1. Word Representation
: 텍스트를 컴퓨터가 이해하고 효율적으로 처리하게 하기 위해 텍스트를 적절히 숫자로 변환시키는 것
1) One-hot vector
=희소 표현(Sparse Representation) = Discrete Representation = Local Representation
- [0,1,0,0,0]
- 벡터의 차원(Vector dimension) = 단어 집합의 크기(고차원), 공간적 낭비
- 표현 방법: 수동
- 값의 타입: 1과 0
- 📌각 단어 벡터간 유의미한 유사성을 표현할 수 없음
ex)
motel = [0 0 0 0 0 1 0]
hotel = [0 0 0 1 0 0 0]
These two vectors are orthogonal.
Solution) learn to encode similarity in the vectors themselves
2) Embedding vector
=밀집 표현(Dense Representation) = Continuous Representation = Distributed Representation
- [0.2, 1.8, 1.1]
- 벡터의 차원 = 우리가 직접 설정할 수 있다(저차원)
- 표현 방법: 훈련 데이터로부터 학습(= 각 단어를 인공신경망 학습을 통해 벡터화, word embedding)
- 값의 타입: 실수
- 📌단어 벡터 간 유의미한 유사도 계산 가능(semantic similarity)
- ex) 강아지, 귀엽다, 애교: 주로 함께 등장하는데 분포 가설에 따라서 해당 내용을 가진 텍스트의 단어들을 벡터화한다면 해당 단어 벡터들은 유사한 벡터값을 가진다.
2. 단어 표현의 카테고리화
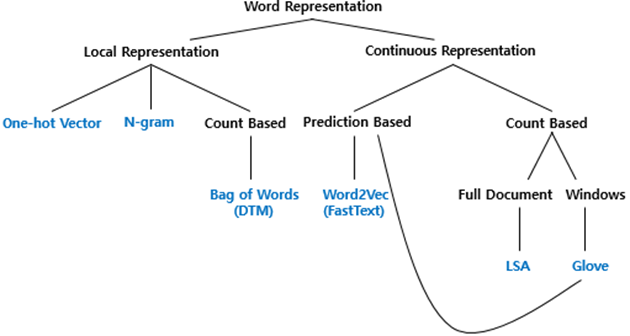
3. Local Representaion
카운트 기반의 단어 표현(Count based word Representation) 챕터에서는 Bag of Words는 국소 표현에(Local Representation)에 속하며, 단어의 빈도수를 카운트(Count)하여 단어를 수치화하는 단어 표현 방법입니다. 이 챕터에서는 BoW와 그의 확장인 DTM(또는 TDM)에 대해서 학습하고, 이러한 빈도수 기반 단어 표현에 단어의 중요도에 따른 가중치를 줄 수 있는 TF-IDF에 대해서 학습합니다.
1) Bag of Words
: 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- ex) vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
- bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
2) DTM
(Document-Term Matrix, 문서 단어 행렬)
: 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 |
|---|---|---|---|---|---|---|---|---|
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
- 한계
1) 희소 표현(sparse representation)
2) 단순 빈도 수 기반 접근
ex) ‘the’(stopwords, 불용어) 빈도수가 높더라도 자연어 처리에 있어 의미를 갖지 못하는 단어. 그렇다면 DTM에 불용어와 중요한 단어에 대해서 가중치를 줄 수 있는 방법은? >> TF-IDF
3) TF-IDF
(Term Frequency-Inverse Document Frequency)
: 단어 빈도-역 문서 빈도(문서의 빈도에 특정 식을 취함)
-
DTM내의 각 단어들마다 중요한 정도를 가중치로 주는 방법. 우선 DTM을 만든 후, TF-IDF 가중치를 부여
-
TF * IDF
-
문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있다.
-
TF-IDF는 TF와 IDF를 곱한 값을 의미. 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때 TF, DF, IDF는 각각 다음과 같이 정의할 수 있다.
(1) tf(d,t): 특정 문서 d에서의 특정 단어 t의 등장 횟수
(2) df(t):특정 단어 t가 등장한 문서의 수, 각 문서 d에 몇 번 등장했는지는 관심x.
