⭐관련 용어
🎈Dataset
: 정의된 구조로 모아져 있는 데이터 집합
🎈Data point(observation)
: 데이터 세트에 속해 있는 하나의 관측치
🎈feature(variable, attribute)
: 데이터를 구성하는 하나의 특성(숫자형, 범주형, 시간, 텍스트, 이진형 등)
🎈Label(target, response)
: 입력 변수들에 의해 예측, 분류되는 출력 변수
🎈x: 출력변수, 독립변수
🎈y: 입력변수, 종속변수
분류
: 종속변수가 범주형일 때
ex) 입력된 보험 청구권에 대해서 자동심사와 인심사 분류
회귀
: 종속변수가 연속형일 때
ex) 날씨, 유가, 경제지표 등을 이용한 주가 예측
⭐준비과정 - EDA
🎈Dataset Exploration
: 데이터 모델링을 하기 전에 데이터 변수별 기본적인 특성들을 탐색하고 데이터의 분포적인 특징 이해
🎈Missing Value
: 데이터를 수집하다 보면 일부 데이터가 수집되지 않고 결측치로 남아있는 경우가 있어서 이러한 부분 보정 필요
🎈Data types and converstion
: 데이터셋 안에 여러 종류의 데이터 타입(숫자, 텍스트, 범주, 시간 등)이 있을 수 있고, 이를 분석 가능한 형태로 변환 후 사용해야함
🎈Normalization
: 데이터 변수들의 단위가 크게 다른 경우 모델 학습에 영향을 주는 경우가 있어 정규화 함
ex) 몸무게, 소득
🎈outliers
:관측치 중에서 다른 관측치와 크게 차이가 나는 관측치들이 있고 이러한 관측치들은 모델링 전 처리가 필요함
🎈feature selection
:많은 변수 중에서 모델링을 할 때 중요한 변수가 있고 그렇지 않은 변수가 있어서 선택이 필요한 경우가 있음
🎈Data sampling
: 모델을 검증하거나 이상 관측치를 찾는 모델링을 할 때/ 앙상블 모델링을 할 때 데이터를 일부만 추출하는 과정을 거치기도 함
=> 이 모든 것을 다해야한다는 뜻은 아님!!
⭐모델링 검증
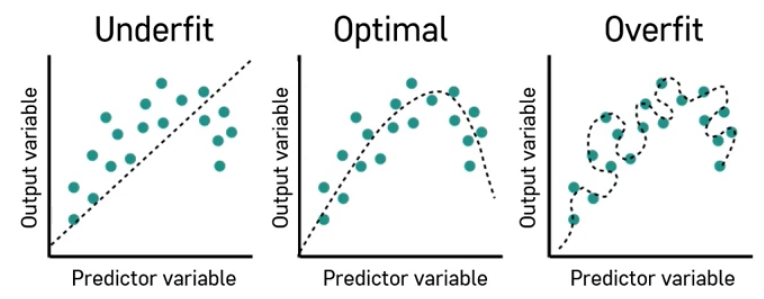
너무 간단하게 학습하면 underfit
너무 복잡하게 학습하면 overfit
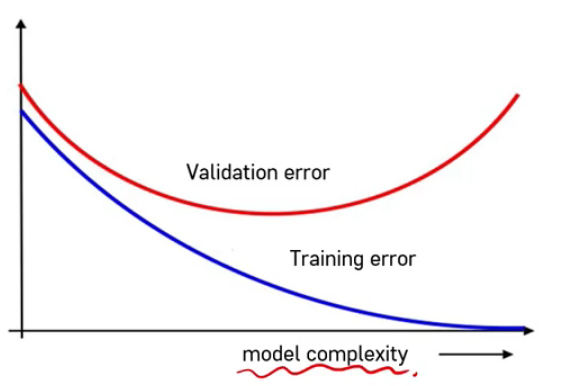
모델의 복잡도가 높으면(복잡하면 복잡할 수록) 트레이닝 에러는 줄어듦
모델의 복잡도가 높으면 validation error가 커짐
-> 오차가 너무 크면 언더피팅, 오버피팅을 의심해야함
⭐분류
-
기계학습
: 우리가 기계학습 모형이 문제를 해결해야하는 환경상황에서 테스크가 주어지고 우리는 어떠한 performance measure를 정의함
-> 테스크를 해결했을 때 accuracy, error 등을 사용해서 문제를 잘 해결했는지 확인 -
