[Kaggle] Optiver Realized Volatility Prediction | 15th Place, Interesting Features - No Phishing | Part 1
Kaggle
Code From
https://www.kaggle.com/competitions/optiver-realized-volatility-prediction/discussion/276137
괜찮은 사진이 있어 가져와 보았습니다..!!
Time Binned Data Gen
시간에 따라 데이터를 구간으로 분할하여 생성하는 작업
binned_time_weighted_mean_stat
- wap, liquidity, spread, book_size, askliq1bal 같이 구간별 값이 필요한 경우 평균 값 사용
- bin 내의 값을 가중평균
binned_sum_impulse
- 값의 누적 값을 확인할 경우 사용
- bin 내의 모든 값을 sum
Clustering
특성 데이터 하나를 (3830,112,30)에서 axis=2 방향의 평균 값 압축하여
(3830,112) 사용해 112개의 주식을 Clustering
get_clusters
-
112개의 주식 데이터별로 피어슨 상관계수 계산 (112,112)
-
특성 데이터 (3830)에서 112개의 PCA 추출
-
하나의 주식의 특징이 잘 드러나도록 112 차원에서 표현함
-
PCA 결과는 기저벡터 (vector size : 1)이므로, 해당 기저 벡터에 분포하는 데이터의 표준편차를 곱함
-
각 기저 벡터 112개를 oblique decision tree로 2^depth 개로 분류
-
이후 GaussianMixture로 한 번 더 Clustering
-
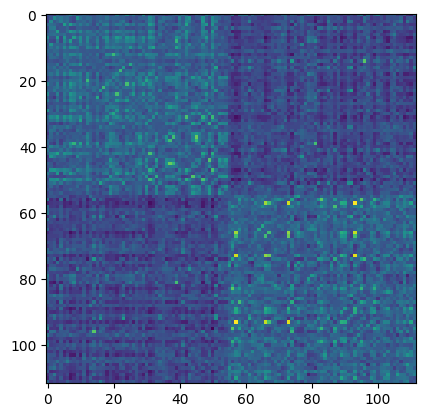
동일한 cluster 별로 순서대로 피어슨 상관계수를 시각화
-
대각행렬 기준으로 대칭이고, 색의 명암이 바뀌는 부분이 cluster간의 경계
-
해당 이미지에서는 하나의 축을 기준으로 두 개의 cluster 가 있음을 확인 가능
Features
최대한 많은 Feature를 뽑아 내고 그 중 괜찮은 것을 선택
get_features
- volatility bin 방향 값의 평균을 제곱 후 , sqrt 및 log
- volatility bin 방향 최근 15 bin의 평균 값을 이전 15 bin의 평균 값으로 나눔
get_cohesion_features
- 'lr1'을 기준으로 새로운 특징들을 추출
- 112 개의 주식의 3830개 데이터의 분산을 구하고 (1, 112, 30) 30개를 평균 => (1, 112) 후, sqrt한 값을 std로 저장
- 특정 bin 시점(ffrom) 이후 데이터만 따로 분리 한 후, 각 주식의 std 값으로 나눔
get_misc_features
- volume, root_volume, liquidity2,3 각 값의 time_id 축 (3830)과 bin 축 방향의 모든 값을 평균하여 s, sr, l2, l3 변수에 저장 (112)
soft_stock_mean TVPL Calculate
(shape 3830,112,30) x (shape 1,112,1) 연산은 (shape 3830,112,30)에 (shape 1,112,1) 크기에 맞는 모든 값을 곱해 줌
s/l2 의 shape은 (shape 1,112,1) 이다.
# Step 1 : 변동성과 유동성을 나눈 값
step_1 = vol[:,:, 0:]/liq2[:,:, 0:]
# (shape 3830,112,30)
# Step 2 : Step_1에 각 주식별 평균 변동성과 평균 유동성을 나눈 값(shape 1,112,1)을 곱한 후 1/8 제곱
step_2 = (step_1*l2/s)**(1/8)
# (shape 3830,112,30)
# Step 3 : 모든 stock_id를 평균하여 time_id 마다의 TVPL 값을 계산 후 8 제곱
step_3 = np.nanmean( step_2, (1,2), keepdims=True)**8
# (shape 3830, 1, 1)
# Step 4 : stock_id 별 특징과 time_id 별 특징을 행렬 곱 후,
# vol1의 realized volatility 계산 값으로 나누어줌
# step2의 l2/s의 역수 값이 곱해짐으로 값 상쇄
step_4 = (s/l2* step3)**.5/v1
# Step 5 : step4의 log 값을 취함
final_features['soft_stock_mean_tvpl2' ] = np.log(step_4)tvpl3_rmed2v1
step 1 : rvol 값의 평균(3830,112,1)을 r4liq3 (bin cutting)값의 평균 값으로 나눔
step 2 (tvpl3) : 해당 값을 4/3제곱 후 vol1 값으로 나누고 log
shape : (3830, 112, 1)
step 3 (tvpl3_rmed2v1) : tvpl3를 v1(3830,112,1)로 나눈 값을 각 timd_id 별로 중앙값에 해당하는 stock_id의 값으로 추출해 로그 값으로 저장
shape : (3830, 1 1)
이런 식으로 많은 파생 Features를 만들어냄
cluster_agg
Parameter
- x : bin 방향으로 평균된 3830x112x1 특징 데이터
- clusters : cluster index Array 1x112
- agg_fun : aggregate 어떤 기준으로 집계할지 numpy function
x와 동일한 shape array (r) 생성
cluster에서 가장 큰 수만큼 반복
동일 cluster의 값들의 평균으로 새로운 값 지정
이러한 방식으로 x값을 어떻게 넣는지 (제곱, 나누기, bin 개수 등)
agg_fun을 어떤 방식으로 할 것인지 (mean, median, std 등)
cluster_agg 결과에 어떤 값을 취할 것인지로
많은 특성들을 뽑아냄
quantile
각 특성의 4분위 수는 어떠한 지도 특성으로 활용
get_simple_features
Parameter
- binned_features : bin 묶음 데이터 (3830x112x30)
- final_features : simple feature를 저장할 최종 데이터
- name ('vol1') : binned_features에서 사용할 데이터, vol관련 특징을 주로 사용
- ffrom (25) : 사용할 bin 개수
step 1 : name에 해당하는 데이터를 binned_features에서 참조 후 v에 저장
shape : (3830,112,1)
step 2 : v의 모든 값을 제곱 후, bin 방향 평균 후 sqrt
step 3 : 이어서 해당 값을 timd_id 방향으로 평균 후 s에 저장
shape (1,112,1)
이어서 name_from_ffrom 와 name_stock_mean_from_ffrom 두 개의 특성을 만듦
step 4 :
-
name_from_ffrom : ffrom까지의 v의 모든 값을 제곱 후, bin 방향 평균 후 sqrt 값을 final_features['vol1']의 값으로 나누고 log
-
name_stock_mean_from_ffrom : ffrom까지의 v의 모든 값을 s로 나누고, bin 방향 평균 이후 stock_id 방향의 중앙 값으로 만들고 s를 곱한 후 log // median(3830,1,1) x s(1,112,1) => (3830,112,1)
ETC
vol1_mean / mean_half_delta / mean_half_delta_lsprd
특성도 추가 후 target data 추가
Summary
'stock_id', 'time_id', 'stock_ids', target을 제외한 총 190개의 특성을 생성