(3) idf(d,t): df(t)에 반비례하는 수. 여러 문서에서 등장한 단어의 가중치를 낮추는 역할, idf(d,t) = log(n/1+df(t)) -
TF_IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다.
-
TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것
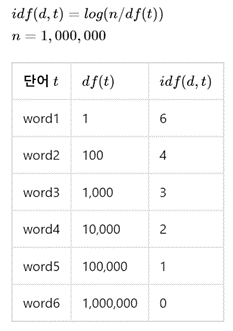
-> log는 n이 커질 경우 값이 너무 커지는 것을 제어.분모에 1을 더해주는 것은 특정 단어가 전체 문서에서 등장하지 않을 경우를 방지.
📌4. Distributed Representation
워드 임베딩(Word Embedding) 챕터에서는 연속 표현(Continuous Representation)에 속하면서, 예측(prediction) 기반, 학습 기반으로 단어의 뉘앙스를 표현하는 워드투벡터(Word2Vec)와 그의 확장인 패스트텍스트(FastText)를 학습하고, 예측과 카운트라는 두 가지 방법이 모두 사용된 글로브(GloVe)에 대해서 학습합니다.
워드 임베딩이란 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 뜻한다.
1) Word2Vec Model
: 여러 임베딩 방법의 모음
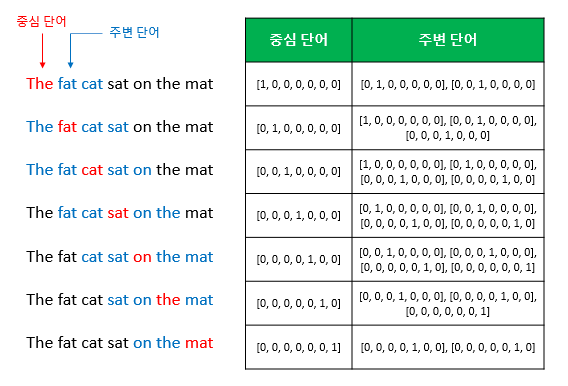
“The fat cat sat on the mat”
(1) CBOW
(The Continuous Bag of Words Model)
: 주변단어(Context word) > 중심단어(Center word) 예측
- window: 앞, 뒤로 몇 개의 단어를 볼지
- sliding window: 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터셋을 만드는 것
Sliding Window, CBOW를 위한 전체 데이터셋
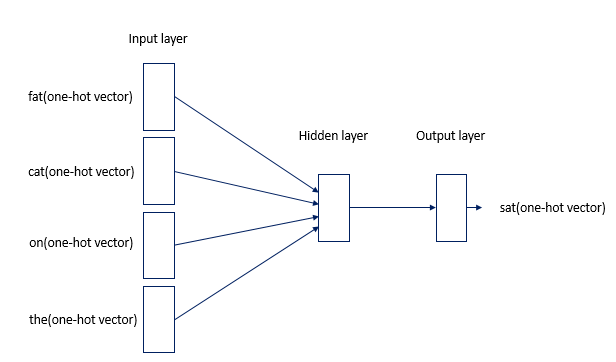
CBOW Word2Vec 인공신경망 모델 도식화
- 오직 하나의 은닉층(Hidden Layer)만이 존재하므로 심층신경망(Deep Neural Network)이 아니라 얕은신경망(Shallow Neural Network)임
CBOW 동작 메커니즘
- 은닉층의 크기 = N = embedding 하고 난 벡터의 크기
- 입력층과 은닉층 사이의 가중치 W는 (VxN) 행렬, 은닉층과 출력층 사이의 가중치 W'는 (NxV). 주의할 점은 이 두 행렬을 동일한 행렬을 전치(Transpose)한 것이 아니라, 서로 다른 행렬임
- 인공 신경망 훈련 전 W, W'는 작은 랜덤 값을 가짐
- 학습 목적: CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해서 계속해서 이 W, W'를 학습해가는 구조임
- 가중치 W행렬과 곱해지는 각 주변 단어(입력 벡터)는 one-hot 벡터이기 때문에 i번째 인덱스에 1이라는 값을 가지고 그 외의 0의 값을 가지므로, 벡터와 가중치W행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과(look up)과 동일하다. 그래서 이 작업을 테이블 룩업(Table lookup)이라고 부른다.
