아래 작성된 글의 많은 부분은 ffighting.net 자료를 많이 참고했습니다.
1. DDPM - Denoising diffusion probabilistic Models
요약: diffusion loss를 쉽게 만들어서 사용함.
논문링크: https://arxiv.org/abs/2006.11239
Introduction
diffusion 활용도가 계속증가함. text to image에서 많이 사용된다. 여러 모델들과의 결합이 가능하다는 특징이 있다.
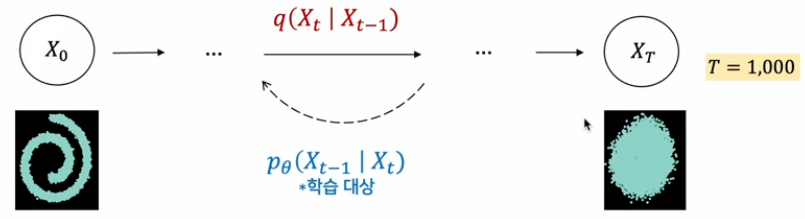
Diffusion: 확산 - 특정한 패턴분포가 점차 와해되는 것을 의미한다.
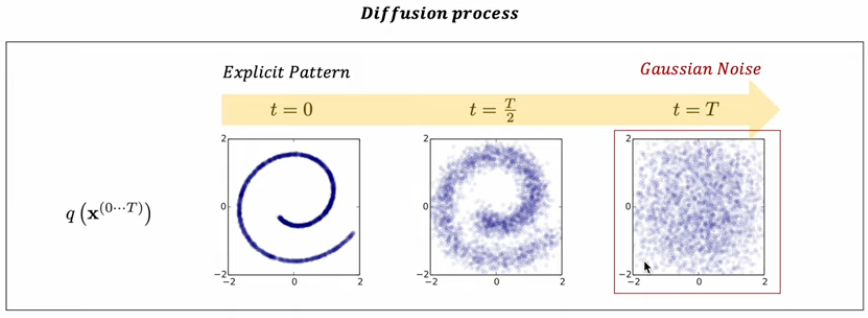
주어진 샘플 데이터의 포인트를 가우시안 분포로 만들어주는 과정이다.
MC: markov chain. markov property: .
Normalizing Flow: 심층 신경망 기반 확률적 생성 모형 중 하나. 잠재 변수(Z) 기반 확률적 생성모형으로서, 잠재 변수(Z) 획득에 ‘변수변환’공식을 활용
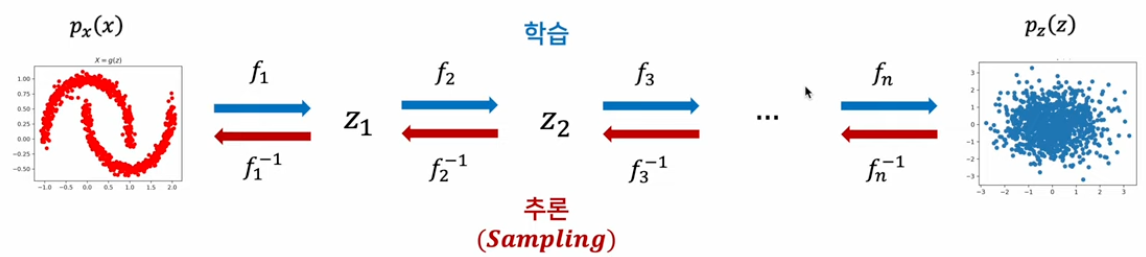
이때 x를 가우시안 분포에 매핑시키는 f 함수를 학습하도록 진행한다. 추론을 진행할 때 f inverse를 통해서 추론이 진행된다.
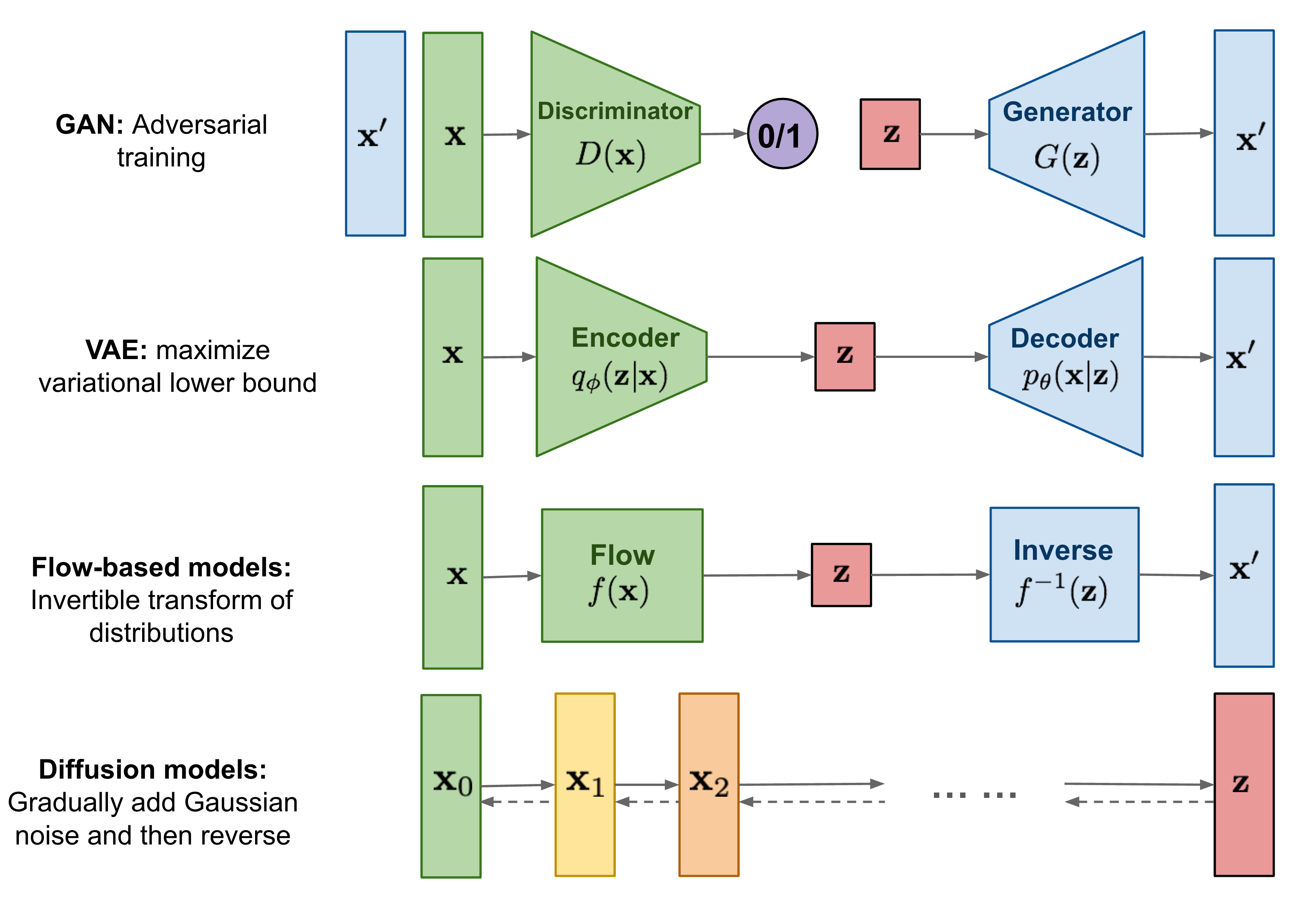
diffusion models의 경우에는 점진적으로 Gaussian noise를 추가한다는점에서 다른 GAN(Adversarial training), VAE(maximize variational lower bound), Flow-based models(Invertible transform of distributions)와 다른 특징이 있으며 반복적 변화를 한다는 점에서 Flow-based models과 비슷하며, 분포에 대한 변분적 추론을 통한 학습이 된다는 점에서 VAE와 유사하다.
