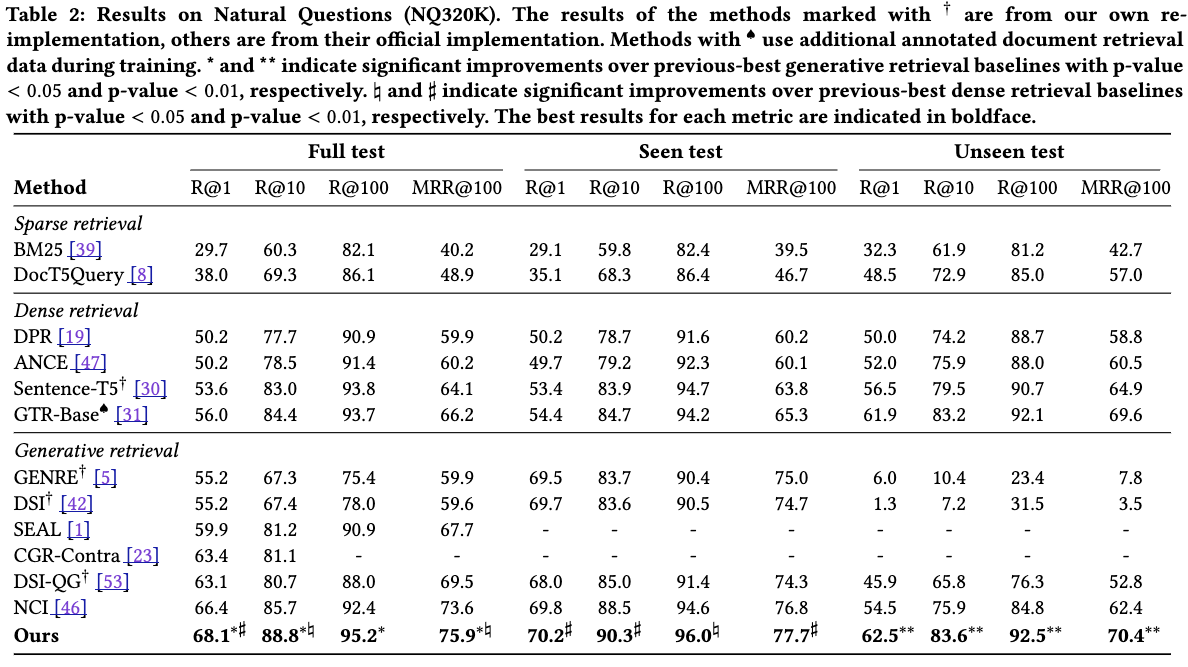
Information retrieval pipline
dpr을 기반으로 지속적으로 발전되고 있는 분야의 pipline
해당 테스크의 중점은 검색 속도와 검색 정확도가 중요한다.
대표적인 논문으로는 DPR에서 제안하는 학습 및 추론 과정의 전반을 사용하고 있다.

in-batch negative 는 학습 시점 탐색 문서를 batch내 passage들로 제한하는 방식이고
infoNCE loss는 query와 다른 문서 간 유사도를 감소시키고 정답 문서 간 유사도를 증대시키는 방식의 loss function이다.
Generative Retrieval
Transformer Memory as a Differentiable Search Index (DSI) 논문에서 시작됨
DPR: 훈련 → index 생성 → 검색 과정이 진행된다.|
DSI: doc id 정의 →memorization → retrieval 학습 → 검색 과정이 진행된다.
doc id 종류
1) Unstructured Atomic Identifiers: 각 문서 당 임의의 ID를 부여, DOC ID내 문서 정보 반영 X → query입력 시 단순 classifier를 진행
2) Naively Structured String Identifier: 각 문서 당 임의의 ID를 부여, DOC ID 내 문서정보 반영 X → query입력 시 생성 문제 수행(Query에 대한 DOC ID 문자열 생성)
3) Semantically Structured Identifiers: 각 문서에 대해 계층적 ID 부여, DOC ID 내 문서 정보 반영 → query입력 시 생성 문제 수행(Query에 대한 DOC ID 문자열 생성) → BERT와 같은 embedding을 바탕으로 k-means 수행 이를 특정 조건이 만족될 때 까지 계속진행 (e.g. 최소 100개, 최대 계층수 7개 등..)

