데이터 베이스, 파일, 레코드, 필드
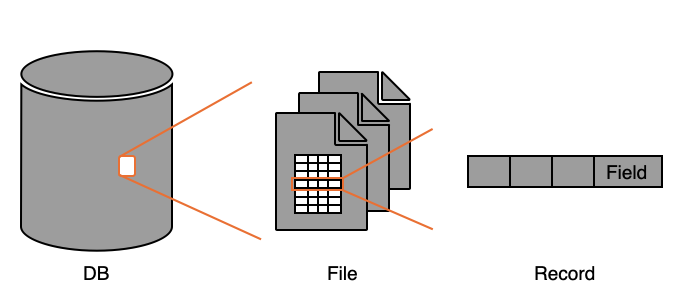
데이터베이스는 저장소에 저장된 File의 모음이고, 파일은 일련의 Record들의 집합이며, Record는 각 Filed의 집합으로 이루어진다.
하지만 데이터베이스의 물리적인 최소단위는 Block이기 때문에, Block과 Record의 관계를 정의하기 위해 Blocking Factor라는 지표가 존재한다.
- Blocing Factor : 한 블록 안에 저장되는 레코드의 수.
- Blocing Factor = 블록크기 / 레코드의 크기
고정길이 레코드
각 파일에 저장되는 레코드의 크기가 모두 같은 구조로 i번째 레코드의 시작주소는 n * (i-1)번째 바이트이다.(n : 레코드의 크기)
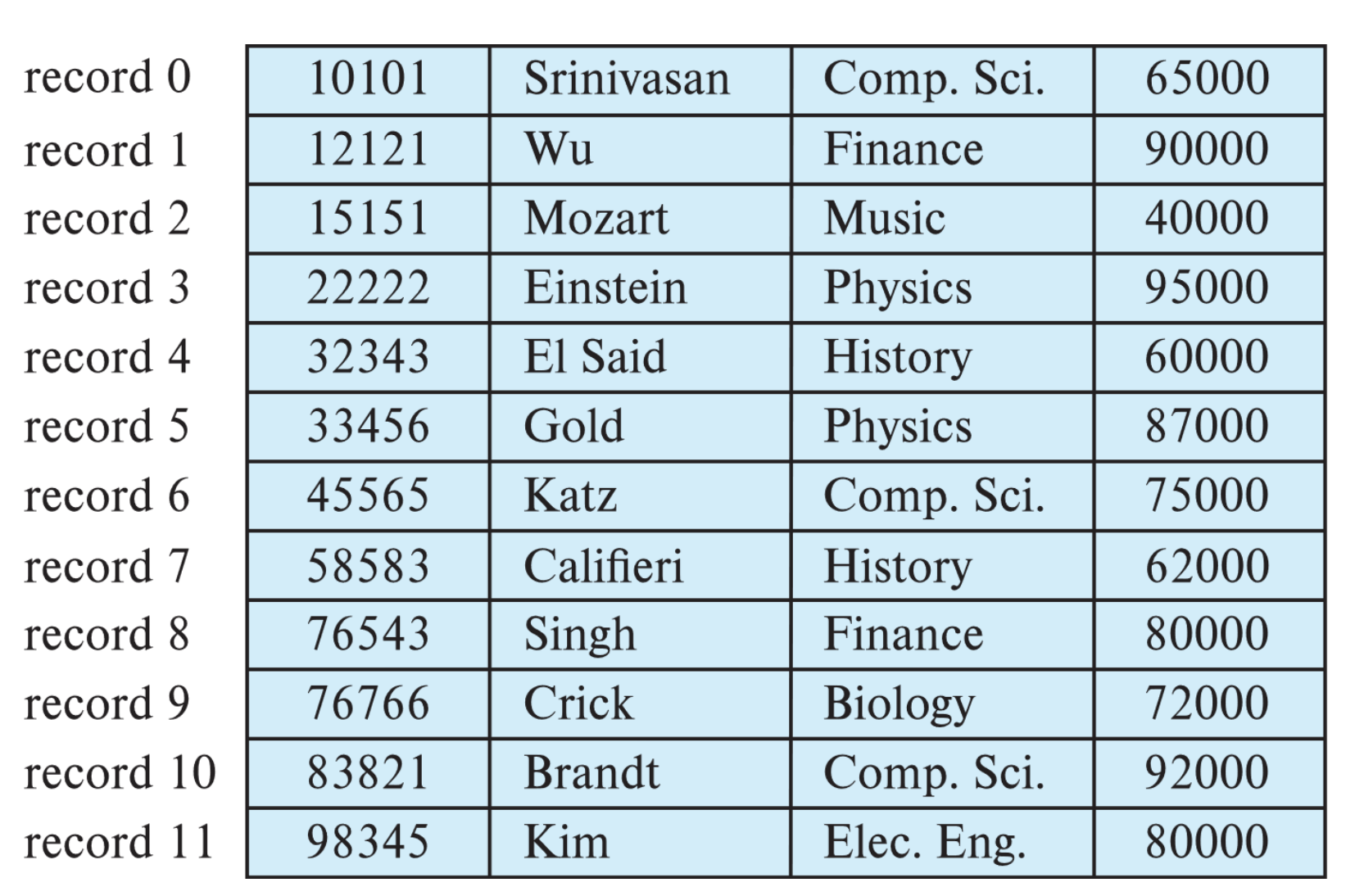
모든 레코드의 크기가 같기 때문에 레코드를 읽는 방법은 간단하다. DBMS는 해당 레코드가 있는 블록을 메모리로 읽어와 간단하게 원하는 레코드를 찾을 수 있다. 하지만 만약 저장공간을 아끼기 위해 하나의 레코드를 두 블록에 나누어 저장하는 경우 구조가 복잡해지기 때문에 일반적으로 저장효율이 조금 떨어지더라도 한 레코드를 나누어 저장하는 것을 허용하지 않는다.
