1. Abstract, Introduction
저자는 superhuman agents를 만드는 방식을 소개했다. 현 시점에서의 문제는 reward모델은 사람의 preference로 부터 오기때문에 bottlenecked by human 이라고 말한다. 이는 reward모델을 통해서 더 나은 LLM으로의 학습에 방해가 된다고 말한다. 본 논문에서의 저자는 self-rewarding language model을 소개한다. 자체 reward를 통해서 반복적인 DPO 학습을 통해 instruction following성능을 증가시킬 수 있고 스스로 high quality reward를 생산해낼 수 있다고한다.
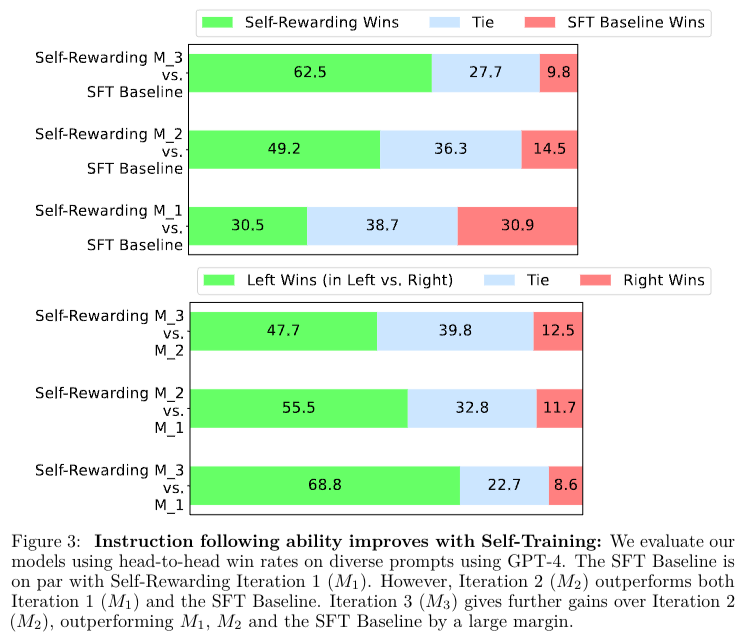
본 논문에서는 Llama 70B을 사용해 3번의 반복학습을 진행해 alpacaeval 2.0 leaderboard에서 기존 LLM을 outperform할 수 있다고 한다.
human alignment 하기위한 방법으로 standard 방식인 RLHF가 존재한다 그리고 그 대안으로 DPO 가 많이 사용되고 있다. 이 중 RLHF방식은 reward model학습에서 human preference data에 의해 학습되므로 quality에 제한이 있다. 본 논문에서는 bottleneck 문제를 해결하기위해 LLM이 reward model과 language model의 역할을 모두 수행할 수 있는 multitasking training을 진행한다.
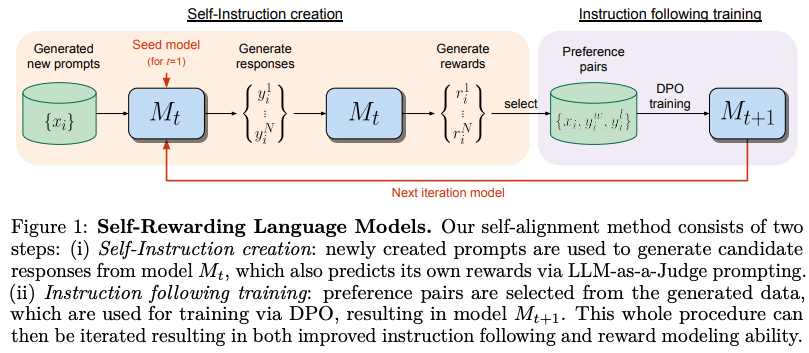
본 논문에서는 위의 Figure 1 방식을 이용해 기존 baseline모델 보다 성능 향상이 보였고 reward modeling능력이 더이상 fixed되지 않으면서 성능향상시킬 수 있다고 주장한다.
2. Self-Rewarding Language Models
본 저자는 작은 양의 human annotated seed data를 바탕으로 학습시킨 후 2개의 스킬을 동시에 모델을 만드는데 주입시키려 하였다.
