[논문 리뷰] DeepLOB: Deep Convolutional Neural Networks for Limit Order Books
Trading Machine Project
Paper From
https://arxiv.org/pdf/1808.03668.pdf
Overview
Feature
- 기존 모델과 달리, 과거 가격과 호가 잔량 정보만을 입력으로 사용
- Orderbook을 사용해 Classification 문제를 해결
- 모델이 훈련 데이터 세트에서 자체적으로 특징을 학습해 데이터에 적응하는(data-adaptive) 방식
Convolutional Layer
- LOB의 '공간-시간 이미지' 형태의 데이터를 처리하기 위해 사용
- 주요 목적은 모델이 데이터에서 특징(feature)을 추출하도록
- 금융 데이터는 Signal 대비 Noise가 많음
Detail of Convolutional Layer
Frequent order cancellations
주문의 90% 이상이 취소로 끝나고, 매칭으로 이어지는 경우는 적음
Top-level contributions to price discovery
Best-Ask, Best-Bid가 가격 발견에 가장 많은 기여를 한다는 연구 결과
다른 레벨들의 기여는 상대적으로 적으며, 전체의 약 20% 정도로 추정
Refine signals and make sense of data
LOB의 깊은 레벨 정보는 덜 유용하기에 신경망에 모두 공급하는 것은 비효율적임
따라서, 더 깊은 레벨의 정보를 합성곱 필터로 요약하여 신호를 정제
Inception Module
다양한 크기의 필터를 동시에 적용하여 더 복잡한 패턴을 감지
금융 데이터의 복잡성과 다양성을 다루기 위해 설계
LSTM Module and Output
Convolutional Layer과 Inception 모듈을 통해 추출된 특징들 사이의 시간적 의존성을 포착하고 분석
짧은 시간 의존성은 Convolutional Layer 층에서 이미 처리되므로,
더 긴 시간에 걸친 의존성을 학습하는 데 중점을 둠
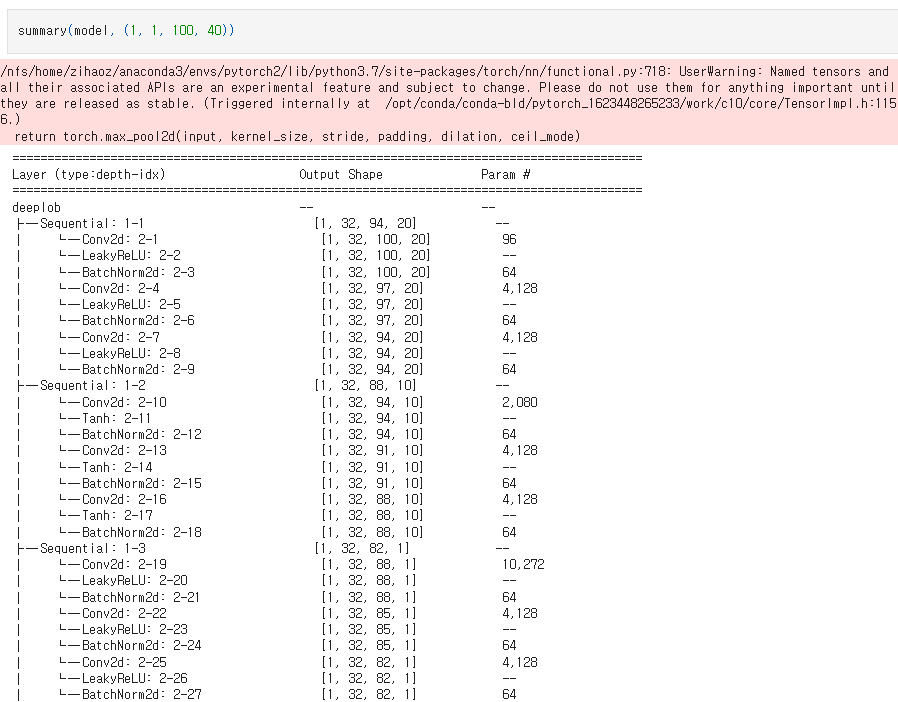
Architecture
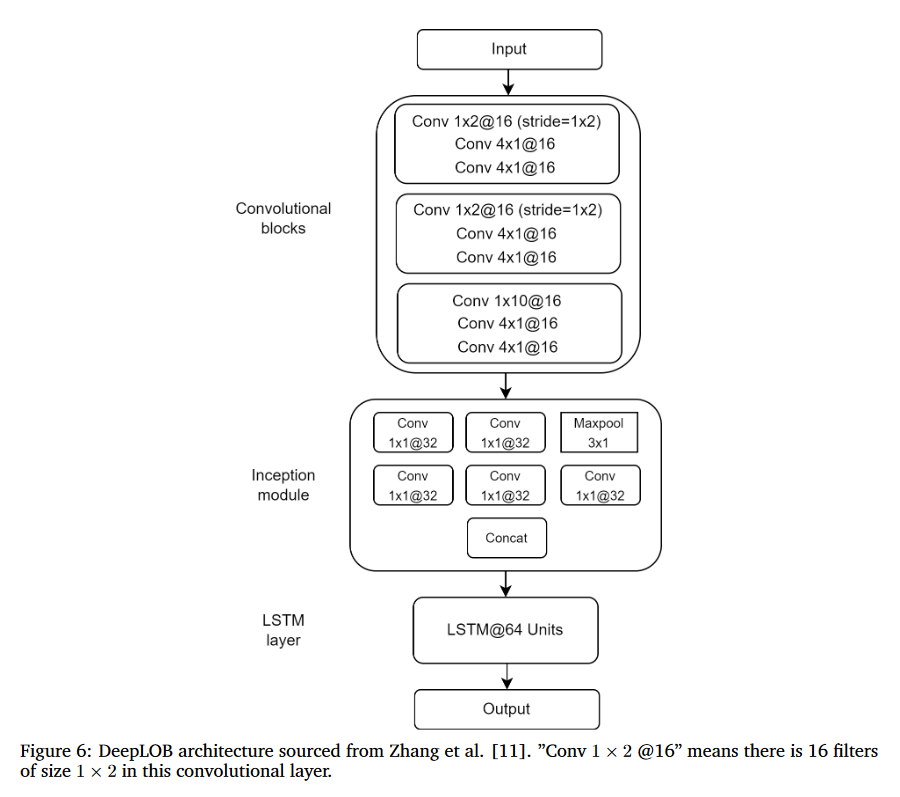
Convolutional Layer
# convolution blocks
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(1,2), stride=(1,2)),
nn.LeakyReLU(negative_slope=0.01),
# nn.Tanh(),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1,2), stride=(1,2)),
nn.Tanh(),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.Tanh(),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.Tanh(),
nn.BatchNorm2d(32),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1,10)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4,1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
Input Data
Conv & Stride (1st block)
-
Conv Fillter (1×2)를 함으로써 각 호가 단위에서 가격(p)과 거래량(v) 사이의 정보를 요약
-
Stride를 (1×2)로 함으로써 컨볼루션 층의 파라미터 공유(오버피팅 문제)를 피함 (ask 1 vol 과 ask 2 price의 요약 정보 -> 굳이 필요 없음)
Micro-Price (2st block)
