다중키 인덱스
select ID
from instructor
where dept_name = "Finance" and salary = 80000위와 같은 쿼리문이 DBMS에 주어졌을 때 인덱스를 사용하여 데이터에 접근하려면 다음과 같은 방법들을 생각 해 볼 수 있다.
- dept_name을 키로 가지는 인덱스에서 값이 "Finance"인 데이터를 찾은 뒤 salary가 80000인 레코드를 찾음
- salary를 키로 가지는 인덱스에서 값이 80000인 데이터를 찾은 뒤 dept_name이 "Finance"인 레코드를 찾음
- dept_name을 키로 가지는 인덱스에서 값이 "Finance"인 포인터를 찾고 salary를 키로 가지는 인덱스에서 값이 80000인 포인터를 찾은 뒤, 두 포인터 집합의 교집합을 통해 레코드를 찾음
- (dept_name, salary)를 키로 가지는 합성키 인덱스를 사용
합성키 인덱스
합성키 인덱스란 하나 이상의 attribute들로 search key를 구성한 인덱스로, 키값 사이의 순서는 사전적 순서를 따른다.
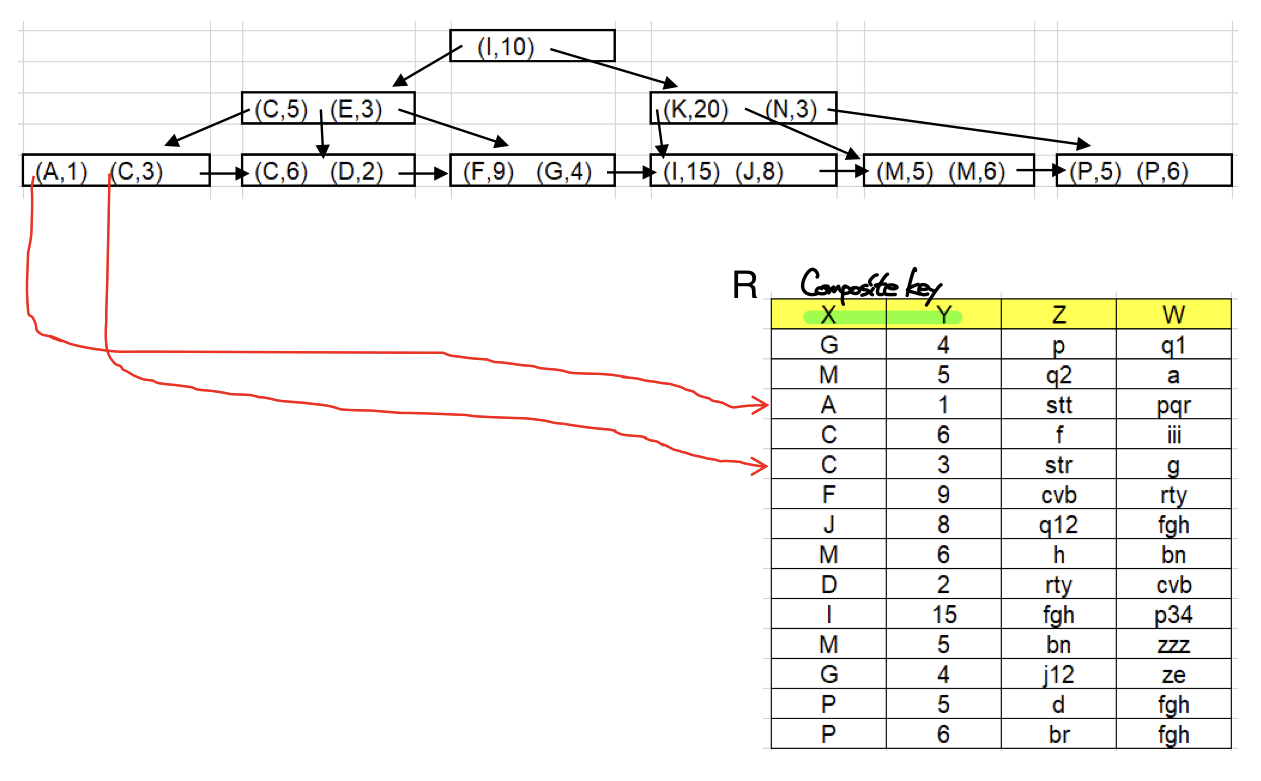
합성키 인덱스를 사용 할 때 주의할 점은 일부 쿼리문은 합성키 인덱스에 적합하지 않을 수 있다는 점이다. 위의 그림에서 다음과 같은 쿼리문들을 작성할 수 있다.