- 앞서 CBOW의 학습목적을 W와 W'을 잘 훈련시키는 것이라고 언급한 적이 있는데, 그 이유가 여기서 lookup해온 W의 각 헹벡터가 사실 Word2Vec을 수행한 후의 각 단어의 N차원 크기를 갖는 임베딩 벡터들이기 때문이다.
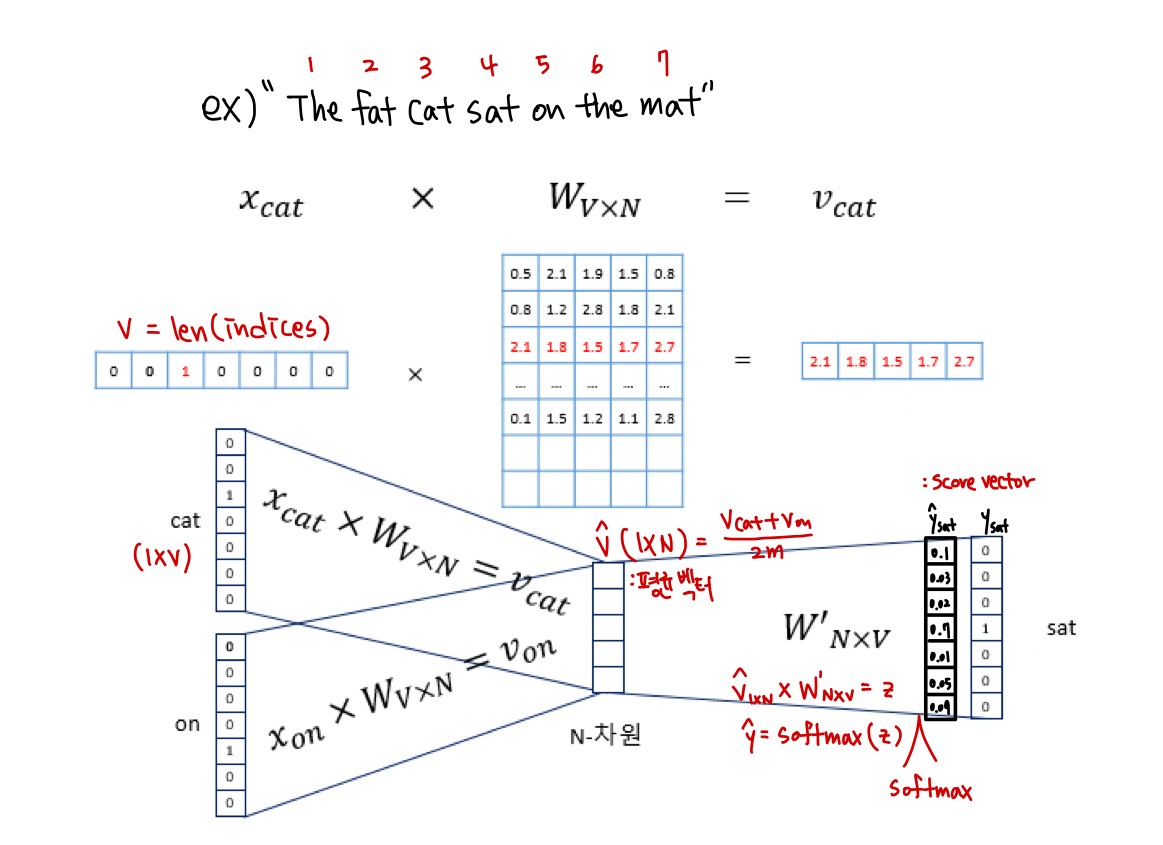
과정1. 각 주변 단어들(1xV)과 W(VxN)를 곱해준 후 나온 N-차원 벡터들(1xN) 2m개에 대해 평균 벡터(1xV)를 구해준다.
과정2. 평균 벡터(1xV)와 두번째 가중치 행렬W'(NxV)를 곱해 입력 벡터와 동일한 크기의 벡터를 내보낸다.
과정3. 이 벡터에 softmax 함수를 취해 출력값을 0과 1사이의 실수, 각 원소의 총합을 1이 되는 상태로 바꾼다. 이렇게 나온 최종 벡터를 스코어 벡터(score vector) 라고 한다.
