
작성자 : 투빅스 13기 오진석
Contents
- Reflections on word representations
- Pre-ELMo and ELMo
- ULMfit and onward
- Transformer archietectures
- BERT
CS224n의 13번째 강의는 단어(word)를 컴퓨터가 이해할 수 있도록 표현하는 방법인 워드 임베딩(word embedding)에 대해 보다 자세히 다룹니다. 단어의 의미를 보다 정확하게 표현하기 위해서는 문장의 문맥을 고려하고 반영해야함의 중요성을 언급하고 있으며, pre-trained Model을 사용함으로써 보다 풍부한 의미의 워드 임베딩을 얻을 수 있다고 말합니다.
첫번째 목파에서는 단어를 표현하는 것의 중요성과 고려해야하는 부분에 대해 간단히 소개하며, 그 이후로는 word embedding 모델을 발전 순서에 따라 설명합니다.
1. Reflections on word representations

단어(word)를 표현(representation)한다는 것은 워드 임베딩(word embedding)이라는 방법을 통해, 단어를 벡터로 표현함으로써 컴퓨터가 이해할 수 있도록 자연어를 적절히 변환해주는 방법을 말합니다. 이렇게 단어를 어떠한 벡터로 표현하는 방법으로는 우리는 앞선 강의에서 Word2vec, GloVe, fastText 등을 학습했습니다.
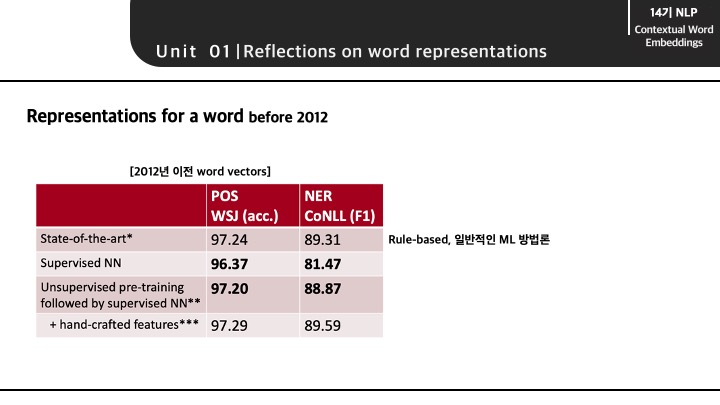
2012년 전까지에는 'POS tag' task와 'NER' tast에서 다음과 같은 성능을 보였습니다.
이 때, 가장 성능이 높다고 보이는 State-of-the-art는 딥러닝 모델이 아닌 rule-based 혹은 일반적인 머신러닝 방법론을 의미합니다.
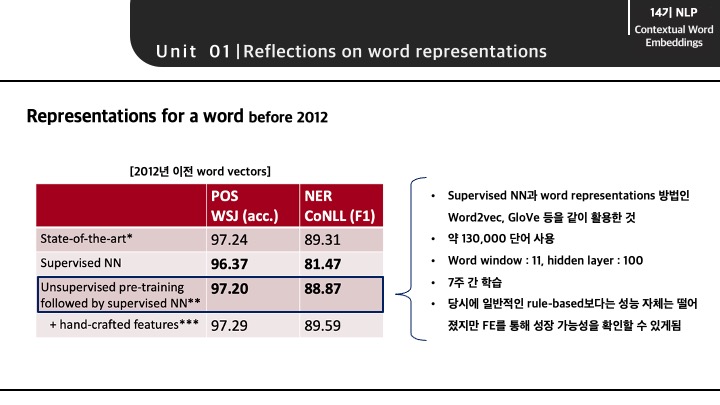
세번째 모델은 word2vec과 같은 unsupervied NN를 supervised NN 방법론과 결합한 방법으로 피처 엔지니어링과 같은 전처리 작업을 조금 거치게 되면 보다 성능이 상승함을 볼 수 있습니다.

