Sequence model_1: Sentiment Classification
Sequence model_2: Sequence2Sequence model
CNN(Convolutional Neural Network: 공간을 따라 파라미터를 공유하는 방법을 살펴보았습니다. CNN은 커널이란 파라미터를 사용해 입력 데이터의 부분 영역 에서 출력을 계산합니다. 합성곱 커널은 입력을 가로질러 이동하고 가능한 위치마다 출력을 계산해 '이동 불변성(translation invariance)' 을 학습하니다.
RNN(Recurrent Neural Network): 같은 파라미터를 사용해 타임 스텝 마다 출력을 계산합니다. 이때 은닉 상태 벡터에 의존해서 시퀀스의 상태를 감지합니다. RNN의 목적은 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산함으로써 '시퀀스 불변성' 을 학습하는 것입니다.
즉, CNN은 '공간을 따라' 파라미터를 공유하고 RNN은 '시간을 따라' 파라미터를 공유한다고 할 수 있습니다.
RNN
-
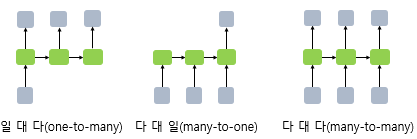
일 대 다(one-to-many)
ex) 하나의 이미지 입력에 대해서 사진의 제목을 출력하는 이미지 캡셔닝(Image Captioning) 작업, 사진의 제목은 단어들의 나열이므로 시퀀스 출력임 -
다 대 일(many-to-one)
ex) 입력 문서가 긍적적인지 부정적인지 판별하는 감성 분류(sentiment classification), 스팸메일 분류(spam detection) -
다 대 다(many-to-many)
ex) 챗봇, 번역기, 태킹 작업(개체명 인식, 품사 태킹) -
RNN 수식
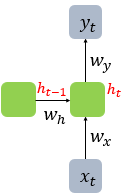

는 를 구하기 위한 활성화 함수, 는 비선형 활성화 함수 중 하나
는 단어 벡터의 차원, 는 은닉 상태의 크기
1. Statistical LM vs Neural Network LM
2. RNN 종류
1) Vanilla RNN
(Elman RNN)
- The simplest recurrent network, Vanilla RNN, transform and linearly, then applies a non-linearity(most often, the tanh function)
- 현재 입력 벡터와 이전 은닉 상태 벡터로 은닉 상태 벡터를 계산
- 문제점
(1) 멀리 떨어진 정보를 유지하기 어렵다.(장기 의존성 문제, the problem of Long-Term Dependencies) 타임 스텝마다 정보의 유익성에 상관없이 은닉 상태 벡터를 업데이트 한다. 즉 어떤 값을 유지하고 어떤 값을 버릴지 제어하지 못합니다. RNN이 선택적으로 업데이트를 결정하거나 업데이트할 때 상태 벡터의 어느 부분을 얼마만큼 업데이트할지 판단할 방법이 필요합니다.
(2) 그레이티언트가 통제되지 않고 0이나 무한대를 만드는 경향이 있다. 그레이디언트 절댓값이 감소 또는 증가하는 방향에 따라 통제할 수 없는 불안정한 그레이디언트를 그레이디언트 소실(vanishing gradient) 또는 그레이디언트 폭주(exploding gradient) 라고 부릅니다.
💡 게이팅(gating)
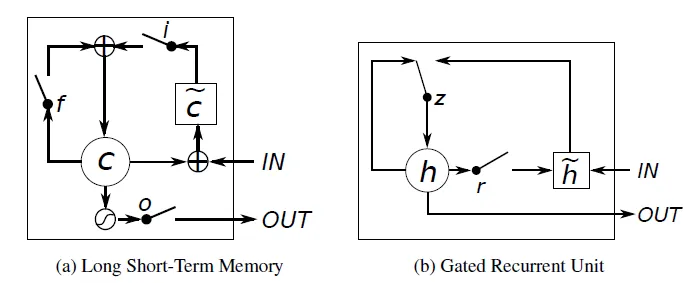
2) LSTM
(Long Short-Term Memory network, 장단기 메모리)
- = 장기 상태(long-term state) = (망각게이트)· + (입력게이트)· +
- = 단기 상태(short-term state) = (출력게이트)·
📌Cell state란?
