인덱스
인덱스(Index)란 데이터베이스 테이블에 대한 검색 성능을 높여주는 자료구조이다.
인덱스는 대용량 데이터를 빠르게 조회하기 위해 사용하는 자료구조로, 테이블의 특정 column을 key로 하여 정렬하고 실제 레코드의 참조값을 저장한다. DBMS는 인덱스를 사용하여 레코드의 물리적 위치를 찾아 실제 데이터에 접근한다.
인덱스 파일은 search key와 실제 레코드를 참조하는 pointer로 구성된 index entry(index record)들의 집합으로, search key는 파일(DB)에서 레코드를 찾기 위한 기준이 되는 값들을 의미한다. 이때, search key는 단일 값이 될 수도 있고, 여러 값을 하나로 묶어 사용하는 합성키(Composite search key)일 수도 있다. 만약 search key가 합성키일 경우 키값은 사전적 순서로 정렬된다. 인덱스 파일은 일반적으로 원본 데이터 파일에 비해 매우 적은 용량을 차지한다.
인덱스는 크게 search key를 정렬하여 관리하는 (Ordered) indices와 search key를 해시 함수에 의해 파일에 균일하게 분산시켜 관리하는 Hash indices로 구분한다.
인덱스 평가 지표
- Access Type : 인덱스를 사용할 때 효율적인 접근 방식. 쿼리의 종류에 따라 인덱스를 사용하는 것이 효과가 없을 수도 있다.
- specified value : 특정 값을 조회. ex) select ~ from ~ where name = "A"
- range of values : 값의 범위를 통해 조회. ex) select ~ from ~ where name > "A" and name < "Z"
- 범위 쿼리는 B+트리 인덱스에서는 지원하지만 Hash 인덱스에서는 지원하지 않는다.
- Access time : 인덱스를 통해 데이터에 접근하는데 걸리는 시간
- Insert time, Delete time : 인덱스 자체를 관리하는데 소모되는 시간(index maintenance)
- 레코드를 insert하거나 delete하면 인덱스 또한 insert, delete해야 한다.
- Space overhead : 인덱스를 저장하는 공간
Ordered Indices
Ordered Index에서는 인덱스 엔트리들이 search key를 기준으로 정렬되어있다. ordered index는 다시 집중 인덱스(Clustering index)와 비 집중 인덱스(Nonclustering index)로 나눌 수 있다.
집중 인덱스, 비 집중 인덱스
집중 인덱스는 인덱스의 정렬순서가 레코드의 정렬 순서와 같은 인덱스로, 인덱스와 레코드의 순서가 같기 때문에 I/ O작업을 최소화 할 수 있다는 장점이 있다. 또한 한 column을 기준으로 테이블을 정렬하면서 동시에 다른 column으로 정렬할 수 없기 때문에 테이블당 집중 인덱스는 최대 하나밖에 만들 수 없다. 집중 인덱스는 다른 말로 primary index라고 부르기도 하고, 집중 인덱스를 사용하는 파일(테이블)들을 index-sequential files라고 한다. 관례적으로 집중 인덱스는 테이블의 PK를 사용하여 만든다.
반면 비 집중 인덱스는 집중 인덱스와 달리 인덱스의 정렬 순서가 테이블의 정렬순서와 다를 인덱스로, secondary index라고 부르기도 한다. 비 집중 인덱스는 인덱스의 정렬 순서가 테이블과 같을 필요가 없으므로 한 테이블에 여러개의 비 집중 인덱스가 있을 수 있고, 관례적으로 PK가 아닌 다른 column을 사용하여 만든다.