2014년 이후 단어를 표현하는 방법으로는 pre-trained된 word vector를 사용하는 방법이 일반적인 random initialize된 word vector보다 성능이 좋음을 보여줍니다. 이 때, pre-trained된 word vector가 성능이 더 좋은 이유는 보다 가지고 있는 데이터보다 방대한 양의 데이터로 학습된 결과를 활용하기 때문에 성능 향상에 도움이 된다고 합니다.

pre-trained된 word vector를 사용하는 것은 또한 unk 토큰을 처리할 때 보다 효과적이라고 합니다. unk 토큰은 보통 데이터 셋에서 잘 나타나지 않는 단어를 일컫거나, test 데이터 셋에만 존재하는 단어를 unk 토큰으로 분류하게 됩니다. 하지만 단순히 횟수로 단어를 unk로 분류하게 되면 unk 토큰이 가지는 의미가 모호해지며 중요한 의미를 가지는 단어를 놓칠 수 있게 됩니다. 이 강의에서는 이러한 unk 토큰을 처리하는 방법으로 3가지를 제시하는데, 그 중 pre-trained word vector를 사용하는 방법이 가장 효과적이라고 말합니다.

다시 돌아와서 단어를 표현하는 함에 있어서 word embedding이라는 방법을 사용할 때도 고려해야할 문제가 있습니다. 바로 1개의 단어를 1개의 vector로 표현하는 것은 동음이의어와 같은 문제를 발생시킬 수 있기 때문입니다. 여기서는 1개의 단어를 1개의 vector로만 표현하게 된다면, vector가 문맥에 따라 달라지는 단어의 type을 고려하지 못하는 문제와 단어의 언어적/사회적 의미에 따라 달라지는 측면을 고려하지 못하는 문제가 있다고 언급합니다.
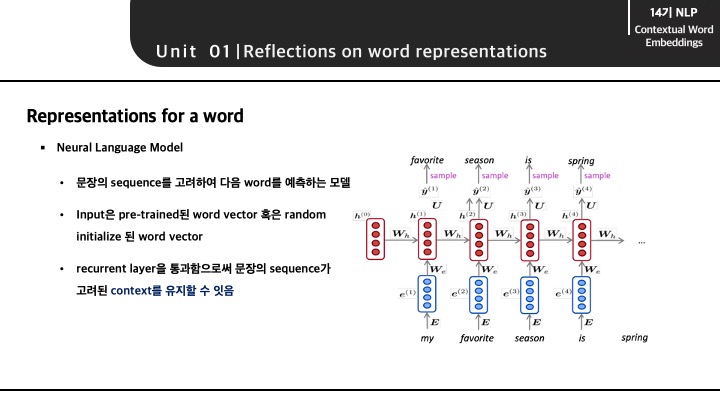
바로 이러한 context, 문맥을 고려하여 word vector를 생성할 수 있는 방법으로 Neural Language Model을 제시할 수 있다고 합니다. LSTM 구조가 적용된 해당 language model은 문장의 sequence를 고려하여 다음 단어를 예측하는 모델로 sequence의 학습을 통해 문맥을 어느정도 유지할 수 있다고 합니다. 그리고 이러한 특징을 활용한 모델의 대표적인 사례가 ELMo 모델입니다.
2. Pre-ELMo and ELMo