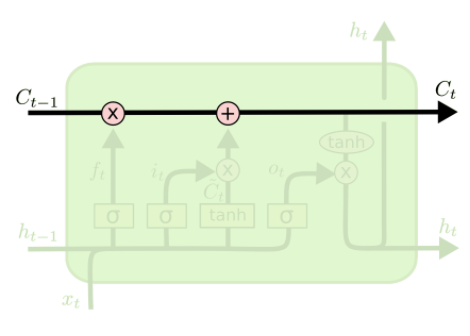
- LSTM의 핵심은 모델 구조도에서 위의 수평선에 해당하는 cell state입니다. cell state는 컨베이어 벨트와 같은 역할로 전체 체인을 지나면서, 일부 선형적인 상호작용만을 진행합니다. 정보가 특별한 변화 없이 흘러가는 것으로 이해하면 쉽습니다.
- LSTM에서 cell state를 업데이트 하는 것이 가장 중요한 일이며, 'gate'라는 구조가 cell state에 정보를 더하거나 제거하는 조절 기능을 합니다.
📌Gate란?
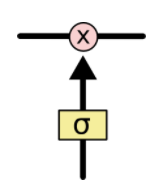 **'sigmoid layer outputs'+'pointwise multiplication operation'**
**'sigmoid layer outputs'+'pointwise multiplication operation'**
- gate란 정보를 선택적으로 통과시키는 길로, 시그모이드 뉴럴 네트워크 층과 접곱(point wise multiplication) 연산으로 이루어져있습니다.
