Introduction
-
Studies on Speech Enhancement usually were performed on Time-Frequency (T-F) domain since the patterns of noise could be easily distinguished in TF domain.
-
Early works on T-F domain speech enhancement try to train in a way that the model predicts the amplitude of the target speech, usually through T-F masking.
-
However, as the above mentioned methods usually made use of the noisy phase in its reconstruction phase, the recovered target speech often had artifacts (since phase is also distorted when a noise or possibly any type of disturbance occur in a clean speech. )
-
Thus, DNN-based methods to estimate both the real and imaginary parts of the ideal-ratio mask has been proposed (to name it, cIRM), which also entailed problems that the structure does not exist in phase spectrogram. The figure below supports this idea through the experiment that the noise in various frequency distorted the phase, and the model trained with cIRM target could not possibly recover the phase mask (the imaginary part) when relatively difficult type of noise was given to the signal.

- Motivated by the above storyline, this paper proposed Phase and Harmonics Aware Speech Enhancement Network (PHASEN), the model that tries to use the predicted amplitude to guide the prediction of phase, or vice versa. This paper proves that phase information has much of a mutual information with the amplitude information, empirically.
Phasen architecture
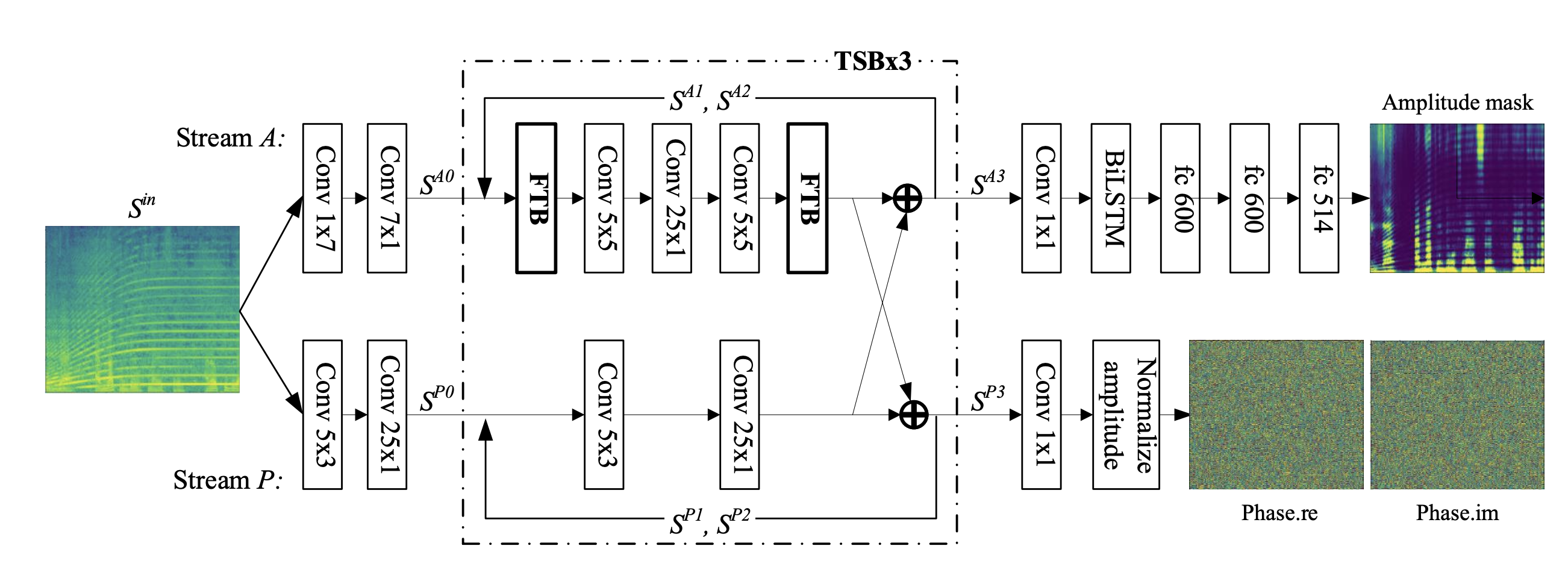
The key componenets of the Phasen architecture are (1) Two-stream blocks (TSBs) and (2) Frequency Transformation Blocks (FTBs).
