Paper Review
1.How Do Vision Transformers Work? 논문 리뷰

Before Multi-head self attention(이하 MHSA) 라는 연산은 데이터의 표현을 학습하는 (token-mixing) 하나의 방법으로 CNN, FCN, Pooling 등과 그 궤를 같이한다. CNN은 늘 MHSA와 비견되어 왔는데 일반적으로 알려
2.WHEN VISION TRANSFORMERS OUTPERFORM RESNETS WITHOUT PRE-TRAINING OR STRONG DATA AUGMENTATIONS 논문 리뷰
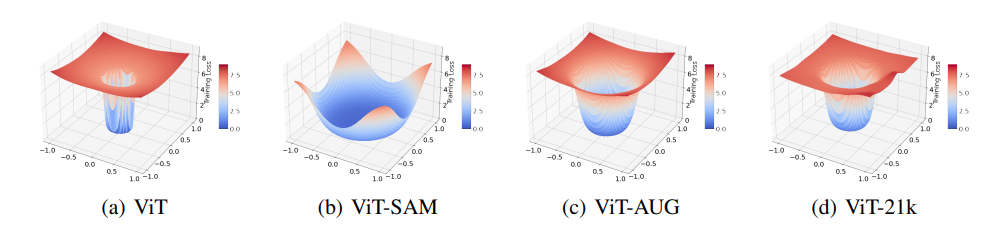
Introduction 이전까지 ViT에 대해 사람들이 알고 있는 것에는 아래의 내용이 있다. ** 데이터의 양이 적을 때 ViT는 ResNet을 뛰어넘기 힘들다. ** ViT는 Inductive Bias가 부족하기 때문에 ViT의 표현력을 키우기 위해서는 많은 양
3.여러 논문에서 가져오는 한줄 인사이트: Mamba 편
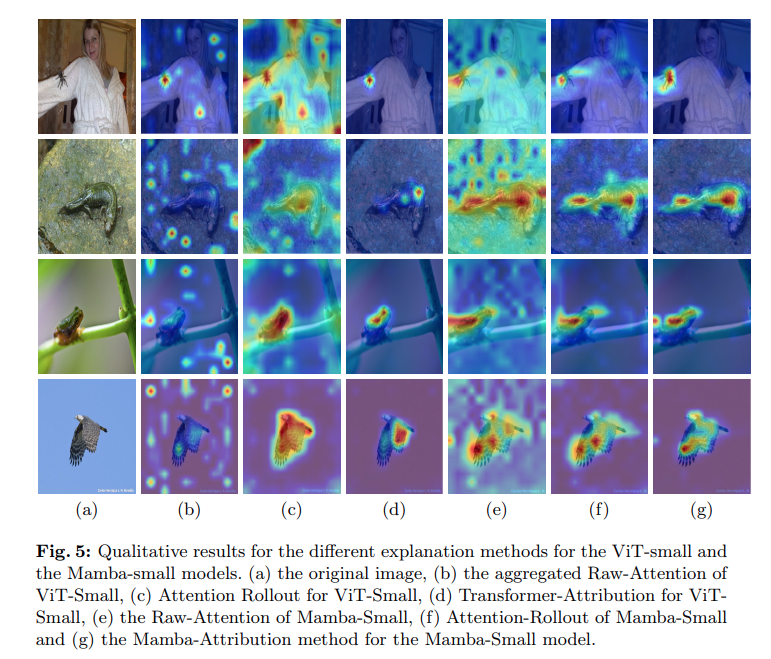
[Rethinking Mamba in Speech Processing by Self-Supervised Models (Xiangyu Zhang et al., 2024)](https://arxiv.org/pdf/2409.07273) Insight: Reconstruct
4.Paper Review: Are all negatives created equal in contrastive instance discrimination?
