B+트리 인덱스
이전 포스팅에서 본 indexed-sequential file들은 인덱스를 통해 정렬된 레코드에 접근할 수 있다. 하지만 이러한 파일구조는 파일의 크기가 커질수록(레코드의 수가 많아질 수록) 누적된 Insert와 Delete연산으로 인해 많은 오버플로우 블록이 만들어져 전체적인 성능이 떨어지고, 때문에 주기적으로 인덱스 파일을 재구성하여 오버플로우 블록을 정리해야할 필요가 있다. 이런 문제를 해결하기 위해 대부분의 주요 DBMS에서는 B+트리 인덱스를 사용하여 조회 성능을 높인다.
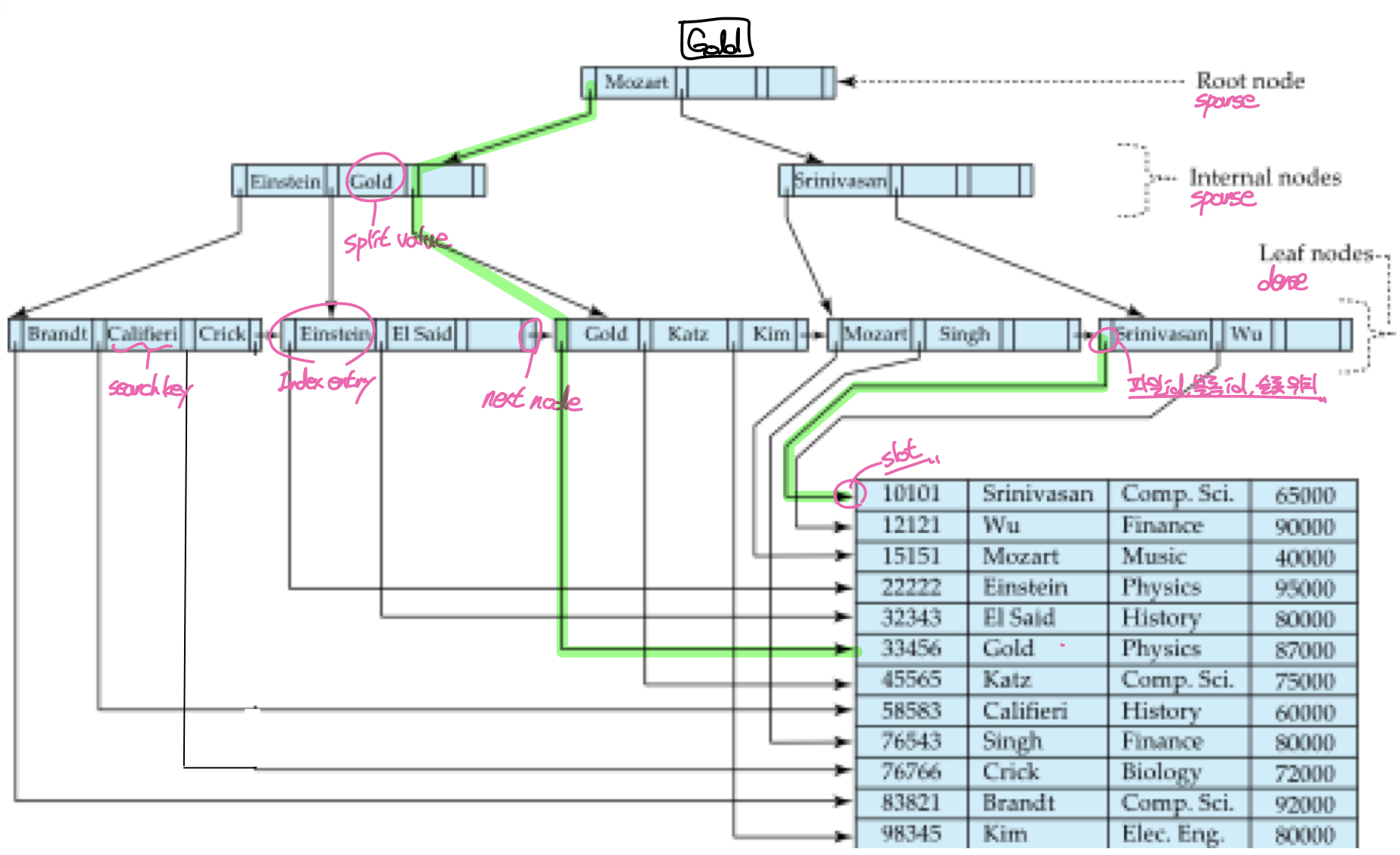
B+트리 인덱스는 Multilevel index의 한 종류로, root node와 internal node에는 split value와 하위 노드로의 포인터만 존재하고, leaf node에는 각 레코드의 search key값과 레코드로의 포인터가 존재한다. 루트와 중간노드의 split value는 찾으려는 레코드의 search key값과 비교하여 레코드의 위치를 알려주기 위한 값으로, 키값이 split value보다 작으면 왼쪽, 크거나 같으면 오른쪽 포인터를 타고 하위 노드로 내려간다. leaf node에는 레코드의 search key와 포인터들이 보관되는데, 한 쌍의 키와 포인터를 묶어 index entry를 구성한다. 즉, 레코드의 물리적 위치는 leaf node에만 저장되기 때문에 항상 leaf node에서 탐색이 종료된다.
또한 B+트리는 멀티레벨 인덱스의 일종이기 때문에 leaf node는 dense index의 역할을 하고, 상위 노드들은 leaf node(dense index)를 관리하는 sparse index의 역할을 한다. 이때 각 노드들은 하나의 블록으로 디스크에 저장되고, 탐색 중 해당 노드를 방문하였을 때 메모리 버퍼로 올라와 작업을 수행한다.
B+트리 인덱스를 사용하여 레코드를 조회할 때에는 먼저 찾고자 하는 레코드의 키값을 루트노드의 split value와 비교한 뒤 방향을 찾고, leaf node에 도달할 때까지 중간 노드의 split value와 앞의 과정을 반복한다. leaf node에 도착했으면 레코드의 키값과 일치하는 search key가 가리키는 포인터를 통해 레코드에 접근한다. 즉, root node -> internal node -> leaf node -> record순으로 탐색이 이루어진다.
B+트리의 조건
B+트리는 탐색 성능을 최대화 하기 위한 균형 트리로 모든 leaf node가 같은 레벨로 유지되도록 아래의 조건을 만족해야 한다.
- 균형조건 : root node로부터 leaf node로의 모든 경로의 길이는 같다(균형 트리)
- 트리의 높이를 최소화하여 탐색의 성능을 높임
- 공간조건 : 각 노드가 최소 절반 이상은 채워져있어야 한다(n : 트리의 차수. 하나의 노드가 최대로 가질 수 있는 포인터의 수)
- internal node : ceil(n/2) ~ n개의 자식노드가 있어야 함
- leaf node : ceil((n-1)/2) ~ n-1개의 search key(혹은 index entry)를 가져야 함
- root node : 루트 노드가 leaf가 아니면 최소 1개의 split value를 가질 수 있음. 만약 루트 노드가 leaf라면 0 ~ n-1개의 엔트리를 가질 수 있음
B+트리 노드 구조

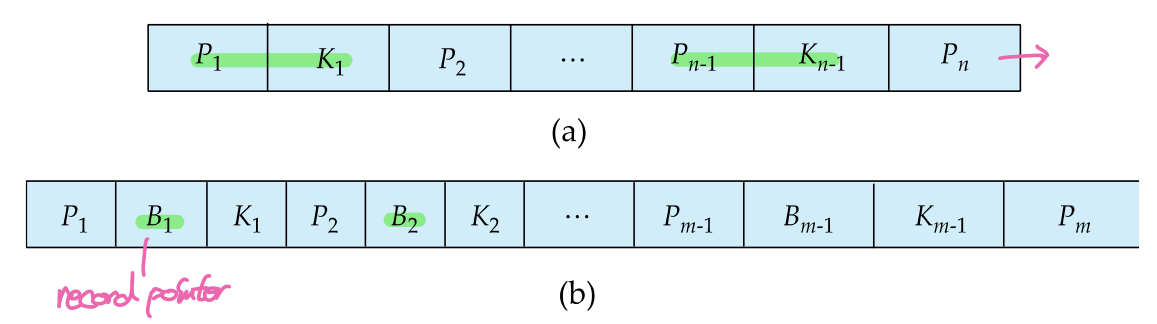
n차 B+트리의 각 노드들은 총 n개의 포인터와 n-1개의 키로 구성된다. 각 포인터는 하위노드 혹은 레코드의 물리적 주소를 가리키고, 한 노드 안의 모든 키값은 순서대로 정렬되어있다.