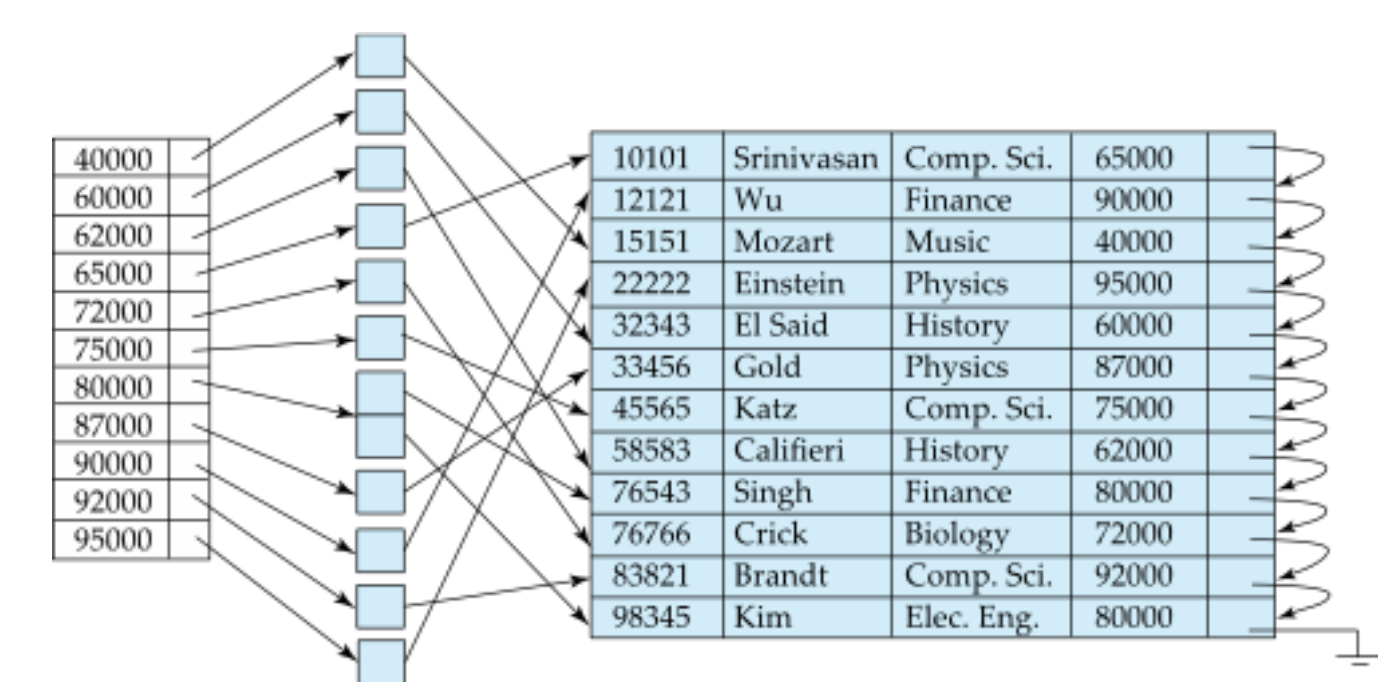
위의 예시에서 각 인덱스는 특정한 search key에 해당하는 실제 레코드의 주소를 담은 bucket이라는 공간을 참조한다. 하나의 인덱스 엔트리에 복수개의 레코드가 연결된 경우 bucket의 길이 또한 레코드의 개수에 맞춰진다. 따라서 search key마다 bucket의 길이가 다를 수 있기 때문에 실제 DB에서는 잘 사용하지 않는다. 또한 비 집중 인덱스는 인덱스의 순서대로 레코드가 정렬되지 않으므로, 인덱스 파일에는 모든 search key가 존재해야 한다.(dense)
일반적으로 인덱스를 사용할 때 데이터의 조회성능이 높아지지만, 만약 데이터를 순차적으로 스캔하는 작업이 발생한다면 집중 인덱스를 사용할 때는 인덱스와 레코드의 순서가 일치하기 때문에 효율적으로 동작하지만, 비 집중 인덱스를 사용하는 경우 최악의 경우 찾는 레코드가 서로 다른 디스크 블록에 흩어져있어 레코드당 1회의 I/O작업이 수반되어 조회성능이 더 나빠질 수도 있다.
인덱스 파일 구조
Dense Index Files
모든 search key에 대해 인덱스 엔트리가 존재하는 구조로, 아래와 같은 예시들이 있다.