과정4. 스코어 벡터의 j번째 인덱스가 가진 0과 1 사이의 값은 j번째 단어가 중심 단어일 확률을 나타낸다. 스코어 벡터를 ŷ 중심 단어를 y라고 했을 때, 이 두 벡터가 가까워지게 하기 위해 cross-entropy 함수를 loss function으로 두고 이를 최소화 하는 방향으로 학습시킨다. 역전파(Back Propagation)를 수행해 W와 W'를 학습시킨다.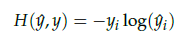
(2) The Skip-gram Model
: 중심단어 > 주변단어 예측
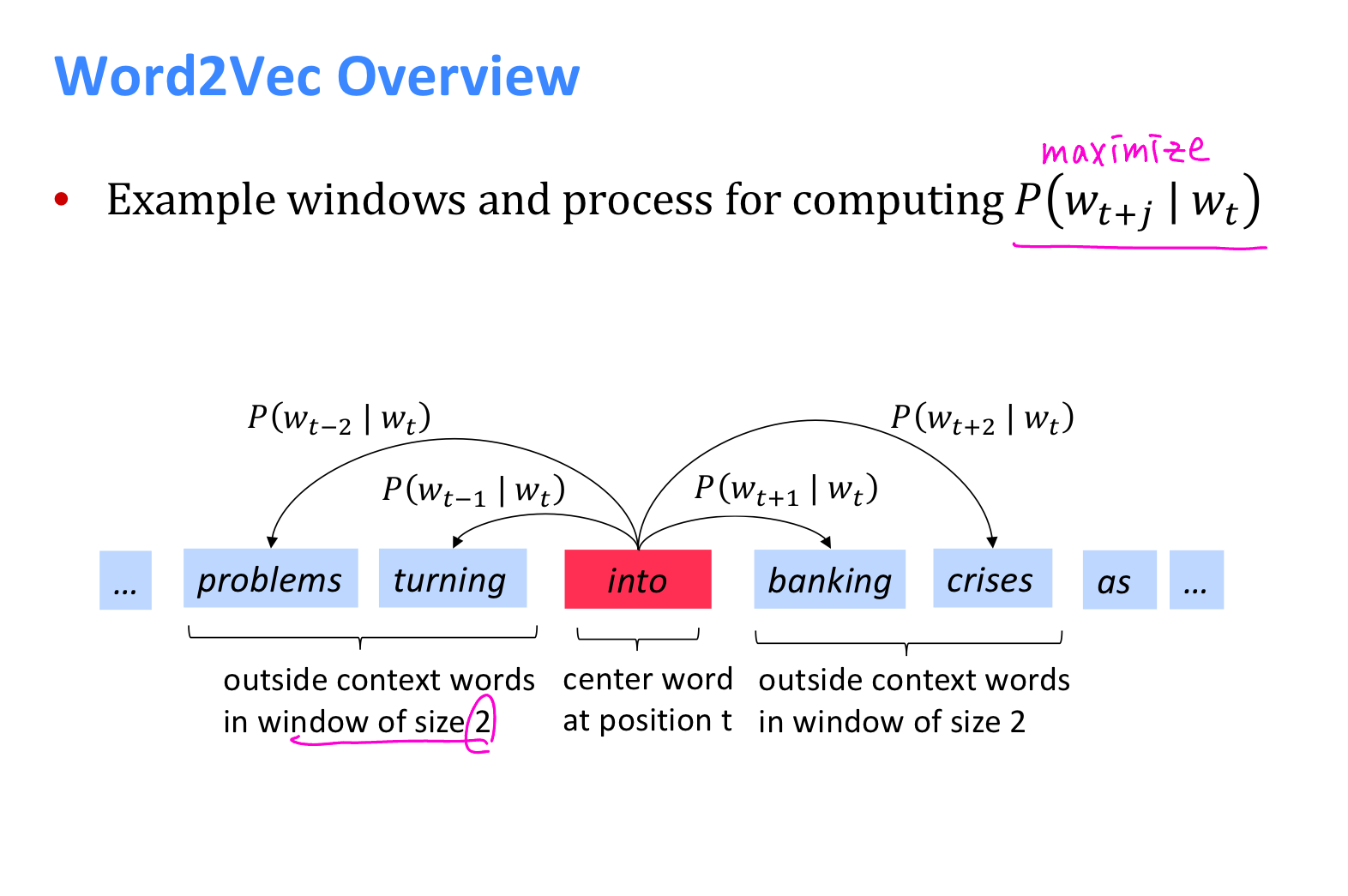
모델은 objective function 을 minimize할 수 있는 방식으로 train한다.
