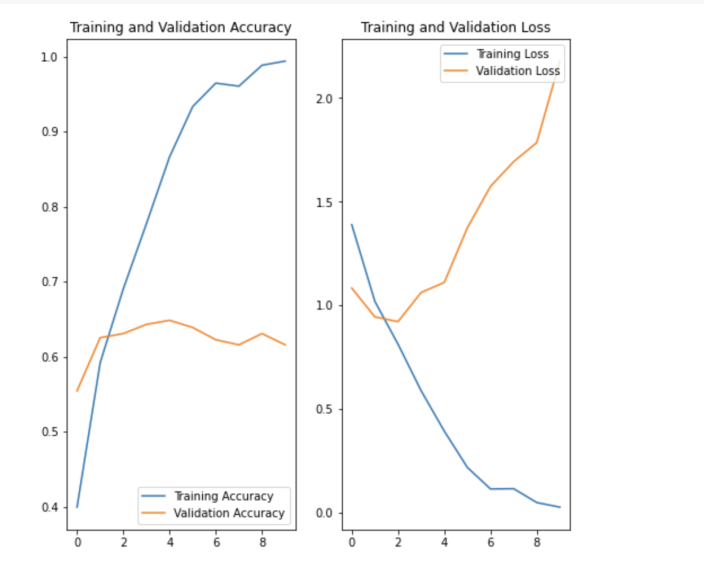
- 훈련 결과 해석
- 오버피팅이 굉장히 심하다
-> 이미지 전처리가 제대로 안되어있어서 그럴 가능성이 높음(노이즈 데이터가 많음)
-> 과대적합을 방지하기 위해서는 데이터 증강을 사용하고 모델에 드롭아웃을 추가하는 방법이 있음
- tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom 이런 전처리 기능을 사용하면 데이터 증강기법을 통해 이미지를 다양하게 생성해서 학습을 진행할 수 있음
💥 접고 돌리고 땡기고
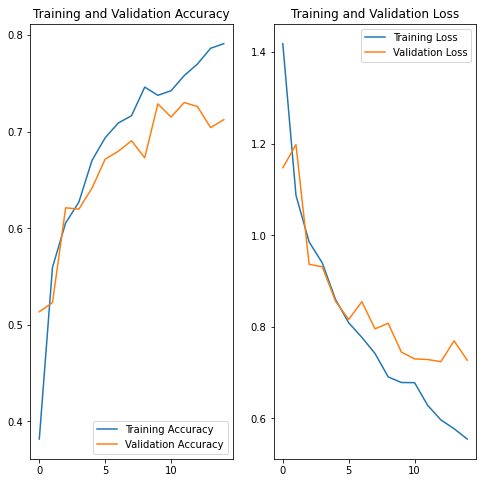
-> 이렇게 과적합이 해결됨
✅용어
- filters : 컨볼루션 필터의 수 == 특징맵 수
- kernel_size : 컨볼루션 커널의 (행, 열) => 필터 사이즈
- padding : 경계 처리 방법
->‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
->‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
💥 MNIST(손글씨 이미지로 0~9 숫자), FMNIST(의류 10가지 이미지) 는 전처리가 잘 되어있기 때문에 기본 모델로 만들어도 99% 까지의 Accuracy가 나왔었다.