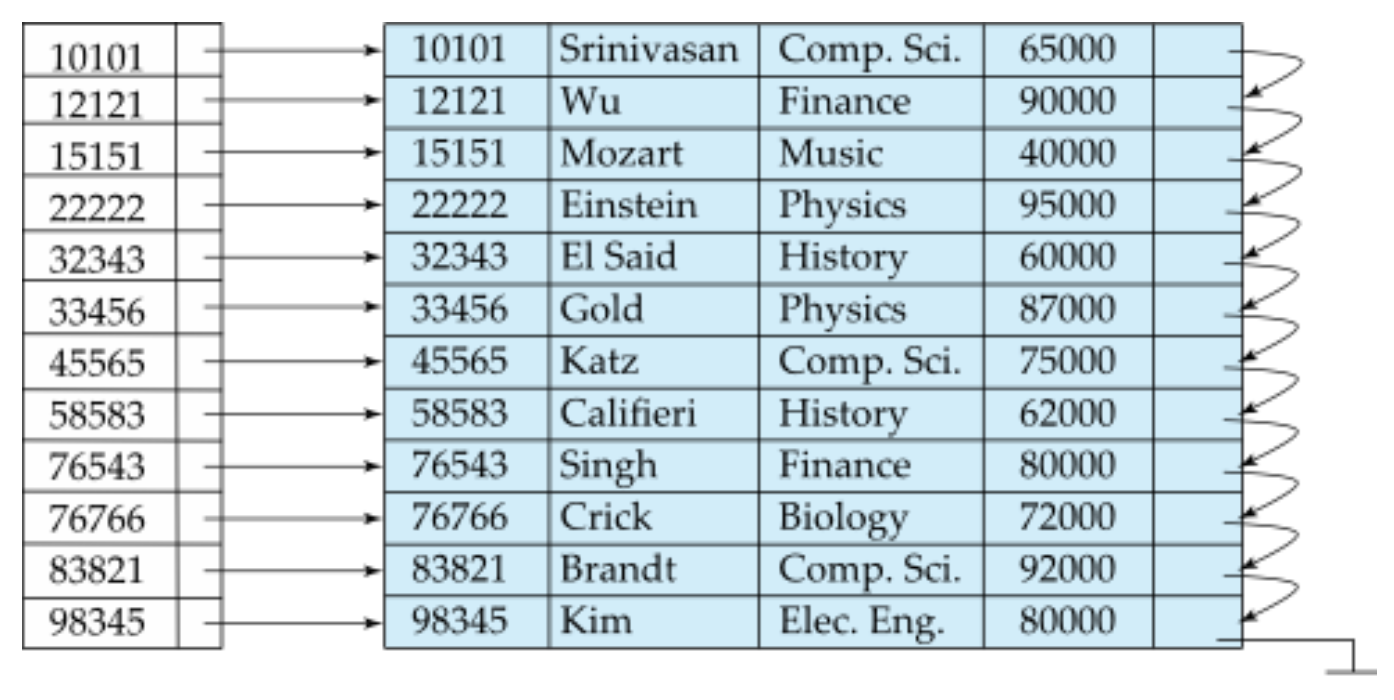
위의 경우 PK를 기준으로 집중 인덱스를 만든 것으로, 모든 레코드의 PK가 인덱스 파일에 포함되어있으므로 Dense Index File로 볼 수 있다.