non-leaf node
non-leaf node에서의 key는 split value의 역할을 하고, split value와 같거나 큰 키값은 오른쪽 포인터를 따라가기 때문에 non-leaf 노드에서는 첫번째 포인터를 제외한 나머지 값들이 키-포인터 쌍을 이룬다. 이때 포인터는 하위노드를 가리킨다. 즉, 위의 사진에서 Pn-1은 Kn-2보다 크거나 같고 Kn-1보다 작은 search key들이 있는 노드를 가리키는 포인터이다.
leaf node

leaf node에서는 포인터가 레코드의 물리적 주소를 가리키고, 키값은 실제 레코드의 search key값을 의미한다. 또한 B+트리에서 모든 leaf node들은 순서대로 연결되어있기 때문에 마지막 포인터를 제외한 나머지 값들이 포인터-키 쌍을 이루고, 마지막 포인터는 다음 leaf node를 가리킨다. leaf node에서 마지막 포인터를 뺀 나머지 포인터들은 레코드의 위치정보를 담고있어야 하기 때문에 실제로는 해당 레코드가 속한 파일과 블록의 id, 레코드를 가리키는 슬롯의 주소를 담고 있다.
Rebuild
B+트리에서 각 노드는 포인터로 연결되기 때문에, 논리적으로 인접한 노드가 꼭 물리적으로 인접할 필요는 없다. 따라서 초기에는 인덱스의 논리적 구조와 물리적 구조가 일치하지만, 삽입/삭제 연산이 누적될수록 노드들이 분할되고 병합되면서 인접한 노드의 물리적인 위치가 변하게 된다.
B+트리에서 일반적으로 각 노드는 하나의 디스크 블록을 차지하므로 노드를 방문할 때마다 I/O작업이 발생하게 되는데, 인접한 노드들이 디스크에서 서로 다른 트랙에 위치하게 되면 seek time이 늘어나 결과적으로 인덱스의 성능이 떨어지게 된다. 따라서 누적된 연산으로 성능이 저하된 인덱스를 되돌리기 위해 인덱스를 Rebuild하여 초기상태로 되돌림으로써 인덱스의 성능을 유지할 수 있다.
Non-unique search key
만약 B+트리의 search key가 unique하지 않을 경우 leaf node의 하나의 포인터가 여러 레코드를 참조해야 하는 상황이 발생한다. 이때 생각해볼 수 있는 방법은 다음과 같다.
- leaf node의 포인터가 bucket을 가리키고, bucket은 동일한 search key를 가진 레코드들의 주소를 저장
- 각 bucket의 길이가 달라 불편하므로 대부분의 DBMS에서는 bucket을 사용하지 않는다.
- bucket layer를 B+트리의 leaf node로 설정하는 방법
- 구현이 복잡하고 중복되는 키값이 많을 경우 삭제에 많은 시간이 소모될 수 있다.
- search key에 id를 더해 unique하게 만들어 사용하는 방법(uniquifier)
- Composite key 사용
- 키의 크기가 커지므로 추가적인 공간이 필요하지만 삽입/삭제 연산이 간단하여 대부분의 DBMS에서 채택
이 중 세번째 방법은 unique하지 않은 search key에 unique한 값을 결합하여 unique한 합성키를 만들고, 이 합성키를 기준으로 인덱스를 생성하는 방법이다. 이때 결합되는 값은 PK나 레코드 id등 다양한 값이 될 수 있지만, 중요한것은 유일함을 보장할 수 있는 값만 결합될 수 있다.
non-unique search key에 대한 인덱스는 DBMS내부적으로 합성키를 만들어서 사용하지만, 사용자가 직접 구성한 합성키 인덱스와는 다르다. 후자는 사용자가 합성키를 통해 인덱스를 구성하고 사용하는것을 알고있는것에 반해, 전자의 사용자는 DBMS의 내부적인 동작은 모른채로 단지 non-unique키를 마치 unique키를 사용하는 것처럼 느낀다. 인덱스를 생성하는 쿼리문을 보면 차이가 명확하게 드러난다.
- non-unique search key index : create index INDEX-NAME on TABLE-NAME(NON-UNIQUE-COLUMN)
- composite key index : create index INDEX-NAME on TABLE-NAME(COLUMN1, COLUMN2, ...)
DBMS는 non-unique키에 대한 인덱스를 unique한 합성키를 사용하여 변환하기 때문에 사용자에게 구체적인 키값에 대한 조회 쿼리가 들어오면 내부적으로 range query로 교체하여 레코드를 찾는다. 예를 들어 non-unique한 A column을 통해 인덱스를 만들었을 때, A = 10인 데이터를 조회하는 쿼리가 들어오면 DBMS는 아래와 같은 순서로 데이터를 찾는다.
- (인덱스 생성시) unique한 값과 결합하여 합성키를 만든다 : <A, uniq>
- 쿼리를 uniq값이 -inf ~ +inf인 범위 쿼리로 바꾼다
- select * from TABLE where A = 10 -> select * from TABLE where (A, uniq) >= (10, -inf) and (A, uniq) <= (10, +inf)
위와 같은 과정을 통해 사용자는 non-unique키에 대해서도 인덱스를 만들어 사용할 수 있다.
B+트리 업데이트 연산
Insert
B+트리에 노드를 삽입하는 작업은 일반적으로 아래와 같은 순서로 이루어진다.
- 엔트리가 삽입될 노드를 B+트리에서 조회
- leaf node에 빈 자리가 있으면 삽입, 빈 자리가 없으면 노드를 분할한 뒤 삽입
leaf node에 여유공간이 있으면 단순히 노드 안에서 순서를 조정하여 엔트리를 삽입하는 것으로 작업이 완료된다. 하지만 엔트리가 들어가야 할 leaf node에 여유공간이 없어 오버플로우가 발생하는 경우 leaf node를 분할하고 엔트리를 분배한 뒤 leaf node와 그 부모를 업데이트 해야한다. 이 작업은 부모 노드에서도 오버플로우가 발생하는지에 따라 두가지 경우로 나뉜다.