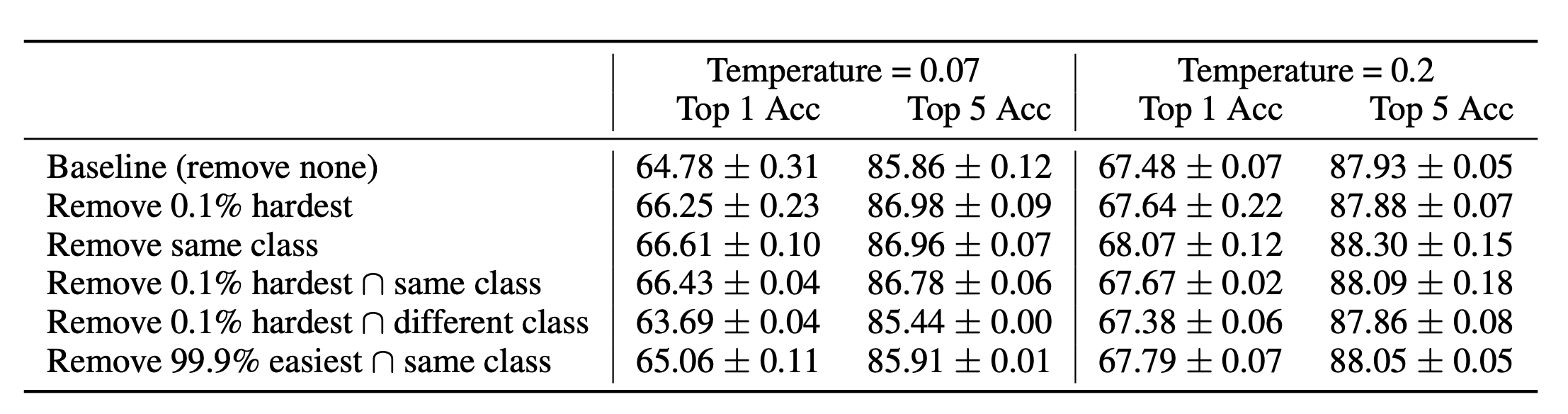
Paper Are all negatives created equal in contrastive instance discrimination? (arxiv preprint, 2020) Link https://arxiv.org/abs/2010.06682 Introduct
5.AudioLDM2: Learning Holistic Audio Generation with Self-Supervised Pretraining 논문 리뷰
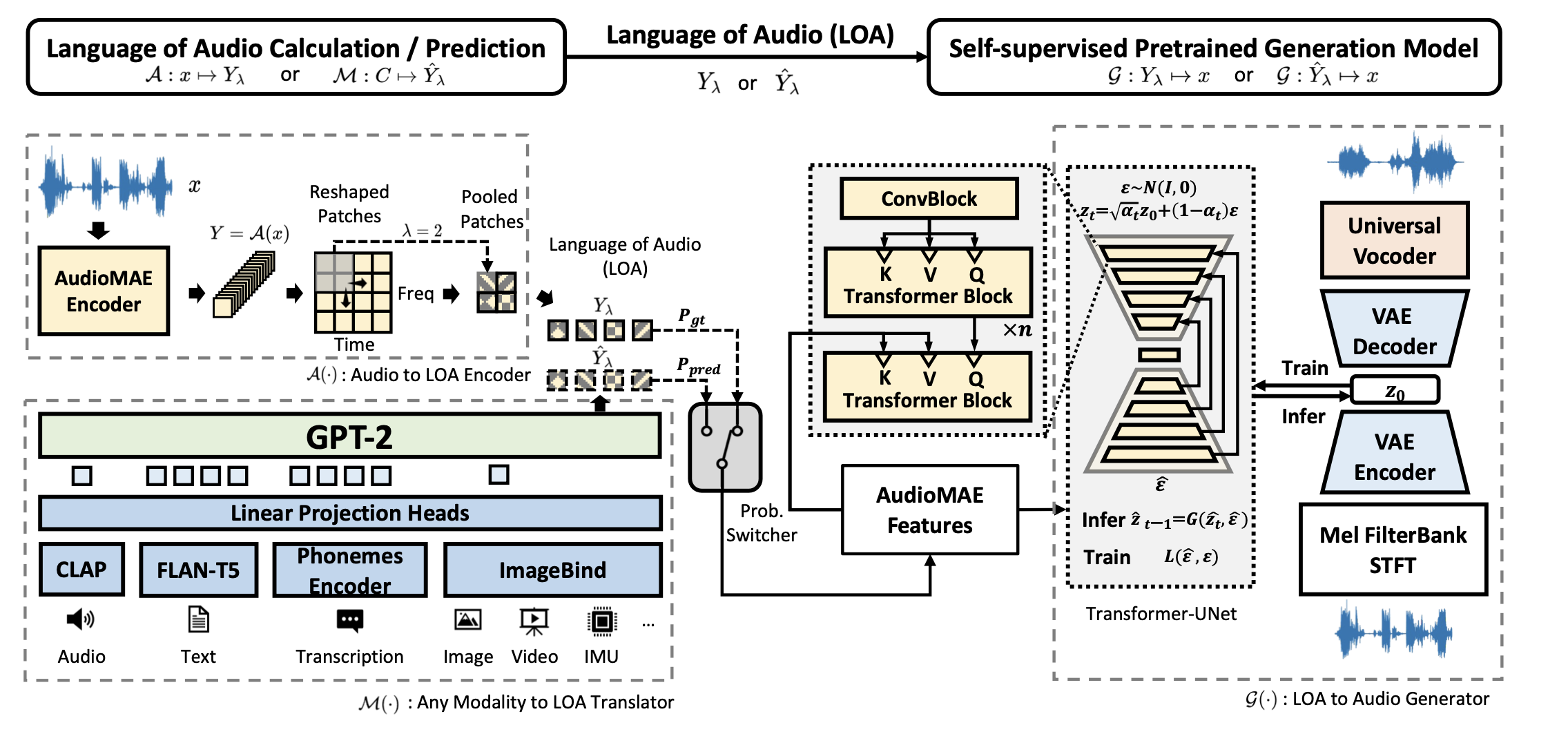
2023년 8월 CVSSP(Center for Vision, Speech and Signal Processing)와 Bytedance가 Audio Generation, 혹은 멀티모달(Multi-Modal) 영역의 SOTA AudioLDM2를 발표했다. 동해 1월에 등장
6.HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis 논문 리뷰

논문 리뷰를 마음속으로만, 노트 필기로만 하고 velog 등에 올리는 것이 귀찮아서 좀 안했었다. 하지만 이제부터라도 꾸준히 논문 리뷰를 하고, 이전에 읽었던 것들 혹은 새로이 읽게되는 것들에 대해 리뷰성 글들을 꾸준히 작성해 보아야겠다.
