Abstract, Introduction
KG는 LLMs에 외부지식으로부터의 inference와 해석가능성을 강화시킬 수 있다. 하지만 KG는 만드는데 어려움이 존재하고, unseen knowledge에 대해서 새로운 facts를 생성하는것은 challenges로 남아있다.
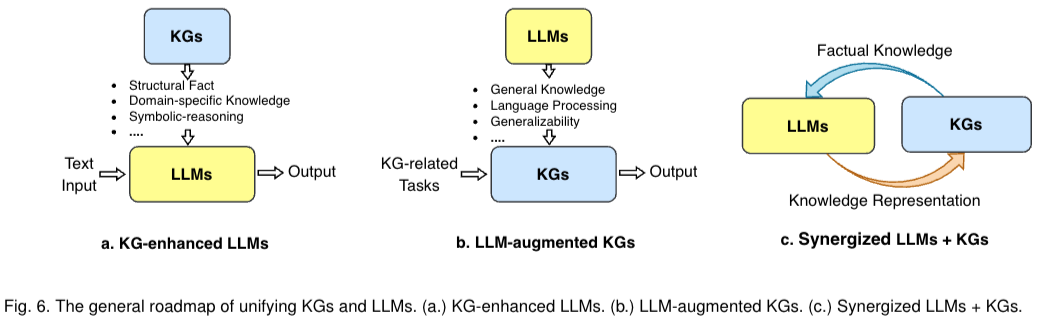
본 논문의 저자는 LLMs과 KG의 unification에 대한 forward-looking roadmap을 제시한다. road mapdpsms 3개의 일반적인 framework가 있다. 1) LLM의 사전 훈련 및 추론 단계에서 또는 LLM에서 학습한 지식에 대한 이해를 높이기 위한 목적으로 KG를 통합하는 "KG-enhanced LLM" 2) 임베딩, 완성, 구성, 그래프-텍스트 생성 및 질문 답변과 같은 다양한 KG 작업에 LLM을 활용하는 "LLM-augmented KGs" 3) LLM과 KG가 동일한 역할을 수행하고 상호 이익이 되는 방식으로 작동하여 데이터와 지식을 기반으로 하는 양방향 추론을 위해 LLM과 KG를 모두 향상시키는 "Synergized LLM KG"
우리는 로드맵에서 이 세 가지 프레임워크 내에서 기존 노력을 검토 및 요약 → 향후 연구 방향 제시
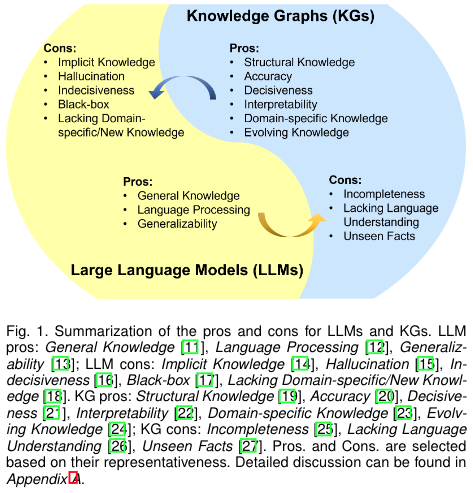
기존 LLMs의 해석 가능하지 않다(blackbox model)는 점, CoT를 사용한다고해도 hallucination 문제들을 해결하기위해 KG를 사용해서 이러한 문제들을 해결할 수 있다. KG를 이용하면 해석가능하다는 장점이 있고 구체적인 정보를 바탕(외부지식 활용)으로 LLM의 성능을 향상시킬 수 있다. 또한 특정 domain-specific하게 KG를 구성하게 되면 해당 분야 지식에 대해 좋은 성능을 가져올 수 있다.
KG 의 문제는 construct하기 힘들다는 문제가 있다. 이는 unseen entities에 대해 new facts표현을 어렵게 한다는 단점이 있다. 또한 textual information을 무시한다는 단점이 존재한다.
