[Kaggle] Optiver - Trading At The Close | K-Fold Time Series Split w/ Selective Ensemble
Kaggle
목록 보기
3/8
Code From
https://www.kaggle.com/code/whitgroves/k-fold-time-series-split-w-selective-ensemble
Main IDEA
다수의 모델을 학습 후 성능이 평균 이상인 모델들만 남긴 후 Ensemble
Code Flow
Result
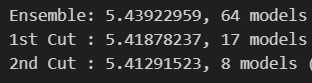
1차로 평균 이상의 앙상블 모델을 만든 후, 2차로 앙상블 모델을 한 번 더 필터링 => 2차의 결과가 더 좋게 나오는 것을 확인 (MAE)
cut1 = ensemble.prune()
cut2 = cut1.prune()
print(f'Ensemble: {ensemble.mean_score:.8f}, {len(ensemble)} models ({", ".join([m for m in ensemble.models])})')
print(f'1st Cut : {cut1.mean_score:.8f}, {len(cut1)} models ({", ".join([m for m in cut1.models])})')
print(f'2nd Cut : {cut2.mean_score:.8f}, {len(cut2)} models ({", ".join([m for m in cut2.models])})')SelectiveEnsemble Class
- mean_score() : Ensemble 전체의 평균 MAE를 Return
- best_score() : Ensemble 전체 중 가장 낮은 MAE를 Return
- best_model() : Ensemble 전체 중 가장 성능 좋은 모델 Return
- add() : Ensemble 모델 추가
- prune() : Ensemble 에서 MAE가 평균 이하인 모델만 남도록 재귀 순환
- clone() : Ensemble 복제
- predict() : Ensemble의 모든 모델로 Prediction
- len : Ensemble 내 모델 수 Return
- repr : Ensemble Reference
class SelectiveEnsemble: # once len(models) >= limit, reject new models with scores above the mean
def __init__(self, limit:int=None) -> None:
self.limit = limit
self.models = dict[str, IModel]()
self.scores = dict[str, float]()
self.kwargs = dict[str, dict]()
self.test_x, self.test_y = load_vars(test=True)
@property
def mean_score(self) -> float:
return sum(self.scores[m] for m in self.models) / len(self) if len(self) > 0 else None
@property
def best_score(self) -> float:
return min(self.scores[m] for m in self.models) if len(self) > 0 else None
@property
def best_model(self) -> tuple[IModel, str, dict]:
return [(self.models[m], m, self.kwargs[m].copy()) for m in self.models if self.scores[m] == self.best_score][0]
def add(self, model:IModel, name:str, kwargs:dict) -> tuple[bool, float]: # raises PredictionError
if name in self.models:
name = f'{name}(1)'
pred = model.predict(self.test_x, **kwargs)
# 예측을 하나의 값으로만 함
if len(np.unique(pred)) == 1:
raise PredictionError('Model is guessing a constant value.')
# 예측을 Nan 값으로 함
if np.isnan(pred).any():
raise PredictionError('Model is guessing NaN.')