- LSTM은 cell state를 조절하고 보호하기 위하여 총 3개의 gate(forget, input, output)를 갖습니다.
- 시그모이드 층은 0과 1사이의 값을 출력하는데, 이 값들은 각 원소들을 얼마나 많이 통과시킬 것인지를 의미합니다. 예를들어 숫자 '0'은 어떤 것도 통과시키지 않음을 의미하며, 숫자'1'은 모든 것을 통과시킴을 의미합니다.
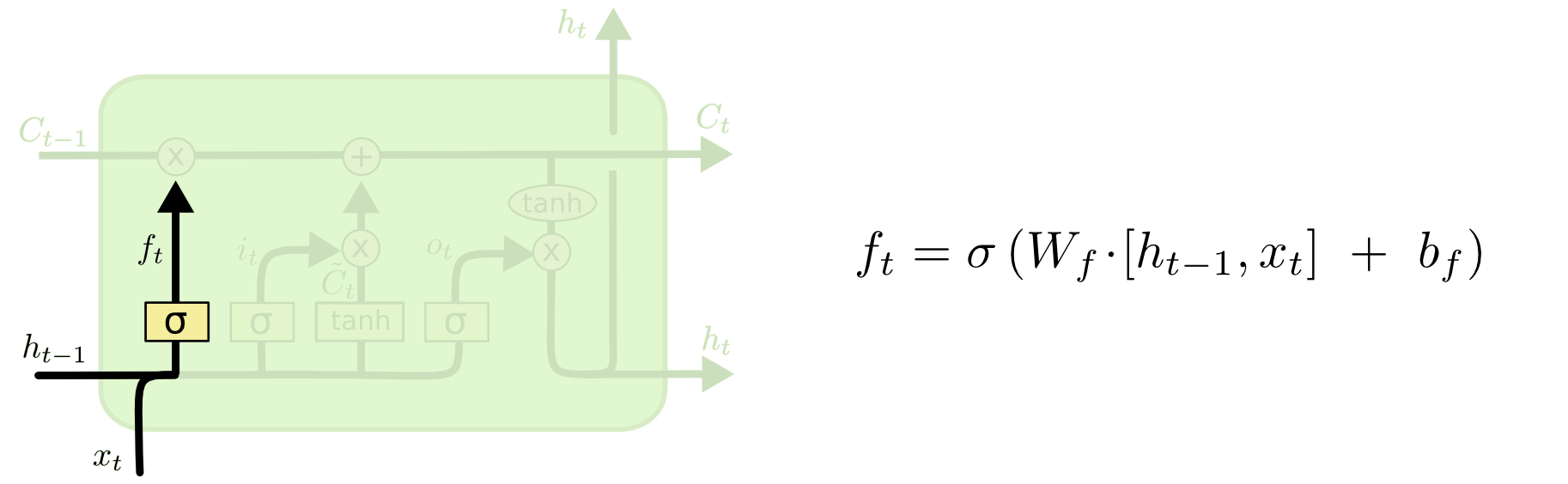
[STEP2.1] 망각 게이트-Forget Gate
- 는 말 그대로 '게이트', 여기서 만들어진 '망각 게이트'를 에 적용해 를 구하는데 사용함, 0~1 사이의 값인데 0은 '완벽히 제거', 1은 '완벽히 보존'
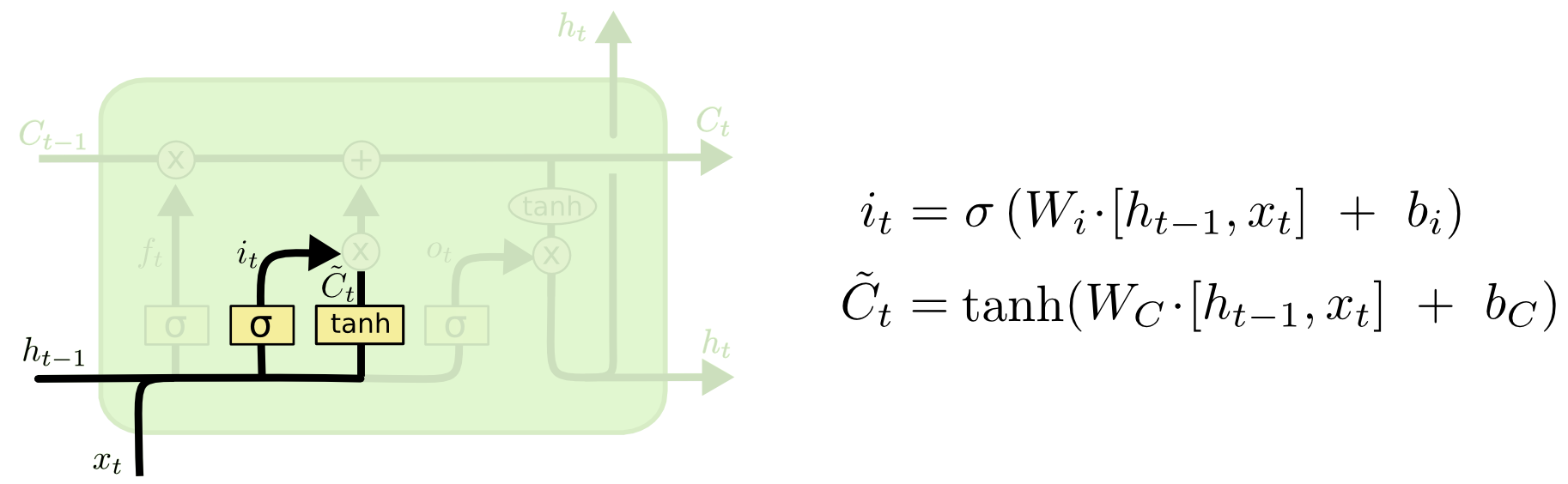
[STEP2.2] 입력 게이트()-Input Gate
- 현재 정보를 기억하기 위한 게이트
(1) Input Gate(): 어떤 값을 업데이트할지 결정
(2) : new cell state()에 추가될 수 있는 새로운 후보 값