Generative Model Overview
Latent variable model: 모든 생성 모델은 latent variable을 사용한다.
생성 모델에서 원하는 것은 매우 간단한 분포(Z)를 특정한 패턴을 갖는 분포로 변환(mapping, transformation, sampling)하는 것
대부분의 생성모델이 주어진 입력 데이터로부터 latent variable(Z)를 얻어내고, 이를 변화하는 역량을 학습하는 것이 목표
VAE: encoder모델구조에 추가해, Latent variable/ encoder/ decoder를 모두 학습할 수 있게 한다.
GAN: 학습된 generator를 통해 latent variable을 특정한 패턴의 분포로 mapping시킨다. generator를 얻기위해서 discriminator를 모델구조에 추가해 generator를 학습(적대적)
Flow-based Model: 학습된 function의 inverse를 이용해 latent variable의 특정 패턴으로 mapping시키도록 학습한다. 생성에 활용되는 Inverse mapping을 학습시기 위해 Invertible function을 학습한다.
Diffusion: latent를 특정 패턴으로 mapping시키는 것이 필요함 . 학습되어야 하는 것 지금까지는 encoder에서는 학습시켜야하는 모델을 제안하는데, 여기서는 Fixed noise schedule을 적용시켜 Diffusion process를 진행하고, 학습대상이 되는 Sampling process는 학습 이 들어가게된다.
ps. DDPM에서는 1000번의 MC 과정을 선정해서 학습이 진행되었다.
Difusion Model
Overview
학습된 데이터 패턴을 새엇ㅇ해내는 역할을 한다. 패턴 생성 과정을 학습하기 위해 고의적으로 패턴을 무너트리고(Noising-Diffusion process), 이를 다시 복원하는 조건부 PDF를 학습한다.(Denoising - Reverse process)
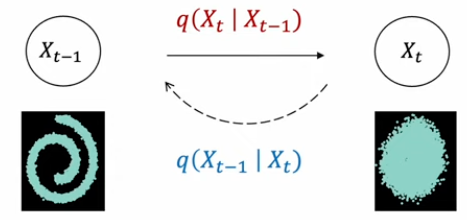
reverse process를 학습한다고한다. 빨간색은 단순히 Gaussian Noise를 주입시키기만 하면 된다. 만약 Diffusion process가 gaussian 이면 Denoising 과정도 gaussian 이다.(1949년에 증명됨)
최종적으로는 Diffusion model은 가 되도록 하는게 목표이고 좌변이 학습대상이다. Difusion은 이러한 과정을 하나의 step으로 진행하지 않고 여러개의 step(e.g. 1000)으로 만들어 진행하였다.
의 학습은 결국 large number of small perturbations을 추정하는 것이다.
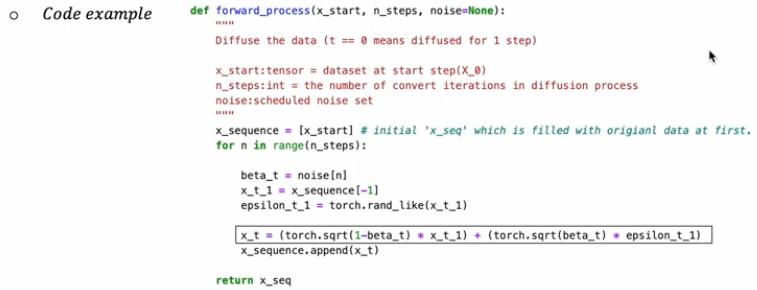
Phase1: Forward
주입되는 gaussian noise크기는 사전적으로 정의되고, 이를 로 표기한다.
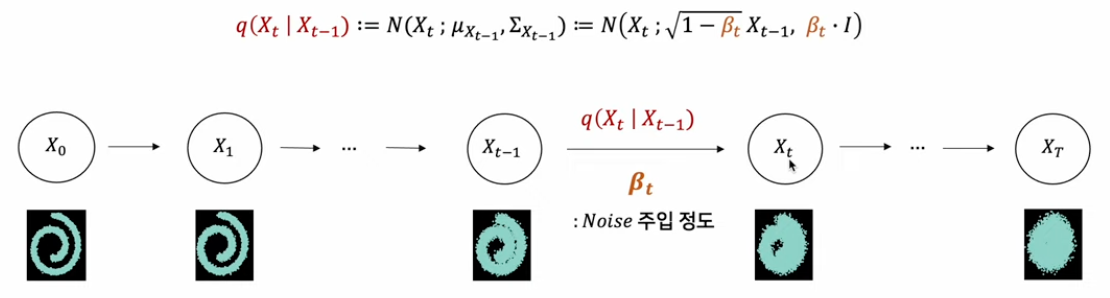
베타는 스케줄링을 사용해 조금씩 변화시키게 되는데 예시로 linear, quad, sigmoid 방식이 존재한다.
이때,
latent variable을 상정한다는 점에서 Hierarchical VAE(HVAE는 전통적인 단일 잠재공간에서 더 계층적으로 만들어 복잡한 데이터를 잘 캡처할 수 있게 한 모델)와 유사한 접근이다.
가장 마지막 latent variable()로 pure isotropic(등방성-방향성이 없는 성질) gaussian 을 획득한다.
phase 2: Reverse Process
diffusion model은 generative model로 학습된 데이터의 패턴을 생성해내는 역할을 한다. Reverse Process는 diffusion 의 역과정으로 생각할 수 있다. 우리가 알지 못하는 조건부 가우시안 분포(평균과 분산)가 학습되어야 한다.
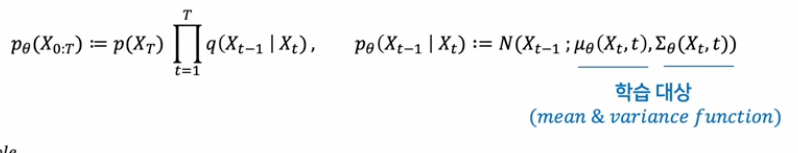
loss 함수
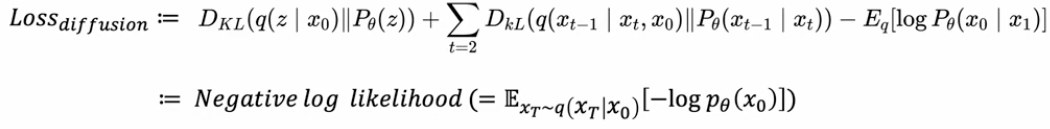
VAE와 Diffusion의 구조 비교 - latent variable 갯수가 다르다는 점이 있다. 이는 loss를 결정하는데에도 결정적인 차이가 존재한다.