leaf node에만 오버플로우가 발생하는 경우
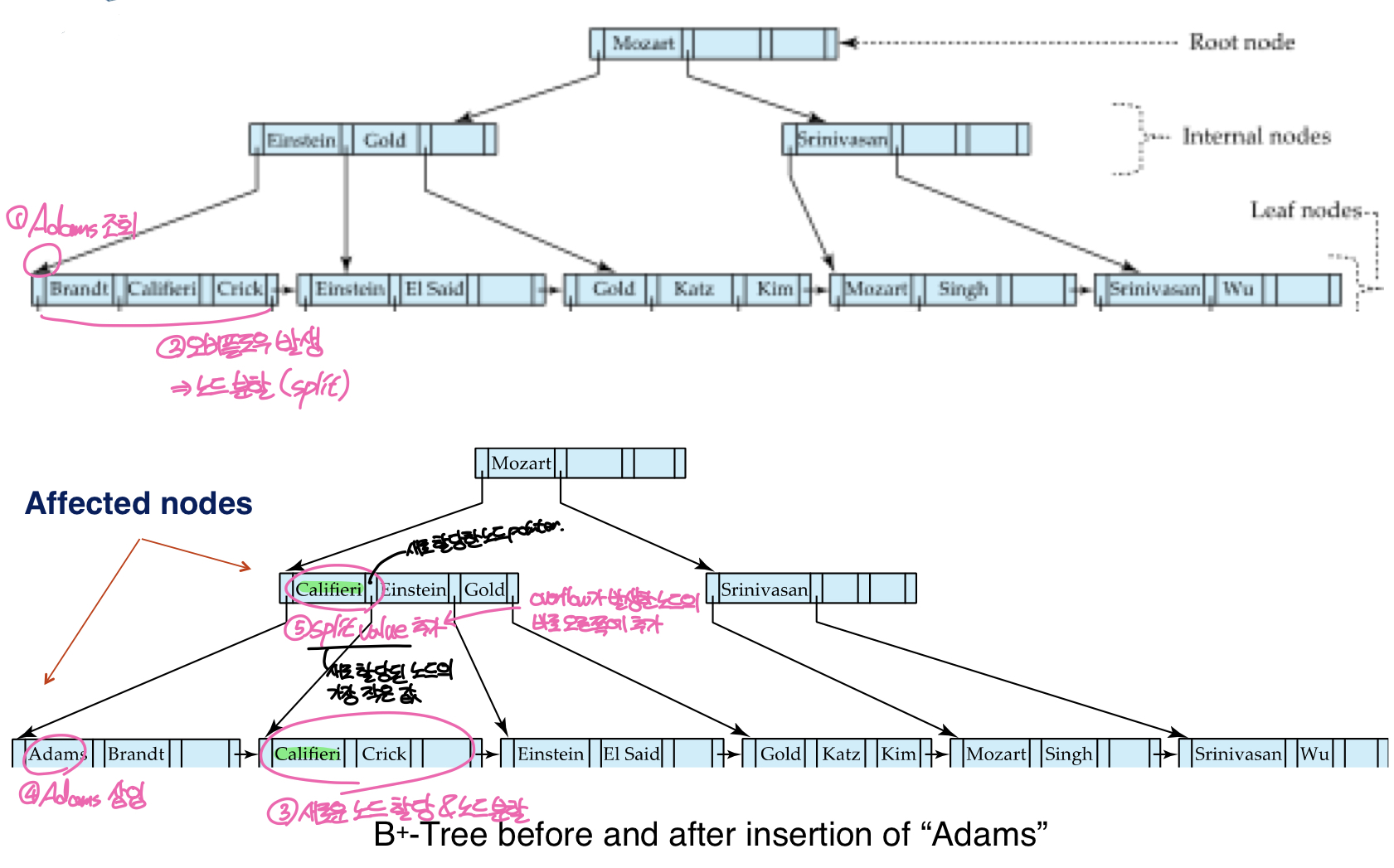
위의 예시에서 삽입 연산 시 leaf node에서 오버플로우가 발생한다. 이 경우 오른쪽에 새로운 leaf node를 하나 만들고 오버플로우가 발생한 노드에 저장된 엔트리의 절반을 새로 만든 노드로 이동한다. 이후 두 노드를 연결하고 부모노드에 split value를 추가하는데 부모노드에 빈 공간이 있으므로 별도의 처리과정 없이 split value를 추가하고 새로 만들어진 노드와 부모노드를 연결한다. 이때, 추가되는 split value는 새로 만들어진 노드의 가장 작은 값으로 설정하며, 부모노드에서의 위치는 오버플로우가 발생한 노드를 가리키는 포인터의 바로 오른쪽이다.
정리하자면 인덱스 엔트리 삽입 과정에서 leaf node에만 오버플로우가 발생하였다면
- leaf node 분할 : 새로운 노드 생성 후 기존 노드의 절반을 새로운 노드로 이동
- 부모 노드에 split value 추가 : 새로운 노드에서 가장 작은 값을 split value로, 부모노드에서 오버플로우가 발생한 노드를 가리키는 포인터의 바로 오른쪽에 추가
- 노드 연결 : 새로운 leaf node와 부모노드 및 기존 leaf node를 연결
의 순서로 B+트리를 업데이트 한다.
leaf node와 non-leaf node 모두 오버플로우가 발생하는 경우
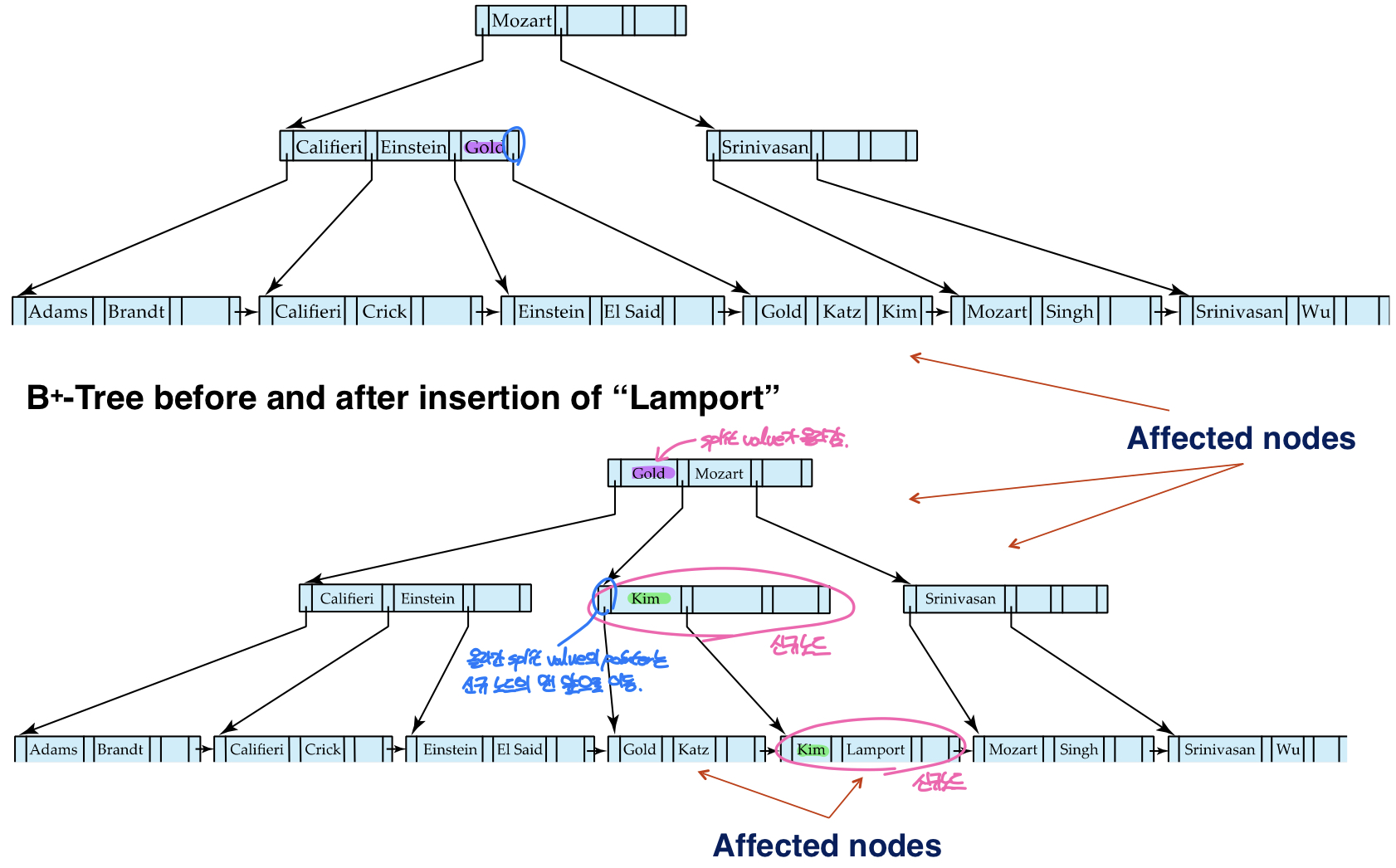
앞의 경우와 달리 이번 예시에서는 leaf node와 부모노드 모두 오버플로우가 발생한다. leaf node에서 오버플로우가 발생하여 위와 같은 과정을 통해 노드를 분할한 뒤 부모노드에 split value를 추가하려 하는데 부모노드에 빈 공간이 없어 오버플로우가 발생한다. 부모노드까지 노드가 분할되는데, 먼저 메모리에 기존 노드보다 키-포인터 쌍이 하나 더 많은 임시 노드를 생성하여 오버플로우가 발생한 non-leaf node를 복사하고 새로 추가된 leaf node의 split value와 포인터를 추가한다. 그 다음 임시노드의 앞쪽 절반은 오버플로우가 발생한 non-leaf node에 덮어쓰고 나머지 절반은 새로운 노드를 만들어 이동한다. 마지막으로 두 노드를 나누는 split value를 상위 노드로 올리는데, 이 때에도 split value의 위치는 오버플로우가 발생한 노드를 가리키는 포인터의 바로 오른쪽이다. 또한 상위 노드로 올라간 split value가 가리키고 있던 leaf node의 포인터는 새로 추가된 non-leaf node의 첫번째 위치로 이동한다.
