Conv 1d, 2d, 3d
- DeepLOB에서 사용되는 Conv는 2D 이지만, Filter가 1xn 이므로 1D와 거의 유사
DeepLOB
CNN
- N개의 호가를 1개의 Feature로 변환하는 작업
- T개의 LookBack을 압축하며 Time Series Noise 제거하는 작업
Inception
- 64개의 1x1 Filter로 차원 구체화
- 3x1, 5x1 Filter 및 3x1 Max Pooling으로 구체화 차원 분석
LSTM
- Inception에서 3개의 Layer에서 추출된 각각의 64개 Feature Concat
- Denosing된 Time Series를 LSTM 분석
Except LOB Feature
Features
LSTM(GRU) 이전 부분을 CNN 분석을 통한 Feature 화 진행 후
LOB Feature와 Concat 이후 LSTM의 Input으로 사용
num rows : 30s 간 거래 횟수
trade vol : 30s 간 거래량
high lowgap : 30s 간 윗 꼬리 아랫 꼬리 길이
volume power : 매수 매도 매물 차를 거래량으로 나눔
ob end bias : ask size / bid size
ob end_bidask spread : (bid-ask) / (최소 tick 별 spread)
ob end liq : bs{i}/(wap1 - bp{i}]) + as{i}/(ap{i} - wap_1) 누적 합
highest_possible_return : 30s 간 가장 비싸게 팔 수 있었던 수익률
LOB + Except Feature
import torch
import torch.nn as nn
class Lobster_A(nn.Module):
def __init__(self, level):
super().__init__()
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.name = 'lobster'
# convolution blocks
self.conv1 = nn.Sequential(
# in_channels = 이미지 한 장 (가로 축 : bid 16 ~ ask 16 / 세로 축 : Look Back 행 수)
# (1,2) size 32개 Filter로 (1,2) stride => 가격+잔량 데이터 압축 (압축 호가)
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(1, 2), stride=(1, 2)),
# x<0 구간은 y=0.01x ReLU
nn.LeakyReLU(negative_slope=0.01),
# 32개의 out_channels 배치 정규화
nn.BatchNorm2d(32),
# Lookback (세로 방향) 으로 4행만큼 정보 압축 => 세로 방향 shape 3 감소
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
# Lookback (세로 방향) 으로 4행만큼 정보 압축 => 세로 방향 shape 3 감소
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
self.conv2 = nn.Sequential(
# 압축 호가 2호가에 대해서 추가 압축호가 분석
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1, 2), stride=(1, 2)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
# Lookback (세로 방향) 으로 4행만큼 정보 압축 => 세로 방향 shape 3 감소
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
# Lookback (세로 방향) 으로 4행만큼 정보 압축 => 세로 방향 shape 3 감소
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
# 전체 압축 호가를 1개의 Feature로 압축
# 압축호가 걸침에 따라 호가 Feature는 (가로) 1/4로 압축이 됨
# Output Shape 4차원 : batchsize, channels, lookback -18, 압축호가 1
conv3_kernel_size = int(level/4)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1, conv3_kernel_size)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
# 추가 Feature CNN 분석
features = 13
self.conv1_1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(1, features)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(10, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(10, 1)),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(32),
)
# inception modules
self.inp1 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(5, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp3 = nn.Sequential(
nn.MaxPool2d((3, 1), stride=(1, 1), padding=(1, 0)),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
# 추가 Feature Inception 분석
self.inp1_1 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp2_1 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(5, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
self.inp3_1 = nn.Sequential(
nn.MaxPool2d((3, 1), stride=(1, 1), padding=(1, 0)),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
nn.LeakyReLU(negative_slope=0.01),
nn.BatchNorm2d(64),
)
# gru layers
self.dropout = nn.Dropout(p=0.1)
self.gru = nn.GRU(input_size=384, hidden_size=128, num_layers=1, batch_first=True)
# 변경된 부분: 최종 출력을 1로 설정하여 회귀 문제에 맞게 조정
self.fc1 = nn.Linear(128, 1)
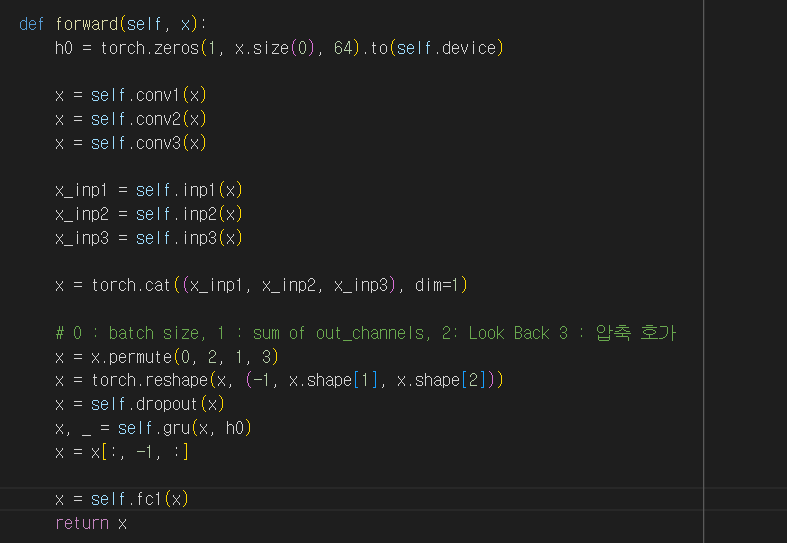
def forward(self, x):
h0 = torch.zeros(1, x.size(0), 128).to(self.device)
# 첫 번째 부분: 마지막 차원에서 처음 28개 요소 선택
x_part1 = x[:, :, :, :28]
# 두 번째 부분: 마지막 차원에서 나머지 19개 요소 선택
x_part2 = x[:, :, :, 28:]
x_part1 = self.conv1(x_part1)
x_part1 = self.conv2(x_part1)
x_part1 = self.conv3(x_part1)
x_part2 = self.conv1_1(x_part2)
x_inp1 = self.inp1(x_part1)
x_inp2 = self.inp2(x_part1)
x_inp3 = self.inp3(x_part1)
x_inp1_1 = self.inp1_1(x_part2)
x_inp2_1 = self.inp2_1(x_part2)
x_inp3_1 = self.inp3_1(x_part2)
x = torch.cat((x_inp1, x_inp2, x_inp3, x_inp1_1, x_inp2_1, x_inp3_1), dim=1)
# 0 : batch size, 1 : sum of out_channels, 2: Look Back 3 : 압축 호가
x = x.permute(0, 2, 1, 3)
x = torch.reshape(x, (-1, x.shape[1], x.shape[2]))
x = self.dropout(x)
x, _ = self.gru(x, h0)
x = x[:, -1, :]
x = self.fc1(x)
return x

개발 새발