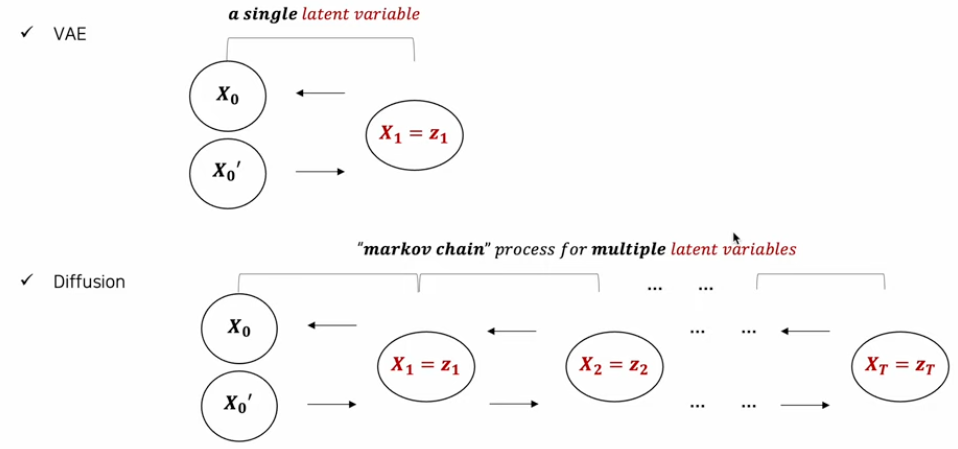
VAE Loss:
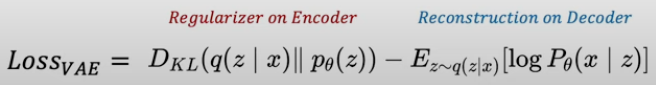
Difussion
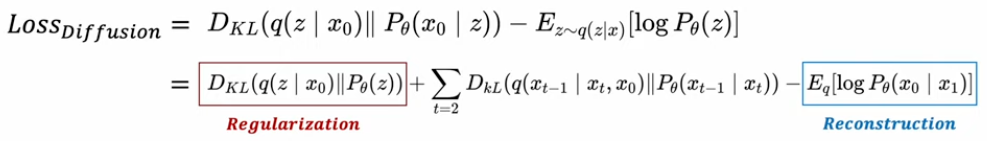
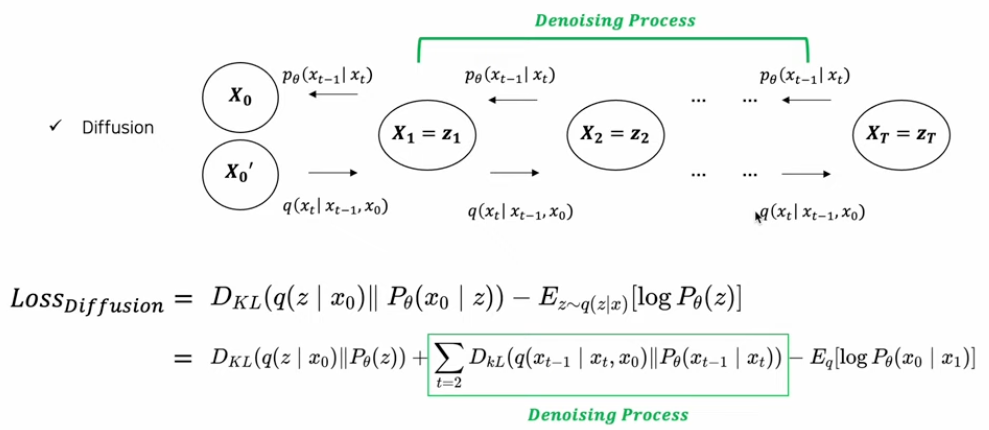
Denoising Diffusion Probabilistic Model

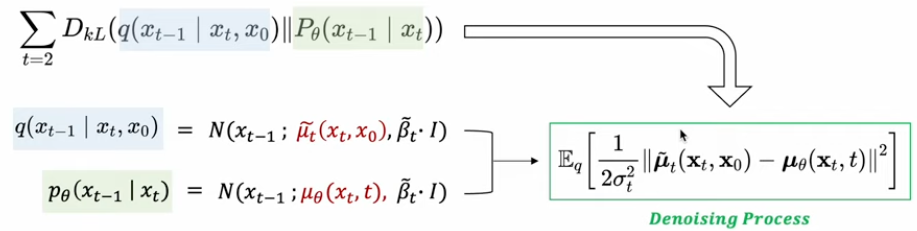
DDPM의 loss term을 보면 각 t라는 시점의 노이즈인 입실론을 model이 예측하게 하는 것이다.
첫번째로 기존 regularization term을 단순히 제외시켜버림. 굳이 학스빗키지 않아도 fixed noise scheduling으로 필요한 isotropic gaussian 획득이 가능하기 때문. 1000번의 step에 걸쳐서 학습시켜본 결과 Linear noise scheduling을 성정 → 최종적인 latent variable()는 다음과 같은 분포를 갖게된다. → 충분한 isotropic gaussian을 확보할 수 있다고 주장함.
두 번째로 denoising process 재구성을 진행함. - Reverse process를 의미하는 부분 (Diffusion process의 역(reverse)과정으로, gaussian noise를 제거해가며 특정한 패턴을 만들어가는 과정)
DDPM 에서는 학습대상으로 평균과 분산을 둘다 학습시키고자 하였다. DDPM이후에는 기존에 denoising시킬 때 사용한 분산인 를 알고있으므로 그 상수텀을 똑같이 reverse과정에서 사용하고자 하였다. → 그래서 학습 대상이 평균만 학습시키면 된다. mean function 추정과정은 아래와 같이 식을 다시 쓸 수 있다.
2. CLIP
요약: text, image data pair를 방대하게 만들어 representation을 잘하는 모델을 만들어냄
논문링크: https://arxiv.org/abs/2103.00020
2021년 당시 vision model은 transformer을 적용하는 실험이 많았고, NLP의 경우 transformer를 이용해 거대 모델을 만들고 있었다. vision model들은 작은 noise에도 취약하다는 단점을 가지고 있다. 이때 저자들은 image data를 방대하게 만들어 해당 문제를 해결하려 했고, 이때 문제는 labeled data가 부족하는 점이다.
본 저자는 image data에 label을 달아주기 위해 언어모델을 SL 하기로 하고 인터넷에 있는 대용량의 데이터를 바탕으로 언어모델이 label을 달게 했다. → 4억장의 이미지-자연어 데이터셋을 구축하였다.
두 번째로 이렇게 많은 데이터를 학습시키위해 각각 label을 숫자로 넣어주는 것이 아닌(CE 방식), contrastive learning을 이용했다. 매칭되는 데이터 feature는 가까워지고 다른 feature는 멀어지도록 학습.
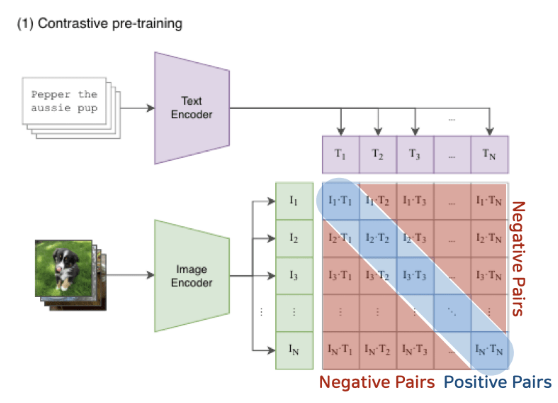
본 논문에서는 CNN 기반 모델 5개와 ViT 모델 3개를 이용하고, 언어모델의 경우 transformer encoder모델을 사용했다. 각 차원을 맞춰주기 위해, 언어모델에서는 linear projection을 진행 하여 image 와 dim 을 맞춰주었다.