7.Paper Review: Listenable Maps for Audio Classifiers
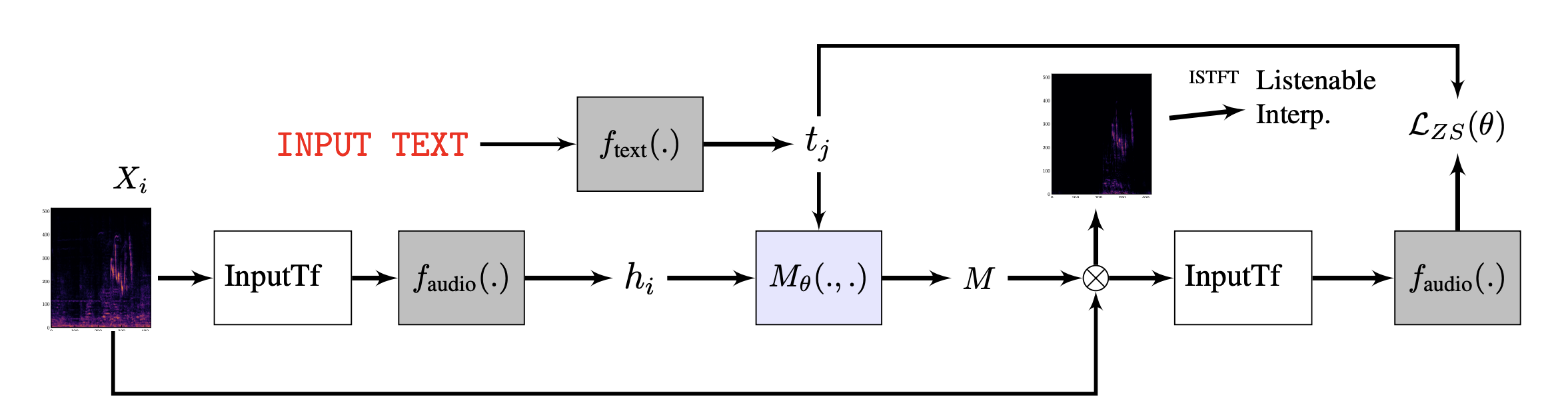
As AI models get bigger and deeper, understanding how AI model works has been a growing topic among many researchers. A few researches focus on layer-
8.REVISITING SELF-SUPERVISED LEARNING OF SPEECH REPRESENTATION FROM A MUTUAL INFORMATION PERSPECTIVE 논문 리뷰
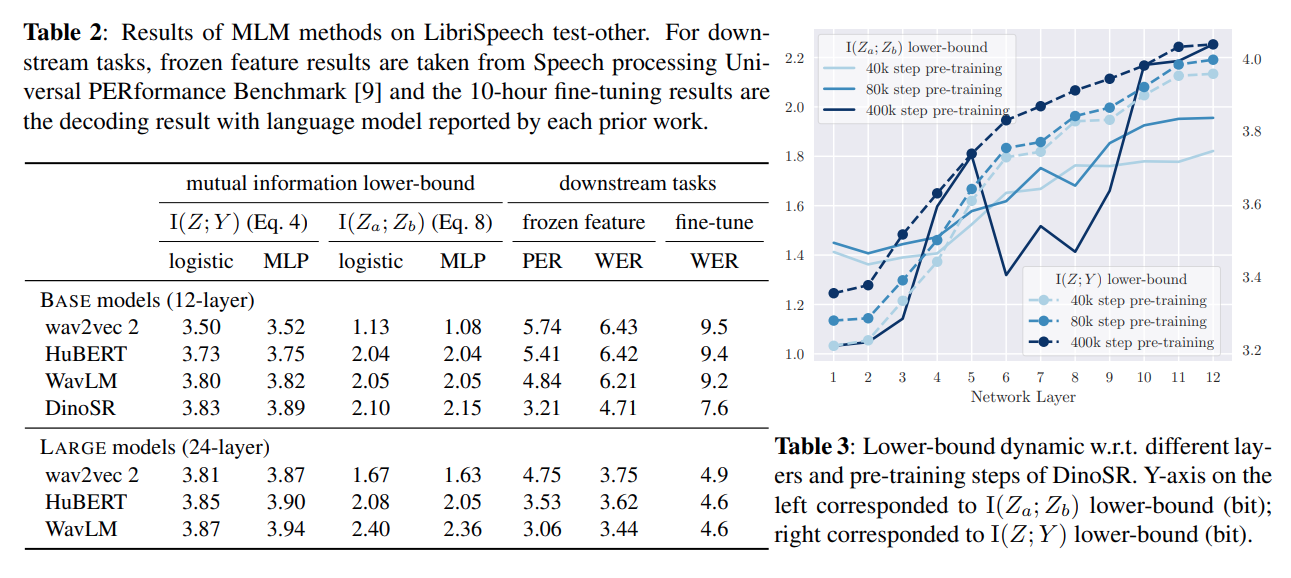
ICASSP 2024에 게재된 Alexander H.Liu et al.의 논문 REVISITING SELF-SUPERVISED LEARNING OF SPEECH REPRESENTATIONFROM A MUTUAL INFORMATION PERSPECTIVE은 Self-Su
