[논문리뷰] Patent analysis and classification prediction of biomedicine industry: SOM-KPCA-SVM model
Paper Review
Introduction
-
SOM-KPCA-SVM 모델로 생명 과학 산업에서 특허 품질(가치) 분류와 예측
-
특허 기관에 매년 상당한 양의 특허가 제출 되는데, 각 특허의 가치 평가와 진실 여부를 따지는 데에는 많은 비용이 소모 됨
-
해당 논문에서는 바이오 산업에서의 Patenet 가치를 Class를 나눠 분류하는 것을 목표로 함
-
고도화된 기술력 / 높은 투자 금액 / 긴 주기(임상) / 리스크 / High Income
Overview
Flow
- SOM을 사용하여 특허 데이터를 그룹화하고 특허 Quality 정의
- KPCA로 Noise 감소 후, SVM로 Classification 결과 도출
- 11,251 / 2,196 (Train / Test) -> Accuracy 84.13%
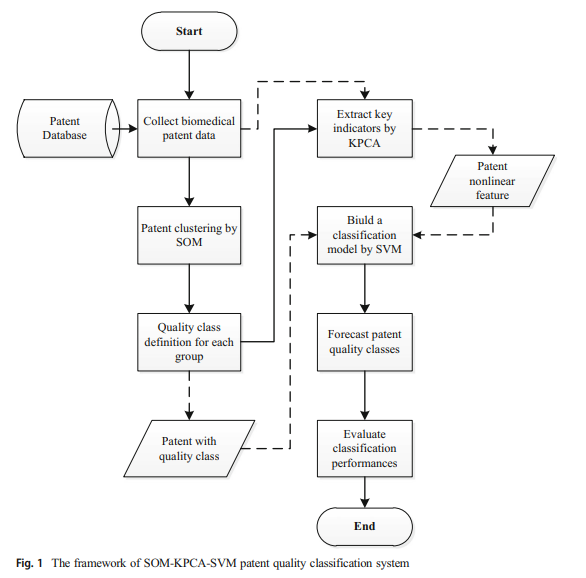
3. Model introduction
3.1 Phase one: patent quality Analysis & Definition
3.1.1 특허 품질 지표 데이터의 수집 및 계산
-
WebPat, PatBase, Google Patent Search, Thomson Innovation 및 국가 특허청에서 Data 수집
-
특허 특징 추출 및 Quality Index 산출 (y)
-
Quality Index Min-Max Scale
-
Quality Index에 따른 Manually Classification이 있을 것이라 생각
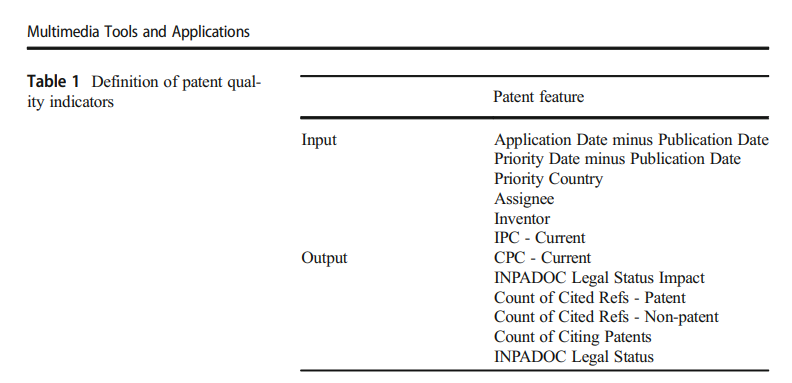
3.1.2 SOM (Self-Organizing Map) 기반 특허 Quality 계산
- SOM (비지도 분류)
- SOM 알고리즘을 사용해 Input Feature 기준 Grouping
3.2 Phase two: Prediction of patent quality classification
-
Patent documnets에서 Key features Extract (KPCA)
-
Quality Classification 모델 학습 (SVM)
-
3.1.1 Quiality Index에 사용된 variable은 SVM 변수로 사용 X
-
New Patent는 Quality Indicator들이 명확하지 않으므로 Patent 자체의 특성만을 사용
Patent Features of KPCA
- Data Noise 감소 및 Dimension 감소
- Train data / Test data는 publication year 따라 나눔