레코드 삭제 전략
레코드의 조회는 위에서 설명한것처럼 단순히 레코드가 있는 블록을 메모리로 읽으면 된다. 하지만 레코드를 삭제하는 경우 삭제된 레코드가 있던 자리를 어떻게 관리하는지에 따라 DB의 성능이 달라질 수 있다.
- 모든 레코드를 한칸씩 당기는 방법
- 레코드 삭제시 DBMS는 DB에서 한번에 2블록씩 메모리로 읽어와서 한칸씩 레코드를 당긴 후 DB에 저장한다. 따라서 각 블록당 2번의 I/O가 발생하므로 전체 I/O의 횟수는 2k이므로 복잡도는 O(k)이다.(k : blocking factor)
- 마지막 레코드를 빈 공간으로 올리는 방법
- 레코드 삭제시 DBMS는 해당 블록과 마지막 블록을 메모리로 올려 작업을 수행한 뒤 저장하므로 총 I/O는 4번 발생하여 O(1)의 복잡도를 가진다.
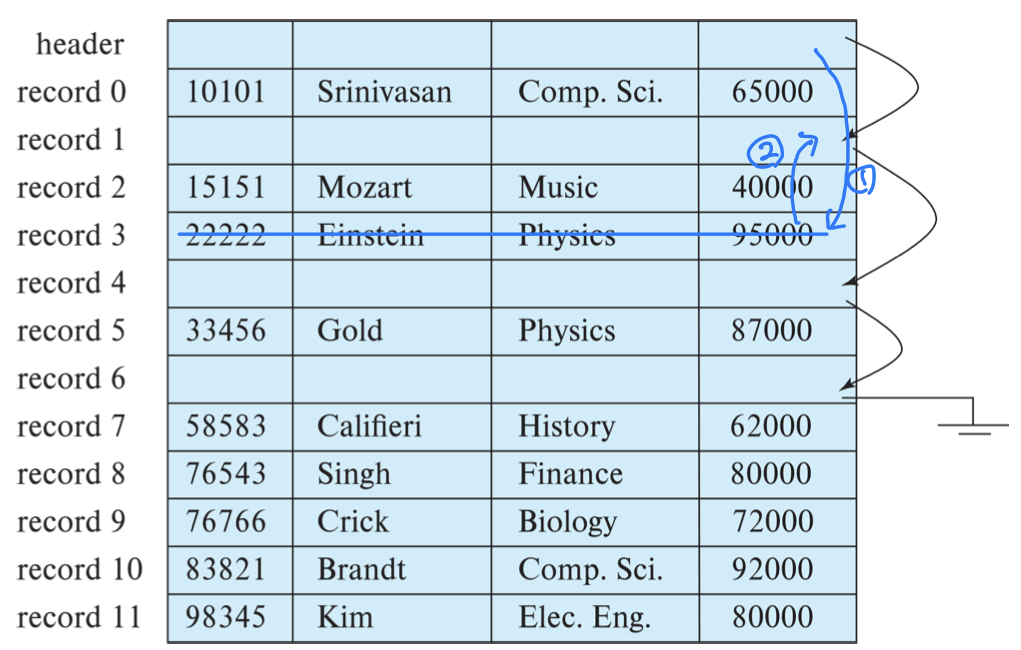
- 빈 공간을 연결리스트를 통해 관리하는 방법
- 레코드 삭제시 레코드를 이동하지 않고, 연결리스트의 헤더와 삭제된 공간을 연결한 뒤 삭제된 공간과 기존 리스트를 연결한다. 이 경우 헤더가 있는 블록과 삭제할 레코드가 있는 블록만 메모리에 올려서 작업하므로 총 4번의 I/O가 발생하고 O(1)의 복잡도를 가진다.
- 링크를 위한 추가적인 필드가 필요하다.