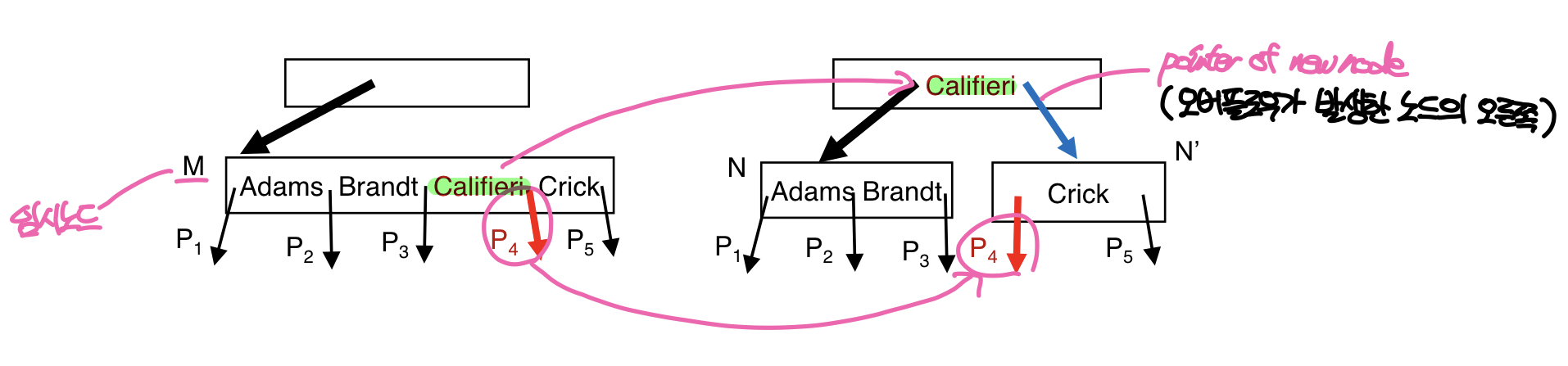
위의 그림과 같이 non-leaf node에서 오버플로우가 발생하면 임시노드 M에 모든 엔트리를 이동한 뒤 새로운 non-leaf node를 만들어 노드를 분할한다. 그림은 n = 4인 non-leaf node가 분할되는 상황을 보여주는데, 4개의 키(K1 ~ Kn)와 5개의 포인터(P1 ~ Pn+1)가 임시노드 M에 보관된다. 이후 노드 분할이 이루어지는데, P1, K1 ~ K2, P3까지의 값이 기존 노드에 복사되고, P4, K4, P5가 새로 만들어진 노드로 이동한다. 이때 중요한 것은 B+트리의 non-leaf node는 Kn-1과 Pn이 쌍을 이루는데, 노드를 분할하는 과정에서 K3은 상위 노드의 split value로 올라가기 때문에 K3과 P4가 찢어지게 된다.
Delete
B+트리에 엔트리를 삭제하는 경우 삽입과 반대로 B+트리의 공간조건에 의해 언더플로우가 발생하여 노드 분할 대신 두 노드를 병합하는 과정이 추가된다.
- B+트리에서 삭제할 엔트리를 찾아 삭제
- leaf node에서 언더플로우가 발생하면 인접 노드와 병합 후 부모노드 업데이트
- 부모노드에서도 언더플로우가 발생하면 인접 노드와 병합.
이때 만약 병합하려는 노드가 가득 차 병합이 불가능하다면 키를 재분배하여 B+트리를 업데이트 한다.
언더플로우가 발생하는 경우
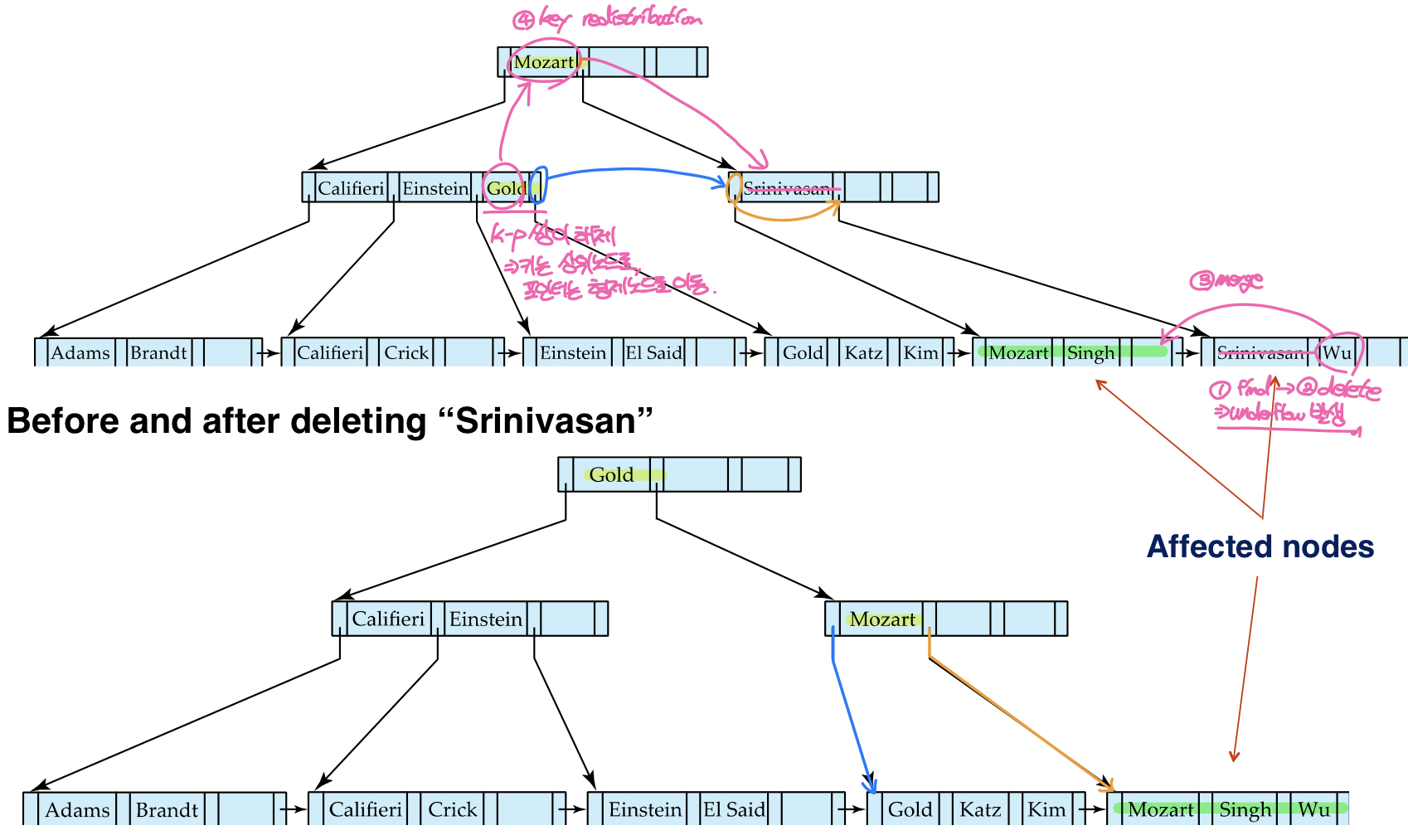
인덱스 엔트리 삭제 후 노드가 B+트리의 공간조건을 만족하지 못해 언더플로우가 발생하게 되면 인접한 두 노드의 병합이 발생한다. 노드의 병합은 분할과 반대로 인접한 두 노드 중 왼쪽 노드로 엔트리를 병합하고 오른쪽 노드를 삭제한다. 위의 예시에서 leaf node에서 언더플로우가 발생하여 인접한 노드와 병합되고, 부모노드의 split value가 제거되면서 부모노드에서도 언더플로우가 발생한다. 하지만 부모노드의 형제노드가 가득 차있기 때문에 병합에 실패하고 키 재분배가 일어난다.
병합에 실패하여 키 재분배가 일어나는 경우
언더플로우 발생 이후 노드를 병합할 때 병합하려는 노드에 공간이 충분하지 않으면 B+트리는 키를 재분배하여 상태를 유지한다. 위의 경우처럼 non-leaf node에서 키 재분배가 발생하는 경우 왼쪽 노드의 마지막 키-포인터 쌍을 해체하여 키는 상위노드로, 포인터는 언더플로우가 발생한 노드의 첫번째 위치로 이동하고, 상위노드에 있던 split value가 내려온다.