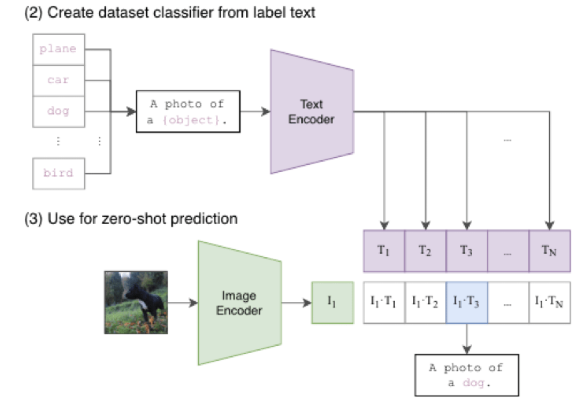
장점: zero-shot prediction
아래의 그림과 같이 처음 보는 사진에 대해 feature를 추출한 후 text를 바탕으로한 feature를 추출한다. 이때 문장을 생성하면서 해당 그림이 뭔지 다양한 텍스트로 설명가능하게 학습되었기 때문에 zero-shot으로 예측이 가능해진다.
조금 더 구체적으로 살펴보면 세부적인 표현 학습이 필요한 Fine Grained Classification 데이터셋에서는 성능이 안좋고, 반대로 일반적인 표현 학습만으로 풀 수 있는 데이터셋에서는 성능이 좋은 모습을 보이고 있습니다. 이러한 결과는 매우 고무적이라고 할 수 있는데요. 왜냐하면 모든 데이터셋에서 좋은 결과를 낸 것은 아니지만 Label 데이터를 전혀 사용하지 않고도 Label 정보를 사용하여 학습한 동일한 모델보다 더 좋은 성능을 보여주고 있기 때문입니다.
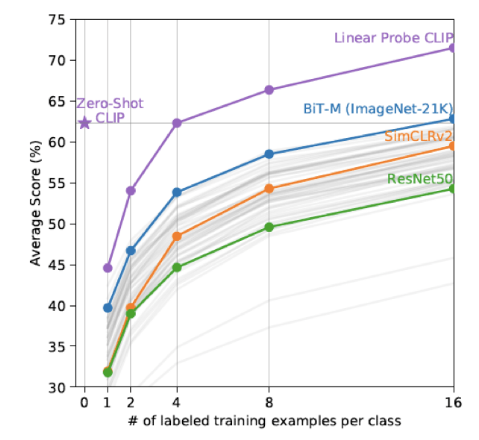
x축은 Linear Probing에 사용한 클래스당 데이터 개수를 의미합니다. 사전 학습이 완료된 상태에서 몇개의 대표 데이터만을 사용하여 Classifier를 학습했을때 누가 더 성능이 좋은지를 비교
CLIP의 Zero Shot 성능은 클래스당 4개의 데이터를 학습한 CLIP 모델과 비슷한 수준이고, 다른 모델들은 더욱 많은 데이터셋을 학습해야 낼 수 있는 수준의 성능
robustness: CLIP 모델이 기존 Vision Model들보다 ‘성능’ 이 더 우수함을 실험을 통해 확인했습니다. 이때의 성능이란 얼마나 더 많은 표현을 학습했는지를 의미하는데요. 대표적으로 방금 살펴본 Linear Probing 테스트를 예로 들 수 있습니다. 하지만 Vision Model들의 한계는 성능에 있지 않은데요. 이들 모델의 공통적인 한계는 Robustness가 현저하게 떨어진다는 점입니다. 예를 들어 학습한 데이터셋에서 노이즈가 조금 섞여 들어간다거나, 텍스쳐가 변한다면 성능이 아주 크게 하락하곤 합니다.
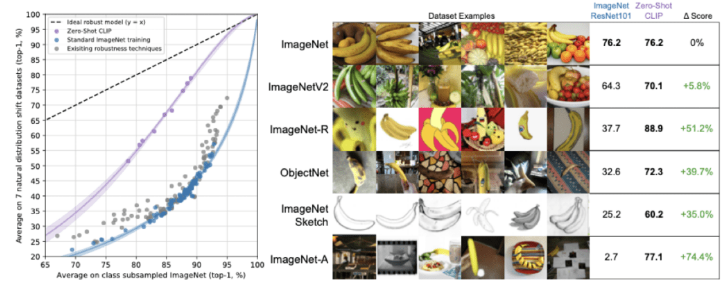
위 그림은 ImageNet에 약간의 변형을 준 데이터셋에 대한 성능을 비교한 자료입니다. 기존 ImageNet과 달리 스케치 형태의 데이터이거나 Adversarial Attack이 추가된 형태
Adversarial Attack이 추가된 ImageNet-A 데이터셋에서도 기존 ResNet[2]은 성능이 크게 하락한 반면, CLIP 모델은 다른 데이터셋에서와 비슷한 성능
3. SR3 - Image Super-Resolution via Iterative Refinement
요약: diffusion post processing에서 사용되는 해상도를 높이는 diffusion 학습방식
논문링크: https://arxiv.org/abs/2104.07636
SR3는 Super-Resolution을 위한 Diffusion Model이다 Super-Resolution은 Low Resolution 이미지를 High Resolution이미지로 복원하는 기술을 의미한다. SR3는 기존 Diffusion Model의 방법을 그대로 사용하면서 Super-Resolution에 응용한 논문이다.
Method
diffusion model의 구성은 기존 모델들과 같은 UNet구조를 사용한다.
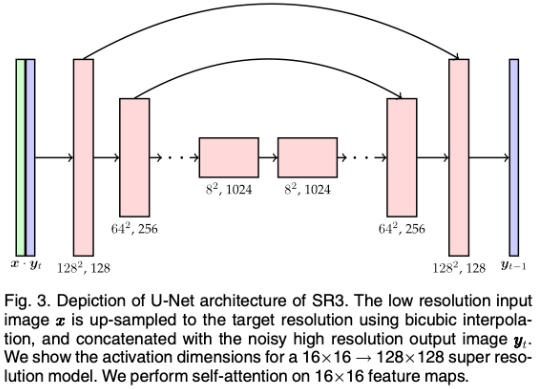
본 논문에서 제안하는 방법은 High Resolution 이미지를 생성하도록 학습해야한다. 이를 위해 Low Resolution 이미지로부터 High Resolution 이미지를 생성하는 Super-Resolution모델을 만드는 것이 목표이다.
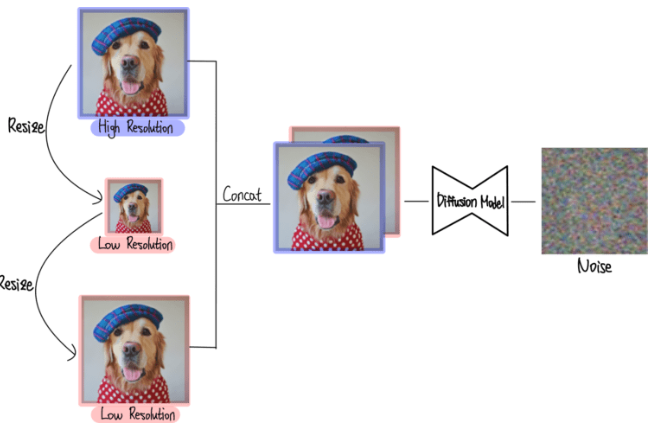
Low Resolution 이미지는 resize2번을 통해 만들어 주고 high Resolution 과 Low Resolution이 concat되어서 diffusion 모델에 들어가 학습하게 된다. diffusion 모델의 입장에서는 Low Resolution을 condition으로 하여 high Resolution을 만들어주게 된다.