Background
Knowledge Graphs(KGs)
KGs에는 4개 종류의 정보저장 방식이 있다. 1) encyclopedic KGs, 2) commonsense KGs, 3) domain-specific KGs, 4) multi-modal KGs
ROADMAP & CATEGORIZATION
KG-enhanced LLM
pre-training: 사전학습단계에서 KG를 사용해 LLM의 표현력을 증가시킴
inference: 추가적인 학습없이 최근 지식의 접근을 가능하게 만들었다.
interpretability: KG를 활용해서 지식을 이해하고, LLM의 추론과정에서 해석하는데 사용한다.
LLM-augmented KGs
embedding: KGs의 representation을 만드는 과정, entity와 relation를 encoding하는 과정
completion: encode text 또는 facts를 생성해 KGC의 퍼포먼스를 더 좋게하는 방식에 LLM을 활용한다.
construction: KG를 구성하게 할 때, LLM에게 entity를 발견, coreference resolution, relation extraction task를 수행하게 한다.
KG to text generation: KG에서부터 facts를 가져온 후 LLMs을 활용해 research를 하게한다.
QA: KG로부터 answer과 자연어의 question의 차이를 연결시켜주는데 LLM을 사용한다.
Synergized LLMs + KGs
LLM과 KG는 서로 보완적인 기술들이다. 두 기술의 통합을 통해서 각각의 성능을 향상시킬 수 있다.

Figure 7은 synergized LLMs + KGs 에서 4개의 layer가 있다는 것을 볼 수 있다. 먼저 data의 경우
KG-ENHANCED LLMs
1. KG-enhanced LLM pre-training
LLM은 large-scale corpus에 대해 unsupervised training을 진행한다. 이전 작업들은 KGs를 LLM에 통합하려했고 3가지 종류가 존재한다. 1. Integrating KGs into Training Objective 2. Integrating KGs into LLM inputs 3. KGs Instruction-tuning
- Integrating KGs into Training Objective
GLM: KG 구조에 masking probability를 할당, pretrain때 중요한 entity에 높은 masking prob가 주어지게된다.
E-bert: token-level과 entity-level 사이에 loss 를 control한다.
SKEP: pos and neg sentiment를 PMI를 활용해서 결정하게한다. 두번째로 identified sentiment words에 높은 masking prob를 준다.
-
Integrating KGs into LLM inputs
sub-graph관련된 지식을 LLM의 input으로 사용
ERNIE 3.0에서는 triple represent를 직접적으로 token으로 만들어 기존 sentence 와 concatenate. 해당 방식은 knowledge sub-graph와 interact 를 통해 만들어 지는데 이는 knowledge Noise를 만들 수 있는 단점이 존재한다. 해당 부분을 해결하기 위해 KBERT에서는 visible matrix를 통해 knowledge noise를 줄이면서 injection할 수 있다고 한다. 그외에도 knowledge noise를 줄이기 위해 word-knowledge graph를 통합하는 방식인 Colake, large amount of knowledge를 LLM에 주입시키기위한 DkLLM, 마지막으로 rare word의 quality representation을 높이기 위한 Dict-BERT방식이 제안되었다. -
KGsInstruction-tuning
Instruction-tuning 방식은 LLMs 학습시킬 때 더 KG 구조를 이해하는 형태로 user 의 의도를 효율적으로 따르기 위해 복잡한 task에서 효과적으로 수행될 수 있다.
KPPLM과 OntoPrompt 방식은 prompt를 이용해 graph구조의 전이학습을 효율적으로 할수 있게 한느 방식이다. 그리고 ChatKBQA, RoG 방식은 reasoning path를 효율적으로 찾기 위한 방식으로 이는 해석가능한 결과를 가져올 수 있다고 한다.
KG-enhanced LLM inference
기존 방식들은 retraining하지 않으면 real world에서 사용하기 어렵다는 단점이 존재한다. 이를 해결하기 위해 inference에서 KGs를 injection시키는 방식으로 성능을 높이는 시도가 inference에서 진행된다. 주로 QA에서 많이 사용한다.
