<Scaling Laws in Patchification: An Image is Worth 50,176 Tokens and More> Paper Review
Paper Review
Introduction
Vision Transformer (ViT) encoding a 224 224 image and Vanilla Transformer encoding a 196 characters result in the same size of feature map when processed into 'patchify' stem.
Generally speaking, 224 224 image contains much richer information then 196 characters. However, there is no intended discrepancy on the size of feature map between those two modalities.
Patchify operation entails surprisingly big amount of information loss with its magnitude scaling up consistently with the size of patch (the amount of compression).
Findings
Before it all starts, the authors have tested on two types of the token mixer (usually MLP, Attention, Mamba, CNN or more). Attention and Mamba.
The only thing the authors have tested was the size of the patchify stem.
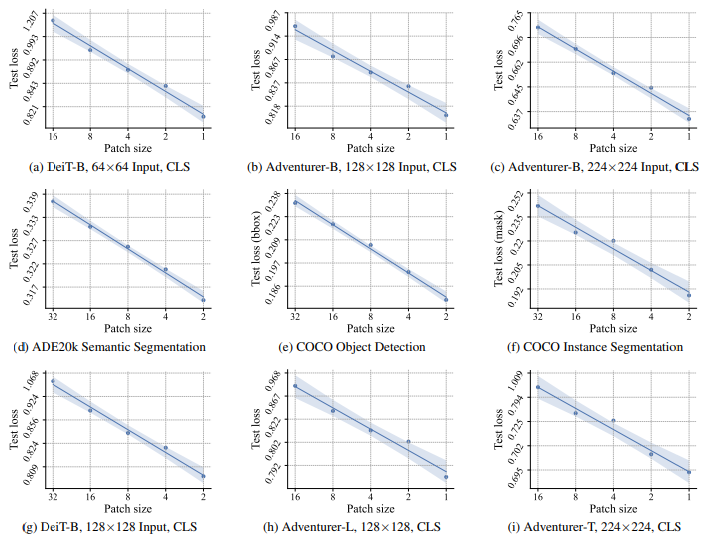
As patch size gets smaller, loss on various tasks ranging from classifcation, semantic segmentation and more made a consistent decrease.
A fun thing is, a pixel-wise patchify (patch size 1) returned the lowest loss, suggesting that a 'patch-free' network can be powerful.
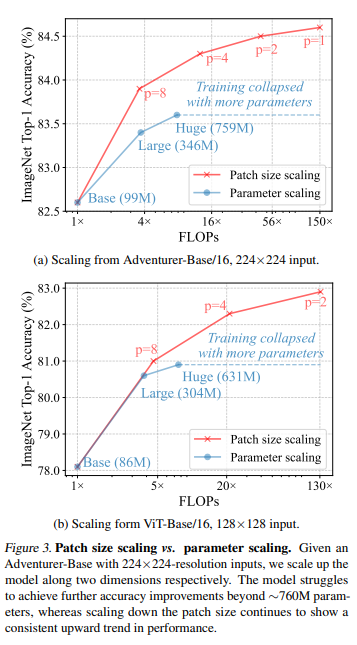
The figure above suggests even more fruitful results.
If you have to scale up parameter sizes to make your model more powerful, you should rather decrease the amount of compression, reducing the patch size.
The red line is about scaling patch size smaller and smaller to make the model expressivity stronger, whereas blue line is scaling up parameters, often through deepening layers, increasing the feature dimension and more.
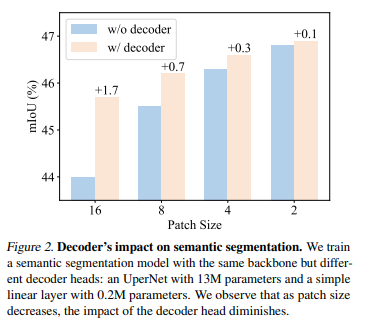
One fun fact also lies in the figure above. A linear layer for prediction (decoder) loses its power when the patch size gets smaller (compression is lesser), suggesting that the role of decoder is to reduce the spatial compression rate, which is not necessary when the patch size is super small.
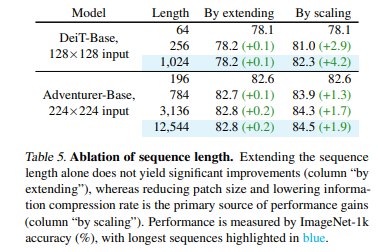
Last but not least fun fact from the figure above is that the reason for the performance improvement from reducing the patch is not primarily from the increased sequence length to be processed in a token-mixer, but the ability not to lose all the useful information at the first glance. 'By extending' refers to the same size of patch, but increased length of input through proper interpolation. And it returned marginal impact. "By scaling" refers to the different size of patch, naturally leading to increase the length of input.
Conclusion
Modern hardwares such as A100 gpus are nowadays prevalent. A modern deep learning framework that exhibits near-linear complexity for the sequence length is also prevalent (e.g., mamba). Why not try 'patch-less' architecture that does not dismiss the useful information to bring up the model performance?