Conclusion
Super-Resolution 기술은 이미지 생성을 위한 Diffusion Model에서 거의 필수적으로 사용된다. 왜냐하면 Diffusion 자체가 computation이 높아 high resolution을 직접 생성하기 어렵기 떄문이다. Low Resolution을 생성한 후 Super-Resolution 모델을 이어 붙여 최종적으로 High Resolution 이미지를 만들어준다.
4. Classifier Guidance(ADM) - Diffusion Models Beat GANs on Image Synthesis
요약: Condition을 반영해주기 위해서 classifier 부분을 만들고 학습 → freeze 후 guidance를 diffusion model의 noise로서 주면서 모델학습진행
링크: https://arxiv.org/abs/2105.05233
본 논문은 ADM(Ablated Diffusion Model) 또는 classifier Guidance라는 별칭으로 불린다.
Classifier Guidance 이전에 다양한 Diffusion 모델이 있는데 이들은 공통적으로 Condition을 반영할 수 없다는 단점이 존재한다. GAN의 경우 2014에 발표 후 곧바로 Conditional GAN이 발표되었다.
Condition 반영이란? 모델이 정보를 기반으로 새로운 데이터를 생성할 때 조건(Condition)은 이미지에 나타나야 할 특정 텍스트 설명일 수 있다. +) 색상, 크기, 스타일, 고양이, "해변에서 서핑을 하는 사람의 이미지를 생성하라”등의 텍스트 입력 ⇒ 다시말해 제어가능성과 다양성을 추가시킬 수 있게된다.
본 논문에서는 Diffusion model에서는 처음으로 class 정보를 condition으로 입력받아 해당 class 이미지만 생성할 수 있는 diffusion model을 제안한다. 이 때 별도의 Classifier를 학습시켜 이로부터 나오는 Gradient를 활용한다.
Method
Architecture의 개선을 통한 성능향상
기존 Diffusion Model은 전부 UNet 구조를 사용한다. Classifier Guidnace에서도 UNet구조를 동일하게 사용하면서 몇가지를 개선한다. 먼저 Depth를 증가시켜주고 Attention head를 늘려준다. 기존에는 8X8 사이즈에만 적용했는데 이를 16X16, 32X32에도 적용해준다. BigGAN의 Residual Block을 차용해 Rescale Connection(Residual Connection에 스케일링 인자 도입)기법을 사용한다. 또한 Adaptive Group Normalization(Batch Normalization의 변형으로 feature map의 그룹마다 정규화를 수행한다. - Adaptive인 것은 모델이 학습하는 동안 정규화 파라미터를 데이터에 맞게 조정 가능) 을 적용한다.
Classifier Guidance
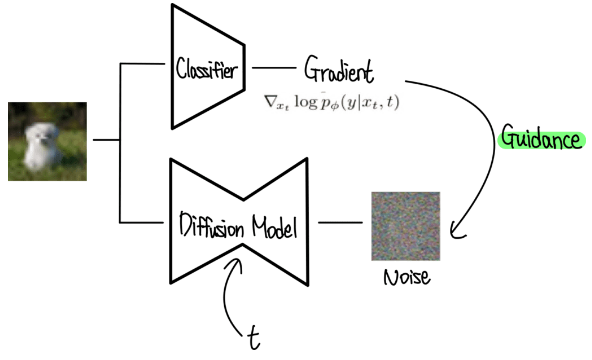
https://ffighting.net/deep-learning-paper-review/diffusion-model/classifier-guidance/
Classifier Guidance는 Classifier를 이용해 Guidance효과를 내줌. 먼저 classifier를 학습(입력은 noise image)해주고 classifier부분을 freeze 후 diffusion model을 학습시킨다. classifier로부터 입력 이미지에 대한 해당 클래스의 gradient가 나오고 이는 noise에 영향을 준다. 기존 diffusion model의 학습방법과 동일하게 학습하되, classifier로부터 나오는 gradient가 예측한 noise를 추가한다.
이를 통해서 기존 diffusion model과 달리 예측한 noise에 classifier로부터의 gradient가 반영된다.
(이러한 방법이 왜 Class Guidance 역할을 할 수 있을까요? 강아지 이미지를 생성하려고 하는 상황을 가정해볼게요. 이때 Diffusion Model이 고양이 이미지를 생성하는 방향으로 진행되면 어떻게 될까요? Classifier는 Noisy Image Classification을 학습했죠. 따라서 Noisy 고양이 이미지에 대해 큰 Gradient를 줄겁니다. 이 Gradient는 Diffusion Model의 Output Noise에 강아지 이미지를 생성하는 방향으로 반영되는거죠.)
Experiment
table4: model별 image generation 성능

Conclusion, Limitation
Classifer Guidance(ADM)은 class를 condition으로 입력받을 수 있는 방법을 제안
하지만 아직까지 GAN보다 느린 속도와 Labeled Dataset만 사용할 수 있다는 한계
사용하기 위해서 별도의 Classifier를 학습해야한다는 한계
5. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
요약: patch를 이용해서 학습, 빈칸부분을 만들어서 생성하도록 하는 diffusion 방식을 제안
링크: https://arxiv.org/abs/2112.10741
Open AI에서 발표한 Text Guided Diffusion Model 이다. Text Guided Diffusion Model은 Condition으로 Text가 들어가는 Diffusion Model을 의미한다. 기존에 Condition으로 class정보가 들어갔었다. 이는 (이미지, class)pair로 구성된 데이터셋에 대해 동작한다. 반면 text guided diffusion model은 class가 아닌 설명하는 text, 즉 caption을 condition으로 받는다. 따라서 LAION같이 (이미지, caption) pair로 구성된 데이터셋을 사용한다. 이는 새로운 개념의 이미지를 생성할 수 있다는 점에서 매우 큰 장점을 가진다.
Method
전체 아키텍처는 caption을 바탕으로 transformer 모델을 통해 text embedding을 만들어주고 이를 diffusion 모델에 주입시킨다. 이를 바탕으로 생성되는 이미지는 64X64로 low resolution을 생성하게 하고 두번 째 diffusion을 통해 high resolution을 통과해 256X256 이미지를 만들게 된다.

이는 diffusion model뿐만 아니라 transformer를 통해 나온 text embedding또한 학습시켜야한다. 이후 모델에서는 pretrained LLM을 사용하여 text embedding을 추출하게된다. 이후 모델들에서 pretrained 모델의 사용은 성능의 큰 차이를 가져오게된다.
다음으로 256X256으로 키워주는 과정은 SR3논문에서 사용한 방식을 통해 upscale을 진행해준다.
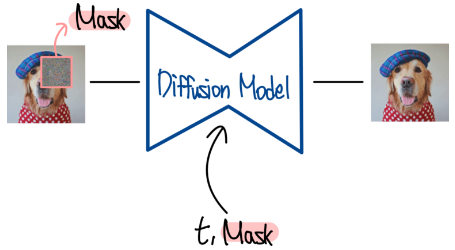
GLIDE에서의 학습방식을 Inpainting방식을 통한 finetuning 방식을 제안한다. Inpainting 방식은 이미지의 masking을 주입한 후 다시 채워 넣는 기술이다. 따라서 입력으로 masking된 이미지가 들어가게 된다. 그리고 condition으로 해당 masking에 대한 정보가 주어지게 된다. diffusion 모델은 이를 각각 입력과 condition으로 받아 복원하도록 학습하게된다. 학습된 모델은 maksing된 이미지가 들어왔을 때 maksing내부를 채워넣게 된다.