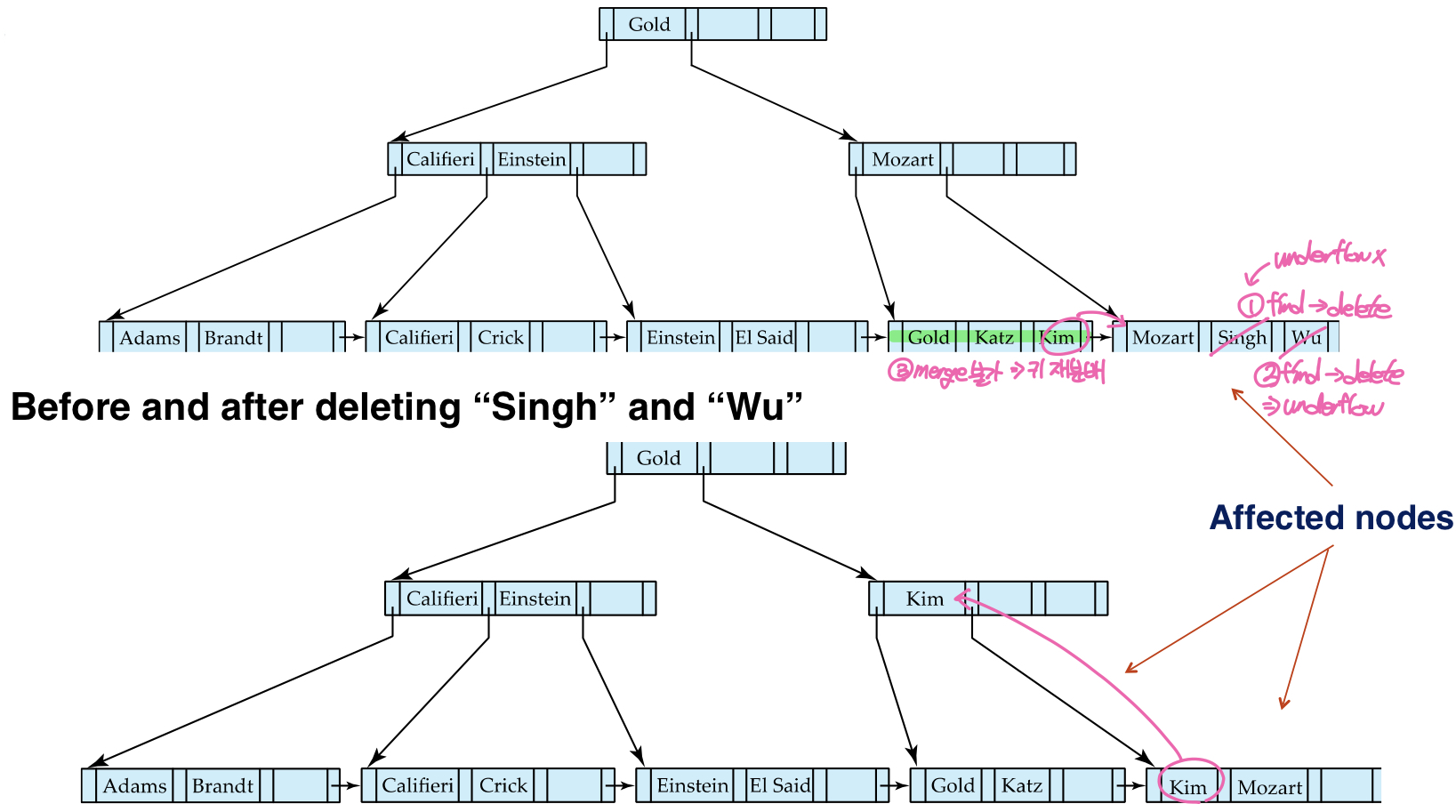
이번 예시에서는 leaf node에서 언더플로우가 발생했지만 병합이 불가능해 키를 재분배한다. 이때에는 non-leaf node와 달리 키-포인터 쌍 모두를 오른쪽 노드로 borrow하고, 빌려온 엔트리의 키값을 상위 노드의 split value로 교체한다.
트리의 높이가 낮아지는 경우
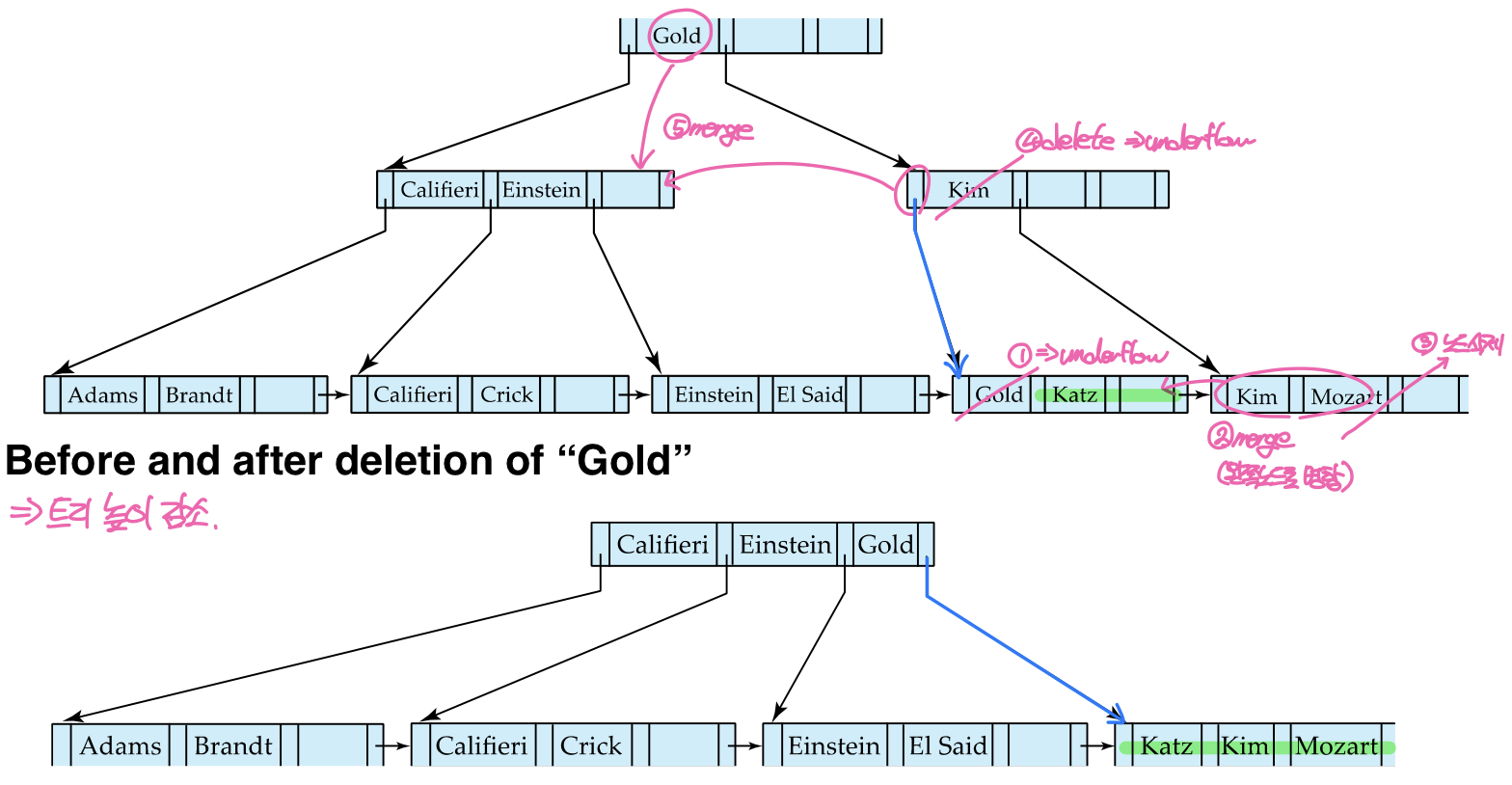
만약 노드 병합과 키 재분배 과정에서 루트 노드에 하나의 포인터만 남게 된다면 트리의 높이가 낮아진다. 그림에서, 왼쪽 leaf node에서 언더플로우가 발생하여 두 노드가 병합된다. 이때 병합은 항상 왼쪽노드로 이루어지기 때문에 오른쪽 노드의 값들이 왼쪽 노드로 이동하고 오른쪽 노드를 삭제한다. 이후 부모노드의 split value를 삭제하면서 부모노드에서도 언더플로우가 발생하고, 왼쪽 노드와 병합한다. 이 때에는 첫번째 예시와 반대로 병합 과정에서 상위노드의 키가 내려오고 언더플로우가 발생한 노드의 포인터가 왼쪽으로 이동하면서 해체된 키-포인터 쌍이 다시 결합된다. 병합 이후 루트노드에는 하나의 포인터만 존재하기 때문에 B+트리는 루트노드를 삭제하고 자식노드를 새로운 root로 설정한다.
