
Before
Multi-head self attention(이하 MHSA) 라는 연산은 데이터의 표현을 학습하는 (token-mixing) 하나의 방법으로 CNN, FCN, Pooling 등과 그 궤를 같이한다. CNN은 늘 MHSA와 비견되어 왔는데 일반적으로 알려진 사실은 아래와 같다.
CNN: Locality, Strong Inductive Bias, Efficient
MHSA: Globality, Weak Inductive Bias, expensive(w.r.t. sequence length)
위의 사실들을 바탕으로 사람들이 보통 생각했던 것은...
-
Representation Learning 등 generic한 task나 SSL 등에 MHSA가 적합하겠다
-
Long-sequence에는 MHSA가 적합하진 않겠다
-
Data 양이 적으면 CNN이 낫겠다
등이 있다.
2022년 N.Park and S. Kim의 ICLR Spotlight 논문 <HOW DO VISION TRANSFORMERS WORK?> 는 MHSA가 어떠한 특징을 가지는지, CNN과는 어떻게 비견되는지 Architecture 적인 차원과 Training principle 의 차원에서 설명한다.
논문 리뷰를 시작하기 전에 알아두어야 할 Loss landscape와 관련한 사전 지식들 (Preliminaries) 을 소개한다.
-
모델 학습 과정 중 Loss landscape이 Convex 하면 모델이 쉽게 minima에 도달할 수 있다 (수렴할 수 있다).
-
Loss landscape의 기울기가 가파르다면 학습 과정이 불안정한 (Instable) 경우가 많고, 반대로 기울기가 완만하다면 (Smooth) 학습 과정이 안정적이다.
-
Gradient의 Hessian matrix의 eigenvalue 최대값이 양수일 때, 그 값이 크면 Loss landscape의 기울기가 가파르다.
-
Gradient의 Hessian matrix의 eigenvalue 최대값이 음수라면, loss landscape의 non-convexity를 암시한다.
위 4가지는 기정사실화하고 논문 리뷰를 시작한다. 이 논문은 여러 파편화된 실험 결과들을 설명하고, 그것으로부터 통합된 유의미한 결론을 끌어내기 때문에 리뷰 역시 분절적이게 보일 수 있다.
About the inductive biases in ViT
모델의 Inductive bias가 적으면 Representation power가 낮아진다. 표현력 (Representation power) 이 낮으면 모델이 데이터에 fit하는 정도가 낮다는 것인데, 이는 데이터가 적은 상황에 ViT를 사용하지 않는 이유가 Overfitting 때문이 아니라 표현력이 낮기 때문이라는 점을 암시한다.
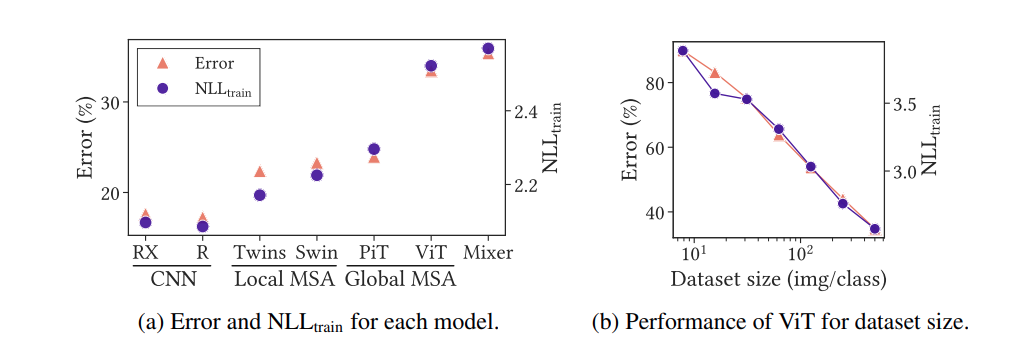
위 그림 왼쪽을 보면 더 명백히 확인할 수 있다. CNN이라는 Locality inductive bias가 가장 큰 구조부터 Local MSA (중간), Global MSA (Vanilla ViT이자 inductive bias가 낮음) 순서대로 Train error가 낮은 것을 확인할 수 있다. Train error는 Overfitting이 아니라, 모델의 표현력에 따라 달라지므로, Inductive bias와 representation power 간 상관관계를 의미한다.
위 그림 오른쪽은 더욱 흥미로운데, 데이터가 커질 때 Low inductive bias 모델인 Vanilla ViT 의 Train Error가 낮아진다는 것이다. 즉, 부족한 표현력은 데이터의 양을 늘림으로서 해결할 수 있다.