기존에 없는 개념인 text가 설명하는 이미지를 생성하는 모습을 볼 수 있다.

Inpainting을 사용해서 점점 복잡한 이미지를 생성하는 모습 DALLE 와 비교.
Conclusion
GLIDE는 text guided diffusion model의 대표적인 최초의 모델이다. 한계로는 256X256 사이즈 이미지만 생성할 수 있다는 한계가 존재한다. 이후에는 이부분을 더 개선하는 모습의 논문이 존재.
6. Classifier-Free Diffusion Guidance
요약: 기존 classifier 모듈이 따로 있어야한다는 단점이 존재하는 부분을 해결한 논문. PE 와같은 방식으로 Condition을 diffusion model에 class condition으로 주입함
논문링크: https://arxiv.org/abs/2207.12598
기존 classifier guidance에서는 classifier를 추가하는 방식으로 학습을 진행하였다. 본 논문은 classifier없이 guidance를 할 수 있는 방법을 제안한다.
Classifier Free Guidance
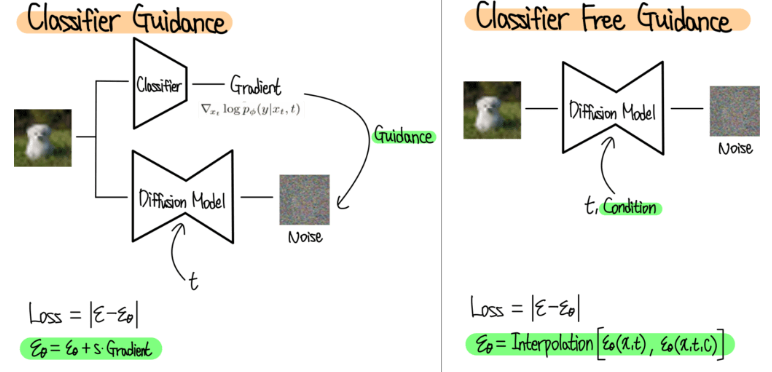
Ref: https://ffighting.net/deep-learning-paper-review/diffusion-model/classifier-free-guidance/
위 그림은 두가지 방식의 비교하고 있다. Noisy Image를 학습한 Classifier로부터 Gradient를 계산하게 되는데 이는 Diffusion Model이 생성한 이미작 원하는 class 이미지가 아닐 경우 큰 Gradient가 반영되어 이미지를 수정하도록 유도하는 방법이다.
오른쪽 그림은 class에 해당하는 Condition 정보를 Diffusion Process 정보인 t와 함께 주는 모습이다. 원래 Diffusion Model에서는 t를 position encoding 방식을 통해 Condition으로 입력하는데 유사한 방식으로 Class 정보를 Diffusion Model에 입력해주는 것이다. 이렇게 Diffusion Model은 Condition을 받았을 때와 받지 않았을 때 두 가지 Noise를 예측하게 되고 최종적으로 둘의 Interpolation을 통해 최종 예측 Noise를 계산한다.
Conclusion
본 논문은 Classifier Free Guidance라는 별도의 classifier없이도 guidance를 할 수 있는 방법을 제안하는것에 의의가 있다. → 이후 diffusion모델에서는 대부분 classifier free guidance방식을 사용한다.
7. Stable Diffusion - High-Resolution Image Synthesis with Latent Diffusion Models
요약: diffusion의 양옆에 encdoer decoder를 추가해 resolution이 바로 가능하도록 하며, computation이 감소, 성능향상에 효과적
논문링크: https://arxiv.org/abs/2112.10752
이전 모델들의 한계는 저화질 이미지만을 생성할 수 있다는 특징이 있다.(SR3 제외) 이때문에 저화질 이미지를 upscale 하기 위해 Super Resolution모델을 따로 학습한 후에 붙여줘야한다. 이러한 문제는 이미지 픽셀값을 바로 생성해야 하는 diffusion model의 근본적인 문제로부터 기인한다.
GAN과 Autoencoder는 bit rate가 비교적 큰 perceptual한 부분을 학습하는데 주력한다. 반면 diffusion model은 bit rate가 작은 None perceptual한 부분을 하긋ㅂ하는데 초점을 맞추고 있는 모습이다. 따라서 stabel diffusion은 이러한 부분을 개선하여 perceptual한 부분에 초점을 맞춰 학습하는 diffusion model을 제안한다.
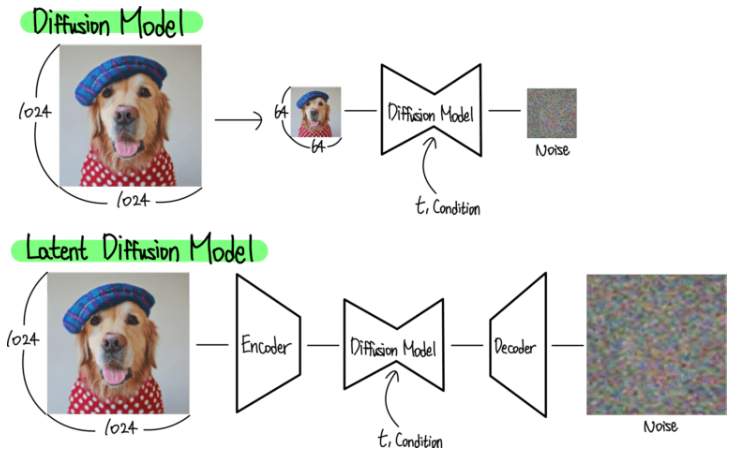
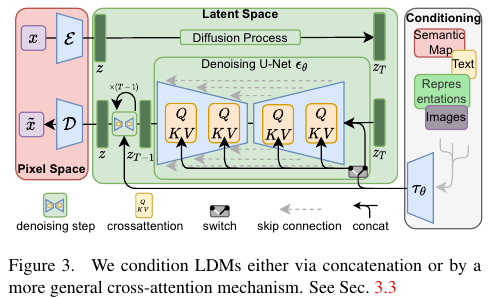
다음 과같은 메서드는 크게 diffusion model 사이에 encoder, decoder가 추가된 것을 볼 수 있다. 이는 논문에서의 figure를 보면 아래와 같다.
+) Perceptual Loss: 1. Feature Reconstruction Loss, 2. Style Reconstruction Loss
1) 목표 이미지와 생성된 이미지가 같은 고수준 특징을 갖도록 하는 것을 목표로 한다. 이를 위해 두 이미지를 신경망에 통과시켜 얻은 중간 레이어의 활성화(feature map) 을 비교한다. 이러한 중간 레이어는 이미지의 고수준 특징내용을 포착하기 때문에, 두 이미지의 이러한 특징맵이 유사하다면, 두 이미지도 비슷한 고 수준의 내용을 갖는다고 볼 수 있다. feature reconstruction loss는 이 특징 맵 사이의 차이(L2거리 사용)를 최소화 하려고한다.
