Paper Review: FINALLY: fast and universal speech enhancement with studio-like quality
Paper Review
목록 보기
12/17
This post includes a brief paper review on the paper called 'FINALLY: fast and universal speech enhancement with studio-like quality', Babaev et al., NeurIPS 2024.
Introduction
- Speech enhancement can be dealt with in two fashions, discriminative methods and generative methods.
- LSGAN holds the property of both branches, possibly making the best fit for the studio-quality speech enhancement.
- Regressive losses can push the generator towards the most probable mode.
- Using an appropriate SSL features as regression target can help the model gain good quality in speech enhancement.
Methods
Choice of SSL features
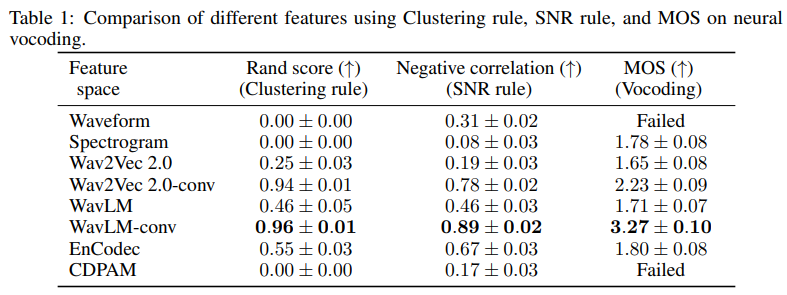
- The authors provide a evaluation tool to assess SSL features' ability to work as a good proxy for regression target.
- Clustering rule is a metric whether the same sound (same speaker, phoneme, recording environment, ... and more) are clustered together in SSL feature space.
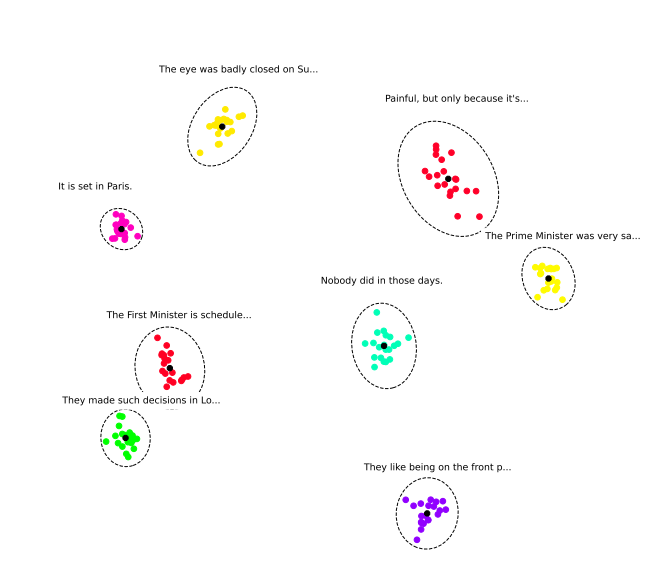
- SNR rule measurse the model's ability to tell between samples of different noise levels.

- Below are the results of different features using various rules, including additional vocoding ability.
Model architecture
- The authors inherit the model architecture from HiFi++, with two modifications.
- The authors incorporate WavLM-large model output as an additional input to the upsampler.
- Upsample WaveUNet that is able to upsample the speech signal.
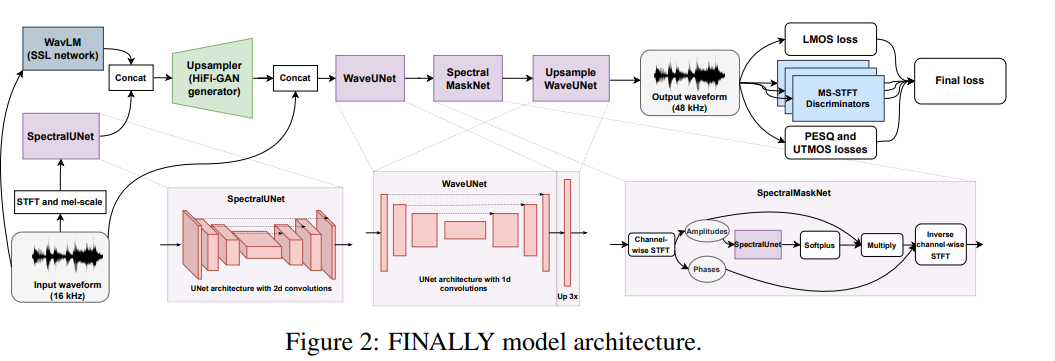
Training details - About GAN
- Generator loss is analogous to many of previous works, especially in neural vocoders.
- The authors use MS-STFT discriminator from neural audio codecs.