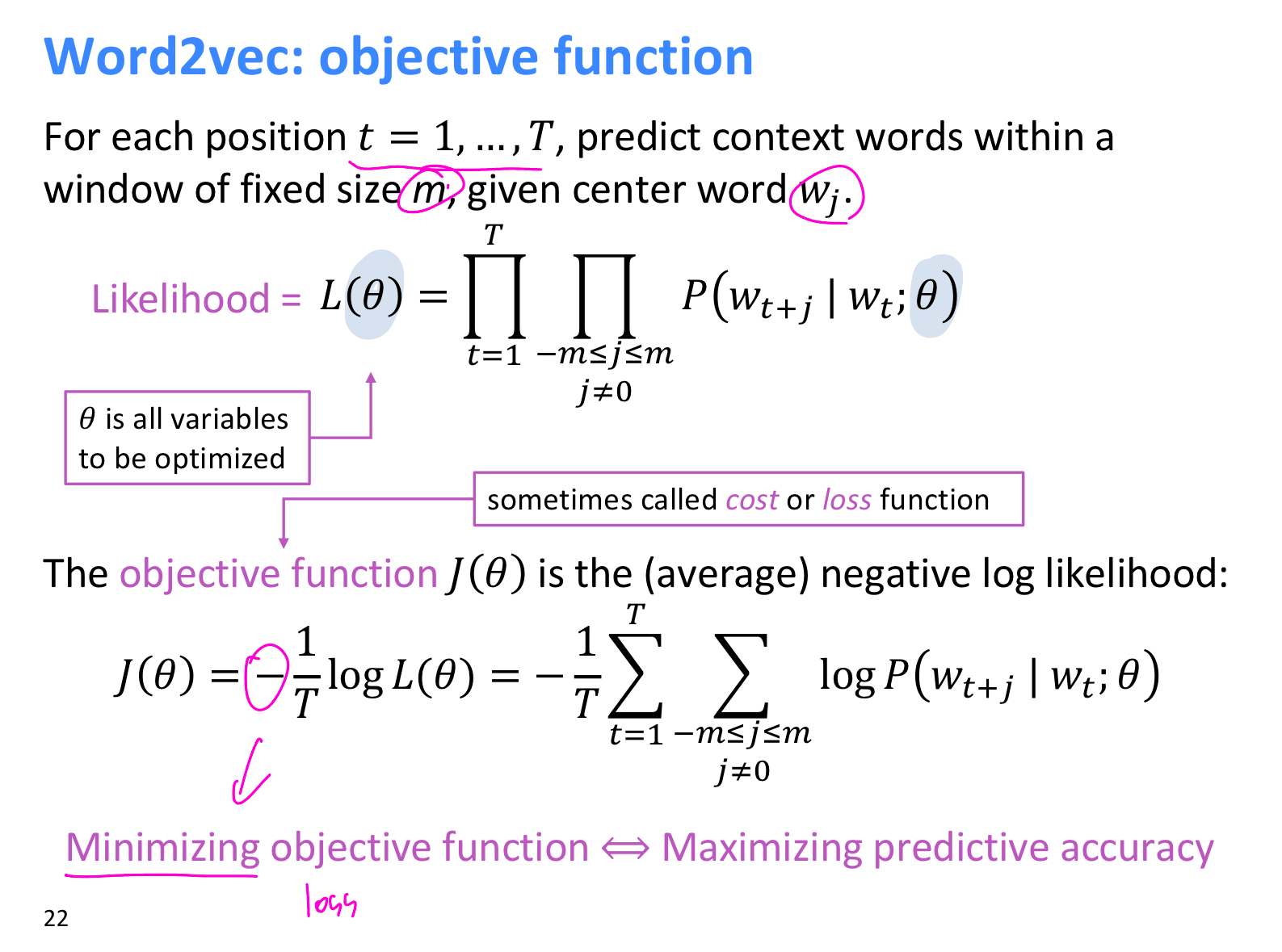
위 식에서 을 구하는 공식은 다음과 같다.