가변길이 레코드
고정길이 레코드방식으로 데이터를 저장하는 경우 한 파일에 하나의 자료형밖에 저장할 수 없고, 모든 필드가 고정된 길이를 가지기 때문에 유연성이 떨어진다. 이런 단점을 해소하고자 가변길이 레코드 방식이 등장하게 되었다.
가변길이 레코드 방식에서는 하나의 파일에 여러 자료형이 저장될 수 있고, 하나 이상의 필드에 varchar와 같은 가변길이 자료형을 저장할 수 있다.
구조
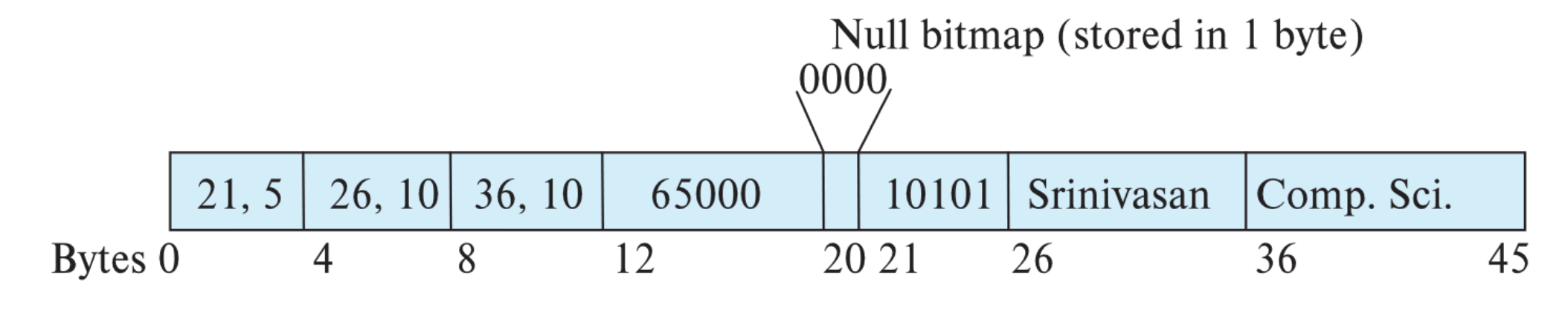
가변길이 레코드는 위의 그림과 같이 저장된다. 0 ~ 19 Byte에는 고정길이 레코드에서와 같이 필드값들이 순서대로 저장된다. 이때 고정길이 필드는 값이 그대로 저장되지만 가변길이 필드값은 일정한 길이의 (offset, length)의 형태로 매핑되어 저장된다.
- offset : 실제 값의 시작위치
- length : 값의 길이
즉, 첫번째 필드인 (21, 5)는 21번째 바이트부터 5바이트의 길이를 가진 값을 참조한다는 의미를 가진다. 가변길이 필드의 실제값들은 모든 고정길이 필드값들 뒤에 저장되는데, 이 둘 사이에 Null bitmap을 통해 null값을 가진 column을 표시한다. DBMS는 실제 값을 보기 전에 Null bitmap을 먼저 확인하기 때문에 레코드에 값이 있어도 Null bitmap이 1로 표시된 필드는 null로 판단한다. 예를 들어 위의 그림에서 Null bitmap이 1000이라면 첫번째 필드값에 10101이 저장되어있지만 DBMS에서는 이를 null로 인식한다.
데이터 변경
가변길이 레코드의 데이터를 변경할 때에는 데이터의 길이에 맞게 (offset, length)쌍을 먼저 업데이트 한 뒤 실제값을 변경한다. 이 과정에서 데이터의 길이가 늘어나거나 줄어드는 경우 뒤의 필드들에 영향을 줄 수 있다.
또한 데이터를 null로 변경하는 경우 두가지 방법으로 구현이 가능한데, 첫번째는 Null bitmap만 업데이트 하는 방식이다. 이 경우 실제값들은 그대로 두고 Null bitmap에서 해당 column의 값만 1로 바꾸면 되기 때문에 처리가 간단하고 정합성에 영향을 주지 않는다. 하지만 사용되지 않는 공간에 값이 존재하기 때문에 저장공간이 낭비될 수 있다는 단점이 있다.
두번째 방법은 위에서 설명한 방법처럼 (offset, length)쌍을 업데이트 하고 실제 메모리를 회수하는 것이다. 이 경우에도 Null bitmap의 값은 변경되어야 한다. 이와 같은 방법은 첫번째 방법보다 처리가 복잡하고 시간이 더 소모되지만 사용하지 않는 공간을 즉시 회수하기 때문에 저장공간을 아낄 수 있다는 장점이 있다.
Slotted Page구조
고정길이 레코드 방식에서는 모든 레코드의 길이가 같고 순서대로 저장되어있기 때문에 레코드의 번호만 알면 (레코드 길이 * 레코드 번호)로 원하는 레코드를 쉽게 찾을 수 있었다. 하지만 가변길이 레코드 방식에서는 각 레코드의 길이가 다르기 때문에 위의 방법으로는 레코드를 찾을 수 없다. 따라서 한 블록 내의 여러 레코드 중에서 특정 레코드를 추출하기 위해서 새로운 페이지 구조가 필요한데, 대부분의 DBMS에서 채택한 구조가 바로 Slotted Page구조이다.