💥 꽃 이미지에는 노이즈가 많기 때문에 Accuracy 가 데이터 증강, Dropout을 했을 때 0.6대에서 0.7정도로 정확도가 높아졌다
=> 지금까지 한 실습은 TF공식예제에 있는 CNN 기본 레이어 구성과 데이터증강 기법을 알아보았다
⭐1001 실습
✅이미지를 로드하는 방법
- matplotlib.pyplot의 imread()를 사용
import matplotlib.pyplot as plt
img = plt.imread(paths[0])
img.shapeplt.imshow(img) plt.axis("off")
-> 감염되지 않은 세포

- PIL(Pilow)로 불러오는 방법
-> PIL로 접고 돌리고 땡기고 가능(이미지 편집기임)
-> TF 내부에서도 PIL이나 OpenCV을 사용해 접돌땡 함
from PIL import Image, ImageFilter
original = Image.open(cell_img)
original- OpenCV로 불러오는 방법(Computer Vision)
-> 주로 사용하는 도구로 동영상 처리 등에 주로 사용
import cv2
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img.shape-> RGB 형태를 사용하지 않고 BGR을 사용하기 때문에 COLOR_BGR2RGB 을 통해 RGB 형태로 변환해야 함
⭐1002 실습
✅이미지 미리보기
- matplotlib
upics_0 = upics[0]
upics_0_img = plt.imread(upics_0)
plt.imshow(upics_0_img)-> 감염 안된 세포
- CV2
import cv2
plt.figure(figsize=(8, 8))
labels = "Uninfected"
for i, images in enumerate(upics[:9]):
ax = plt.subplot(3, 3, i + 1)
img = cv2.imread(images)
plt.imshow(img)
plt.title(f'{labels} {img.shape}')
plt.axis("off")
✅데이터 셋 나누기
-
ImageDataGenerator 를 통해 이미지를 로드하고 전처리 합니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator -
validation_split 값을 통해 학습:검증 비율을 8:2 로 나눕니다.
datagen = ImageDataGenerator(rescale=1/255.0, validation_split=0.2)
-> 가장 큰 값이 255가 있어서 리스케일을 통해 나눠서 0~1 사이값으로 만들어주기
💥 Keras의 ImageDataGenerator는 다음과 같은 이미지 변환 유형을 지원한다❗❗
공간 레벨 변형
- Flip : 상하, 좌우 반전
- Rotation : 회전
- Shift : 이동
- Zoom : 확대, 축소
- Shear : 눕히기
픽셀 레벨 변형
- Bright : 밝기 조정
- Channel Shift : RGB 값 변경
- ZCA Whitening : Whitening 효과
✅이미지 사이즈 설정
- 이미지가 너무 작으면 왜곡이 되거나 특징을 잃어버릴 수 있지만 계산량이 줄어들어 학습속도가 빠름
- 이미지가 너무 크면 흐려지거나 왜곡이 될 수 있고 계산량이 많아 학습속도가 오래걸리지만 좀 더 자세히 학습할 수 있음
- 학습이 너무 오래 걸리지 않도록 32 정도로 설정
height = 32-> 보통은 상황에 따라 다름! 장비가 연산을 많이 지원할 수 있다면 원본 사이즈를 사용하고 장비계산이 너무 오래 걸리면 줄여야함
✅학습세트