9.Paper Review: PHASEN: A Phase-and-Harmonics-Aware Speech Enhancement Network

Studies on Speech Enhancement usually were performed on Time-Frequency (T-F) domain since the patterns of noise could be easily distinguished in TF do
10.<Scaling Laws in Patchification: An Image is Worth 50,176 Tokens and More> Paper Review
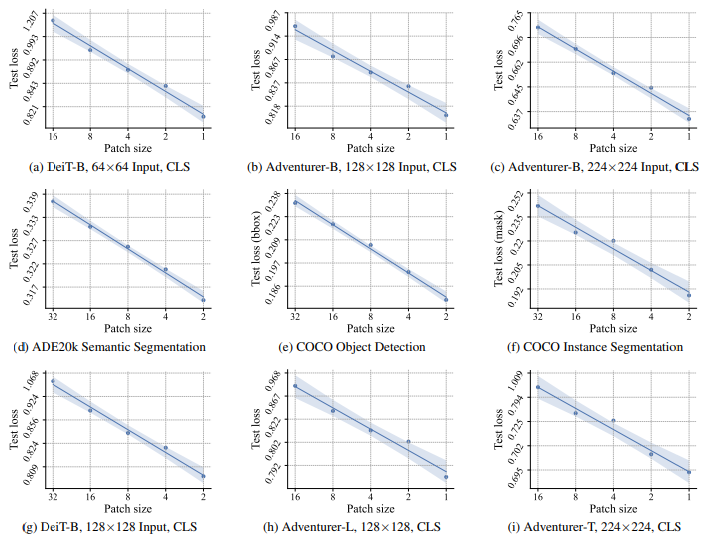
Vision Transformer (ViT) encoding a 224 $\\times$ 224 image and Vanilla Transformer encoding a 196 characters result in the same size of feature map w
11.Paper review: TASNET: Time-Domain Audio Separation Network For Real-Time and Single-Channel Speech Separation