2) 목표 이미지의 스타일을 생성된 이미지에 전달하는 것을 목표로 한다. 이러한 스타일 (색상 분포, 질감, 패턴) 등은 특징 맵의 상관관계 (그람 행렬) 를 통해 수량화 될 수 있다. 목표 이미지와 생성된 이미지의 그람 행렬 사이의 차이 (보통 L2거리 사용)를 계산하여, 생성된 이미지가 목표 이미지와 비슷한 스타일을 갖도록 한다.
p.s. 그람행렬 (Gram Matrix)는 벡터공간에서 백터 집합의 내적을 모은 행렬이다. 스타일 전송에서 그람행렬은 feature map의 상관관계를 계산하여 이미지의 스타일을 수량화 한다.
위 이미지의 빨간색 부분은 autoencoder부분을 의미한다. 그리고 가운데 초록색은 LDM 을 표현하며, 회색부분은 condition입력 부분을 나타낸다. 저자들은 auto encoder를 학습하는 과정을 perceptual image compression이라고 표현한다. 이는 기존의 auto encoder학습 방법과 동일하게 perceptual loss를 사용하여 이루어진다. 이렇게 학습된 auto encoder 덕분에 diffusion model은 autoencoder로부터 출력되는 latent embdding을 생성하도록 학습할 수 있다.
LDM(latent diffusion model)
기존 DM:
제안하는 LDM:
픽셀값 x에서 latent embedding z가 입력값으로 들어간다. Auto Encoder로 정보를 압축해준 덕분에 high frequency와 사람 눈으로 인식이 안되는 Noise성 정보들은 제거 (이미지를 latent embedding - 로 변환할때 불필요한 세부사항들은 무시한다는 의미 )되었다고 볼 수 있다. 따라서 좀더 semantic한 부분에 집중할 수 있으면서 계산복잡도를 줄일 수 있다. (이미지의 의미있는 요소들에 집중할 수 있다는 뜻)
conditioning
회색부분에서 들어오는 text 정보등을 사용할 때 기본적으로 PLM 으로 text embedding을 만들어주고 와 text emb의 정보를 고려하기위해 Cross Attention을 사용한다.
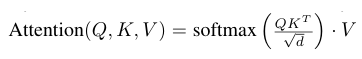
cross attention까지 적용된 최종 stable diffusion loss function은 아래와 같다.
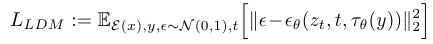
Experiment
text to image

super resolution - SR3, inpainting - GLIDE, layout to image (bounding box 정보와 class정보를 넣어줄 때 이미지를 생성하는 방법) 또한 condition으로 받을 수 있다.
8. Imagen - Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
요약: pre-trained 언어모델을 사용하기 시작함 이를 통해 언어에 대한 이해된 모델로 부터 diffusion model을 학습시킬 수 있게 되었음.
논문링크: https://arxiv.org/abs/2205.11487
Introduction
Imagen에서는 GLIDE 논문뒤에 나온 논문으로 text guided diffusion model이다. GLIDE에서는 caption(text)에 해당하는 부분이 따로 diffusion model에 주입되는 방식으로 학습이 진행되었다는 특징이 있고 해당 논문에서는 pre-trained 된 text encoder모델을 사용했다는 특징이 존재한다.
Method

ref: https://ffighting.net/deep-learning-paper-review/diffusion-model/imagen/
위 그림에서 3가지의 모듈을 볼 수 있다. 첫 번째로는 text encoder 부분이고, 두 번째로는 text to image difussion model 마지막으로 cascaded diffusion model이다.
text encdoer 모듈은 사전학습된 text 모델(bert)를 가져와 사용한다는 특징이 존재하고 이를 바탕으로 text to image diffusion model에 text 정보를 넣어주게 된다. 마지막으로는 연산량이 많은 단점을 극복하고자 작은 64X64 픽셀에서의 이미지 생성후 1024X1024까지 resolution을 키워주는 방식이다.
기존 GLIDE논문에서는 text부분이 따로 떨어져 있는 것을 확인할 수 있는데 이는 언어를 완벽하게 이해하지 못한 모델이 diffusion model에게 이미지 생성을 지도한다는 모순적인 부분이 존재한다. 또한 당연히 해당 모델에서는 classifier free guidance 방식으로 학습이 진행된다.
classifier free guidance 방식은 한가지 문제가 존재한다. 바로 guidance weight가 일정수준 보다 커지게되면 픽셀 값들이 포화상태가되어 온통 검정색으로 변하게된다는 것이다. 이를 해결하기 위해 저자는 static threshold방식과 dynamic threshold 방식을 제안했다. 첫 번째 방식은 간단하게 픽셀 값에 threshold를 정해놓고 이범위를 넘어가면 잘라주는 방식이다. 반대로 dynamic threshold 방식은 픽셀값에 대한 threshold를 dynamic하게 변하게 해주어 그 기준 값을 넘어가면 잘라주게 하는 방식을 사용하였다.
Super Resolution Diffusion Model
Upscale 하기 위한 방식으로 SR3논문과 같은 방식으로 해상도(resolution)을 증가시키는 방식을 사용하였다.
Conclusion
본 논문은 2개의 super resolution 과 pretrained llm을 사용해 좋은 결과를 낼 수 있다.
9. Hierarchical Text-Conditional Image Generation with CLIP Latents
요약: CLIP 사용한 image generation (DALLE2)
논문링크: https://cdn.openai.com/papers/dall-e-2.pdf
본 논문은 DALLE의 후속버전
본 논문은 이미지 생성을 위해 CLIP과 같은 contrastive model을 바탕으로 robust함을 살려 representation을 잘 학습시킬 수 있다는 점을 사용한다. 본 논문에서는 이미지 생성에 활용하기 위해 2-stage model을 제안한다.
1. prior: text로 CLIP image embedding을 생성 (AR-autoregressive / diffusion model실험)
2. decoder: prior의 image embedding을 condition으로 받아, diffusion model로 이미지 생성
해당 방식으로 caption이 주어졌을 때 caption과 유사성을 높게 유지하면서 시각적으로 사실성이 높은 이미지를 생성할 수 있다는 특징이 있다. 이는 주요 의미와 style을 유지하면서 variation을 가진 이미지도 생성할 수 있다는 특징이 있다.
추가적으로 CLIP은 text-image joint embedding space를 통해 language guided image manipulation을 가능하게한다.
Method
full text-conditional image generation stack이 unCLIP, 이 방식으로 학습한 모델이 DALL-E 2이다.
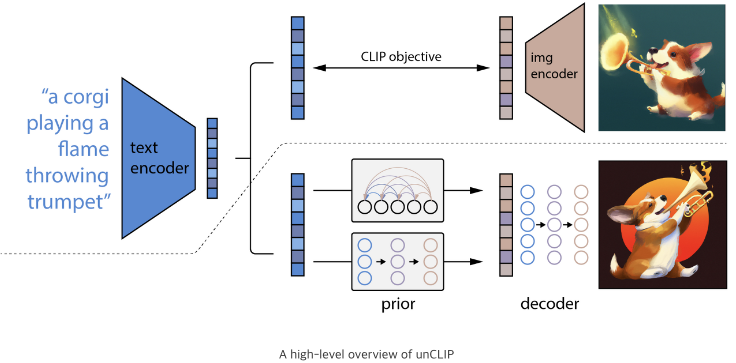
점선 윗부분은 CLIP을 묘사하고 있으며, 사전학습된 CLIP모델을 가져와 사용하고 있다. 점선 아래는 text-to-image 생성 과정을 나타내며, CLIP의 text encoder에서 나온 text embedding을 prior에 넣어 image embedding을 생성한다. 생성된 image embedding과 caption(text)를 이용해 decoder가 최종 이미지를 생성한다. prior와 deocder를 학습시킬 때 CLIP model은 frozen시킨다.
notation.