- 말라리아 데이터에서는 class_mode 에는 이진분류이기 때문에 binary 를 넣어줍니다. => 감엽되었다 아니다 둘 중 하나
- class_mode: One of "categorical", "binary", "sparse", "input", or None. Default: "categorical"
- subset: Subset of data('training' or 'validation' )
trainDatagen = datagen.flow_from_directory(directory = 'cell_images/',
target_size = (height, width),
class_mode = 'binary',
batch_size = 64,
subset='training')✅레이어 설정
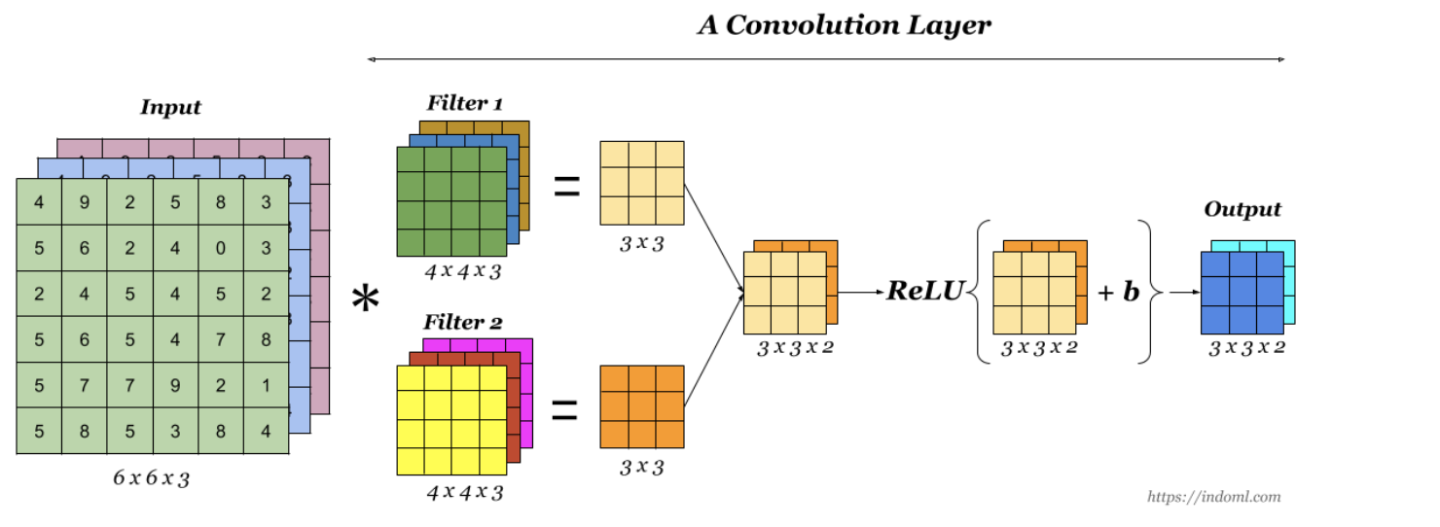
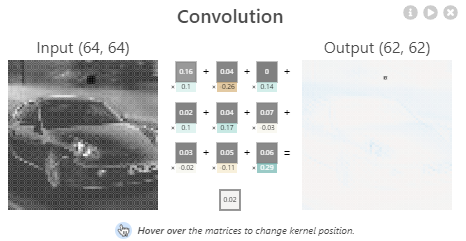
-> 피처맵은 몇개? 2개(필터 2개를 통과했기 때문에)
-> kernel_size는? 4*4
🔷 padding: 경계 처리 방법
- valid: 유효한 영역만 출력 -> 출력 이미지 사이즈는 입력 사이즈보다 작다
- same: 출력 이미지 사이즈가 입력 이미 사이즈와 동일
model = Sequential()
# 입력층
model.add(Conv2D(filters=16, kernel_size=(3,3), padding = 'valid', activation='relu', input_shape=(height, width, 3)))
model.add(Conv2D(filters=16, kernel_size=(3,3), padding = 'valid', activation='relu'))
model.add(MaxPool2D(pool_size = 2,2), stride=1)
model.add(Dropout(0.2))
# Fully-connected layer
model.add(Flatten())
model.add(Dense(units=64, activation = 'relu'))
model.add(Dense(units=32, activation = 'relu'))🔷 참고로 층을 쌓을 때 "비선형 활성화 함수 없이" 두 개의 합성곱 층을 쌓는 경우 그냥 많은 커널을 가진 하나의 conv2d 층을 사용하는 것과 수학적으로 동일하기 때문에 비효율 적으로 합성곱 신경망을 만드는 것과 같다!
✅학습하기
early_stop = EarlyStopping(monitor='val_loss', patience=5)
model.fit(trainDatagen, epochs = 1000,
callbacks = early_stop, validation_data = valDatagen)-> validation 모델을 만들었기 때문에 validation_split이 아닌 validation_data = valDatagen을 입력
✅정리
1002 번 파일 실습
=> 주제: 말라리아 혈액도말 이미지 분류 실습
=> 목적: TF 공식 문서의 이미지 분류를 다른 이미지를 사용해서 응용해 보는 것
1) 이미지 데이터 불러오기 wget 을 사용하면 온라인 URL 에 있는 파일을 불러올 수 있다.
2) plt.imread 와 cv2(OpenCV) 의 imread 를 통해 array 형태로 데이터를 불러와서 시각화를 해서 감염된 이미지와 아닌 이미지를 비교해 봤다. => 레이블값을 폴더명으로 생성
3) TF.keras의 전처리 도구를 사용해서 train, valid set을 나눠주었다.
4) CNN 레이어를 구성, 컴파일 하고 학습하고 정확도(Accuray) 성능을 비교해봤다.