머신러닝 모형: Supervised Learning, Unsupervised Learning, Reinforcement Learning
🎈1. Supervised Learning: classification, regression
-> 지도학습: '이러이러한 input이 들어오면 이런 output이 나와야돼'라는 것을 정확히 알려주는 것
🎈2. Unsupervised Learning: clustering
-> 비지도학습: 컴퓨터 스스로 데이터에 있는 속성과 특징들을 추출, 사전에 정의된 레이블로 학습하지 않고 데이터 자체가 속해있는 속성들을 찾아내는 것
🎈3. Reinforcement Learning: Markov Decision Process, DQN, A3C
강화학습: 컴퓨터에 정확한 direction은 주지 않지만 컴퓨터가 취한 액션에 대해 잘했다 못했다라는 리워드를 줌으로써 학습
⭐Clasification
-
구분 기준:
'Y' == 출력변수
if) y가 연속형 -> regression
if) y가 범주형 -> classificaiton -
사용 예시
이미지 분류, 텍스트 분류, 정확한 구분선을 기준으로 구분 -
중요 개념
🔷Training dataset: 우리가 추정해야되는 함수를 최적화할때 사용
🔷Testing dataset: 학습할때 사용이 안된 데이터
ex) 100개 중 80개를 training하면 20개는 testing data가 됨
✒️ training만 잘 된다고 끝이 아니고, testing dataset의 성능을 봐야함
🔷hyper parameter: 함수의 특성을 결정지어주는, 기저가 되는 기저 함수
-> training dataset을 쪼개서 validation dataset에 먼저 적용 후 가장 좋은 후보를 training dataset에 적용하여 학습 후 testing에 이용
🔷Bias-Variance Tradeoff:
모형의 오차 = Bias + Variance
-> 모형이 복잡하면 복잡할수록 training 데이터의 미세한 패턴과 변동까지도 완벽하게 학습가능/ 변동성이 너무 큼
-> 모형의 복잡도가 낮으면 bias가 커짐(너무 간략하면 모형이 예측을 잘 못함)/ variance는 줄어들어 기존의 데이터가 빠지거나 추가되어도 모형이 크게 변동이 되지 않음
💥 모델의 복작도를 결정하는 것이 hyper parameter이다!!!
🔷complexcity
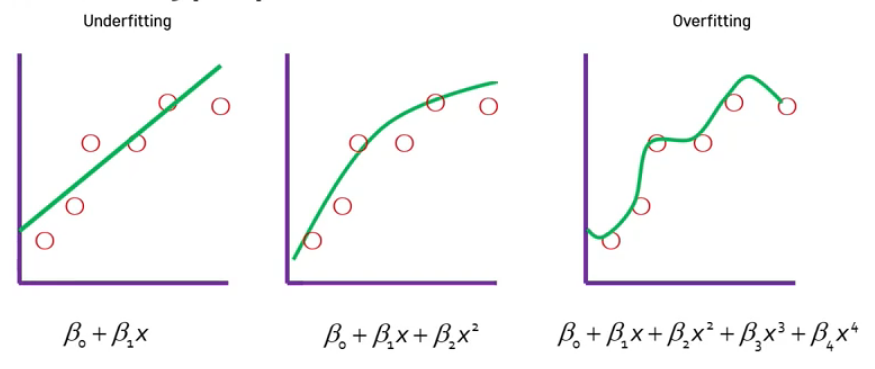
- complexcity 낮음: 데이터 패턴이 선 하나로 예측 -> 언더피팅
- complexcity 보통
- complexcity 높음: 데이터 패턴이 다양해서 곡선이 다채롭게 변화 -> 오버 피팅
=> 너무 높거나 낮으면 둘 다 일반화 성능이 안 좋을 수 있음
💥 hyperparameter를 적절히 잘 조절하자!!