DPR과 같은 방식은 모델 사이즈가 커져도 성능 향상이 크지 않다는 점이 존재한다. 반대로 doc id를 생성하는 DSI 방식의 경우 모델 크기가 증가함에 따라 성능도 크게 증가하는 scaling law를 가지고 있다.
ABSTRACT, INTRODUCTION
dpr 방식의 dense retrieval 같은 경우는 hidden representation을 만들어 document와 query간의 MIPS(maximize inner products search) 를 진행한다. 이는 lexical mismatch 할 수 있다는 한계가 존재한다.
Generative retrieval 방식은 docids를 LM이 직접 생성해서 매칭되는 document를 단순히 가져오는 방식을 사용한다. Generative retrieval 방식에는 핵심적인 두 가지 방식이 존재한다.
1) Document tokenization: corpus id 를 만들어주는 과정으로 어떻게 document들이 semantic space상에 분포되어 있을지 정해주는 과정이다.
1) Unstructured Atomic Identifiers: 각 문서 당 임의의 ID를 부여, DOC ID내 문서 정보 반영 X → query입력 시 단순 classifier를 진행
2) Naively Structured String Identifier: 각 문서 당 임의의 ID를 부여, DOC ID 내 문서정보 반영 X → query입력 시 생성 문제 수행(Query에 대한 DOC ID 문자열 생성)
3) Semantically Structured Identifiers: 각 문서에 대해 계층적 ID 부여, DOC ID 내 문서 정보 반영 → query입력 시 생성 문제 수행(Query에 대한 DOC ID 문자열 생성) → BERT와 같은 embedding을 바탕으로 k-means 수행 이를 특정 조건이 만족될 때 까지 계속진행 (e.g. 최소 100개, 최대 계층수 7개 등..)
2) Generation as retrival: 단순하게 query를 바탕으로 docid를 생성하는 과정이다.
본 연구에서 제안하는 방식 GENRET
GENRET는 3개의 방식 model을 parameter shared 상태로 사용한다.
1) tokenization model: doc → doc-id
2) reconstruction model: original document reconstruct
3) generative retrieval model: generate doc-id for a given query
또한 해당 연구를 진행하기 위해 두 가지 챌린지가 존재한다.
첫 번째 문제는 doc-id 가 autoregressive 하게 생성된다는 것이다.
이를 해결하기 위해 loss function 3가지를 결합해서 사용한다.
1) reconstruction loss: predicting the documnet using the generated doc-id
2) commitment loss: committing the doc-id and to avoid forgetting
3) retrieval loss: optimizatio the retrieval performance
두 번째 문제는 doc-id 가 diverse 하다는 점(trivial solution에 빠질 우려)이다.
이 문제를 해결하기 위해 파라미터 초기화하는 전략과 diverse clustering 을 기반으로 한 re-assignment기술을 사용한다고 한다.
PRELIMINARIES
Documnet tokenization: doc-id 를 z 라고 하면 z는 두 가지 조건을 만족해야한다. 첫 번째로 document보다는 짧아야한다. 두 번째로 doc-id 관련 documnet와 관련된 의미를 가능한 많이 포함하고 있어야 한다. z는 fixed length. → 이렇게 되엇을 때 학습과 inference에서 더 효율적이고 간단하게 할 수 있다고 한다.
Generation as retrieval: 각 document를 doc-id로 토큰화시킨 이후에, retrieval model은 query를 z의 형태로 만들게 된다. z 는 corpus 에 존재하는 doc-id 내로만 한정하고, 디코딩과정에서 invalid doc-id 는 0.0으로 짤라낸다.
+) 모델은 여러 document를 가져올때는 beam search를 사용해서 가저온다.