Prediction of patent quality (SVM)
- SVM (지도 분류)
- Input : KPCA Feature + SOM Feature
Evaluation of patent quality classification performance
- ACC / Precision / Recall로 평가
4. Experimental results
- Data Time scale에 따른 결과 (5y / 10y / 40y)
- Quaility group (3 / 5 / 7)
- KPCA 사용 Features (25% / 50% / 75% / 100%)
4.1 Patent data collection and statistical analysis
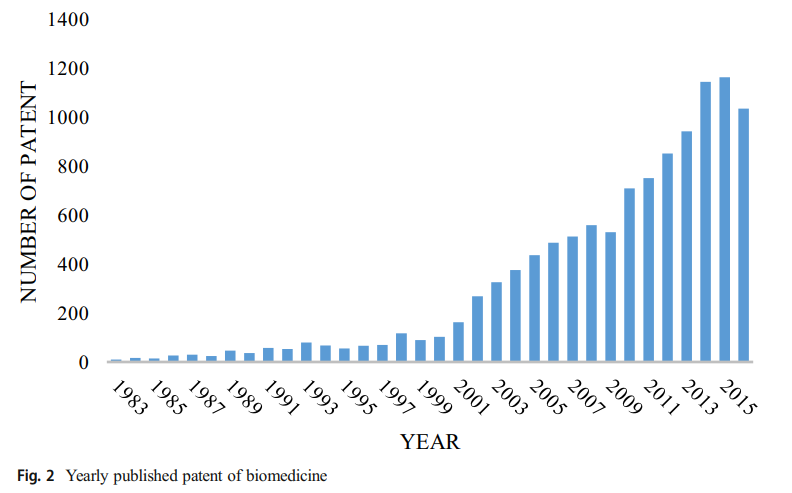
- ST Group : 2012 ~ 2016
- MT Group : 2007 ~ 2016
- LT Group : 1977 ~ 2016
4.2 Analysis results of patent quality
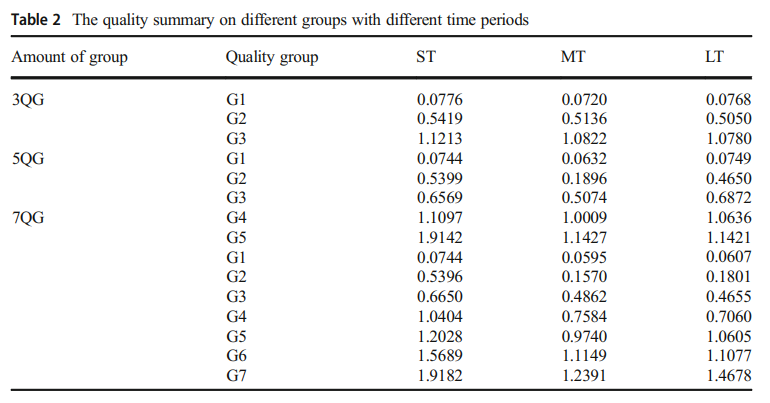
- G1 저품질 논문 그룹 ~ G7 고품질 논문 그룹
- SOM Step의 Quailty Score
Group 별 Patent 수 분포
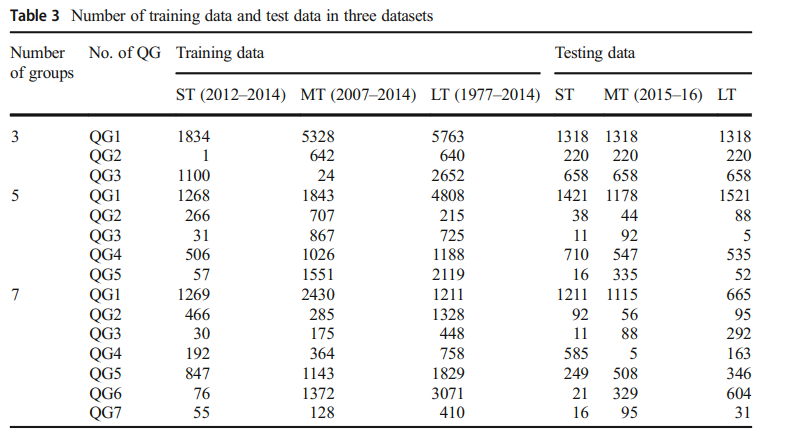
- G(Quality)가 높아질수록 수가 줄어듦
KPCA 방법론 및 KPCA Feature 사용률에 따른 설명력 비교
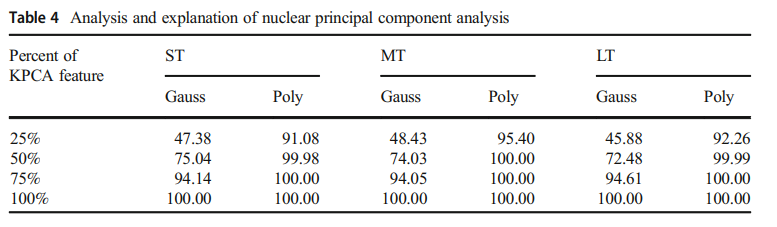
- KPCA에서 다항커널함수를 사용했을 때, 설명력이 가우시안 함수보다 높음을 확인
5. Discussion
그룹 수
- 3개 그룹을 사용하여 클러스터링할 때 품질 그룹 내 그룹 간의 유사성이 너무 높아 그룹 간의 차이가 뚜렷하지 않음
- 7개 그룹 클러스터링을 사용하면 더 많은 범주로 인해 카테고리를 설정하기 어려움
- 5개의 클러스터 그룹으로 구분할 때 각 그룹의 특허 수가 설명력이 높게 나옴
KPCA of Kernel
- 안 하는 것보다 커널을 적용하는 것이 성능이 좋게 나왔고,
- 가우스 커널의 처리 시간은 매우 짧았으나
- 다항식 커널이 정확도, 정밀도, 재현율이 더 좋았음
Review
-
SOM이 Group의 근거가 무엇인지?
-
이전에 다뤘던 논문들과 비슷한 Feature들을 사용하였음
-
SOM, K-PCA의 Input Data를 어떻게 넣고, SVM 시 Data를 어떻게 Concat 하였는지에 대한 서술이 없어서 아쉬움
-
과거 Patent의 가치를 다루기에는 쉽지만, 최근 Publish 된 Patent의 가치는 Patent 내부 요소들로 최대한 끌어내야한다는 문제