,
: CLIP img emb, : CLIP text emb,
: y로부터 CLIP img emb 생성(prior),
: prior에서 생성한 로부터 이미지 x 생성(decoder)
모델 : prior, decoder두 구성요소를 쌓아 텍스트 y가 주어졌을 때 이미지 x생성
첫 번째 equality는 img emb 가 이미지 x의 deterministic function이기 때문에 성립한다.
두 번째 equality는 chain rule
prior. -CLIP image embedding 를 생성하기 위함
AR, diffusion 두 방식을 모두 실험해본 결과 diffusion 방식을 채용함
continuous vector()를 캡션 가 condition으로 주어진 Gaussian diffusion model을 통해 재구성 → deocder only transformer로 학습..?
decoder - img emb → img 생성
기존 GLIDE의 architecture를 수정
- timestep emb에 CLIP emb를 projecting & adding
- CLIP embedding을 4개의 추가 tokens으로 projecting한 후 , 이를 GLIDE text encoder출력 시퀀스에 concat
Image Manipulations
unclip 구조를 통해 주어진 이미지 x를 bipartite latent representation()로 인코딩 가능
: CLIP에서 인식하는 img에 대한 정보, CLIP img encoder에 forwarding 해서 얻는다.
: decoder가 img x 를 재구성하는데 필요한 모든 residual information을 encoding, DDIM inversion를 통해 얻음
두 개의 representation(bipartite representation)을 이용한 3가지 manipulation이 존재한다.
1. variations
이미지의 주요한 content를 유지하면서 색감, 색체 등을 변화를 줄 수 있다. (증가할 수록 변화 증가)의 변형을 통해 변형 정도 조절할 수 있다.

2. Interpolations

두 이미지를 blend 할 수 있다. 두 이미지 에 대해서 두 개의 CLIP img emb을 라고 하면, 가운데 있는 이미지들은 두 CLIP 이미지 emb 공간사이 concept을 탐색하는 과정
이를 위해 spherical interpolation을 이용해 intermediate CLIP representation 를 얻을 수 있다. 는 0~1 사이 값, 이렇게 만든 representation을 decoder의 condition으로 전달해 위와 같은 intermediate그림들을 생성한다.
3. Text Diffs

img representation을 위해 다른 모델이 아닌 CLIP을 사용하는 것의 가장 핵심적인 이점은 img 와 text를 같은 latent space에 임베딩 한다는 것이다. 이는 language-guided image manipulation(=text diffs)를 가능하게 한다.
새로운 caption(text = )를 반영해 이미지 수정하기 위해서는, 이 캡션의 CLIP text emb인 와 이미지를 설명하는 기존 캡션의 CLIP text emb: 를 얻어야한다. 그 후 diff vector = norm()를 구한다. 이렇게 구한 와 이미지 CLIP emb 에 spherical interpolation을 적용해 intermediate CLIP representation인 를 구한다. 이때 값을 선형적으로 증가시켜 representation을 decoding시키면 위와같은 그림이 나온다.
10. GLIGEN: Open-Set Grounded Text-to-Image Generation
요약: 학습 연산량 줄이고 여러 condition을 줄 수 있는 방법 제안
논문링크: https://arxiv.org/abs/2301.07093
기존 diffusion model의 한계
1) 여러 condition을 동시에 입력으로 받을 수 없다는 점
2) diffusion model을 학습하기 위해 많은 computing resource가 필요하다는 점
GLIGEN은 이 두 가지 한계를 모두 극복한 모델이다. 우선 multi condition을 입력으로 받을 수 있다. 또한 computing resource문제도 해결했다. 이를 위해 기존 diffusion model의 모든 가중치는 고정한 채 새로 추가된 모듈만 학습하는 방법을 제안. 모든 diffusion model의 가중치는 고정한 채 새로운 추가된 모듈만 학습하는 방법
주요내용
Grounding 제작 방법, GLIGEN의 핵심인 Gated Self Attention 동작 방법, Loss function

몸통 부분은 stable diffusion architecture이다. GLIGEN은 여기서 모든 파라미터는 고정하고 (stable diffusion의 생성능력은 그대로 사용) 새로운 condition인 Grounding에 대한 연산만 추가해준다.
Grounding 제작. Grounding이란 추가 Condition이다.
Instruction:
Caption:
Grounding:
caption c는 기존과 동일하게 이미지를 표현하는 text이다.
Grounding은 (e,l) 두 가지로 구성되어 있다.
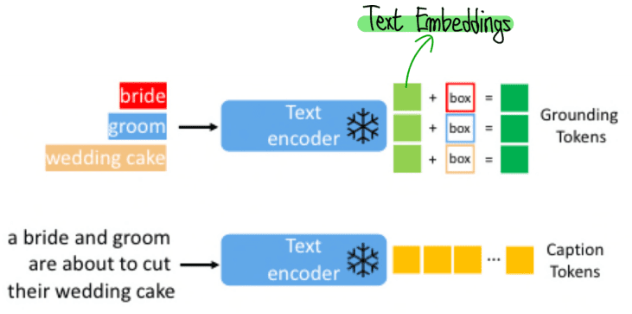
class정보에 해당하는 text는 text encoder를 통과한 후 text embedding으로 만들어주고 bounding box 정보가 있는 부분은 Fourier transformer를 통해서 embedding으로 각각 변환 후 더해준다. 이를 Grounding Tokens으로 사용한다.
gated self attention 부분
위와같이 나온 grounding 정보를 기존 정보들과 결합하여 연산해주어야 한다.
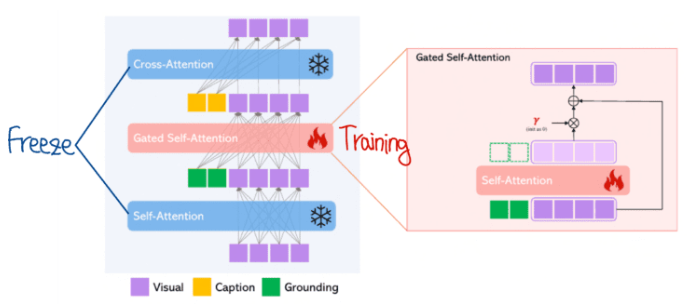
아래에서 위로 가는 형식. Grounding과 visual정보간의 self attention을 수행한 후 visual 정보만 추출하는 모습이다. scale 조절을 위해 를 곱해주고 기존 visual 정보를 더해준다. 수식적으로 표현하면 아래와 같이 나온다.
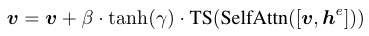
는 scale 조절을 위한 학습 가능한 scalar 값이고 학습을 시작할때는 0으로 시작한다. 즉 gated self attention 정보는 받지 않고 시작하는 것이다. 학습이 진행되면서 적절한 값을 찾아가게 된다.
TS는 token selection operation으로 간단히 visual 정보만 선택해주는 연산이다.
는 scheduled sampling을 위한 값으로 학습 동안 1을 유지한다.
+) 실험적으로 self attention이 cross attention보다 좋았서 해당 방법으로 사용함.

는 stable diffusion 파라미터를 의미한다. 은 새롭게 추가된 파라미터를 의미한다. GLIGEN에서는 만 학습이 진행된다.