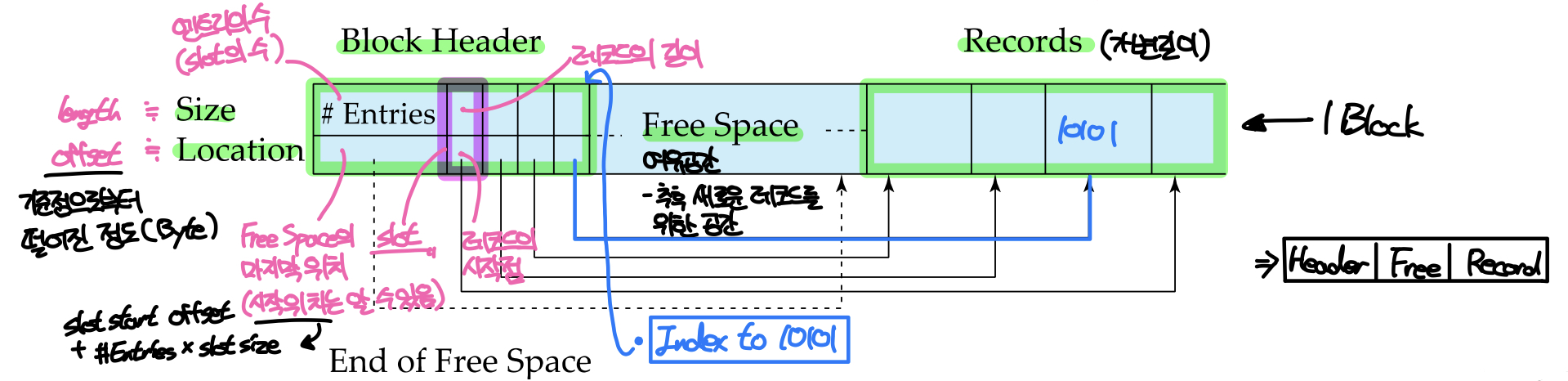
이 구조에서는 하나의 블록이 Header, Free Space, Records로 구성된다.
헤더는 블록과 레코드의 정보를 담고있는 공간으로, 레코드 엔트리(슬롯)의 수(Size), Free Space의 마지막 위치(Location, 전체 Record의 시작위치), 그리고 레코드의 위치와 크기정보를 담고있는 슬롯(Slot)이 저장된다.
헤더 다음으로 오는 Free Space는 블록에서 할당되지 않은 빈 공간으로 추후 새로운 레코드가 저장되거나 기존 레코드의 크기가 증가할때를 대비하기 위해 마련해 둔 공간이다.
Free Space의 뒤에는 실제 데이터를 저장한 레코드들이 앞서 본 가변길이 레코드 형식으로 저장된다.
Slotted Page구조에서는 각 레코드들 사이에 빈 공간이 없도록 유지한다. 따라서 레코드에 변경이 발생하면 레코드의 위치를 조정하여 빈 공간을 Free Space로 이동하고 헤더를 업데이트하여 슬롯과 레코드를 동기화한다.
또한 인덱스와 같이 외부에서 레코드를 가리키는 포인터는 레코드의 위치를 직접 가리키지 않고 슬롯의 위치를 가리키고 있어야 한다. 슬롯은 고정된 길이를 가지고 있기 때문에 블록 내에서 고정된 위치에 있지만, 레코드는 변경이 발생하면 그 위치가 조정될 수 있기 때문이다. 이를 Indirect Access라고 한다.
Blocking Factor 역시 고정길이 레코드 구조에서와는 다른 방식으로 계산되어야 한다. 고정길이 레코드 방식에서 Blockinf Factor는 (블록크기/레코드크기)로 구할 수 있었는데, 가변길이 레코드 방식은 레코드의 크기가 일정하지 않기 때문에 앞의 방법으로는 계산할 수 없다. 따라서 Slotted Page구조에서는 Blocking Factor를 다음과 같은 방법으로 계산한다.
- Bf = ceil((블록크기 - 헤더크기) / (평균 레코드 크기 + 슬롯 크기))
- 이때 헤더는 Size와 Location정보를 저장한 공간만을 의미한다.
CRUD연산
Slotted Page구조에서 SELECT, DELETE, INSERT, UPDATE쿼리문은 다음과 같은 방식으로 처리된다.
- 레코드 검색(SELECT) : indirect access
- 인덱스가 있는 경우 : 인덱스에서 가리키는 슬롯을 찾고 슬롯이 가리키는 레코드에 접근
- 인덱스가 없는 경우 : 블록 헤더의 슬롯에서 원하는 레코드의 위치를 찾아 접근
- 레코드 삭제(DELETE)
- 레코드 공간을 Free Space로 회수하기 위해 삭제할 레코드의 앞에 있는 레코드들을 오른쪽으로 Shift하여 Free Space의 공간을 확장한다.