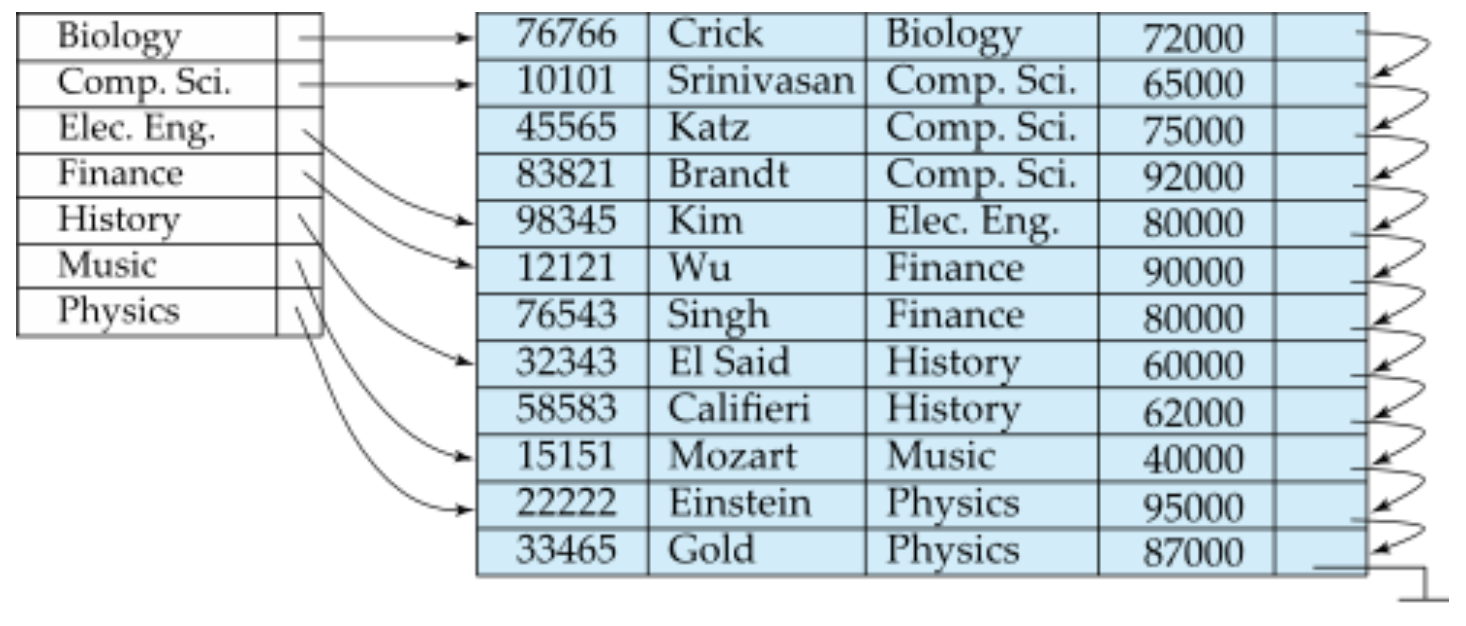
이 경우에는 PK가 아닌 column을 기준으로 집중 인덱스를 만들었다. 오른쪽 테이블에서 index로 설정한 column은 unique하지 않기 때문에 인덱스가 모든 레코드를 가리키지 않는다. 즉, 여기서는 하나의 인덱스 엔트리에 복수개의 레코드가 연결되어있어 인덱스 엔트리의 수와 레코드의 수가 일치하지 않지만, 모든 search key가 인덱스에 존재하기 때문에 이 경우 역시 dense index file로 볼 수 있다. 참고로 위의 예시는 집중 인덱스이므로 인덱스와 레코드의 정렬 순서가 일치하기 때문에 인덱스가 테이블의 첫번째 레코드만 가리킴으로써 bucket을 사용하지 않고 구현할 수 있다.
Sparse Index Files
인덱스 파일이 전체 search key중 일부에 대한 인덱스 엔트리만을 관리하는 구조로, 인덱스 엔트리에 없는 레코드를 찾는 경우 다른 레코드에 접근한 뒤 원하는 레코드를 찾아야 하므로 검색성능은 조금 떨어지지만, dense index File구조에 비해 인덱스 엔트리의 수가 적기 때문에 공간효율이 좋고 인덱스 관리에 들어가는 비용이 적다는 장점이 있다.