참고 : 대부분의 트리구조에서 부모노드로 향하는 포인터를 저장하지 않는 이유
- 트리는 root에서 leaf로 가는 경로가 유일한 자료구조이기 때문에 leaf node를 탐색하면서 그 경로를 저장할 수 있다. 따라서 각 노드에 부모노드를 가리키는 포인터를 저장하는 것은 낭비이다.
- B+트리에서 root node는 보통 버퍼에 상주하고, leaf node를 탐색할 때 그 경로에 존재하는 노드들은 탐색과정에서 모두 버퍼에 올라오게 된다. 따라서 부모노드로의 포인터 없이도 leaf node를 탐색하는 것 만으로도 Update 작업에 필요한 대부분의 노드가 메모리에 올라오게 된다.
B+트리의 장점
- 삽입/삭제 연산시 자동으로 인덱스가 재구성되기 때문에 전체 파일을 한번에 재구성하지 않아도 된다.
- (트리높이 + 1)회의 I/O작업만으로 원하는 레코드를 조회할 수 있다.
- fanout의 정도가 크기 때문에 대용량 DB에서도 높이가 3 ~ 4정도로 낮다.
- K개의 search key값으로 트리를 구성하면 B+트리의 높이는 최대 ceil(logceil(n/2)(K))이다
- 일반적으로 노드는 디스크 블록과 크기가 같고(4Kb), 인덱스 엔트리(포인터-키 쌍)의 크기를 40byte로 보면 보통 n = 100인 B+트리가 만들어진다.
- 따라서 1,000,000개의 엔트리를 가진 100차 B+트리의 높이는 log50(1,000,000) = 4로 총 5번의 I/O만으로 원하는 레코드에 접근할 수 있다.
- 참고로 동일한 엔트리수의 이진트리의 높이는 20이다.
- Update(Insert, Delete)연산이 매우 효율적이다 - worst case에도 O(logceil(n/2)(K)) = O(h)만큼의 시간만 소요
- 일반적으로 루트노드는 버퍼에 상주하고, split과 merge가 발생하는 경우는 드물기 때문에, 대부분의 Insert/Delete연산은 leaf node에만 영향을 준다.
B+트리 파일 구조
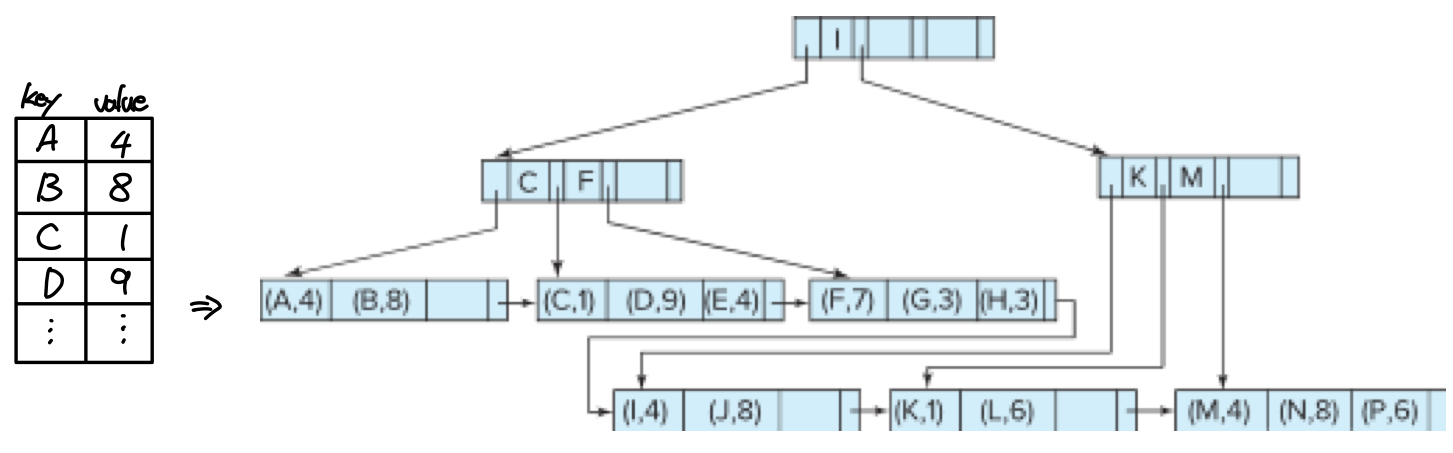
B+트리 인덱스는 데이터를 저장한 별도의 순차 파일이 존재하고 트리의 leaf node에 각 레코드를 가리키는 포인터를 저장한다. 이와 반대로 B+트리 파일에서는 별도의 데이터 파일이 없고, leaf node에 레코드 자체를 저장한다. B+트리 파일을 사용하면 삽입, 삭제시에 트리가 자동으로 업데이트 되기 때문에 데이터를 항상 clustered하게 유지할 수 있어 주요 DBMS에서 clustered index를 구현하는 방법으로 채택하고 있다.
B+트리 파일의 secondary index(non-clustered index)
일반적으로 순차파일 구조에서는 인덱스에 레코드를 가리키는 슬롯의 주소를 저장한다. 하지만 B+트리 파일구조에서는 secondary index가 레코드를 직접 가리키면 문제가 발생한다.
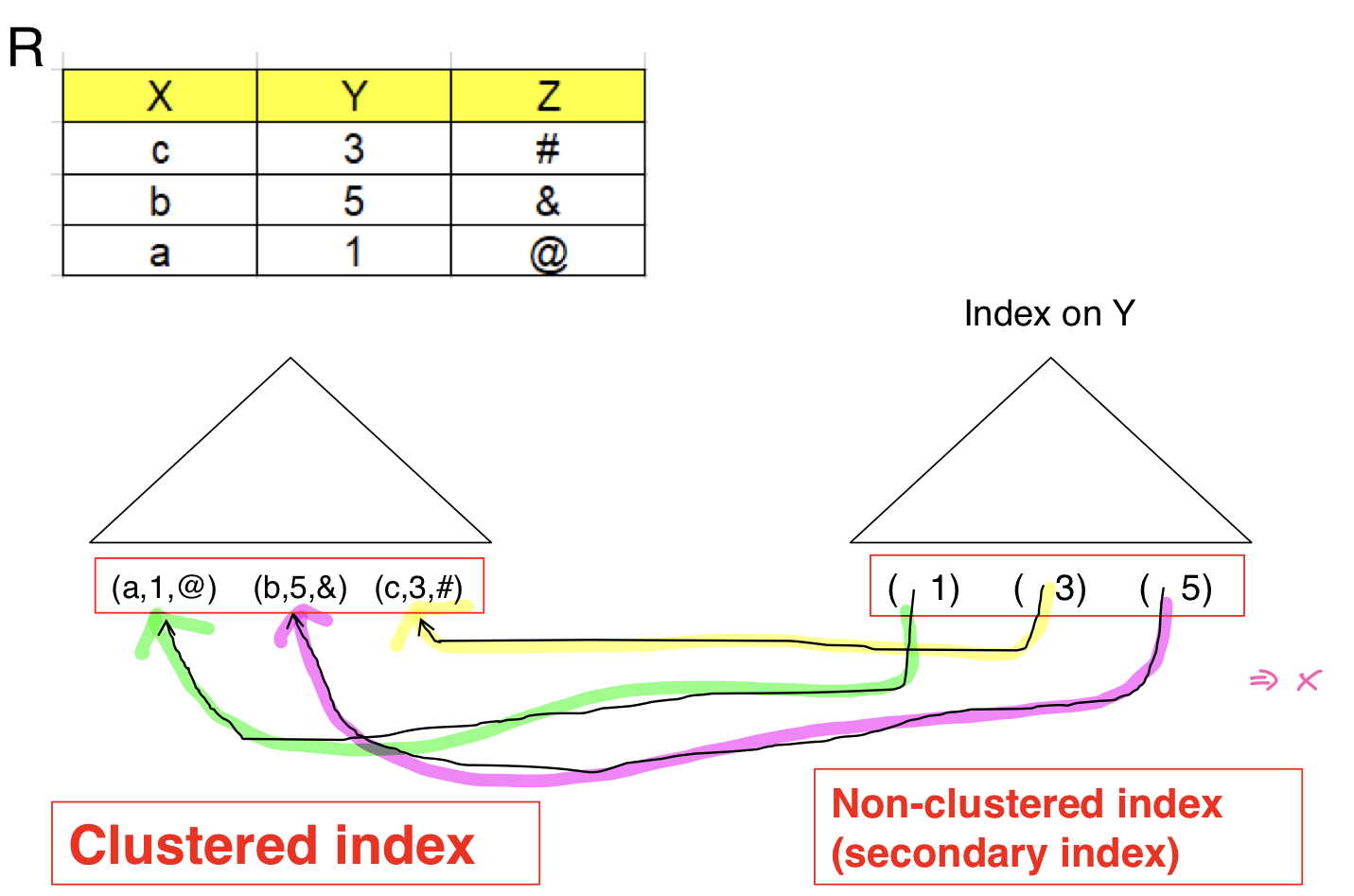
위의 그림과 같이 non-clustered index가 B+트리 파일에 저장된 레코드를 직접 가리킨다면 레코드가 삽입되거나 삭제될 때 clustered index의 노드가 분할되거나 병합되면 레코드의 위치가 변할 수 있고, 그때마다 영향을 받은 non-clustered index의 포인터가 갱신되어야 한다. 특히 노드 분할시 레코드가 새롭게 만들어진 노드로 이동하는 경우 자신을 참조하는 모든 포인터에게 새 노드의 주소를 통보해야 하기 때문에 연산이 매우 무거워진다.