Real-time speech processing remains challenging. Issues are: is Fourier decomposition the best? The vanilla works usually predict the source magnitude
12.Paper Review: FINALLY: fast and universal speech enhancement with studio-like quality
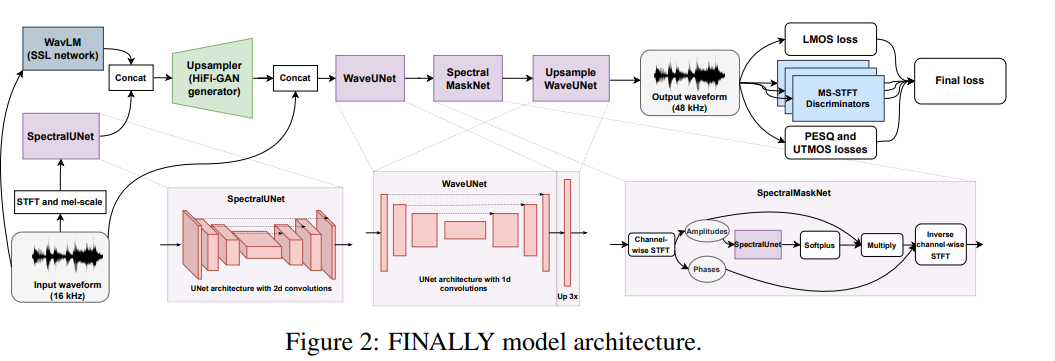
This post includes a brief paper review on the paper called 'FINALLY: fast and universal speech enhancement with studio-like quality', Babaev et al.,
13.Paper Review: Voice-ENHANCE: Speech Restoration using a Diffusion-based Voice Conversion Framework
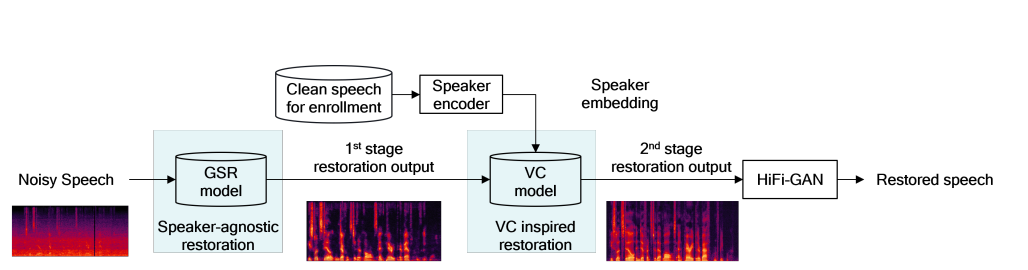