- 이후 슬롯의 레코드 포인터를 갱신한다.
- 이때 슬롯공간은 Free Space 회수하지 않고 특수한 값(ex : -1)을 넣어 레코드가 없다는 것을 표시한다.
- 인덱스와 같은 외부포인터는 슬롯을 가리키고 있는데, 슬롯의 위치가 변경되면 인덱스가 잘못된 레코드를 가리키거나 dangling될 수 있다.
- 따라서 항상 슬롯의 수와 실제 레코드의 수가 일치하는 것은 아니다.
- 레코드 삽입(INSERT)
- Free Space에서 슬롯과 레코드 공간을 할당하고 레코드값을 저장, 슬롯에 레코드 정보를 반영한다.
- 해당 블록에 새로운 레코드가 삽입될 수 있는 조건은 아래와 같다.
- (Slot Size + Record Size <= Free Space) or (빈 슬롯 존재 & Record Size <= Free Space)
- 레코드 갱신(UPDATE)
- 레코드의 길이가 늘어나는 경우 : 앞쪽 레코드를 앞으로 이동하여 공간을 마련한 뒤 레코드의 값을 변경하고 슬롯에 변경된 레코드 정보를 반영한다.
- 레코드의 길이가 줄어드는 경우 : 레코드의 값을 변경한 뒤 앞쪽 레코드를 뒤로 이동하여 빈공간을 Free Space에 반납하고 슬롯에 변경된 레코드의 정보를 반영한다.
LOB
레코드들은 한 페이지의 크기보다 작아야 한다. 따라서 한 페이지의 크기를 넘어서는 데이터들은 레코드에 저장하면 비효율적이다. 이렇게 크기가 큰 데이터들을 LOB(Large Objects)라 하고 저장되는 자료형에 따라 BLOB(Binary LOB)와 CLOB(Character LOB)로 나눌 수 있다. LOB들을 저장하는 방법은 다음과 같다.
- LOB를 File System의 파일이나 데이터베이스가 관리하는 파일로 저장하고, 레코드에는 파일의 포인터를 저장하는 방법
- LOB를 작은 크기로 나누어 여러 튜플로 저장하는 방법
파일구조
레코드가 파일에 저장될 때, 파일의 구조에 따라 레코드들은 다양한 방식으로 저장될 수 있다.
Heap
레코드간 순서가 없이 파일에 빈 공간이 있으면 레코드를 저장하는 방식으로, 파일의 어느 곳이든 빈 공간만 있으면 레코드가 저장될 수 있다. 일반적으로 힙 파일의 레코드들은 한번 저장되면 이동하지 않고, Free-space map을 통해 블록 내의 빈 공간을 관리한다.
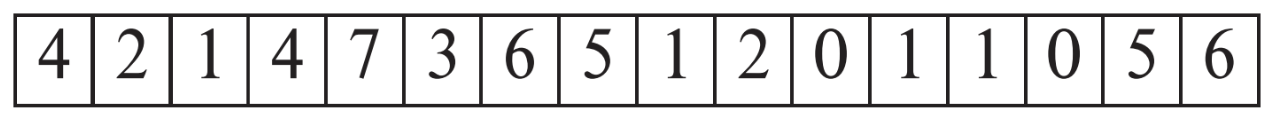
Free-space map은 각 블록에 빈공간이 얼마나 있는지 나타내는 배열로, 파일당 하나의 map을 가지고있다. 예를 들어 위의 배열은 첫번째 블록에 4/8, 두번째 블록에 2/8만큼의 빈 공간이 있다는 것을 표시한다. 이를 좀 더 축약하면 몇개의 블록을 하나로 묶어 가장 빈 공간이 많은 값을 나타내는 Second-level Free-space map으로도 표시할 수 있다.
Sequential
레코드의 search-key(주로 PK)값을 기준으로 모든 레코드를 순서대로 저장하는 방식으로, 업데이트는 불편하지만 모든 레코드를 순서대로 처리해야 할 때에는 적합한 방식이다.