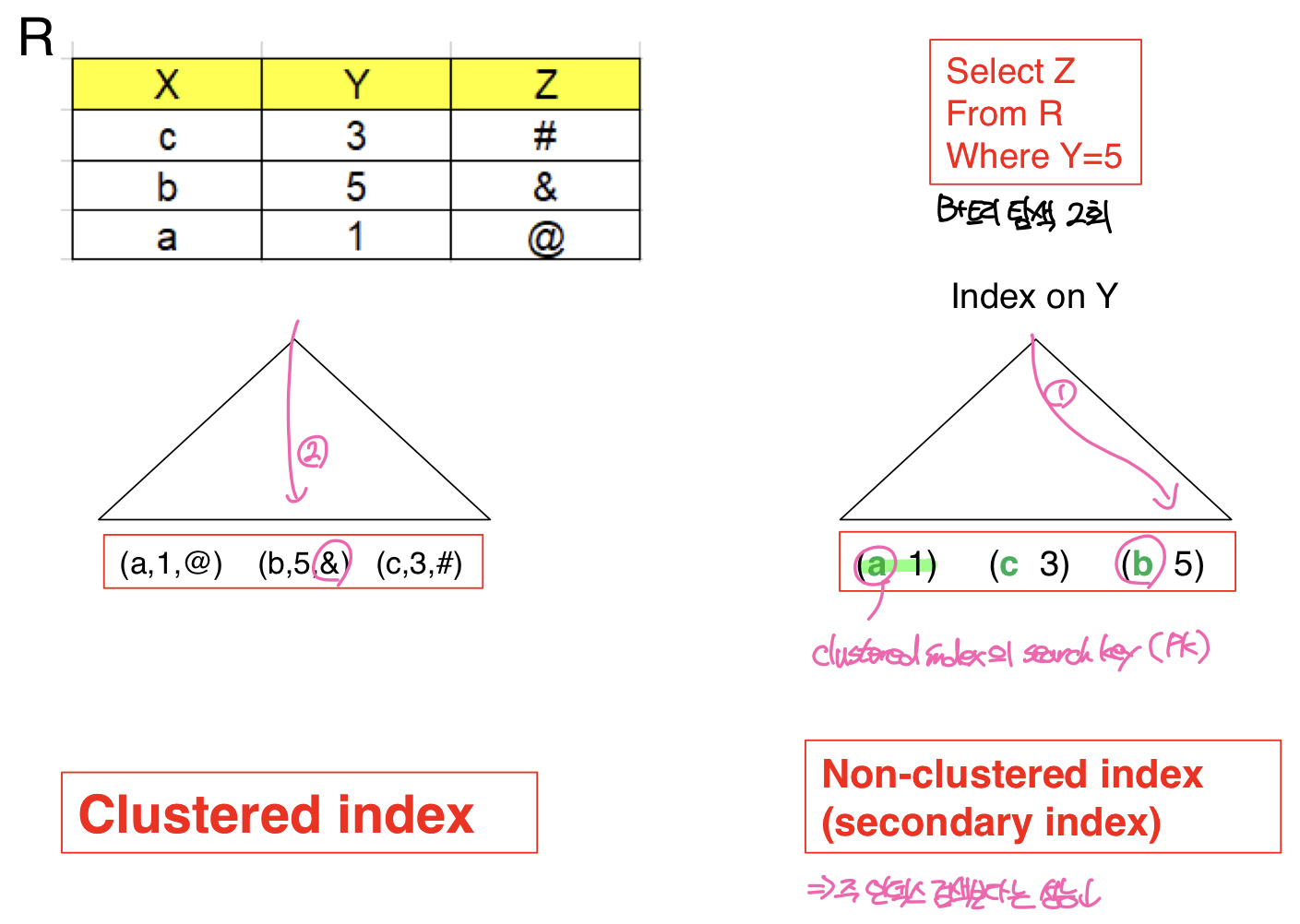
이를 해결하기 위해서 secondary index에서는 그림과 같이 레코드로 향하는 포인터가 아닌 B+트리의 search key를 사용한다. 이를 통해 레코드가 이동하는 문제는 해결할 수 있지만, 레코드를 찾기 위해서는 secondary index를 통해 clustered index의 search key를 찾고, 다시 clustered index를 탐색하여 레코드를 찾아야 하므로 추가적인 B+트리 탐색이 필요하기 때문에 clstered index를 사용하여 검색할 때보다는 성능이 떨어진다.
B트리 인덱스
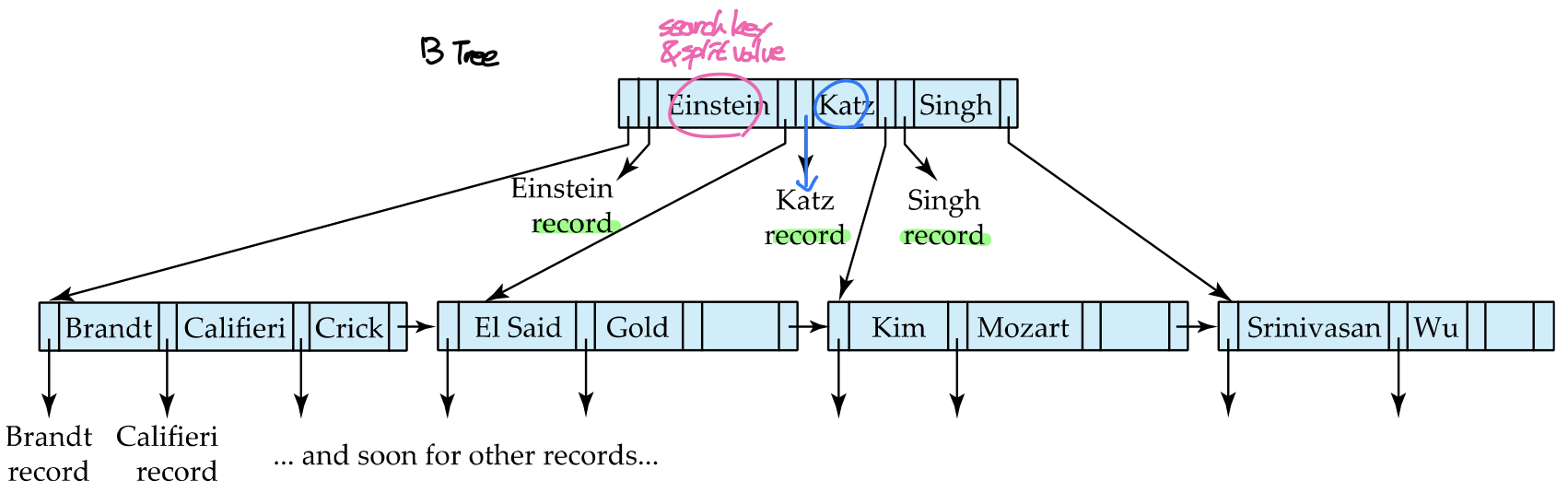
B트리 인덱스는 B+트리 인덱스의 원형으로, leaf node 뿐만 아니라 root node와 internal node에서도 레코드를 가리키는 포인터를 가지고있어서 트리에 키가 중복되어 저장되는 것을 막은 인덱스이다. B트리의 leaf node는 B+트리와 같고, non-leaf node에는 각 키값마다 하나의 포인터 Bn이 추가되었다. 이는 해당 키에 대응하는 레코드를 가리키는 포인터로, 여기에서 키값은 split value이면서 동시에 search key의 역할을 한다.