Speech Restoration is a complicated task that deals with multiple acoustic distortions such as reverberation, band-limitation and more.Such a complica
14.Paper review: Listen through the Sound: Generative Speech Restoration Leveraging Acoustic Context Representation
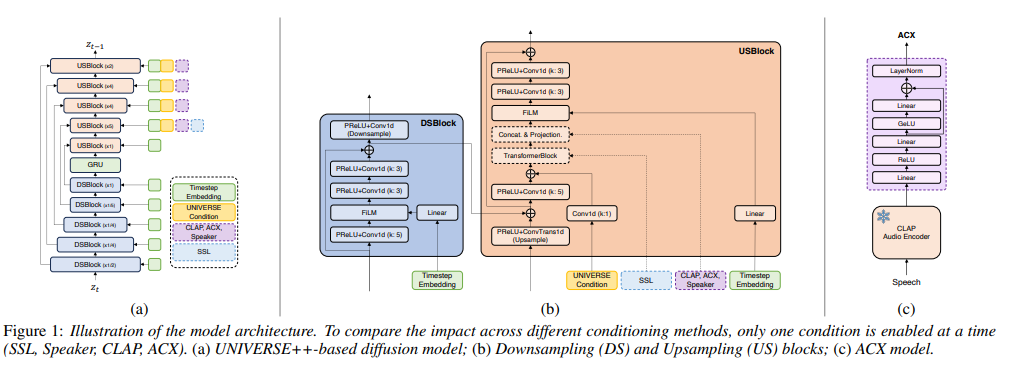
Current models do not explicitly model degradation information (e.g., type, intensity)Injection of conditions like SSL or Speaker embeddingACX, a nove
15.Paper review: <Sampling Frequency Independent Dialogue Separation>
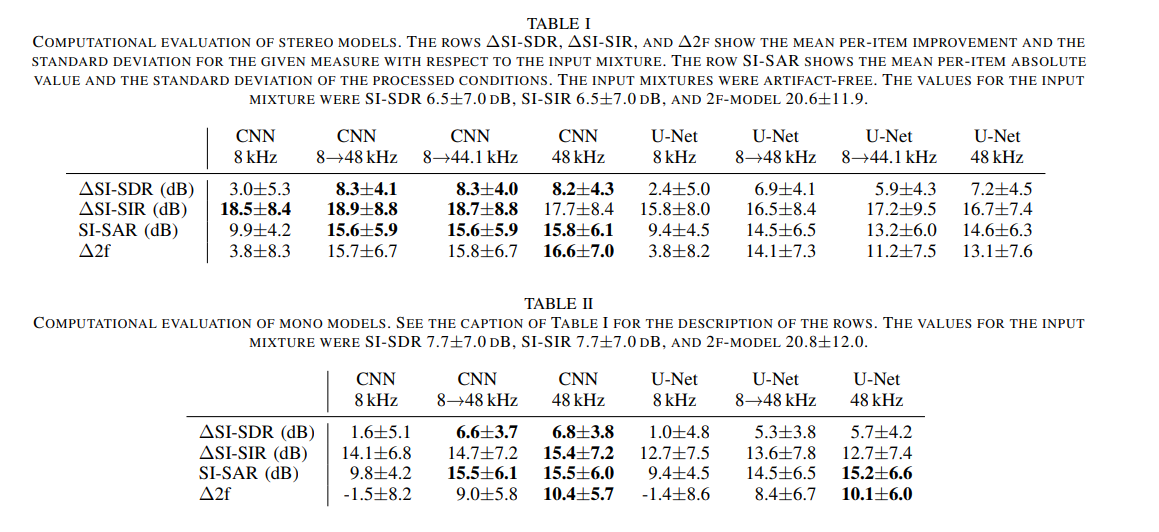