Retrieval-Augmented Knowledge Fusion
parametric modules: dist of data를 바탕으로 한다. fixed number of parameter, e.g.) linear regression, logistic regression, Gaussian Naive Bayes
non-parametric modules: dis of data바탕으로 하지 않는다. data에 복잡한 패턴을 adapt 시키는방법(?), e.g.) knn, svm, decision trees
RAG를 이용해서 기존 parametric, non-parametric 들을 outperform할 수 있다고 한다.
RAG에서 search 는 MIPS(maximize inner product search), MCSS(maximize cosine similarity search), NNS(유클리드 거리가 작은 것) 중에서 MIPS를 사용해 document를 서치하게된다고 한다.
대표적인 논문은 EMAT, REALM, KGLM 등이 존재한다.
KGs Prompting
inference에서 KG 구조에 LLM을 feed하기 위해 prompt를 이용해서 KG → text sequence로 바꾸는 작업이 존재한다. 이 방식은 LLM이 더 추론작업에 KG 구조를 잘 쓸 수 있게 된다.
대표적인 예로 ChatRule, Mindmap, Cok등이 존재하며 이러한 방식들은 쉽게 KGs와 LLM을 통합시킬 수 있다는 장점이 존재하지만 prompt를 manually 만들어야한다는 점에서 human effort가 들어간다.
Comparison between KG-enhanced LLM pre-training and Inference
KG-enhanced LLM pre-training은 일반적으로 corpus를 학습시키게되고 이는 knowledge update될때마다 추가적인 학습을 시켜한다는 점이 존재. 반면 inference에서 사용은 추가적인 학습은 없지만 sub-optimal 에 빠지게될 수 있다는 단점이 존재한다.
KG-enhanced LLM Interpretability
기존 LLM 은 해석가능성에서 큰 문제가 된다. 내부 작용을 정확하게 설명하기 어렵고 어떤 decision-making을 바탕으로 생성했는지 알기 어렵다. 이러한 문제점은 medical diagnosis 와 legal judgment등 high-stakes 상황에서 문제가 된다. KG는 구조적으로 추론결과에 대한 해석가능한 장점이 존재한다.
해당 방식에는 KGs for language model probing 과 KGs for language model analysis 카테고리로 분류할 수 있다.
KGs for language model probing
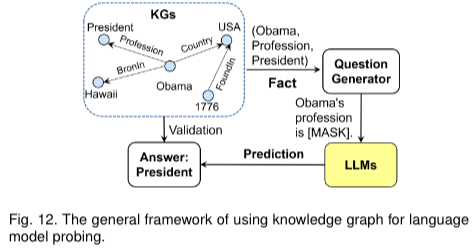
LAMA 논문에서 사전학습된 KGs를 바탕으로한 cloze statements를 만들어(prompt template가 정의되어 있음) 언어 모델이 prediction 할때 사용했다. 본 논문에서는 사전 정의된 cloze statements를 사용했는데 이는 LLM이 선호하는 형태가 아니라 다른 논문들(LPAQA, Autoprompt, LLM-facteval)에서는 paraphrasing, 자동적으로 prompt를 만든 방식등이 제안되었다.
KGs for LLM Analysis
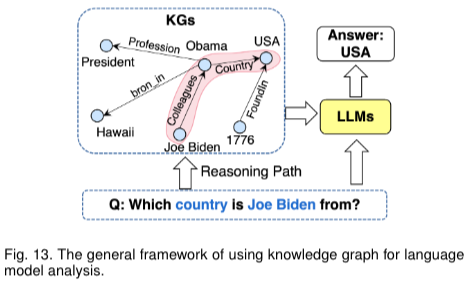
Fig13과 같이 언어모델이 생성된 결과가 얼마나 정확한지 분석하는 것으로 사용될 수 있다고한다.