-
예시
-제품이 불량인지 양품인지 분류
-고객이 이탈고객인지 잔류고객인지 분류
-카드거래가 정상적인지 사기인지 분류 -
모델
아주 다양함
K-nearest neighbor, logistic regression, decision tree, random forest 등등
⭐K-Nearest Neighbors
(k는 임의의 숫자)
: K개의 이웃들
-> 두 관측치의 거리가 가까우면 Y도 target 또는 해당 관측치의 label도 비슷하다
=> 관측치의 거리랑 가까우면 target도 비슷하다
=> majority voting(다수결)에 의해 주위에 있는 관측치들을 살펴보고 관측치의 레이블이 가장 다수에 속해진 클래스로 분류
🔷 거리에 기반하기 때문에 distance-based model,
🔷개별 instance들에 대해 특성들을 공유할 것이기에 instance-based learning이라고도 함
ex) 남녀 12명이 키와 몸무게 데이터 획득
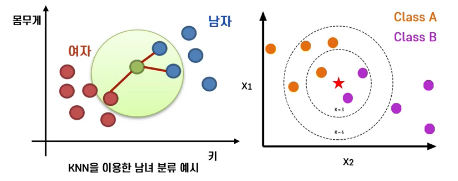
if) k=3
: 거리가 가장 가까운 3개의 관측치를 찾기
: 초록색 관측치의 가장 가까운 관측치 3개의 경우 남자 2, 여자 1명
: 초록색 관측치의 키와 몸무게를 봤을 때 초록색은 남자겠구나라고 예측할 수 있음
if) K가 커지거나 작아지면?
: 빨간색 별표를 분류하자
-> K가 3일때는 classB
-> K가 6이면 classA가 될 것임
💥 K가 변함에 따라 분류 결과가 달라지기 때문에 K는 hyper parameter
💥 K가 크면 클수록 단순화된 모형(복잡도가 낮음)
- lazy algorithm
-linear regression 같은 경우는 training data에 이미 학습을 시켜 놓으면 베타 값이 결정되고 실제 input이 되는 데이터가 오기만을 기다림 -> 데이터만 넣으면 바로 결과를 알 수 있음
-KNN은 가만히 있다가 테스팅을 해야하는 데이터가 오면 그 데이터 기준으로 거리를 구하고 최종적인 결과가 나옴 -> 게으름
- 거리의 종류
- Euclidean distance: 가장 대표적임
- Manhattan distance: 가각의 절대값을 더하는 것
- mankowski distance
✒️ 범주형 변수의 거리일때 -> dummy 변수 생성
ex) A=100, B=010, C=001로 추가하여 각 클래스를 대표하도록 함
💥 K가 크면 underfitting, K가 작으면 overfitting
💥 대략 k=15정도가 적당함
⭐Logistic Regression
-> linear regression의 classification 버전
: 다중 선형 회귀 분석, logistic function이라는 변환함수 사용
: 범주형 변수를 output으로 출력해야 함
🎈필요한 이유
ex) 종속 변수: 0 or 1
-> 불량품 0, 양품 1
종속 변수로 1 or 0만 나오는데 선형회귀를 여기에 바로 적합시키는 것이 의미가 있을까??
=> 정확한 숫자 개념이 아니라 분류되는 확률, 분류될 법한 정도를 모델링해야 되기 때문에 이 방식은 적합하지 않음
🎈예시
나이에 따라 암의 여부 진단(암이면 1, 아니면 0)
-> 그냥 선형 회귀를 이용하면 의미 없는 패턴을 학습
-> Age group으로 나누어 나이대에 따라 몇 명의 사람들이 존재하는지, % 등을 계산
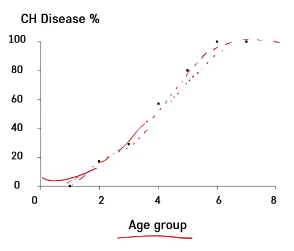
-> 커지다가 100%에 수렴하는 형태의 함수가 있으면 좋겠다!
=> 그 함수가 logistic function == sigmoid function
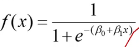
-> X가 - 무한대로 발산하면 0으로 수렴하고, X가 +무한대로 발산하면 1로 수렴
💥 따라서 이 함수가 0과 1사이의 값을 예측하기에 적합한 함수
* Loss 함수
: 분류 문제에서는 cross-entropy 사용 多
🎈cross-entropy
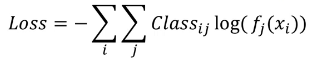
해당 클래스로 분류되는 확률 값을 넣고 두개의 곱 후 로그를 취함
ex) 22살(암 진단 X -0)과 78살(암 진단 O-1) 두 명
-> C_11log(f_11(x))-C_12log(f_12(x)) == -0log(0.21) -1log(0.79) == 0.2357
✒️로그는 자연로그
=> loss값을 minimize해주면 실제 클래스로 분류될 확률이 최대화 되는 값을 찾을 수 있음
❤️출처: K-MOOC 실습으로 배우는 머신러닝