input []이 가중치 와 각각 곱해지고, (시그모이드), (하이퍼볼릭탄젠트 함수)를 지난 후, 나온 값들 [] 이 두 값을 후에 cell state를 계산하는데 사용
[STEP2.3] Cell State(셀 상태, )
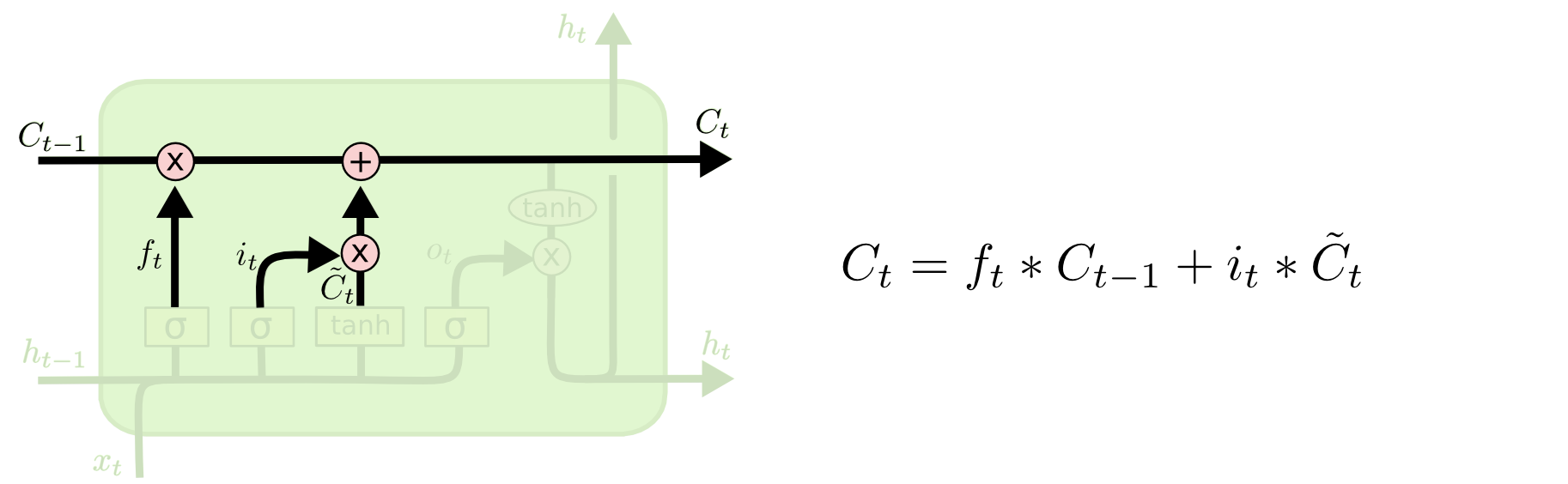

삭제 게이트와 입력 게이트의 영향력을 이해해봅시다. 만약 📌삭제 게이트의 출력 값이 가 0이 된다면, 이전 시점의 셀 상태의 값인 은 현재 시점의 셀 상태의 값을 결정하기 위한 영향력이 0이 되면서, 오직 입력 게이트의 결과만이 현재 시점의 셀 상태의 값 을 결정할 수 있습니다. 이는 삭제 게이트가 완전히 닫히고 입력 게이트를 연 상태를 의미합니다. 반대로 📌입력 게이트의 을 0이라고 한다면, 현재 시점의 셀 상태의 값 는 오직 이전 시점의 셀 상태의 값 의 값에만 의존합니다. 이는 입력 게이트를 완전히 닫고 삭제 게이트만을 연 상태를 의미합니다. 결과적으로는 삭제 게이트는 이전 시점의 입력을 얼마나 반영할지를 의미하고, 입력 게이트는 현재 시점의 입력을 얼마나 반영할지를 결정합니다.