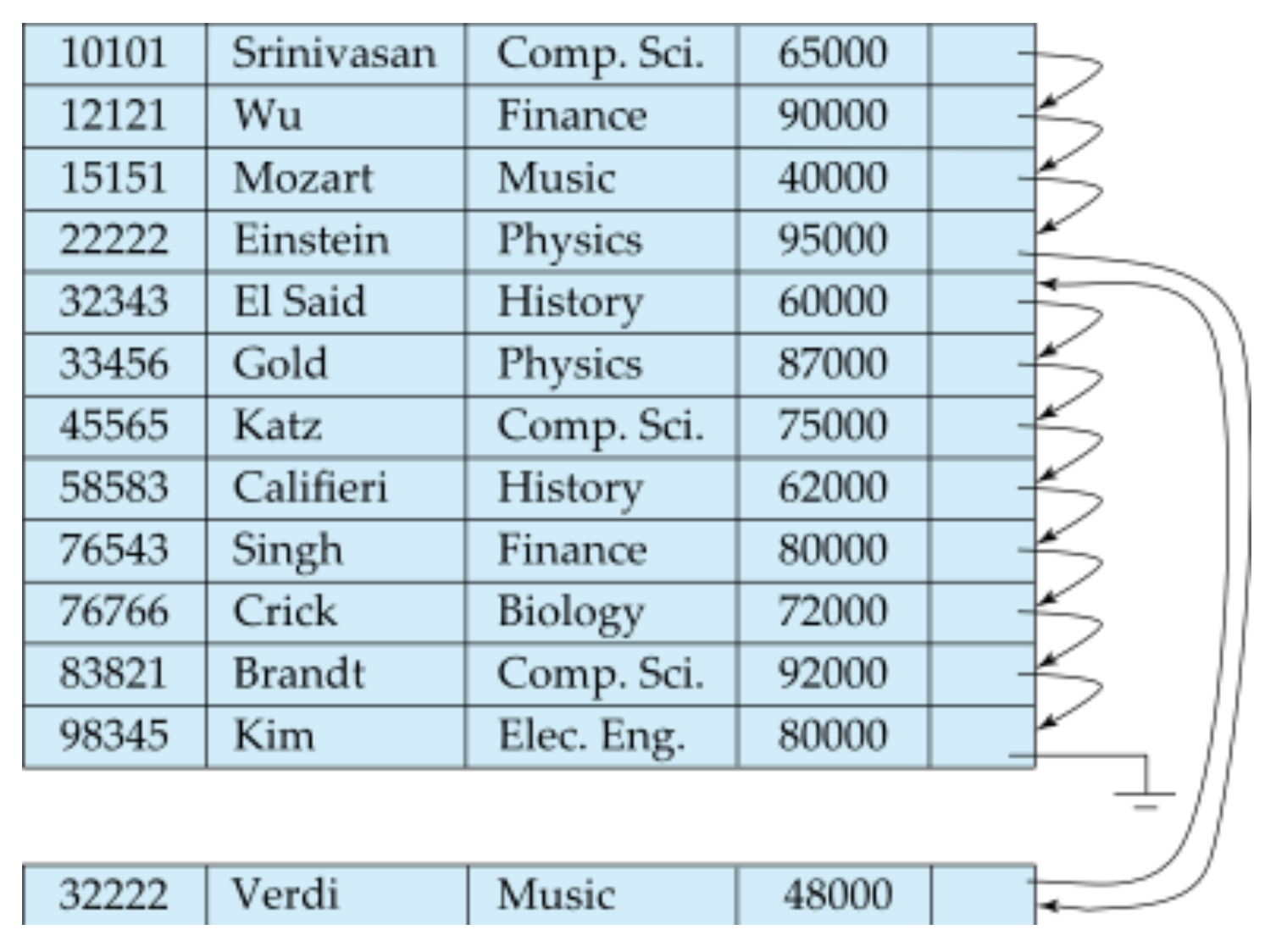
Sequential 파일 구조에서 레코드의 삭제는 단순히 pointer chain을 갱신하면 된다. 하지만 새로운 레코드를 삽입하는 경우 블록에 빈 공간이 있으면 그 자리에 레코드를 저장하고, 빈 공간이 없다면 별도의 오버플로우 블록에 레코드를 저장해야 하는데, 이 경우 오버플로우 블록을 메모리로 올려야하므로 I/O횟수가 2회 증가하게 된다. 또한 레코드간의 순서를 유지해야 하므로 두 경우 모두 pointer chain을 갱신한다.
Sequential 파일 구조에서 처음에는 파일의 논리적 구조와 물리적 구조가 일치하지만, 시간이 지날수록 오버플로우 블록의 사용이 많아져 I/O횟수가 증가한다. 따라서 이 구조에서는 적절한 시기에 파일을 재구성하여 레코드를 정리할 필요가 있다.
Multitable Clustering
서로 다른 테이블(릴레이션)에 있는 레코드들을 하나의 파일에 모아서 저장하는 방식으로, 연관된 레코드들을 하나의 블록에서 관리하여 I/O횟수를 줄이기 위해 등장하였다.