12/7
⭐복습
✅CNN의 핵심 요소
- 필터: 각 레이어의 입출력 데이터의 형상 유지, 복수의 필터로 이미지의 특징 추출 및 학습
-> 필터를 공유 파라미터로 사용하기 때문에 일반 신경망과 비교하여 학습 파라미터가 매우 적음 - 합성곱층: 입력 데이터의 특징을 추출하여 특징들의 패턴을 파악, 이미지의 공간 정보를 유지하면서 특징을 인식
- 풀링층: 추출한 이미지의 특징을 모으고 강화하는 레이어
✅용어
-
채널: 이미지 픽셀 하나하나는 실수(float)이며, 이미지 형태(shape)는 높이, 폭, 채널로 구성
: 컬러 사진은 RGB 3개의 실수로 표현한 3차원데이터로 3개의 채널로 구성
ex) (39,31,3)
: 흑백은 2차원 데이터로 1개 채널로 구성
ex) (39,31,1)
-> 입력 데이터에는 한 개 이상의 필터가 적용되고 1개의 피처맵의 채널이 된다.
-> 합성곱층에 n개의 필터가 적용되면 출력 데이터는 n개의 채널을 생성 -
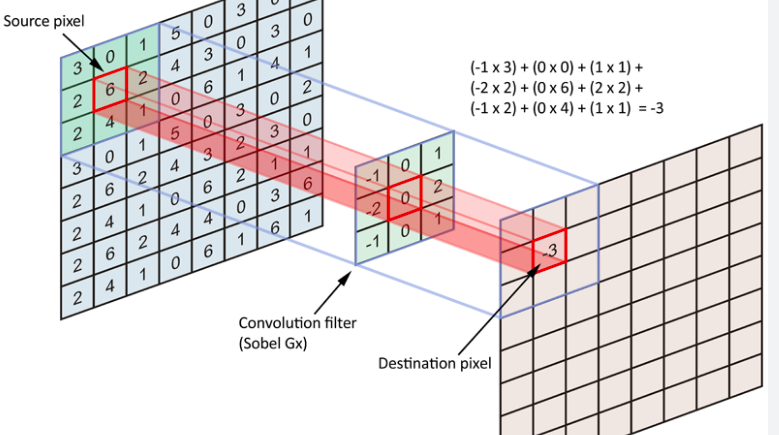
합성곱: 데이터의 특징을 추출하는 과정으로 필터를 사용하여 각 영역의 인접 데이터를 조사해 특징을 파악하여 한장으로 도출
-> 도출된 장을 합성곱층이라고 함
🔷 합성곱의 추상화: 이미지의 특정 부분을 추상화하여 특정층으로 표현(하나의 압축 과정으로 파라미터 개수를 효과적으로 축소) -
필터: 이미지의 특징을 찾아내기 위한 공용 파라미터로 학습의 대상이며 합성곱의 가중치에 해당
-> 커널이 가중치 합산하는 영역의 크기
ex) 16필터수는 피처맵 수와 같음 -
커널: sliding window하는 영역에서의 크기
ex) 44, (33)과 같은 정사각
-
스트라이드: 필터를 적용하는 간격을 의미
-> 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산
ex) stride=1이면 필터를 한번에 한 픽셀씩 이동, stride=2이면 필터는 2칸씩 이동
-> stride를 높일수록 공간적으로 더 작은 출력 볼륨이 생성되고 데이터 손실을 고려해야 함
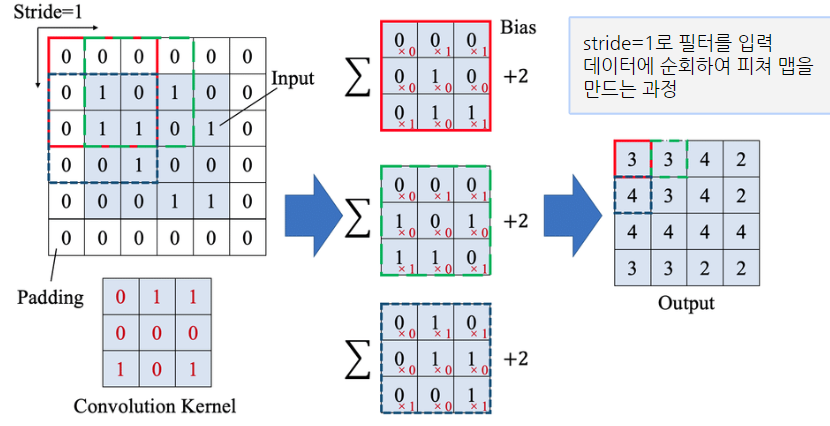
❓ stride를 통해 여러칸을 이동시키면 어떻게 될까?