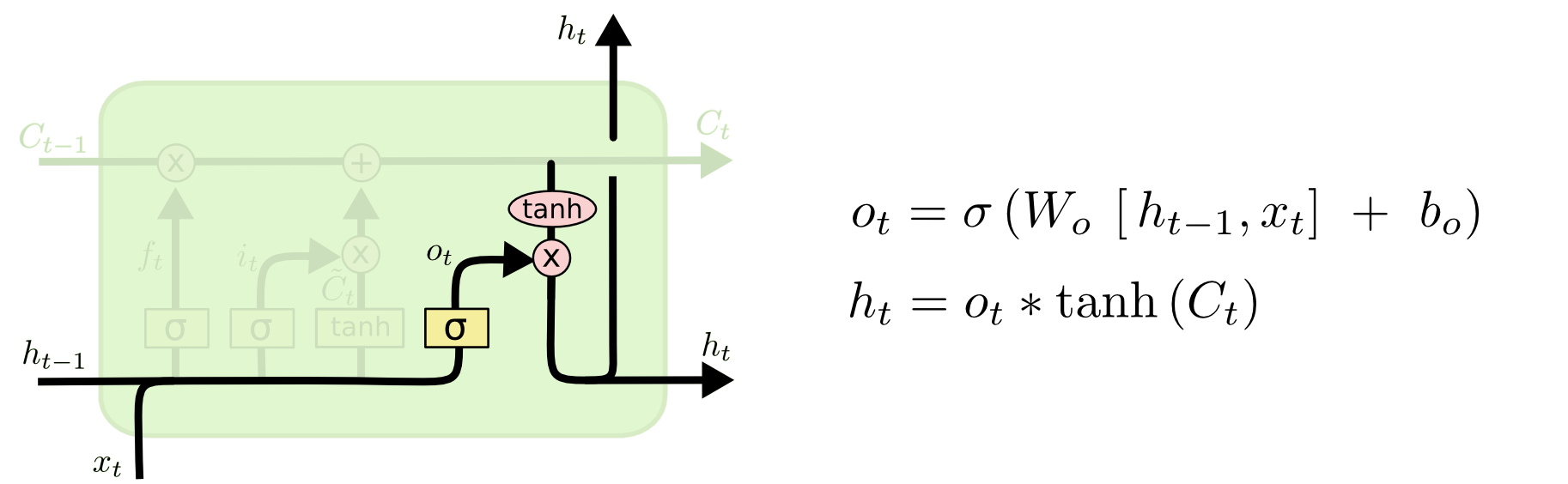
[STEP2.4] 출력 게이트()-Output Gate
[STEP2.5] 은닉상태()-Hidden State
3) GRU
(Gatted Recurrent Unit)
= (업데이트게이트)∘ , ( 없음)
(리셋게이트)
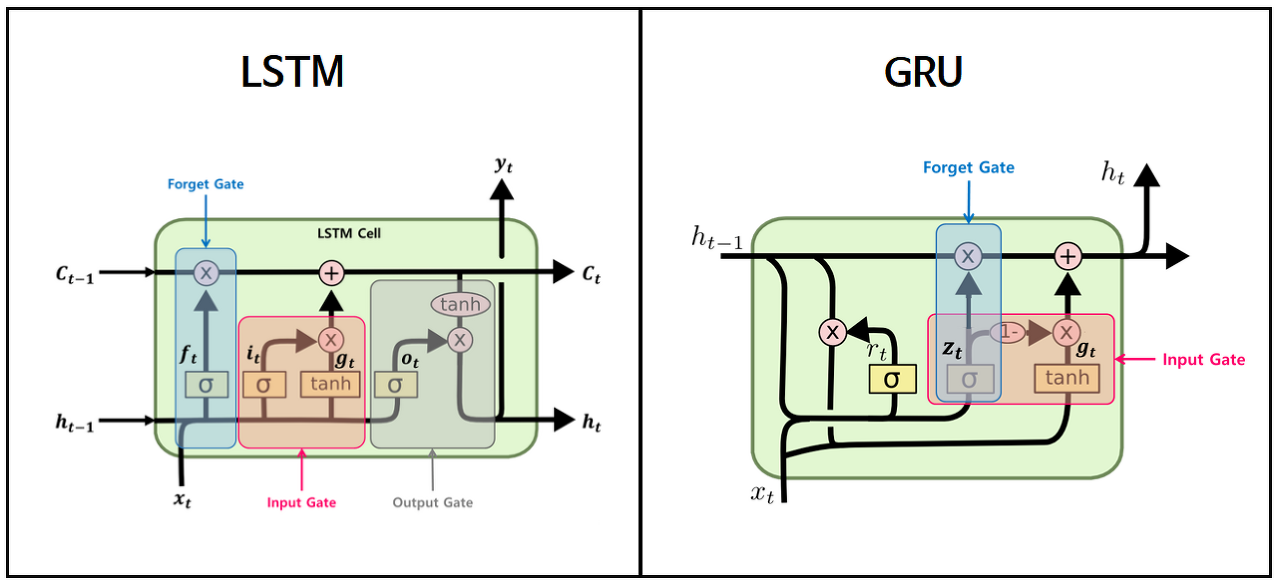
GRU의 핵심
(1) LSTM의 forget gate와 input gate를 통합해 하나의 'update gate'를 만든다. 그리고 output gate는 reset gate로 대체.