두 번째 목차에서는 Pre-ELmo와 ELMo 모델의 구조와 특징에 대해 설명합니다. 먼저 해당 강의에서는 ELMo를 발표한 저자가 ELMo를 발표 이전에 제시했던 TagLM을 Pre-ELMo라고 지칭합니다. Pre-ELMo는 ELMo의 기본적인 구조가 굉장히 유사하며 RNN을 통해 context가 유지되는 word vector를 찾기 위한 가정이 적용되어 있습니다. 또한 Neural Language Model로 word vector를 pre-trained한 뒤에 추가로 학습이 진행되는 Semi-supervied 접근법이 활용되었습니다.
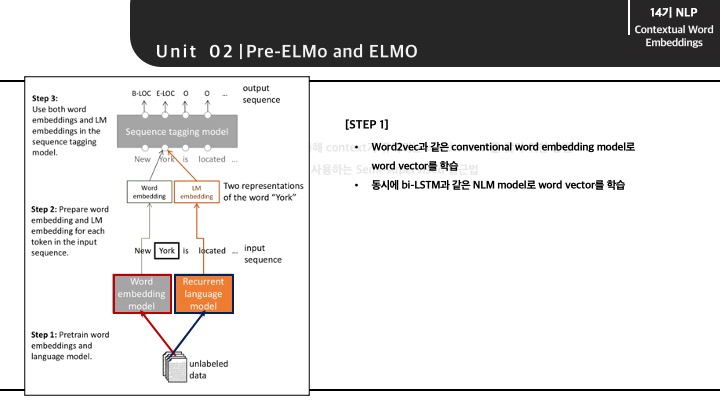
Pre-ELMo의 전체적인 구조는 다음과 같습니다. 어떠한 input이 들어오게 되면 2가지 다른 방법으로 parallel하게 단어가 임베딩됩니다. 한 쪽으로는 Word2vec과 같은 conventional word embedding 모델, 다른 한쪽으로는 bi-LSTM과 같은 RNN이 적용된 word embedding 모델을 통과하게 됩니다.
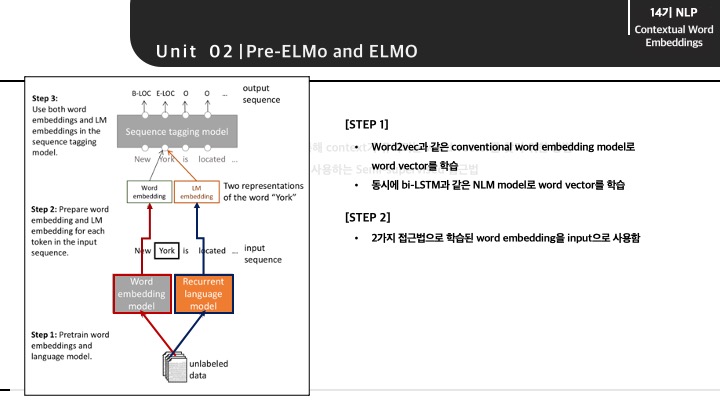
그렇게 2가지 접근법으로 만들어진 word vector를 NER과 같은 small task-labeled에 사용하게 됩니다.
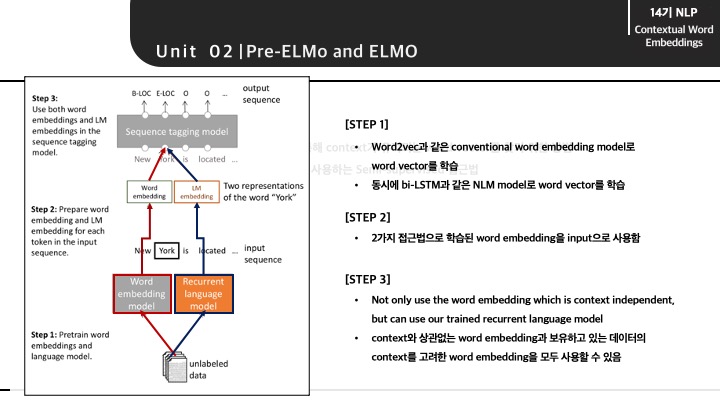
즉, context가 아닌 특징 자체를 고려한 word vector와 데이터의 문맥(context)를 고려한 word vector를 모두 사용하였고 의미를 반영했다고 볼 수 있습니다.
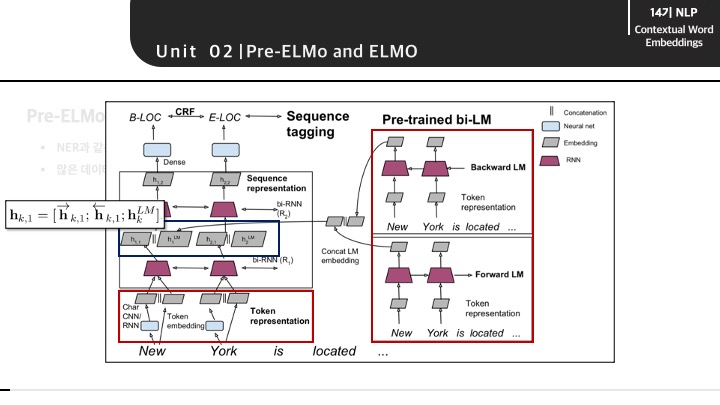
전체적인 구조를 다시 보게 되면 우측에 존재하는 pre-trained model로 학습한 word vector와 char-CNN model로 학습한 word vector를 concat하는 과정을 수식을 통해 확인할 수 있습니다.
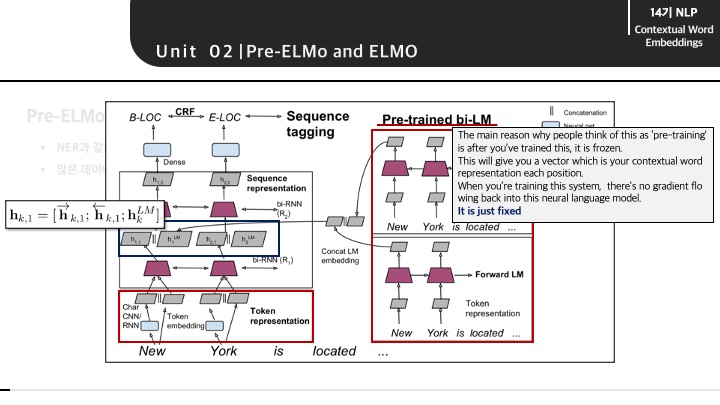
여기서 강의 도중에 한 학생이 질문으로 교수님이 답을 해주게 됩니다. 질문이 정확하게 들리지는 않지만 우측에 존재하는 pre-trianed bi-LM에서 'pre-trained'의 의미에 대해서 물어보는 것 같았고 교수님께서는 위와 같이 답변해줍니다. 여기서 말하는 pre-trained라는 의미는 한번 학습을 통해서 고정된(fixed)된 word vector라는 의미입니다. 그렇다면 char-CNN과 같은 다른 방법으로 word vector가 생성되는 방법에서는 이 word vector가 backpropagation을 통해 계속해서 학습 및 업데이터 됨을 의미하는 것 같습니다.(정확하지는 않습니다 ㅠ)