Two-stream blocks (TSBs)
The basic idea is to separate the predictions of amplitude and phase. The network sends its input to two independent (that becomes dependent later) streams that tries to predict the amplitude and the phase.
Note that at the end of the stream, two branches exchange their information. The communication of information is analogous to the frequently-used dot-product attention mechanism written below.
Frequency Transformation Blocks (FTBs)
Another key component is FTBs. CNNs commonly used in speech enhancement task do not often capture the harmonic correlation that is present in the noisy signal. Stacked CNNs can 'implicitly' capture the correlation through increased receptive field, but not as definite enough. (U-Net based methods in Time domain can handle this issue automatically)
However, harmonic correlation gives a big hint to predicting a enhanced speech. Thus, the authors introduce the concept of FTBs to handle the frequency-wse global correlation.
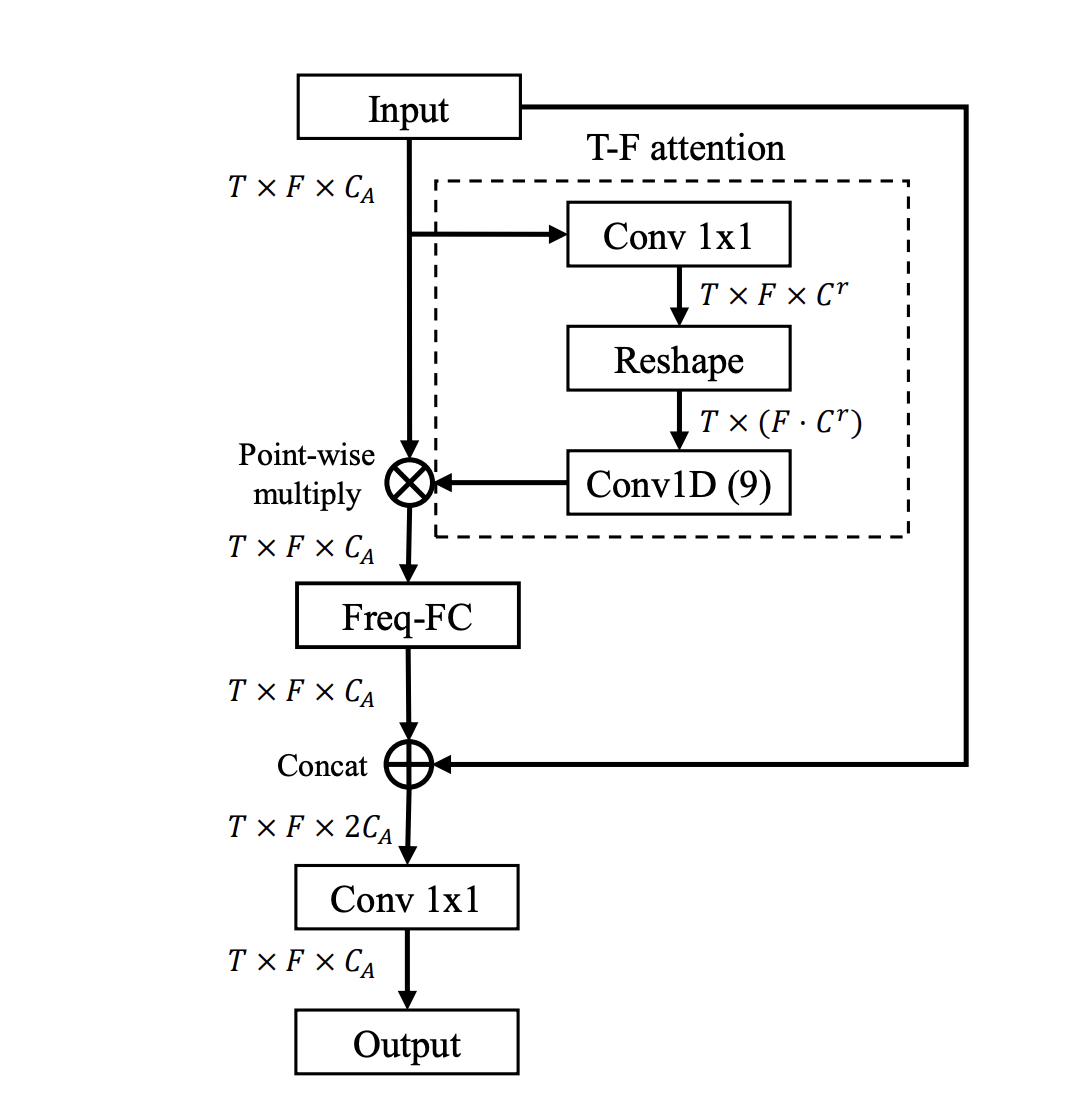
The key component in the proposed FTBs is the presence of Freq-FC. In the derivation of Freq-FC, every time step (time bin in spectrogram) is computed independently.