score = met.mean_absolute_error(self.test_y, pred)
# self.limit : 수용 모델 수, None인 경우 무제한 수용 가능
# 수용 모델 수 확인
# 전체 모델의 평균 예측 값보다 낮은 경우 커트
if self.limit and len(self) >= self.limit and self.mean_score < score:
return False, score
self.models[name] = model
self.scores[name] = score
self.kwargs[name] = kwargs
return True, score
# 앙상블에서 평균 성능보다 낮은 모델들을 재귀적으로 제거
## 성능 == MAE 값이 낮은 것
def prune(self, limit:int=None) -> ext.Self:
pruned = SelectiveEnsemble(limit=(limit or self.limit))
pruned.models = {m:self.models[m] for m in self.models if self.scores[m] <= self.mean_score}
pruned.scores = {m:self.scores[m] for m in pruned.models}
pruned.kwargs = {m:self.kwargs[m] for m in pruned.models}
if pruned.limit and len(pruned) > pruned.limit > 1: return pruned.prune()
return pruned
def clone(self, limit:int=None) -> ext.Self:
clone = SelectiveEnsemble(limit=(limit or self.limit))
clone.models = self.models.copy()
clone.scores = self.scores.copy()
clone.kwargs = self.kwargs.copy()
return clone
def predict(self, X:pd.DataFrame, **kwargs) -> np.ndarray: # wrapper for soft voting; kwargs for compat
y = np.zeros(len(X))
for m in self.models:
pred = self.models[m].predict(X, **self.kwargs[m])
pred = pred.reshape(-1) # reshape needed for tensorflow output; doesn't impact other model types
# mask NaN and +/- inf to find largest valid values
temp = np.ma.masked_invalid(pred)
# then use those to clamp the invalid ones, Nan => Zero
pred = np.nan_to_num(pred, posinf=temp.max()+temp.std(), neginf=temp.min()-temp.std())
y += pred
y = y / len(self)
return y
def __len__(self) -> int:
return len(self.models)
def __repr__(self) -> str:
return f'<SelectiveEnsemble ({len(self)} model(s); mean: {self.mean_score:.8f}; best: {self.best_score:.8f}; limit: {self.limit})>'
class PredictionError(Exception): pass # specific for training feedback
class IModel(ext.Protocol): # partial wrapper for sklearn API
def fit(self, X, y, **kwargs) -> ext.Self: ...
def predict(self, X, **kwargs) -> np.ndarray: ...
def get_params(self, deep=True) -> dict[str, ext.Any]: ...Model Creation & Hyper Parameter
- Sequential (MLP)
- XGBRegressor
- LGBMRegressor
- CatBoostRegressor
위 초기 모델들을 생성 후
최대 모델 개수 21, k-fold 10인 SelectiveEnsemble 생성
N_FEATURES = len(load_vars(test=True)[0].columns)
ACTIVATION_1 = 'tanh' # inputs are standardized so keep negative range
ACTIVATION_2 = 'relu' # performed better than tanh, sigmoid
DROPOUT = 0.5 # performed better than 0.3, 0.4
RANDOM_STATE = 25 # funnier than 24
layers = tf.keras.layers
Sequential = tf.keras.Sequential
regularizer = tf.keras.regularizers.l1(0.001)
tf.keras.utils.set_random_seed(RANDOM_STATE)
shared_kw = dict(random_state=RANDOM_STATE, learning_rate=0.2, max_depth=3, subsample=0.8)
xgb_lgb_kw = dict(n_jobs=16, colsample_bytree=0.85, reg_alpha=500)
xgb_cat_kw = dict(early_stopping_rounds=5)
lgb_cat_kw = dict(num_leaves=8, min_child_samples=2000)
models = [ # order matters if limit is set; frontloading stronger models will cause more rejections; the reverse will oversaturate
Sequential([ # 145 -> 18 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//8, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='octo'),
Sequential([ # 145 -> 36 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//4, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='quad'),
Sequential([ # 145 -> 72 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//2, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='duce'),
Sequential([ # 145 -> 145 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='mono'),
xgb.XGBRegressor(**shared_kw, **xgb_lgb_kw, **xgb_cat_kw, eval_metric='mae', tree_method='hist', gamma=0.2), #, nthread=1),
lgb.LGBMRegressor(**shared_kw, **xgb_lgb_kw, **lgb_cat_kw, early_stopping_round=5, metric='l1', min_split_gain=0.001, verbosity=-1),
cat.CatBoostRegressor(**shared_kw, **xgb_cat_kw, **lgb_cat_kw, eval_metric='MAE'),
Sequential([layers.Dense(1, activation=ACTIVATION_1, input_shape=[N_FEATURES])], name='linear'), # 145 -> 1