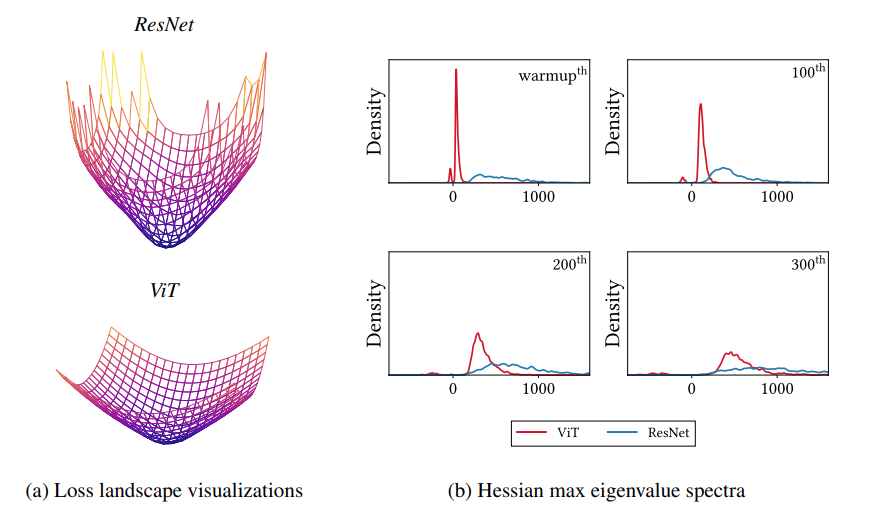
MHSA는 Loss landscape을 flatten 한다.
Loss landscape를 평탄화하는 것은 training stability를 높이는 데 매우 중요한 요소 중 하나이다. 대표적으로 ResNet이 loss landscape smoothing 에 가장 크게 기여하는 것을 우리는 잘 알고 있다. 위 그림 오른쪽을 보면 Hessian matrix의 max eigenvalue가 ViT에서는 0에 가깝게 분포하는 반면, ResNet에서는 값이 큰 양수들이 많이 있는 것을 볼 수 있다. 앞선 Before 섹션에서 Hessian max eigenvalue 설명한 내용과 연관지어 생각해보면, Loss landscape가 평탄한 정도가 ViT (MHSA를 사용한) 의 경우가 좋다는 것을 확인해 볼 수 있다.
MHSA는 Low-frequency components에, CNN은 High-frequency components에 집중한다.
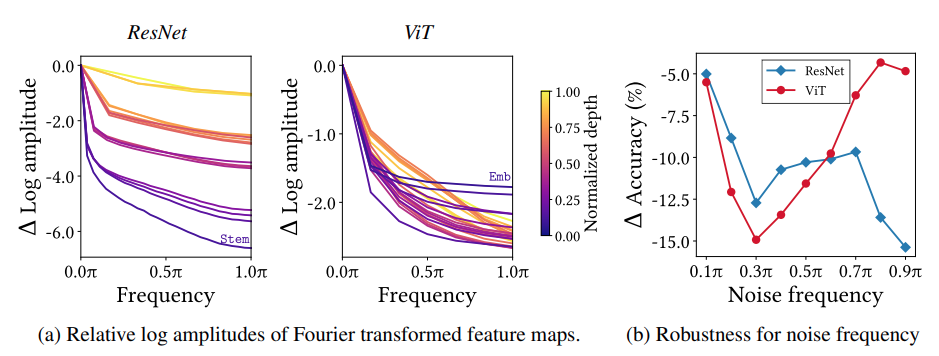
Audio나 신호를 공부한 적이 있다면 쉽게 이해할 수 있겠지만, High-frequency components는 주로 고해상도, 디테일한 정보와 연관되어 있고, Low-frequency components는 제반적인 정보와 관련되어 있다. 아래 그림의 왼쪽을 보면 ResNet의 경우 입력 데이터의 제반적인 정보 (Low-frequency)와 디테일한 정보 (High-frequency)를 골고루 이해하며, 정보를 병합하지 않는다. 이는 Locality라는 inductive bias 에서 기인한 것으로 보인다.
반면 MHSA의 경우 High-frequency 정보를 통합해서 기본적인 정보만 남기는 것을 확인할 수 있는데, 이는 Attention value의 mean 연산을 통해 context를 모으는 MHSA의 특징이겠다. 아무래도 평균 연산을 하다보면 디테일한 정보는 어느정도 사라질 테니까.
아래 그림의 오른쪽은 High-frequency noise를 첨가하는 것과, Low-frequency noise를 첨가하는 것 둘중에 ViT와 ResNet이 어떻게 성능에 악영향이 있는지 확인하고자 한다. High-frequency 정보를 디테일하게 파악해야 하는 CNN 기반의 ResNet의 경우는 High-freq noise 첨가에 robust하지 못하지만 Low-freq noise 첨가에는 비교적 robust한 경향을 보인다. ViT의 경우는 그 반대로 High-freq noise를 첨가하는 것이 성능에 유의미한 영향을 주지 못하는데, 그 이유는 ViT가 Low-frequency 정보만 가지고 작업을 수행하기 때문일 것이다.
Conclusions
MHSA와 CNN은 서로 다른 특징을 갖고 있고 따라서 상호보완적으로 사용될 때 그 성능을 극대화할 수 있다. 좋은 모델은 Loss landscape이 convex 한 상태에서 평탄해야 하며, 표현력이 좋아야 할 것이다. 표현력을 키우기 위해 Locality inductive bias가 있는 CNN을 사용해야 하지만 Loss landscape을 평탄하게 만들기 위해 MHSA 역시 기용해야 한다. 게다가 MHSA는 표현력이 데이터의 양과 다양성에 의존하기 때문에 데이터의 양을 키우는 것 역시 매우 중요하다. 또 주파수 관점에서 ResNet과 ViT를 함께 사용하는 것은 고주파, 저주파 영역의 신호를 모두 적절히 혼합해 추론하겠다는 의미겠다. 이 논문에서는 저자가 AlterNet이라는 구조를 ResNet과 ViT를 함께 융합한 버전으로 소개한 바 있다.