(2) Cell State와 Hidden State를 통합한다. (만 존재, Vanila RNN과 동일)
+(3) LSTM에서는 forget과 input이 독립적이었으나, GRU에서는 전체 양이 정해져있어(=1), forget한 만큼 input하는 방식으로 제어한다. 이는 gate controller인 에 의해서 조절된다.
=> 가 1이면 forget gate가 열리고, 0이면 input gate가 열린다.
GRU는 LSTM에 비하여 파라미터수가 적기 때문에 연산 비용이 적게 들고, 구조도 더 간단하지만, 성능에서는 LSTM과 비슷한 결과를 낸다.
LSTM과 다른점
| LSTM | GRU |
|---|---|
| gate 수 3개(forget, input, ouput) | gate 수 2개(reset, update) |
| Control the exposure of memory content(Cell State) | Expose the entire cell state to other units in the network |
| Has sperate input and forget gates | Performs both of these operations together via update gate |
| More parameters | Fewer parameters |
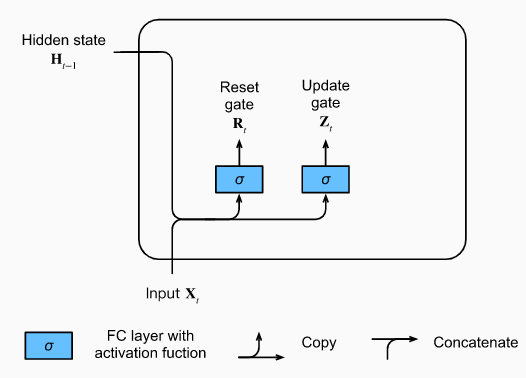
[STEP3.1] 리셋 게이트()-Reset Gate
: 이전의 정보()를 얼마나 잊어야하는지를 결정
[STEP3.2] 업데이트 게이트()-Update Gate
: 이전의 정보(기억)을 얼마나 통과(유지)시킬지를 결정
[STEP3.3] Candidate Hidden State
:hidden layer의 후보로(update gate를 아직 반영하지 않았으므로) reset gate와 을 곱하여, 이전 타임 스텝에서 무엇을 지워야할지를 결정

[STEP3.4] Hidden State
: 이제 update gate를 합칠 차례. update gate는 얼마나 새로운 hidden state가 이전 hidden state와 같을지 아니면 새로운 candidate hidden state이 많이 사용될지를 결정.
=> 가 1이라면 old state를 유지하고, 0이라면 candidate state로 완전히 대체됨.
= ∘
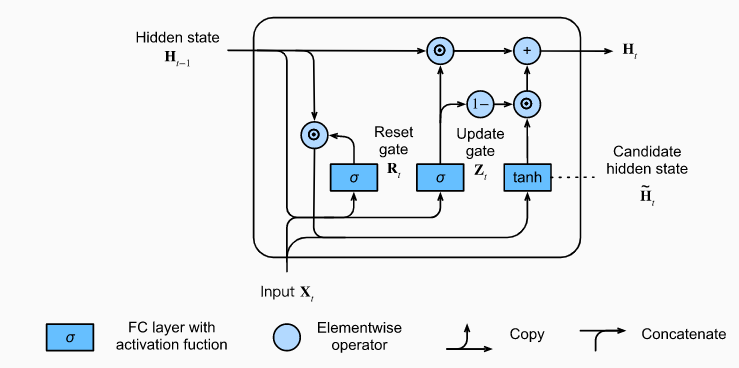
[STEP3.5] 정리
즉, Reset Gate는 short-term dependency를 의미. Update Gate는 long-term dependency를 의미

- 출처: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- 출처: https://hyen4110.tistory.com/26
- 출처: Natural Language Processing with PyTorch_O'REILLY
- 출처: Day2/topic/2_TextClassification_FinTech.ipynb