LLM-augmented KGs
KG는 지식을 구조적으로 representation하는 것으로 잘 쓰인다. 전통적인 KG 방식은 textual information을 잘 고려하지 못한다는 단점이 있다 이 부분을 보완하기 위해 LLM을 이용해 augment 시키는 방식들 사용하고 이를 통해 성능을 더 좋게 만들수 있다고한다. 해당 방식에는 integrate LLMs for KG embedding, KG completion, KG construction, KG-to-text generation, KG question answering 이 있다.
LLM-augmented KG embedding
KG embedding은 각 entity와 relation을 낮은 차원의 vector space로 mapping 시키는 것을 목표로 한다.
LLMs as Text Encoders 방식은 언어모델을 바탕으로 임베딩을 만드는 과정이다. 직접적으로 embedding을 만드는 방식은 long-tailed relation이나 unseen entities에 구조적 연결성이 단점이 있다. 이러한 문제를 해결하기 위해 KGE에서는 graph embedding방식을 통해 representation을 풍부하게 만들었다..?

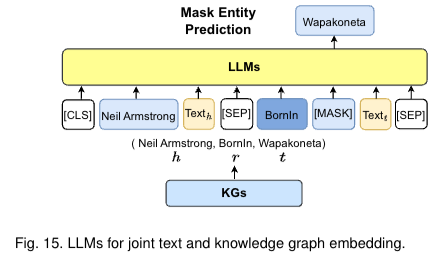
LLMs for Joint Text and KG embedding. KGE모델(graph 구조)대신에 단순히 graph 구조와 textual information을 embedding space에 동시에 넣는 방식을 사용했다. entities와 relation사이에 special token을 넣고, masking을시켜 학습을 진행한다.
LLM-augmented KG Completion(KGC)
KGC는 missing facts를 추론하는 테스크를 의미한다. KGE와 비슷하게 전통적인 KGC방식은 주로 외부의 지식을 고려하지 않고 KG의 구조에 포커스를 두었다. 그러나 최근 LLMs과 KGC의 통합하는 과정이 많이 사용된다. 이러한 방식에는 LLM as Encoder(PaE)와 LLM as Generators(PaG) 두가지 방식이 존재한다.
PaE는 encoder only LLM을 이용해 KG facts뿐만아니라 textual information을 사용한다. 그런다음 masking entity를 예측하는 방식으로 사용한다.
PaG는 query triple을 만들어(h, r, ?) 하나의 tail entity를 예측하는 방식으로 사용된다. 이는 prompt에 의해 custom될 수 있다.
LLM-augmented KG Construction
specific한 도메인 뿐만아니라 relation을 및 entity를 identify하는 방식으로 사용된다. 1)entity discovery 2) coreference resolution 3) relation extraction 4) end-to-end knowledge graph construction 방식이 존재한다.
end-to-end KG Construction: 최근 연구자들은 LLM을 이용해 end-to-end KG construction을 수행한다. raw text를 바탕으로 BERT모델을 이용해 NER(named entity recognition) or relation extraction task를 수행한다. 2개의 classifier가 존재하는데 첫 번째 cls는 relation class, 두 번째 cls는 entities간에 relation이 있는지 파악하게 된다. 뿐만 아니라 bert기반으로 end to end 방식으로 하는 방식도 있다.(Guo et al)
LLM-augmented KG-to-text Generation
KG-to-text 는 high-quality text를 생산하는 것을 목표로한다.
Leveraging Knowledge from LLMs의 방식은
………(pass)
LLM-augmented KG Question Answering
3.1.1장, 4장(KG-enhanced LLM), 4.2.1장(Retrieval-Augmented Knowledge Fusion) 부분과, 키워드로는 RAG와 lack of factual knowledge/interpretability, hallucination 등이 포함된 부분 위주로 참고
SYNERGIZED LLMs + KGs
LLM과 KG는 각각의 장점을 가지고 있기 때문에 두 방식의 장점을 결합해 성능을 향상시킬 수 있다. Synergized LLMs + KGs 는 두가지 관점이 존재한다. 1) Synergized Knowledge Representation, 2) Synergized Reasoning