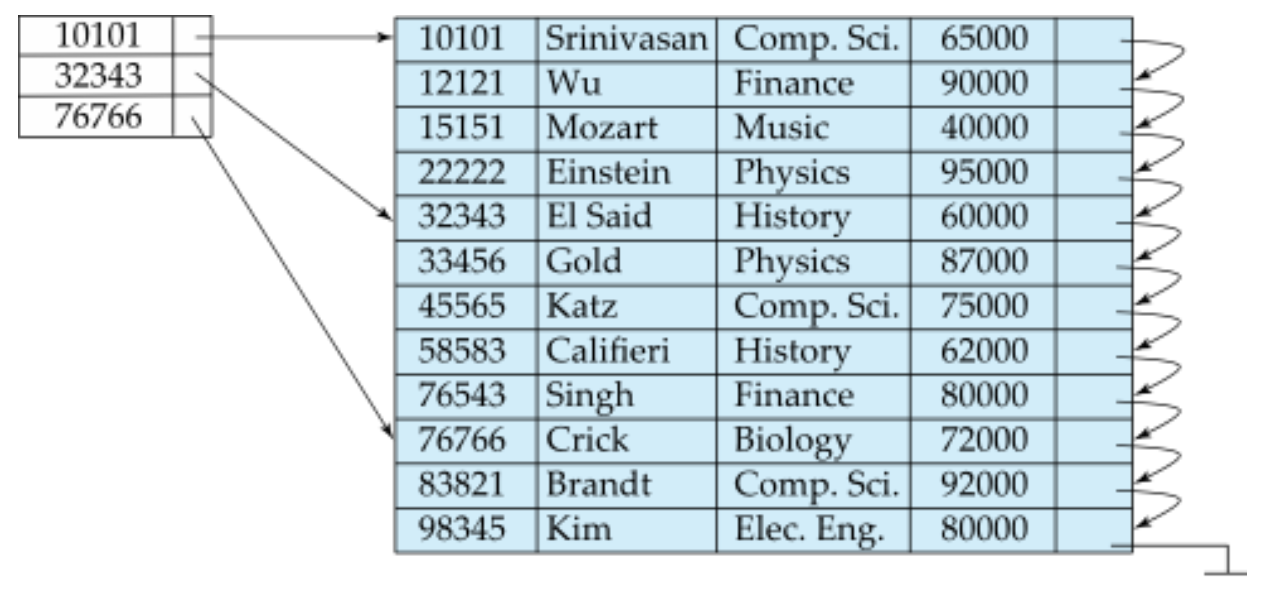
sparse Index File구조에서 중요한 점은, 인덱스에 모든 search key가 포함되어있지 않기 때문에 반드시 집중 인덱스로 만들어야 인덱스 엔트리에 없는 레코드를 찾을 수 있다(단일 레벨 인덱스). 인덱스가 없는 레코드의 경우 이전 인덱스의 레코드에 먼저 접근한 뒤 테이블을 순차적으로 탐색하여 원하는 레코드에 도달해야 하는데, 만약 레코드의 순서가 인덱스의 순서와 다를 경우 이 작업이 불가능하므로 반드시 sparse index file은 집중 인덱스로만 만들어야 한다.
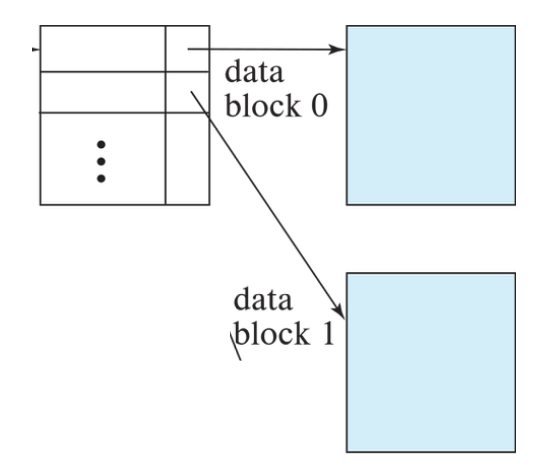
DB에서 레코드를 찾을 때에는 하나의 디스크 블록을 통채로 메모리에 올리기 때문에 sparse index구조의 효율성을 높이기 위해 하나의 인덱스 엔트리가 하나의 디스크 블록을 가리키도록 구현할 수 있다. 이 경우 인덱스 엔트리의 search key값은 각 블록에서 가장 작은 레코드의 search key값이 된다.