❗ 세부내용을 학습하지 않고 이미지 크기가 더 작아지고 가로세라고 더 줄어듦, 데이터가 손실된다
-> 용량이 줄어들고 학습 속도는 빨라지지만 자세히 학습하지 못해 언더피팅이 될 수 있다
❓ 색상을 변경하면 안되는 예시는?
❗ 신호등 등등
❓ 이미지 증강을 할대 주의할 점!
❗
1) 크롭이나 확대 => 노이즈를 확대하거나 크롭하면 더 문제가 될 수 있다
2) 회전, 반전 => 6을 180도 돌리면 완전히 다른 의미인 9가 되기 때문에 이런 숫자 이미지는 돌리지 않는다
3) 색상 변경 => 만약 장미꽃이라면 다양한 색상이 있기 때문에 색상을 변경해도 상관이 없지만, 신호등이라면 안전과 직결되기 때문에 변경하면 안 된다.
3) 데이터셋 => 증강할 때 train 에만 해줍니다. test에는 해주지 않는다다.
-> 현실세계 문제를 푼다고 가정했을 때 현실세계 이미지가 들어왔을 때 증강해주지는 않고 들어온 이미지로 판단하기 때문에 train에만 사용
💥 결론 => 증강을 할 때는 현실세계 문제와 연관해서 고민해야함!!
❓ CNN 모델을 학습시키는데 내 컴퓨터로 돌렸더니 메모리 오류가 났다!
-> 성능(정확도가 낮게 나와도 오류 없이 돌리고 싶을 때)과 관계 없이 돌리고 싶다
❗ 이미지 사이즈를 줄인다.
레이어를 줄인다. 필터수를 줄인다.
배치(한번에 다 불러오지 않고 나눠서 불러오게) 사이즈를 줄인다.
⭐1003 실습 -> 전이 학습(Transfer Learning) 해보기
Module: tf.keras.applications
Keras Applications are premade architectures with pre-trained weights.
=> 미리 유명한 모델 아키텍처로 학습을 해서 찾아놓은 가중치를 사용.
=> 간단하게 보면 유명한 모델 아키텍처를 가져다 사용하는 것.
=> 논문을 보면 코드가 많고 복잡한데 간단하게 API를 만들어서 코드 1~2줄로 사용하게 만들어 놓은 것
https://www.tensorflow.org/api_docs/python/tf/keras/applications/vgg16
✅VGG16 사용하기
vgg = VGG16(
include_top=False,
weights='imagenet',
input_shape=(height, width,3))-> input_top = False로 지정하면 32*32를 최소 이미지 크기로 요구함
(상단에 완전 연결 레이러를 추가할지에 대한 여부)
✒️ 구성한 네트워크를 기준으로 설정해야 함
✒️ include_top = True인 경우
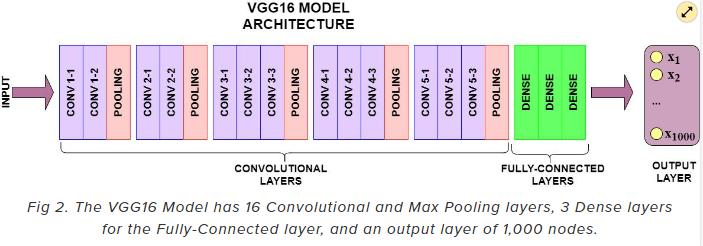
✒️ include_top = False인 경우
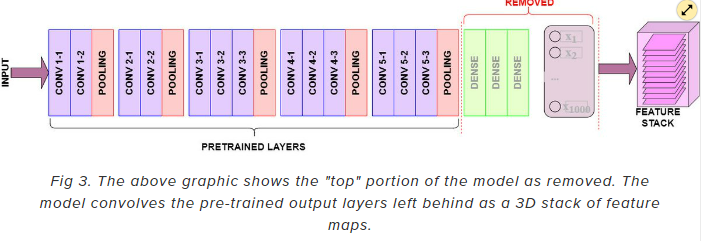
-> image_shape는 각 image의 shape를 출력했을 때의 값과 동일하게 만들어줘야함
⭐1004 실습
✅mount 사용해서 폴더 불러오기
import os
root_dir = "/gdrive/My Drive/data/dataset/archive/dataset"
image_label = os.listdir(root_dir)
image_label.remove("test.csv")
image_label✅일부 이미지 미리보기
import glob
fig, axes = plt.subplots(nrows=1, ncols=len(image_label), figsize=(20, 5))
for i, img_label in enumerate(image_label):
wfiles = glob.glob(f"{root_dir}/{img_label}/*")
wfiles = sorted(wfiles)
print(wfiles[0])
img = plt.imread(wfiles[1])
axes[i].imshow(img)
axes[i].set_title(img_label)- print(wfiles[0]) -> 1번째 이미지 파일 리스트 불러오기