- Instruction following: 사용자의 request를 바탕으로 응답을 생성, helpful 하고 harmless 한 응답을 생성하는 능력
- Self-Instruction creation: 스스로 학습데이터를 생성하고 evaluation하는 능력
2.1 Initialization
IFT(Instruction Fine-Tuning): 일반적인 SFT 학습과 동일. baseline 모델이 instruct 를 이해하고 원하는 response 를 생성하는 기본적인 능력을 학습시키기 위함
EFT(Evaluation Fine-Tuning): model이 스스로 생서한 response를 보고 evaluation하기 위한 학습과정. 특정 prompt를 이용 + CoT(chain of thought)를 이용해 final score를 생성하게 하는 과정을 학습시키고 이를 reward model의 역할을 하도록 학습시킨다. 아래 Figure2는 위에서 말한 prompt이다.

2.2 Self-Instruction Creation
위의 두 과정을 통해 학습된 모델을 바탕으로 self-modify 하기위한 training set을 만들기위해 추가적인 training data를 만들어야한다.
- Generate a new prompt: 새로운 프롬프트 는 few-shot prompting을(기존 seed IFT데이터로부터 sampling prompts) 이용해 생성
- Generate candidate responses: 로부터 만들어진 N개의 후보 responses 를 생성
- Evaluate candidate responses: 마지막으로 LLM 을 reward model로써 사용해 scores 를 주게된다. [0,5]
2.3 Instruction Following Training
- preference pair: (instruct prompt , wining response , losing response ) 를 준비하고 똑같은 score를 가진 pair 는 버리게된다.
- Positive examples only: 추가적으로 perfect score를 가진(5점) response들을 SFT학습을 위한 데이터로 추가하였다.
본 저자는 두가지 방식중 preference pair를 가진 데이터로 학습시키는 것이 SFT에 비해 더 좋은 결과가 나왔다고 말한다.
2.4 Overall Self-Alignment Algorithm
총 4번의 학습과정을 거치게되는데 모델()는 에서 나온 데이터로부터 학습된 모델을 의미한다.
: baseline, no fine-tuning
: IFT + EFT (section 2.1 과정)
: 로부터 AIFT학습이 진행된 모델(section 2.2 과정을 통해 데이터를 만들고 2.3 과정을 통해 학습시킨다. - DPO 방식이용)
: 로부터 AIFT학습이 진행된 모델(section 2.2 과정을 통해 데이터를 만들고 2.3 과정을 통해 학습시킨다. - DPO 방식이용)
3. Experiment
3.1 Dataset, Evaluation
IFT Seed Data: Open Assistant dataset(3200 examples)
EFT Seed Data: Open Assistant dataset에서 랭크된 human responses를 이용해 학습을 진행하였다. (1775 train, 531 evaluation examples). 학습된 SFT 에서 Figure2의 prompt를 이용해 Cot와 score를 생산하게 하고 label과 비교하는 방식으로 학습
Evaluation Metrics
Instruct following: AlpacaEval 2.0 leaderboard
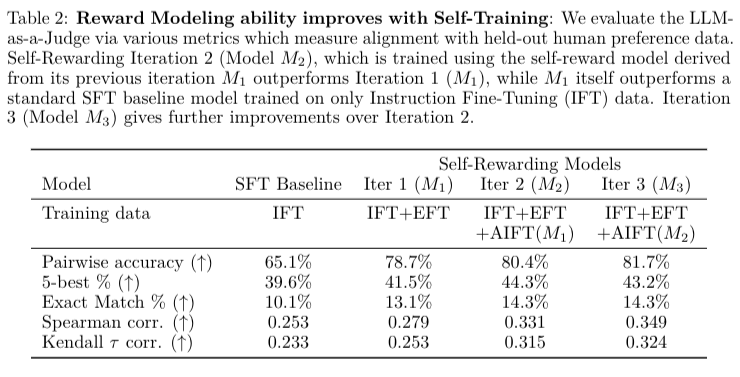
Reward Modeling: 사람이 rank시킨 것과 correlation 을 비교함
3.2 Result