Paper Review: Voice-ENHANCE: Speech Restoration using a Diffusion-based Voice Conversion Framework
Paper Review
Introduction
- Speech Restoration is a complicated task that deals with multiple acoustic distortions such as reverberation, band-limitation and more.
- Such a complicated task can be simplified if the task is separated into steps.
Proposed Methods
- To address the task, this method GSR first does speaker-agnostic restoration, followed by a mel spectrogram restoration with speaker style injection.
- The restored mel spectrogram is fed into HiFi-GAN to generate a restored speech.
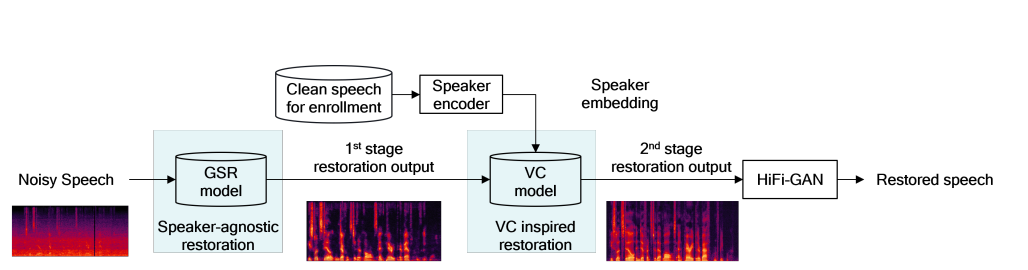
Speaker-agnostic restoration
- A ResUNet based method is used for speaker-agnostic restoration.
VC inspired restoration
-
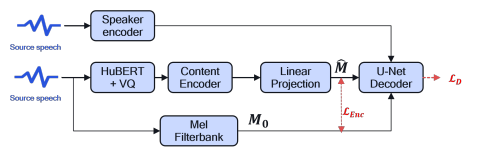
Diff-VC-inspired framework is used.
-
A speaker encoder is ECAPA-TDNN.
-
A content encoder is transformer-based, improved with putting HuBERT-VQ before the content encoder
-
The training is done with the weighted sum of two loss functions, first of which is a reconstruction loss that would make closer to the clean mel filterbank.
-
Second loss is a diffusion loss that make the final output mel spectrogram that was fed with both the speaker embedding and the content embedding closer to the clean mel filterbank.
Results & Experiments
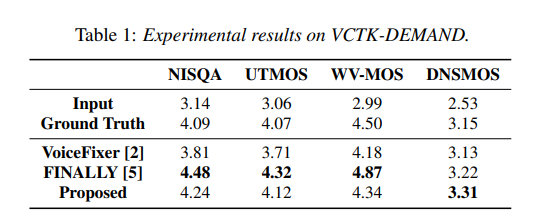
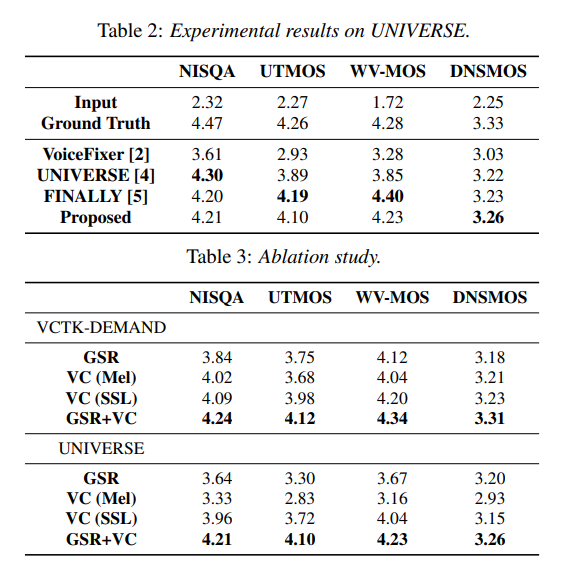
Thoughts
-
The authors highlight that VC-inspired step helps restore many of the damaged speech components. They don't say that the step actually ensure the style-injection. Then is speaker-agnostic restoration really speaker-agnostic? How can you tell that the tasks are decoupled?

Water damage can escalate quickly, turning a minor leak into a major problem within hours. Mold growth, structural weakening, and electrical hazards are just a few of the dangers. That’s why calling professionals right away is essential. They have the tools and expertise to assess and address the damage fast. In cases of flooding or extreme weather, Storm damage cleanup becomes even more critical. Waiting can lead to costly repairs and long term health risks. Protect your home and family don’t wait. Immediate professional intervention can make all the difference in restoring safety and preventing further destruction.