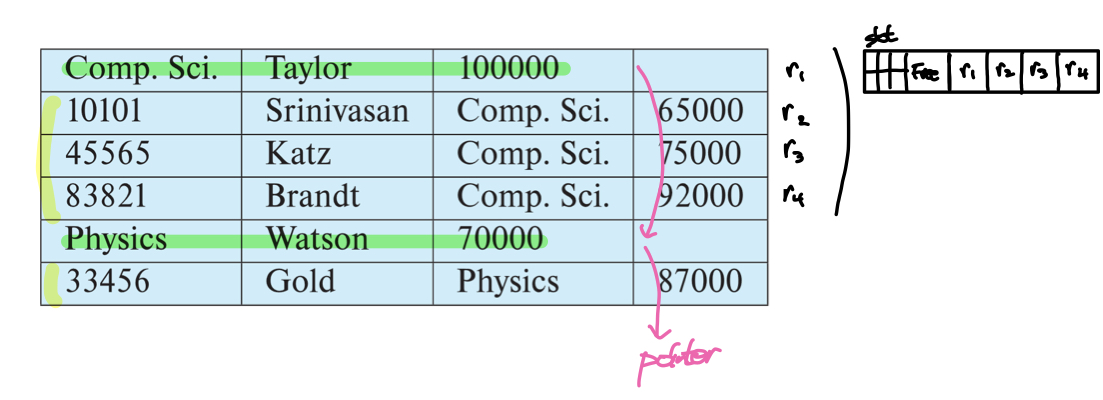
Multitable Clustering 파일구조는 연관된 레코드들을 모아서 관리하기 때문에 JOIN쿼리에 유리하다는 장점이 있다. 하지만 반대로 단일 테이블을 조회하는 쿼리에는 공간적으로 비효율적이다. 또한 조회성능을 향상시키기 위해 특정 릴레이션의 레코드들을 포인터로 연결하여 관리할 수도 있다.
B+ tree
B+트리의 leaf node에 레코드를 저장하는 방식으로, INSERT와 DELETE연산에서도 순서가 보장된다는 장점이 있다.
자세한 내용은 B+ Tree에 정리하였다.
Hashing
해시함수에 search-key를 넣어 계산한 값을 통해 레코드가 어느 블록에 위치하는지 찾을 수 있다.
자세한 내용은 Hashing에 정리하였다.
Data Dictionary Storage
Data Dictionary(System Catalog)란 데이터를 설명하는 정보인 metadata를 저장하는 공간이다. 메타데이터는 DDL Interpreter에 의해 DDL쿼리가 해석된 결과값으로 다음과 같은 정보를 가지고있다.
- 릴레이션의 정보(이름, 타입, 길이, 속성, 뷰 정보, 무결성 제약조건 등)
- view : 가상테이블. 실제 튜플은 저장하지 않고 definition만 저장
- 사용자, 계정정보
- 통계 데이터 : 질의 최적화에 사용
- 물리적 파일 구조 정보
- 인덱스 정보
메타데이터는 데이터를 설명하는 데이터이기 때문에 어딘가에 저장되어야 한다. 따라서 메타데이터 자체를 RDB에 저장해두고 SQL로 조회하여 사용한다. 추가적으로, 일반적으로 메타데이터는 DBMS에 의해 매우 빈번하게 조회되기 때문에 데이터베이스의 성능 향상을 위해 메모리 버퍼에 특별한 자료구조로 저장해두고 사용할 수도 있다.
버퍼
DBMS는 디스크와 메모리 사이의 블록교환(I/O)를 최소화 하기 위해 가능한 많은 블록을 메모리에 올려두고 사용하려 한다. 이때 디스크블록의 사본이 메모리에 보관되는 영역을 버퍼라 하고, 제한된 버퍼공간을 관리하기 위한 subsystem을 버퍼 매니저라고 한다.
프로그램이 DBMS를 통해 디스크에서 데이터 블록을 요청하는 경우 전체적인 동작과정은 다음과 같다.
- 프로그램이 버퍼 매니저를 호출한다.
- 찾는 블록이 버퍼에 있으면 버퍼 매니저는 프로그램에게 메모리에 있는 블록의 주소를 반환한다.
- 찾는 블록이 버퍼에 없으면 버퍼 매니저는 버퍼에 새로운 블록을 위한 공간을 할당한다. 이때 버퍼에 여유공간이 없으면 기존 블록을 교체한다. 교체된 블록은 변경사항이 있을 때에만 디스크에 write된다.
- 버퍼 매니저는 디스크로부터 블록을 읽어서 버퍼에 올리고, 프로그램에게 메모리상의 블록의 주소를 반환한다.
만약 데이터 블록이 변경될 때에는 I/O횟수를 줄이기 위해 버퍼의 데이터만 변경하고 실제 DB에는 여러 이유로 I/O가 발생할 때 반영한다. 따라서 특정 시점에 버퍼와 DB의 상태는 다를 수 있다.
버퍼 교환 정책
버퍼에 새로운 블록을 올려야 하는데 버퍼가 가득 찬 경우 버퍼에서 블록을 선택하여 교체해야 한다. 이때, 교체되는 블록은 버퍼 교환 정책에 의해 선택된다.