-
(1×2) 크기 필터 와 (1×2) 크기 stride를 가진 레이어로 구성되고 이전 정보 특징 추출과 Micro Price Mapping
-
1st block에서 요약된 가격 정보들을 10개 호가에 대한 Micro Price 형태로 변환
Integrate all Information (3st block)
- (1×10) 크기 필터로 (orderbook 수 x 1) Feature Map 생성
- 위 아래 10개 호가에 대한 Micro Price를 1개의 정보로 압축
Imbalance
Micro Price
Inception Module
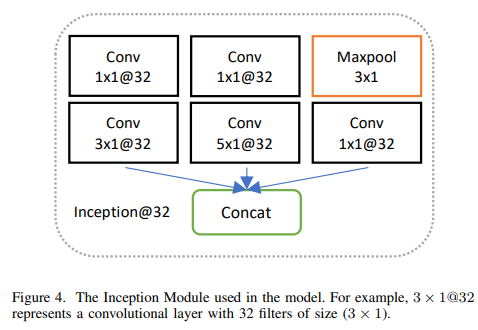
# inception moduels
self.inp1 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1,1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1,1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(5,1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp3 = nn.Sequential(
nn.MaxPool2d((3, 1), stride=(1, 1), padding=(1, 0)),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1,1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)Basic concepts of the Inception module
-
Inception 모듈은 여러 개의 합성곱을 함께 묶어서 다양한 시간 범위로 신호 포착
-
기술적 분석에서 다양한 이동 평균을 사용하는 것과 비슷
How the Inception module is structured and works
Max-pooling
- Conv Block에서 가장 중요한 정보만을 선택해서 가져오는 역할
- denoising
1×1 합성곱으로 데이터 분할
- 1×1 합성곱 사용해 데이터의 각 포인트를 필터로 걸치면서 차원 축소
다양한 크기의 필터로 데이터 변형
- 3×1과 5×1 크기의 필터를 사용하여 데이터의 다양한 부분을 확인
- 데이터에서 여러 패턴이나 특징을 찾음
Concat
- 각각의 필터를 통과한 데이터를 모두 합침
- 각기 다른 크기의 필터를 통해 얻은 정보들이 하나로 모여 유의미한 정보 생성
The benefits and practicality of the Inception module
LSTM Module and Output
Limitations of the Traditional Fully Connected Layer
-
Classification Task에서 Fully Connected Layer는 데이터의 각 입력이 서로 독립적이라고 가정
-
시계열 데이터처럼 시간에 따른 관계가 중요한 데이터에는 적합하지 않음
-
또한 Inception 모듈로 얻은 많은 특징들을 단순한 완전 연결 계층으로만 처리하면, 파라미터의 수가 상당히 늘어남
LSTM Module
# lstm layers
self.lstm = nn.LSTM(input_size=192, hidden_size=64, num_layers=1, batch_first=True)
self.fc1 = nn.Linear(64, self.y_len)- 64개의 LSTM 유닛을 사용
Final Output Layer and Softmax Activation Functions
- 소프트맥스(softmax) 활성화 함수를 사용
- 각 시간에 따른 각 Price Moving Class에 대한 확률 값 Return
Summary

Thought
- 호가 깊이에 따른 성능변화 연구도 시도 의미있는 연구가 될 것