Training details - 3-stage training
- The authors employ three stages training scheme, mainly due to the different traits data have.
- At first stage, the authors use regression loss only without adversarial learning. This stage helps provide the generator with a better initialization before adversarial training.
- In the second stage, the authors start adversarial training wih MSSTFT discrimiantors and the LMOS loss, with larger values for LMOS and FM loss to better emphasize the reconstructino of linguistic content.
- In the third stage, the adversarial training is done, but in the sampling rate of 48 kHz to generate a studio-quality speech enhancement. In this stage, the relative weight on adversarial losses increase in order to focus on the perceptual quality. UTMOS and PESQ loss are included as well.
Results
- The results suggest the superior performance of the model over other baselines.
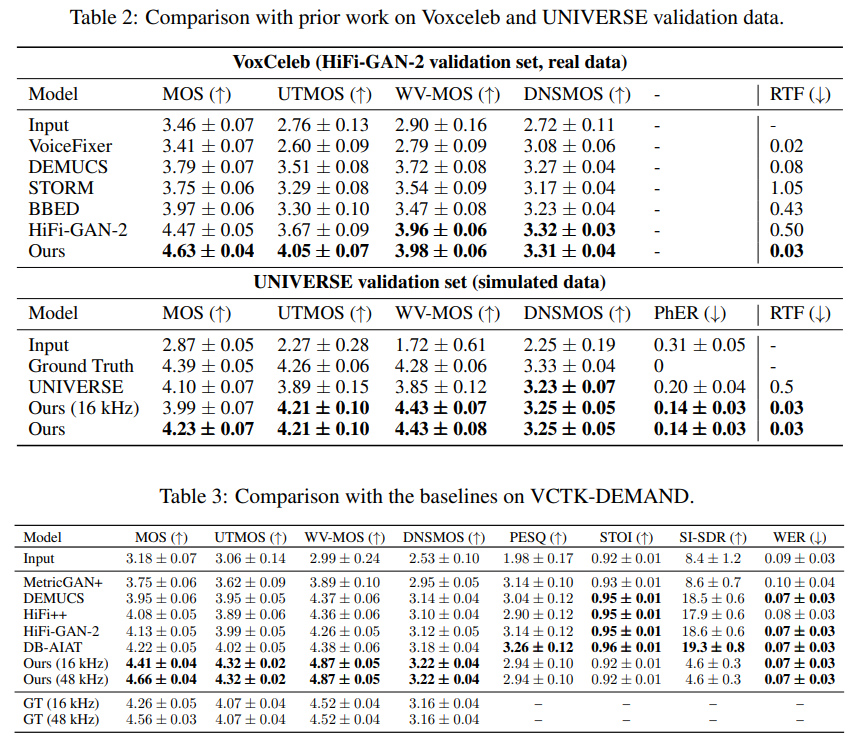
Ablation studies
- The inclusion of HF loss (PESQ and UTMOS) helps in performance increment.
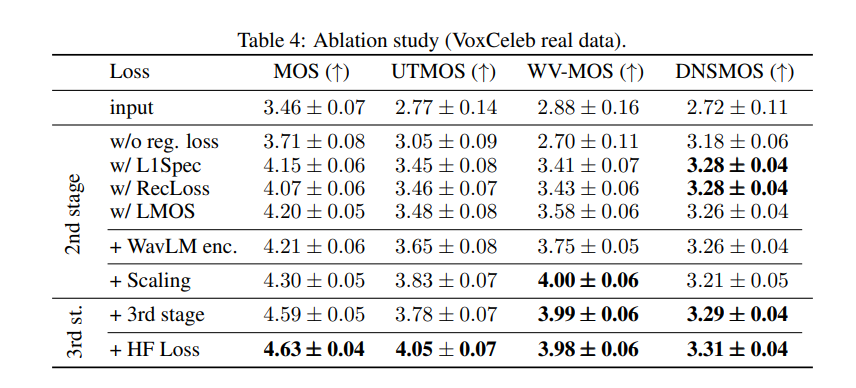
- An extra WavLM encoder helps in performance increment.

Thoughts
- 3-stage training that has different objectives, aligned with the relative weightinig of the loss terms are interesting.
- Clustering rule and SNR rule seem to be sub-optimal tool, since there are so many criteria that makes up a speech quality.

Ad libitum