또한 멀티 레벨 인덱스 구조에서는 dense index들의 top level에서 비 집중 인덱스를 sparse index구조로 저장할 수 있다. 정리하자면 sparse index구조에서 실제 데이터 블록과 이어지는 인덱스는 반드시 집중 인덱스여야 하지만, 상위 레벨의 인덱스는 비 집중 인덱스도 가능하다.
Multilevel index
인덱스를 통해 데이터베이스의 조회성능이 향상되기는 하지만, 인덱스 자체로도 메모리공간을 차지하기 때문에 인덱스를 많이 만든다고 항상 좋은 것은 아니다. 또한 테이블에 레코드가 너무 많은 경우 인덱스 파일이 메모리에 다 올라오지 못할 수 있다. 이에 대한 해결책으로 인덱스의 단계를 나누어 디스크에 보관하는 Multilevel index를 사용할 수 있다.
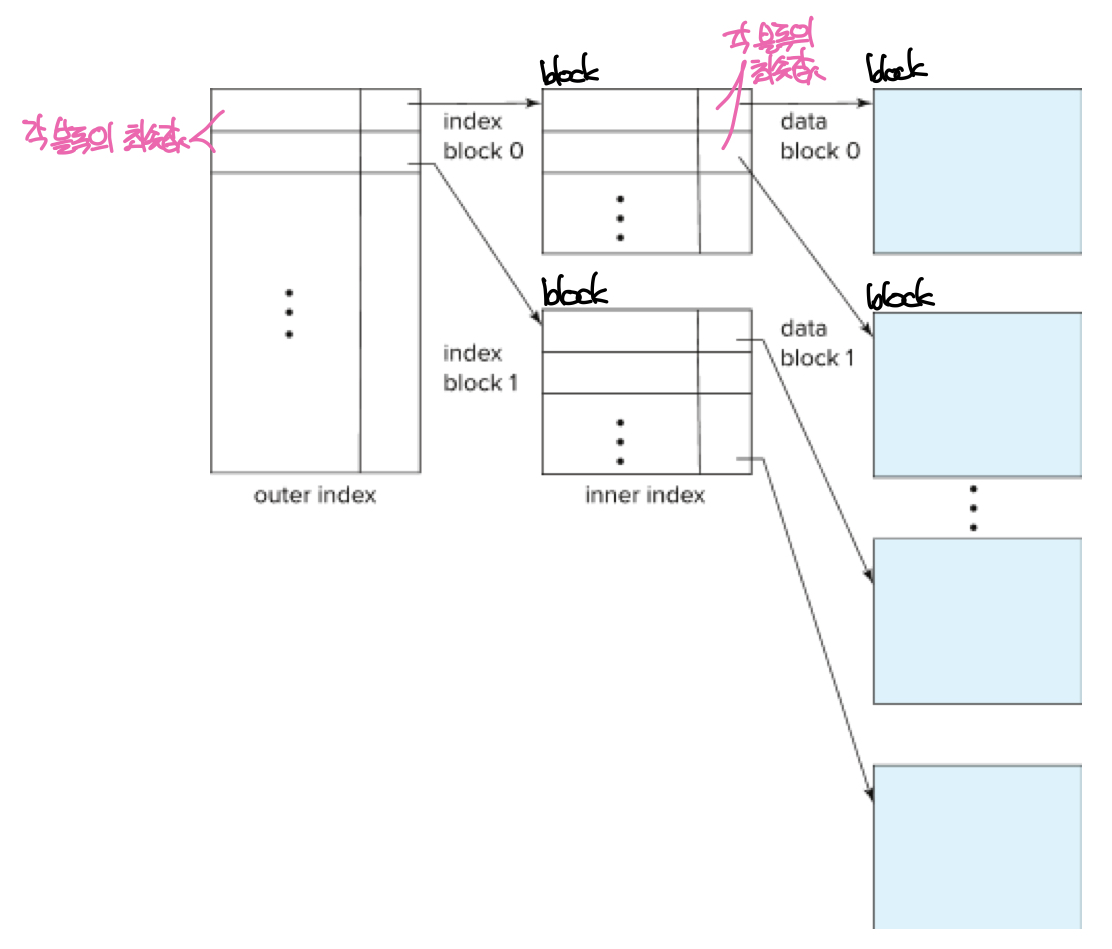
Multilevel index에서 실제 인덱스는 순차파일의 형태로 디스크에 저장되고, 이 인덱스 파일에 대한 sparse index를 만들어 메모리에서 관리한다. 이때 디스크에 있는 인덱스를 inner index, 메모리에서 인덱스들을 관리하는 인덱스를 outer index라고 한다. 만약 outer index의 엔트리가 너무 많아져 메모리에 다 올리지 못하는 경우 새로운 레벨을 만들어 동일한 구조로 sparse index를 만든다. 그렇기 때문에 Multilevel index는 주로 트리의 형태로 구현한다.
인덱스 업데이트
인덱스로 관리하는 파일에 레코드가 삽입되거나 삭제되면 해당 인덱스 또한 업데이트 되어야 한다. 이때 인덱스를 업데이트 하는 방식은 인덱스 파일의 구조에 따라 다르다.
레코드 삽입
- Dense : 새로 삽입되는 레코드의 search key값이 인덱스 파일에 없으면 새로운 인덱스 엔트리를 적절한 위치에 추가하여 레코드에 할당함.
- Sparse : 레코드가 삽입될 때 새로운 디스크 블록이 만들어진다면 인덱스 엔트리에 새로운 블록의 가장 작은 키값을 search key로 저장.