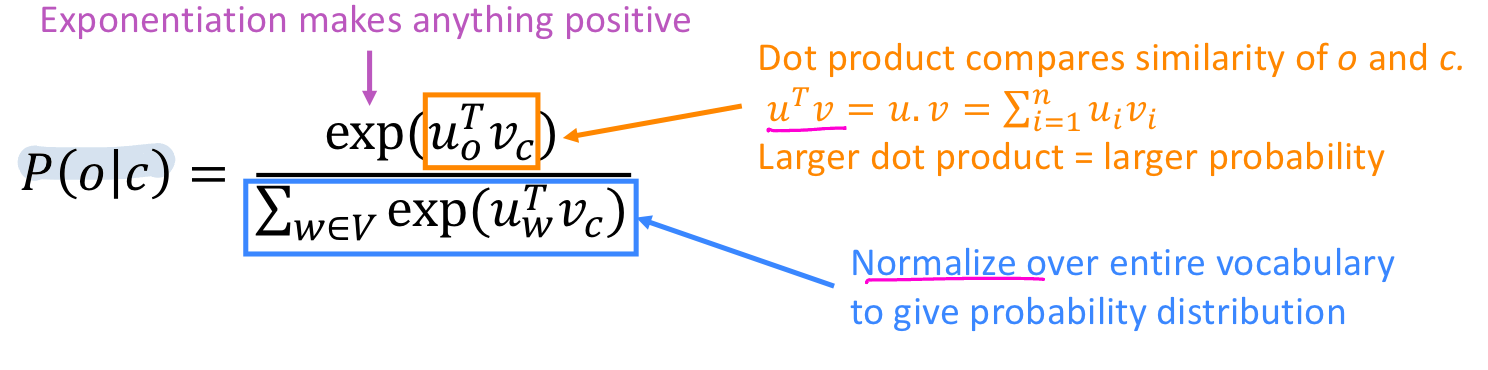
이제 CBOW에서도 설명했듯이 모델을 도식화하면 다음과 같다. Skip-Gram은 CBOW와 달리 input이 center word() 하나만 들어가고 그에 대한 outside context word인() output vector가 여러 개 나오는 것을 확인할 수 있다.
+ Skip-Gram with Negative Sampling(SGNS)
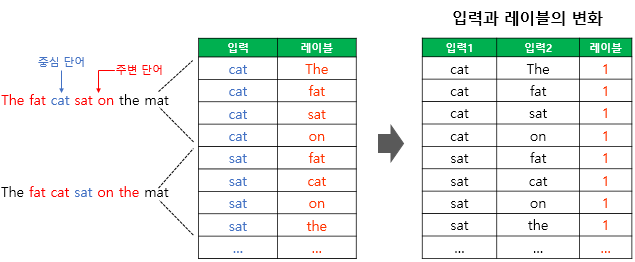
: '강아지', '고양이',' 귀여운'과 같은 단어에 대해 Word2Vec을 학습하는 경우, 이 단어들과 연관 없는 '돈가스', '컴퓨터' 단어의 임베딩 벡터값까지(즉, 임베딩 테이블 W에 있는 모든 단어에 대한 임베딩 벡터값을) 업데이트하는 것은 비효율적.
(3) 실습
과정1. 훈련 데이터 다운로드
- xml파일로 실습 진행
(코퍼스 파일 다운로드): https://wit3.fbk.eu/get.php?path=XML_releases/xml/ted_en-20160408.zip&filename=ted_en-20160408.zip
과정2. 훈련 데이터 전처리
- 과정2.1. xml문법으로 작성되어 있으므로, 얻고자 하는 영어 문장 데이터를 얻기 위해 전처리 필요
- <content>..</content> 사이의 내용
- 과정2.2. tokenizer
- nltk, Mecab, okt, Kkma, KnNLPy,,
- 한국어 형태소 분석기: KoNLPy는 다양한 형태소 분석, 태깅 라이브러리를 파이썬에서 쉽게 사용할 수 있도록 모아놓았다.
