WHEN VISION TRANSFORMERS OUTPERFORM RESNETS WITHOUT PRE-TRAINING OR STRONG DATA AUGMENTATIONS 논문 리뷰
Paper Review
이전까지 ViT에 대해 사람들이 알고 있는 것에는 아래의 내용이 있다.
- 데이터의 양이 적을 때 ViT는 ResNet을 뛰어넘기 힘들다.
ViT는 Inductive Bias가 부족하기 때문에 ViT의 표현력을 키우기 위해서는 많은 양의 데이터를 활용한 표현 학습이 필요하다. ResNet은 Locality나 Equivariance와 같은 property를 연산 과정 자체에 내재하고 있으므로, 데이터의 양이 적어도 충분히 훌륭한 학습을 할 수 있다는 것이 정론이었다.
이는 Transformer에도 널리 적용되는 부분일 것이라 생각했는데, 2022년 ICLR Spotlight 논문이었던 WHEN VISION TRANSFORMERS OUTPERFORM
RESNETS WITHOUT PRE-TRAINING OR STRONG DATA
AUGMENTATIONS 는 데이터의 양이 적을 때 어떻게 ViT가 ResNet을 이길 수 있을지 연구했다.
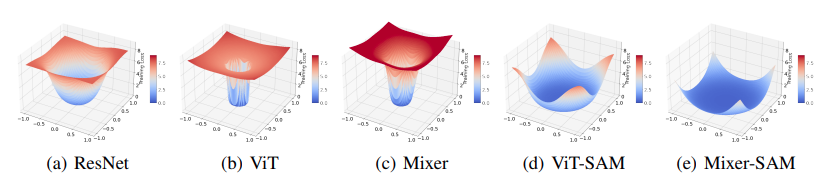
위 그림을 보면, (a) ResNet의 Loss landscape은 wide & smooth 한 반면 (b) ViT 의 Loss landscape은 narrow & spiking 하다는 것을 확인할 수 있다. (c) Mixer, 즉 2021년도 등장한 inductive-bias free한 MLP-Mixer 의 Loss landscape 역시 그 경사도나 narrowness가 훨씬 심하다는 것을 확인할 수 있다.
Loss landscape가 평탄하면 모델의 표현 학습이 더욱 Generalizable 하다. 즉, 가장 가깝게는 test data에 대한 적용부터 domain adaptation, task adaptation 등 다양한 transfer learning 스키마에서도 잘 작동할 수 있게 된다. ViT는 선행 연구에서 Loss landscape의 기울기를 평탄화하기 위해서 많은 양의 데이터로 Pretrain 하는 방식을 선택했다고 우리는 잘 알고 있다.
논문의 주요 Contribution은 ViT에 Large data나 augmentation 등이 아닌 SAM을 적용해 Loss landscape을 평탄하게 만들 수 있었다는 점이다.
여기서 SAM은 2020년 논문 Sharpness-Aware Minimization for Efficiently Improving Generalization
에 나왔던 Sharpness-Aware-Minimization의 약자로 Loss landscape에서 개별 지점들끼리의 관계를 바탕으로 Gradient을 계산하는 것이 아니라, 도달하고자 하는 목표 지점과 그 주변 부분을 전부 보고 gradient를 계산한다. 이렇게 하면 평탄한 지점으로 loss를 움직이게끔 작동시킬 수 있고, 따라서 training stability가 높아지면서 가장 중요하게는 generalization power를 키울 수 있다는 점이 있다.
더 세부적으로는, SAM은 Gradient가 모이는 (Back-prop에서) 앞 레이어들 (Early layers)에서 활동성이 있는 (non-zero) neurons의 개수를 줄여서, Hessian max eigenvalue를 낮출 수 있게 되고, 이는 곧 Loss landscape의 평탄화를 이끌어 낼 수 있는 것이다.
마치 Early convolutions help transformers see better (2021, NeurIPS) 에서 초기 embedding을 세밀하게 조정해 training stability를 키웠던 것과도 유사한 것 같다.
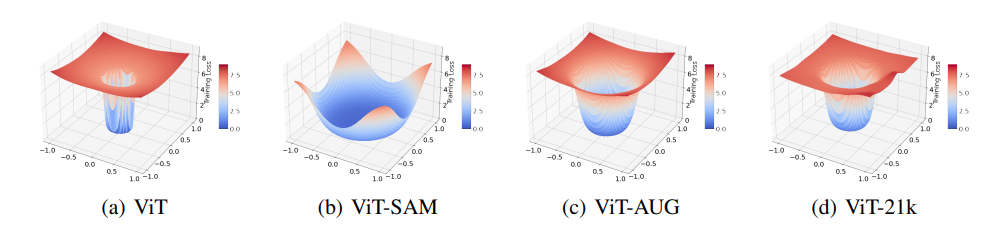
더 재밌는 것은 위의 그림처럼 ViT에 Augmentation을 적용하거나 (ViT-AUG) 데이터의 양을 늘리는 등의 방식을 적용할 때 (ViT-21k) Loss landscape을 보면, smoothing을 하는 방식 자체에서 차이가 있다는 것을 확인해 볼 수 있다. 이는, 여러 policy를 융합해 함께 사용했을 때 그 효과가 maximize될 수 있겠다는 implications도 남긴다.
아쉬운 것은, ViT에 SAM을 썼다는 것도 알겠고.. 다양한 실험을 했던 것도 알겠다. 그러나 과연 저자가 Novel한 contributions를 한 점은 무엇일까? 나의 이해가 부족할 수도 있으나 현재로서는 크게 떠오르지 않는다.