From the above equation, is a input freature that goes in to Freq-FC module. represents the Freq-FC process which consists of a dot product between a learnable frequency transformation matrix (FTM) and the input feature every time step . The resulting tensor holds the global information from the whole frequency bins. Lastly, the information is concatenated to build a resulting tensor with improved global connectivity.
Experiments & Results
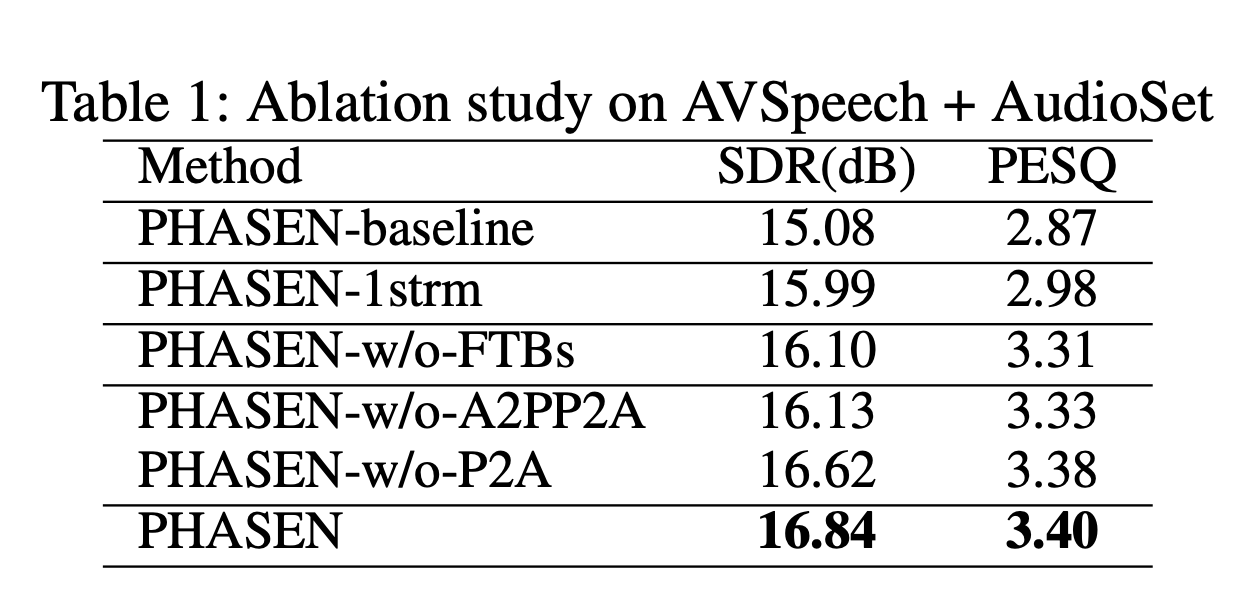
We can infer from the above ablation results that
-
the two-stream networks played a vital role in performance improvement.
-
FTBs also played a vital role in performance improvement (better approach to model the harmonic clue)
-
Information Communication between Amplitude (A) and Phase (P) played a vital role in performance iimprovement.