버퍼 교환 정책은 여러 종류가 있는데, 어떤 경우라도 현재 사용중인 블록이 교체되어 디스크로 내려가는 일이 발생해서는 안된다. 따라서 연산중인 블록에는 Pin을 꽂아 페이지가 교체되는 것을 방지하고, 연산이 끝나면 Unpin하여 교체대상이 될 수 있도록 한다. 즉, Pinned block은 버퍼에 있는 블록 중 디스크로 교체되면 안되는 블록이다.
만약 여러 사용자들이 동일한 페이지를 사용중인 경우 한 페이지에 여러개의 핀이 꽂혀있을 수 있는데, 이 경우 모든 핀이 뽑혀야 해당 블록이 디스크로 written back될 수 있다.
LRU
대부분의 OS에서 채택하는 블록 교체 정책으로 가장 오래된 블록을 디스크로 내리는 방법이다. 하지만 데이터베이스 환경에서 LRU는 비효율적일 수 있다.
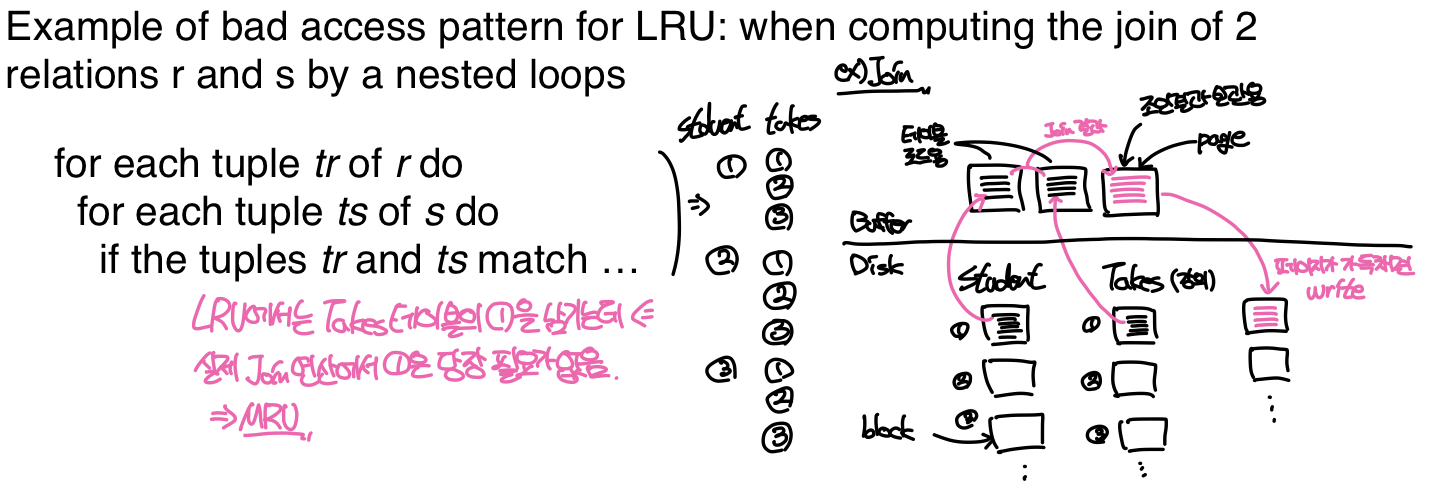
위의 예시에서 버퍼 매니저는 JOIN쿼리를 위해 3개의 페이지를 할당받았다. 따라서 두 페이지에는 원본 테이블의 블록이 올라오고, 한 페이지에는 JOIN결과로 만들어진 데이터를 보관한 뒤 페이지가 가득 차면 디스크로 write하고 페이지를 비운다. 이때 JOIN을 위해 두 테이블의 블록들을 모두 조합해보는 작업이 필요한데 이중 반복문의 형태로 작업이 이루어진다.
그런데 LRU에서는 가장 오래된 블록을 교체하기 때문에 작업을 마친 블록은 버퍼에 남아있다가 디스크로 교체된다. 하지만 실제 데이터베이스의 작업을 생각해보면 JOIN을 마친 블록은 가까운 미래에 사용되지 않기 때문에 버퍼에 남아있을 이유가 없다. 따라서 데이터베이스 환경에서는 LRU가 아닌 다른 버퍼 교환 정책을 고려해볼 수 있다.
Toss-Immediate
블록이 처리된 직후 교체하는 방법으로 항상 버퍼가 비어있다. 매 블록 처리마다 I/O가 수반된다는 단점이 있다.
MRU
가장 최근에 사용된 페이지를 교체하는 방법으로 블럭 내의 모든 튜플이 처리되고 꽂혀있는 핀이 없다면 그 블록은 most recently used block이 되어 우선적으로 교체된다. 위의 예시에서 만약 버퍼 매니저가 4개의 페이지를 할당받은 경우 LRU에서는 총 7번의 페이지 교체가 발생하지만 MRU방식에서는 4번의 교체밖에 발생하지 않는다. 따라서 LRU방식보다 좀더 데이터베이스 환경에 적합한 버퍼 교환 정책이라고 볼 수 있다.