A model trained with a single sampling rate (sampling frequency) can be transferred to a model with different sampling rates.Sampling frequency indepe
16.Paper review: <Understanding and Improving Layer Normalization>
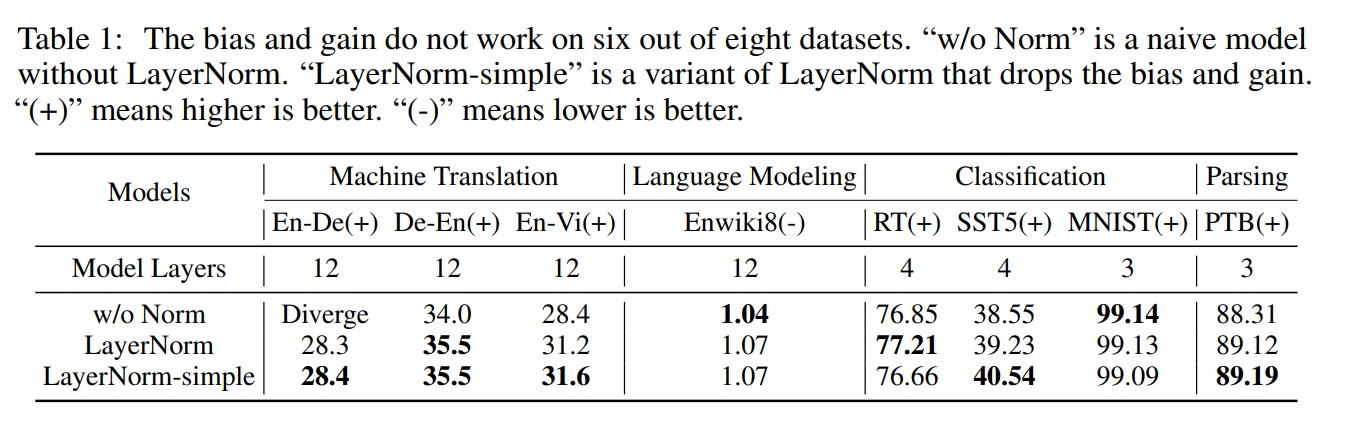
Layer normalization (LN) has been often incorporated in systems especially in NLP or Speech, due to its adaptaility to sequential data. Not all compon
17.Paper Review: <AN INVESTIGATION OF INCORPORATING MAMBA FOR SPEECH ENHANCEMENT>
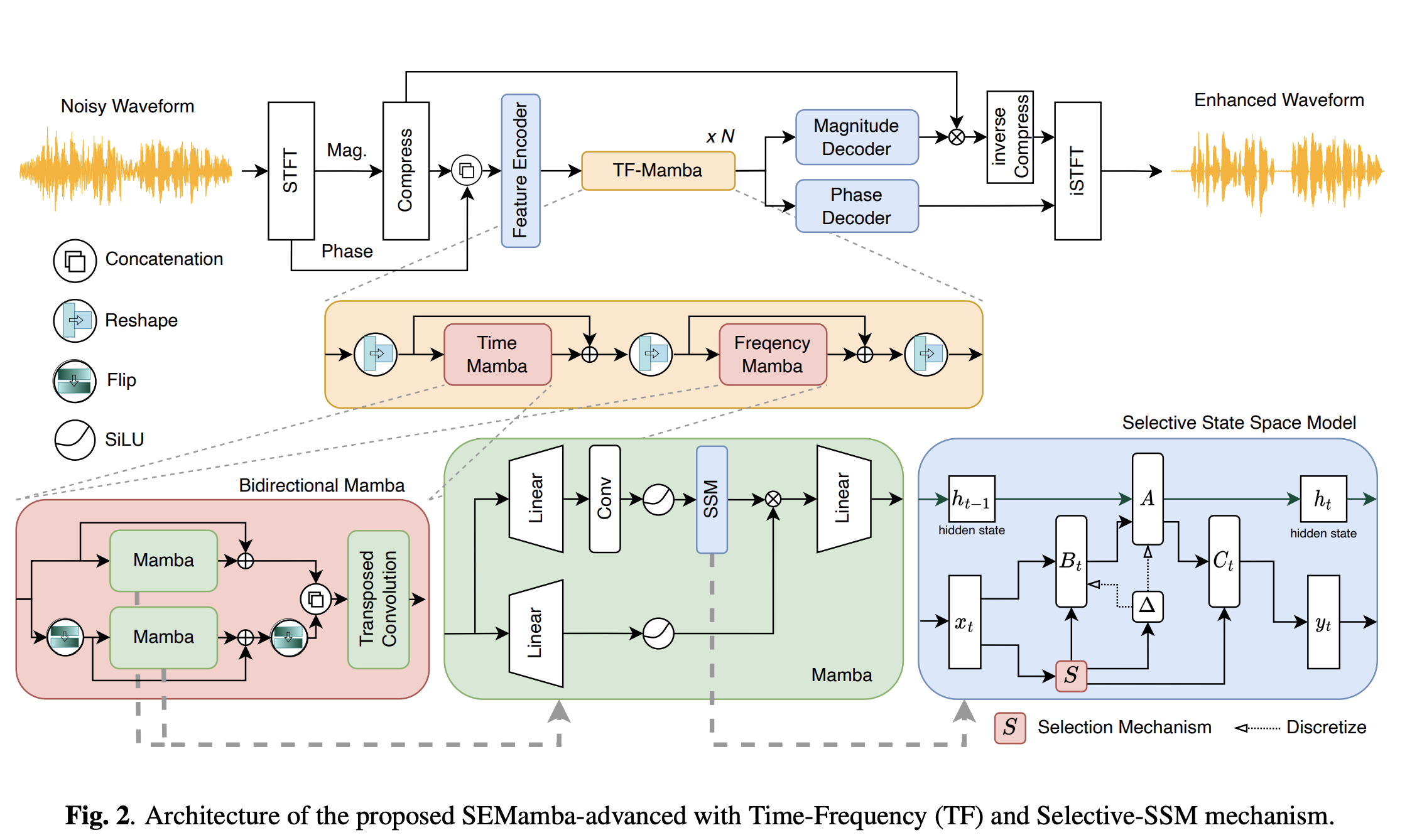
This post is about the paper review on "AN INVESTIGATION OF INCORPORATING MAMBA FOR SPEECH ENHANCEMENT", Chao et al., SLT 2024. Applying Mamba on Spee