- 출처:<https://datascienceschool.net/03%20machine%20learning/03.01.02%20KoNLPy%20%ED%95%9C%EA%B5%AD%EC%96%B4%20%EC%B2%98%EB%A6%AC%20%ED%8C%A8%ED%82%A4%EC%A7%80.html
과정3. Word2Vec 훈련시키기
- gensim 패키지
<하이퍼파라미터>
- size(워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원)
- window(컨텍스트 윈도우 크기)
- min_count(단어 최소 빈도 수 제한, 빈도가 적은 단어들은 학습하지 않는다.)
- workers(학습을 위한 프로세스 수)
- sg(CBOW은 0, Skip-gram은 1)
import re
from lxml import etree
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
# 훈련 데이터 다운로드
targetXML = open('./ted_en-20160408.xml', 'r', encoding='UTF-8')
target_text = etree.parse(targetXML) #etree.parse(XML): XML데이터 가져오기, parse: (문장을 문법적으로)분석하다
# 훈련 데이터 전처리
##xml 파일로부터 <content>와 </content? 사이의 내용만을 가져옴
parse_text = '\n'.join(target_text.xpath('//content/text()'))
##정규 표현식의 sub 모듈을 통해 content 중간에 등장하는 (Audio), (Laughter) 등의 배경음 부분을 제거
content_text = re.sub(r'\([^)]*\)', '', parse_text)
##입력 코퍼스에 대해서 NLTK를 이용해 문장 토큰화 수행
sent_text = sent_tokenize(content_text)
##단어 토큰화
###각 문장별 특수문자 제거
normalized_text = []
for string in sent_text:
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
normalized_text.append(tokens)
###최종 단어 토큰화
result = []
result = [word_tokenize(sentence) for sentence in nomalized_text]
# 해당 데이터를 가지고 Word2Vec 수행
from gensim.models import Word2Vec
model = Word2Vec(sentences=result, size=100, window=5, min_count=5, workers=4, sg=0)
##입력한 단어에 대해서 가장 유사한 단어들을 출력하기
a = model.wv.most_similar("man")
##모델 저장과 로드
model.wv.save_word2vec_format('eng_w2v')
loaded_model = KeyedVectors.load_word2vec_format('eng_w2v')2) Pre-trained Word2Vec embedding
(1) 구글 Word2Vec
: It includes word vectors for a vocabulary of 3 million words and phrases that they trained on roughly 100 billion words from a Google News dataset. The vector length is 300 features.
- 모델 다운로드 경로: https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit (~3.35GB)
import gensim
import urllib.request
# 구글의 사전 훈련된 Word2Vec 모델을 로드
word2vec_model = gensim.models.KeyedVecotrs.load_word2vec_format('./model/GoogleNews-vectors-negative300.bin', binary=True)(2) FastText
: 단어를 vector로 만드는 또 다른 방법으로, 페이스북에서 개발. 메커니즘 자체는 Word2Vec(구글)의 확장판
📌Word2Vec vs FastText??: Word2Vec은 단어를 쪼개질 수 없는 단위로 생각한다면, FastText는 하나의 단어 안에도 여러 단어들이 존재하는 것으로 간주. 즉,
- 서브워드(subword, 내부 단어)를 학습
- 모르는 단어(OOV, Out Of Vocabulary)에 대한 대응
- 단어 집합 내 빈도 수가 적었던 단어(Rare Word)에 대한 대응 > 노이즈가 많은 코퍼스에서 강점을 가짐.
ex) n=3 -> apple =<ap, app, ppl, ple, le> 시작 ,,,, 끝, <'apple'> 특별토큰
(3) glove
-출처: https://wikidocs.net/31767
-출처: https://omicro03.medium.com/%EC%9E%90%EC%97%B0%EC%96%B4%EC%B2%98%EB%A6%AC-nlp-13%EC%9D%BC%EC%B0%A8-%EC%9B%8C%EB%93%9C%EC%9E%84%EB%B2%A0%EB%94%A9-e50cc78607bd
-참고: 신효필 교수님 자료, 구글 클라우드, 자연어처리>Day2>topic>1_WordEmbeddingsForNLP.ipynb