- img = plt.imread(wfiles[1])
axes[i].imshow(img)
axes[i].set_title(img_label)
-> 불러온 2번째 이미지 시각화하기
✅이미지 데이터 셋 만들기
-
def img_read_resize(img_path):
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)-> 색상 변경
img = cv2.resize(img, (120, 120)) return img-> 사이즈 변경 -
구글 드라이브 기준으로 경로 변경
img_path = f"{root_dir}/cloudy/cloudy131.jpg" -
plt.imread(img_path).shape
img_read_resize(img_path).shape -
이미지 사이즈가 잘 변경되었는지 확인
plt.imshow(img_read_resize(img_path))
🔷 append와 extend의 차이
append 는 통째로 넣고 extend 는 풀어서 넣습니다.
ex) 사탕을 다른 봉지에 담을 때
봉지째 담는다 => append
낱개로 풀어서 담을 때 => extend
✅train, valid, test 만들기
- 0) 목표 train, valid, test set 에 대한 X, y값 만들기!
- 1) label 별로 각 폴더의 파일의 목록을 읽어온다
- 2) 이미지와 label 리스트를 만들어서 넣어줄 예정
- 3) test는 폴더가 따로 있음 -> 이미지를 불러올 때 test 여부를 체크해서 train, test 를 먼저 만든다
- 4) np.array 형태로 변환
- 5) train 으로 train, valid 를 나누어주기
-> ```python
from sklearn.model_selection import train_test_split
x_train_raw, x_valid_raw, y_train_raw, y_valid_raw = train_test_split(
x_train_arr,y_train_arr, test_size = 0.33, stratify = y_train_arr, random_state=42)
-> fit을 할 때 validation_split으로 나눠도 되지만 class가 균일하게 나뉘지 않아서 학습이 불균형해짐
-> valid 데이터를 직접 나눠 넣어주면 더 잘 학습된다
* 6) train, valid, test 를 만든다
-> ```pyrhon
x_train = x_train_raw / 255
x_valid = x_valid_raw / 255
x_test = x_test_arr / 255-> 정규화 작업
-> 255: RGB 값이 0~255로 빨초파로 표현
❤ 출처: https://itwiki.kr/w/CNN
❤ 출처: https://bkshin.tistory.com/entry/OpenCV-17-%ED%95%84%ED%84%B0Filter%EC%99%80-%EC%BB%A8%EB%B3%BC%EB%A3%A8%EC%85%98Convolution-%EC%97%B0%EC%82%B0-%ED%8F%89%EA%B7%A0-%EB%B8%94%EB%9F%AC%EB%A7%81-%EA%B0%80%EC%9A%B0%EC%8B%9C%EC%95%88-%EB%B8%94%EB%9F%AC%EB%A7%81-%EB%AF%B8%EB%94%94%EC%96%B8-%EB%B8%94%EB%9F%AC%EB%A7%81-%EB%B0%94%EC%9D%B4%EB%A0%88%ED%84%B0%EB%9F%B4-%ED%95%84%ED%84%B0
❤ 출처: https://www.researchgate.net/publication/348296106_Improvement_of_Damage_Segmentation_Based_on_Pixel-Level_Data_Balance_Using_VGG-Unet
❤ 출처: 오늘코드
❤ 출처: 멋쟁이 사자 AI SCHOOL 7기