Sequential([ # 145 -> 72 -> 36 -> 18 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//2, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//4, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(N_FEATURES//8, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='deep'),
Sequential([ # 145 -> 89 -> 13 -> 5 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(89, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(13, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(5 , kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='fib'),
Sequential([ # 145 -> 29 -> 5 -> 1
layers.Dense(N_FEATURES, kernel_regularizer=regularizer, activation=ACTIVATION_1, input_shape=[N_FEATURES]),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(29, kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(5 , kernel_regularizer=regularizer, activation=ACTIVATION_2),
layers.Dropout(DROPOUT),
layers.BatchNormalization(),
layers.Dense(1)
], name='prime'),
]
try: ensemble = train_ensemble(models, limit=1, folds=10, ensemble=load_ensemble())
except FileNotFoundError: ensemble = train_ensemble(models, limit=21, folds=10)
ensembleBuild Ensemble
train_ensemble()
load_vars()에서 Data Set을 로드하여 앙상블을 구축
기존 앙상블이 제공되면, 해당 앙상블로 업데이트
- TimeSeriesSplit를 사용해 Train Set 길이를 늘려가며 고정된 길이의 Vaildation Set으로 Hyperparameter 조정
- Sequential 인 경우, Adam optimizer과 MAE Loss 사용
- 반복하며 모델 별로 학습 진행 시 메모리 초과 및 단일 값으로 예측 시 해당 모델 Pass
def train_ensemble(models:list[IModel], folds:int=5, limit:int=None, ensemble:SelectiveEnsemble=None) -> SelectiveEnsemble:
setup_start = time.time()
print(f'Pre-training setup...', end='\r')
ensemble = ensemble.clone(limit=(limit or len(ensemble))) if ensemble else SelectiveEnsemble(limit=(limit or len(models)))
cv = sel.TimeSeriesSplit(folds)
X, y = load_vars()
setup_time = time.time() - setup_start
print(f'Pre-training setup...Complete ({setup_time:.1f}s)')
for j, model in enumerate(models): # each model gets its own ensemble, then the best fold will be added to the main
name = type(model).__name__
is_sequential = name == 'Sequential'
if is_sequential:
model.compile(optimizer='adam', loss='mae')
name = model.name
_msg = f'Model {j+1}/{len(models)}:'
# (i_train, i_valid) : index List 반환
for i, (i_train, i_valid) in enumerate(cv.split(X)):
try: # fail gracefully instead of giving up on the whole ensemble
fold_start = time.time()
_name = f'{name}_{int(time.time())}'
msg = f'{_msg} Fold {i+1}/{folds}:'
print(f'{msg} Training {name}...'+' '*48, end='\r')
X_valid, y_valid = X.iloc[i_valid, :], y.iloc[i_valid]
fit_kw, predict_kw, early_stop_kw = build_model_kwargs(model, (X_valid, y_valid))
# Train / Vaildation
try:
model.fit(X.iloc[i_train, :], y.iloc[i_train], **fit_kw) # some kwargs fail on kaggle
except:
model.fit(X.iloc[i_train, :], y.iloc[i_train], **early_stop_kw) # fallback to early stop only
del X_valid, y_valid
mem_total = process.memory_info().rss / 1024**3 # B -> GiB
if MEMORY_CAP and mem_total > MEMORY_CAP:
raise MemoryError(f'High memory allocation ({mem_total:.1f} > {MEMORY_CAP:.1f} GiB)')
# plug memory leak
print(f'{msg} Adding {name} to ensemble...', end='\r')
if is_sequential:
clone = tf.keras.models.clone_model(model)
clone.set_weights(model.get_weights())
else:
clone = None
res, score = ensemble.add((clone or model), _name, predict_kw)
# save model
if (res): joblib.dump(model, os.path.join(MODEL_FOLDER, f'{_name}.joblib'))
fold_time = time.time()-fold_start
print(f'{msg} {("Accepted" if res else "Rejected")} with score: {score:.8f}'
+f' ({fold_time:.1f}s) ({mem_total:.1f} GiB)'+(f' ({_name})' if res else '')+' '*10)
except Exception as e:
print(f'{msg} Stopped: {type(e).__name__}: {e}')
# these tend not to improve, so move on to the next model
if isinstance(e, PredictionError): break
# malloc resets with each model, so move on if exceeded
if isinstance(e, MemoryError): break
finally:
while gc.collect() > 0: pass # memory is at a premium
return ensemble
개발 새발