select * from T
where X = "M" and Y = 6
-- result : (M, 6)이 경우 키값과 정확히 일치하는 search key를 가진 레코드를 찾기 때문에 합성키 인덱스에 적합하다. 하지만 and를 기준으로 range query가 포함되는 경우 상황이 달라진다.
select * from T
where X = "M" and Y < 6
-- result : (M,5), (M,6)이 경우는 두번째 키값이 range query로 들어간다. 하지만 합성키 인덱스는 첫번째 키값에 대해 우선적으로 정렬하기 때문에 결과로 나오는 두 노드는 서로 인접해있으므로 합성키 인덱스를 사용하는 것이 적합하다.
select * from T
where X < "M" and Y = 6
-- result : (C,6), (M,6)하지만 첫번째 키값이 range query로 들어가는 경우 인접하지 않은 노드를 찾아야 하기 때문에 B+트리의 탐색이 여러번 일어나게 된다. 이 경우 합성키 인덱스를 사용하는 것이 오히려 성능을 저하시킬 수 있다.
Covering indices
Covering index는 합성키 인덱스와 비슷하게 leaf node에 여러개의 value를 저장하지만, 이들을 합성키로 구성하지 않는다. 대신 하나의 키값과 레코드 포인터에 더해 일부 attribute를 추가하여 저장함으로써 실제 레코드에 접근하지 않고도 원하는 값을 찾을 수 있게 만든 인덱스이다.
합성키 인덱스를 사용해도 동일한 결과를 얻을 수 있지만 Covering index를 사용하는 이유는 search key의 크기를 줄이기 때문에 더 큰 fanout을 허용하여 결과적으로 트리의 높이를 줄일 수 있기 때문이다.
Bitmap indices
비트맵 인덱스는 다중키 인덱스의 특수한 형태로 인덱스로 사용하는 키값이 비교적 다양하지 않은 경우 사용할 수 있는 방법이다.
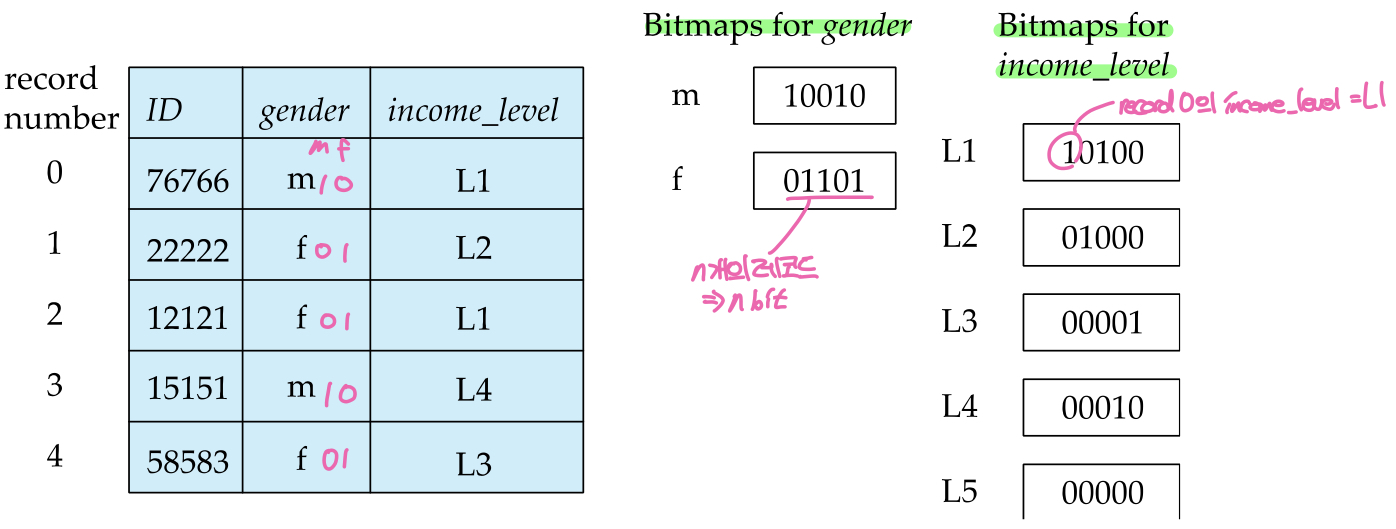
위의 예시 테이블에는 총 5개의 인덱스가 있기 때문에 비트맵의 크기는 5bit이다. 각 bitmap은 인덱스로 사용하는 column에 올 수 있는 값을 이름으로 가지고, 해당하는 값이 있는 레코드의 위치를 1로 표시한다. 즉, gender column의 인덱스는 m, f 두개의 비트맵이 존재하고, 0번 레코드의 gender 값이 m 이므로 m bitmap의 첫번째 비트가 1이다.