Pre-ElMo의 저자가 해당 방법론을 보다 일반화하여 새롭게 제시한 모델이 ELMo입니다. ELMo의 특징은 모든 문장 전체를 사용해서 문맥이 반영된 word vector를 학습하는 모델입니다. 이는 보통 window를 지정함으로써 주변 단어를 통해서만 문맥을 고려하게 되는 기존 모델과의 차이를 보입니다. 전체적인 흐름으로는 char-CNN과 같은 모델로 단어의 특징을 고려한 word vector를 구하고 해당 vector를 LSTM의 Input으로 사용해서 최종 word embedding 결과를 도출하는 과정을 가집니다. 이러한 과정을 거치게 되면 'present'라는 동일한 단어임에도 문장에 따라 '선물'과 '현재'라는 다른 word vector로 표현될 수 있게 됩니다.

ELMo의 전체적인 구조는 순방향 Language Model과 역방향 Language Model이 모두 적용된 bidirectional Language Model이라고 볼 수 있습니다. 순방향 모델은 문장 sequence에 따라 다음 단어를 예측하도록 학습되며 역뱡향 모델은 뒤에 있는 단어를 통해 앞 단어를 예측하도록 학습됩니다. ELMo는 모든 layer의 출력값을 활용해서 최종 word vector를 임베딩하는데 이는 최종 layer의 값들로만 word vector로 사용했던 이전 모델들과의 차이점을 보입니다. 해당 내용은 뒤에서 보다 자세하게 설명할 예정입니다.