GENRET
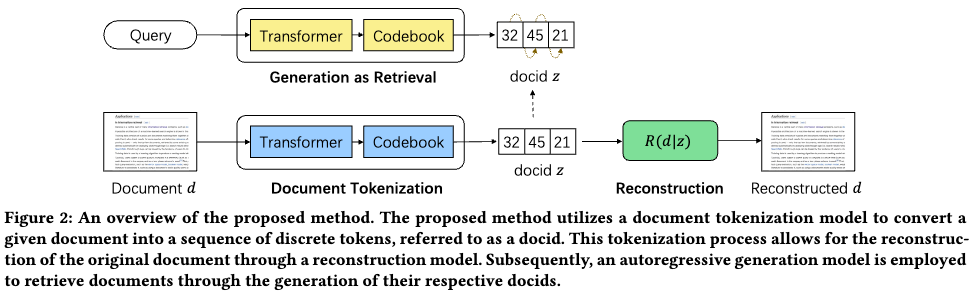
1) Tokenization model, generative retrieval model
는 document, 는 t시점 이전의 doc-id, 인 는 codebook 이라고 부르며 외부 embedding matrix, 는 discrete latent space의 사이즈 = code book 갯수(0~512), j는 particular value
, (decoding 에서 last hidden state 에서 tokenizer size로 매핑 시켜주는 것과 유사한 역할)
(document를 model input으로 넣을 때 나오는 결과와 차원)
, doc-id 인 0~512사이 값을 정해준다.
,
generative retrieval model 과 Document tokenization model 는 모델 파라미터를 쉐어한다.
2) Document reconstruction model (문서 정보 반영을 위함)
1) reconstruction loss: predicting the document using the generated doc-id
Reconstruction Loss: 각 Doc ID가 문서의 정보를 반영하도록 유도
Doc ID의 representation이 해당 Doc ID를 가지는 문서와 유사한 representation을 가지도록 학습
Relevance Score(): Doc ID를 가지는 문서와 유사한 Representation을 가지도록 학습
Doc ID representation 학습을 위해 사용되는 term
문서 representation(Latent representation)에 대해서는 학습 진행 X(Stop gradient)
문서 A의 Doc ID: 학습 중인 GenRet이 예측한 문서 A의 Doc ID
사전에 임의로 Doc ID 생성 X
학습 중: 실시간으로 모델이 생성한 Doc ID 이용
학습 후: 후처리를 통해 최종 Doc ID 배정
stop gradient: doc latent vector 에 적용 모델은 doc id 가 어떻게 변화되어야 하는지, doc id를 생성하기위해서 latent vector를 어떻게 만들어야 되는지를 학습하게 된다.
2) commitment loss: committing the doc-id and to avoid forgetting
이전 doc id를 기반으로 향후 doc id를 생성하도록 유도
문서가 가지는 모든 단계의 doc id를 순차적으로 생성하도록 학습
모델이 단계 별 doc id를 순차적으로 생성하도록 학습
doc id 간 관계, 모든 단계의 doc id와 문서 간 관계를 학습하기 위한 stop gradient 적용
3) retrieval loss: optimization the retrieval performance
탐색 단계에서 질문과 관련된 문서의 doc id 를 생성하도록 유도
Reconstruction/commitment Loss: 문서 Memorization을 위한 loss
Retrieval 모델 평가: 질문(query)입력 시 관련 문서 Doc ID 생성 여부
target Doc ID: 관련 문서 입력 시 생성되는 Doc ID
질문-문서 간 Contrastive Learning + 질문 입력 시 Doc ID 생성 학습
Doc ID 간 관계, 모든 단계의 Doc ID와 문서 간 관계를 학습하기 위한 Stop gradient 적용 X
Doc ID Diversity Technique
문제: GenRet의 경우 Doc ID를 임의로 배정하지 않고 모델이 스스로 학습과정 중 Doc ID를 배정한다. 이는 tirvial solution에 빠질 우려가 존재 한다.(모든 문서를 소수의 Doc ID에 배정하는 것) 이는 Doc ID간 의미적 구분이 불가능해지는 문제가 생긴다.
해결방법:
codebook Initialization: 각 doc ID가 유의미한 의미적 차이를 가지도록 초기화
매 doc id 단계 학습 초기 N step 적용
reconstruction loss 내 doc id representation을 latent representation으로 교체
각각의 문서가 최대한 다른 representation 생성하도록 학습
reconstruction loss와 commitment loss만 사용
memorizing에 집중(문서와 관련된 representation 생성에 집중)
N step 학습 종류 후 모든 문서의 latent representation 수집
k-means clustering 수행 및 centroid벡터 산출
4에서 산출된 각각의 centroid 벡터를 codebook의 초기값으로 설정한다.
Doc ID Re-assignment: 각 Doc ID 당 비슷한 수의 문서 배정(학습 과정 내 한 배치에서 doc id가 고르게 배정되도록 유사도 행렬 조정)
Experiment