비트맵 인덱스를 사용하면 다중 키값에 대한 조회가 비트연산으로 처리되기 때문에 매우 빠르다는 장점이 있다. 예를 들어 select * from T whrer gender = "m" and income_level = "L1" 이라는 쿼리를 처리할 때 이름이 m인 비트맵(10010)과 L1인 비트맵(10100)에 대해 AND연산을 처리하면 결과 레코드의 위치를 얻게 된다.(10000 -> 0번 레코드)
비트맵 인덱스를 사용하여 성능을 향상하기 위해서는 레코드를 번호로 빨리 찾을 수 있는 파일구조여야 한다. 비트맵의 각 자리수는 해당 레코드의 위치를 표시하기 때문에 이 순서대로 레코드가 저장되어있어야 비트맵 인덱스를 통해 빠르게 레코드에 접근 할 수 있다.
또한 비트맵 인덱스는 쿼리가 들어오면 AND, OR, NOT등의 비트연산을 통해 레코드의 위치를 찾는데, 이때 연산의 결과로 나온 비트맵에 포함된 1의 수가 적을수록 성능이 향상된다. 따라서 다중조건으로 값을 찾는 경우에는 AND연산을 통해 비트맵의 1의 수를 줄일 수 있어 효율적이지만, 단일조건으로 레코드를 찾는 경우나 OR연산을 통해 값을 찾는 경우에는 오히려 1의 개수가 증가하여 효율이 떨어질 수 있다.
그리고 비트맵 인덱스의 또다른 장점은 count연산이 레코드에 접근하지 않고 단순히 비트맵에 포함된 1의 개수를 세기만 하면 되기 때문에 매우 빠르게 처리될 수 있다는 것이다.
일반적으로 비트맵 인덱스의 크기는 테이블의 크기에 비해 매우 작다. 예를 들어 레코드 1건이 100byte를 차지하면 비트맵 인덱스가 차지하는 비율은 (비트맵의 크기 / 테이블의 크기)로 계산할 수 있고, 비트맵의 크기는 레코드의 수와 같기 때문에 (레코드 수 / (레코드 크기 * 레코드 수)) = 1 / 레코드 크기 = 1/100byte - 1/800bit이므로 단일 컬럼에 대한 비트맵의 크기는 전체 테이블의 1/800수준에 그친다.
하지만 비트맵 인덱스는 유지보수의 관점에서 레코드를 삽입/삭제할 때마다 모든 비트맵을 변경해야하고, null값을 관리하는 비트맵이 추가로 필요하다는 단점이 있다. 이 중 삭제연산에 대해서는 existence bitmap이라는 특수한 비트맵을 두어 관리가 가능하다. existence bitmap은 인덱스를 생성할 때 모든 비트를 1로 초기화하여 값이 있음을 나타내고, 레코드가 삭제되면 해당 비트를 0으로 바꾸어 값이 없음을 표시한다. 그리고 조회결과를 추출할 때 여러 비트맵과 함께 AND연산을 통해 결과를 계산한다.