B트리 인덱스는 search key의 중복을 최소화했기 때문에 B+트리 인덱스에 비해 노드의 수가 적고, leaf node에 도달하기 전에 레코드를 찾을 수 있다는 장점이 있다. 하지만 leaf node에 도달하기 전에 레코드를 찾는 경우는 매우 드물고, non-leaf node의 크기가 증가하면서 fanout의 정도가 감소하여 결과적으로 트리의 높이가 높아질 수 있다는 단점이 있다. 또한 B+트리에 비해 삽입과 삭제 연산이 더 복잡하고 구현이 어렵다.
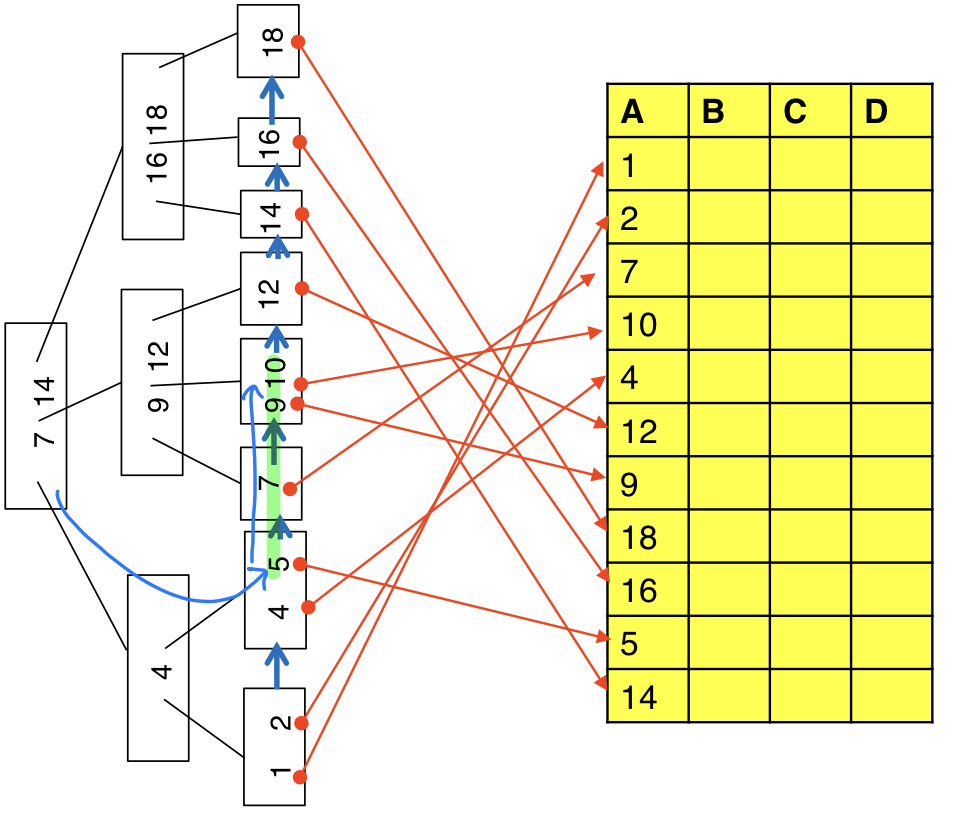
B트리의 가장 중요한 단점은 B+트리 인덱스에 비해 range query가 비효율적이라는 것이다. 위의 그림은 B+트리에서 select * from T where 5 <= A and A <= 10을 수행하는 과정으로, leaf node에서 5를 찾은 뒤 키 값이 10이 나올 때까지 순차적으로 형제노드를 탐색한다.
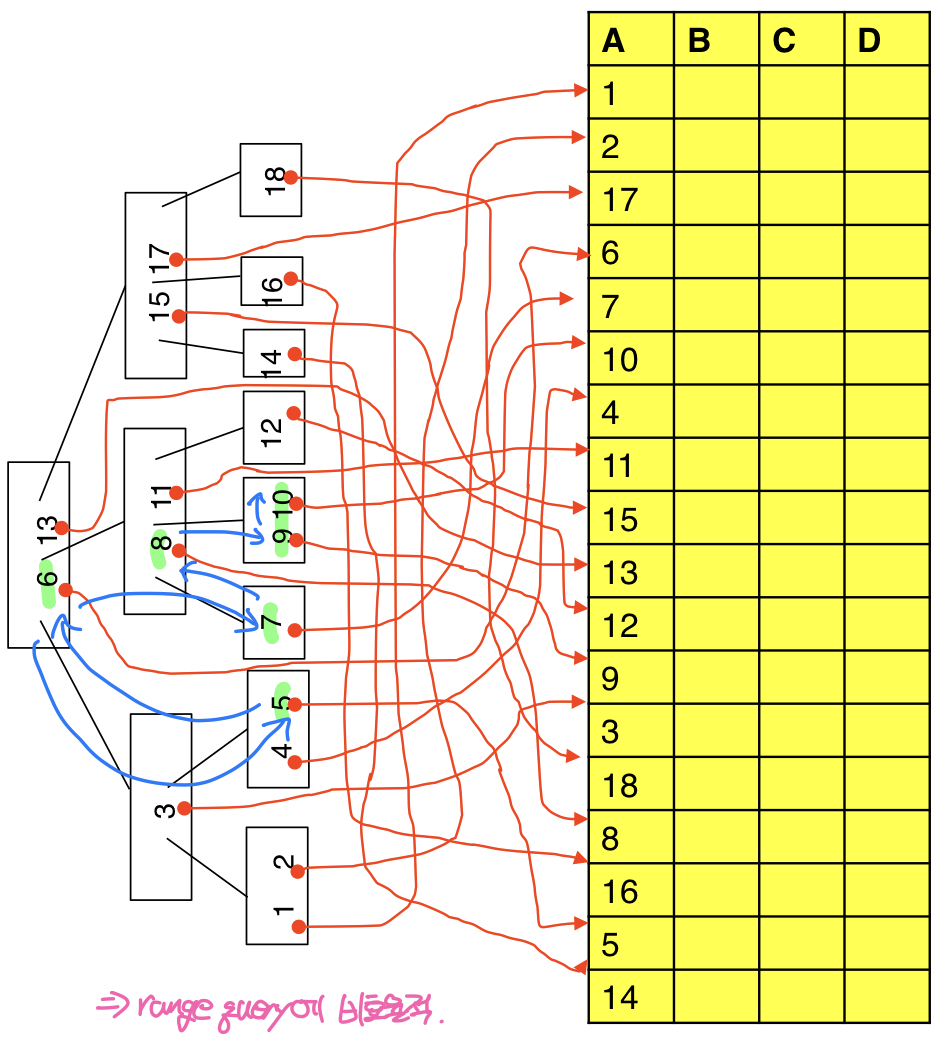
반면 B트리에서는 같은 쿼리에 대해 키값이 5인 노드를 찾은 뒤 다음 값을 찾기 위해 부모노드와 자식노드를 반복적으로 순회하는 것을 볼 수 있다. 이와 같은 이유로 B트리 인덱스는 장점보다 단점이 더 두드러지기 때문에 잘 사용하지 않는다.

B+트리는 다단계 구조를 가지고 있습니다. 루트 노드와 중간 노드는 오직 포인터만을 가지고 있고, watermelon game leaf 노드에는 실제 데이터(레코드)가 위치하게 됩니다. 이 다단계 구조는 효율적인 검색을 가능케 하며, 트리의 높이가 낮아짐으로써 빠른 검색 속도를 제공합니다.