레코드 삭제
- Dense : 해당 레코드를 가리키고 있는 인덱스를 삭제
- Sparse : 인덱스 엔트리가 가리키고 있는 레코드가 삭제되는 경우, 다음 레코드의 키값으로 인덱스 엔트리를 업데이트. 만약 다음 레코드의 키값이 이미 인덱스 파일에 있는 경우, 기존 인덱스 엔트리만 삭제
인덱스 생성
대부분의 DBMS에서는 PK에 대한 인덱스를 자동으로 생성하여 관리한다. 왜냐하면 DBMS는 DB의 무결성을 유지하기 위해 PK의 고유 식별성을 유지해야 하고, 고유 식별성을 유지하려면 자신과 같은 PK가 존재하는지 확인하기 위해 테이블 전체를 탐색해야 하는데, PK를 인덱스로 관리하면 테이블 전체를 확인하지 않고도 B+트리에서 자신을 찾는 것 만으로 자신과 같은 PK가 존재하는지 빠르게 확인할 수 있기 때문이다.
또한 몇몇 DBMS에서는 FK에 대해서도 인덱스를 자동으로 생성하기도 한다. FK는 주로 JOIN작업에 쓰이는데 FK의 대상이 되는 테이블에 FK를 인덱스로 관리하면 두 테이블을 JOIN할 때 FK를 통해 레코드를 빠르게 찾을 수 있기 때문에 성능이 향상되기 떄문이다.
따라서 인덱스를 생성하여 사용하는 것은 레코드의 조회성능을 향상시키지만 인덱스를 관리하는 비용이 추가로 발생하기 때문에 불필요하게 많은 곳에 인덱스를 생성하는 것은 좋지 않다.
아래는 인덱스에 관련된 sql구문이다.
-- 인덱스 생성 구문
create index <index-name> on <relation-name> (<attribute-list>)
-- search key를 candidate key로 선언
create unique index ...
-- 인덱스 삭제
drop index <index-name>이중 unique 키워드를 사용하여 인덱스를 생성하면, search key의 고유 식별성을 보장하기 때문에 조회 성능이 향상된다.