순방향 모델이 학습되는 과정에 대해서 알아보겠습니다. 먼저 input으로 들어오는 문장과 단어는 char-CNN을 통해 임베딩이 됩니다. 여기서 char-CNN이 사용되는 이유는 최초 임베딩은 context의 영향보다는 단어 자체의 특징을 찾기를 원했고, word2vec 혹은 glove와 같은 pre-trained word embedding 모델과 비교를 위해서입니다.

첫번째 layer는 문맥으로부터 영향을 받지 않도록 설계하였지만 이후 layer인 LSTM layer에서는 문맥을 반영하도록 하였습니다. 첫번째 LSTM layer에서는 char-CNN의 결과에residual connection을 적용하였습니다. residual connection을 적용함으로써, char-CNN으로 반영된 단어의 특징을 잃지않고 유지할 수 있고, 학습 시 역전파를 통한 gradient vanishing 문제를 완화시킬 수 잇었습니다. 그렇게 첫번째 layer에서 얻은 결과로 다음 단어를 예측하는 LSTM layer를 통과하게 됩니다.
이 때, 'I read a book yesterday' 문장에서 'I' 다음으로 예측할 'read'는 현재형과 과거형이 같기 때문에 모델은 'read'를 현재형과 과거형을 구분할 수 없으며, 보통 현재형으로 임베딩을 출력할 가능성이 높다고 합니다. 하지만 역방향 모델을 같이 활용함으로써, 뒤에서 발견되는 'yesterday'로 'read'가 과거형임으로 알 수 있고 보다 정확한 임베딩을 뽑아낼 수 있습니다.

그렇게 순방향 모델과 역방향 모델이 각각 그 다음과 그 전의 단어를 예측하기 위해 학습된 layer 정보다 다음과 같이 표시할 수 있습니다. 해당 그림은 'read'의 다음 단어를 예측하는 순방향 모델, 그리고 'read'의 전 단어를 예측하는 역방향 모델의 'read' 부분만을 추출한 결과입니다. 즉, 'read'에 대한 각 layer별 출력값이 존재하며 확인할 수 있습니다.

다음과 같이 'read'에 대한 각 layer의 출력값만 추출하고 두 모델의 데이터를 모두 활용하기 위해 concat할 수 있습니다.

그렇게 concat된 layer별 출력에 정규화된 가중치를 곱해주며 학습을 통해 최적화합니다. 최종적으로는 모든 layer의 벡터를 더해 하나의 임베딩 벡터라는 word vector를 만들게 됩니다.

이렇게 되면, syntax 특징을 고려한 하위 layer의 정보와 semantics 특징을 고려한 상위 layer의 정보를 모두 활용함으로 효과적인 word vector라고 할 수 있습니다. syntax 정보는 tagging, NER 등과 같은 단어 자체가 가지고 있는 특징을 의미하고 semantics 정보는 문맥이 고려된 특징을 의미합니다.
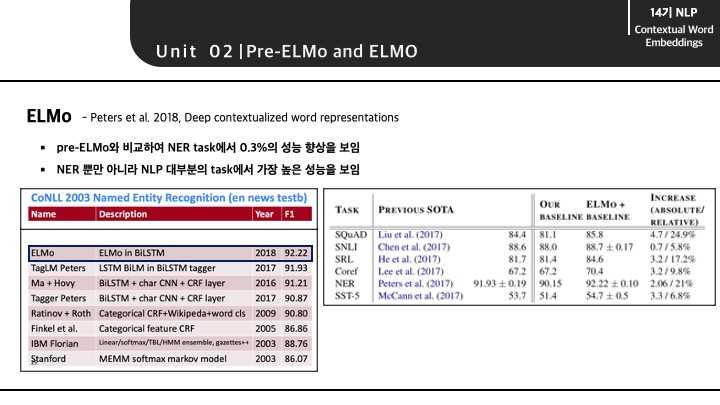
ELMo의 등장이 NLP 분야에서 굉장히 놀라움을 선사했는데, NER뿐만 아니라 대부분의 task에서 SOTA의 성능을 보여주었기 때문입니다.
3. ULMfit and onward

ELMo를 시작으로 contextual word representaion에 대한 관심이 증가하게 되면서 ULMfit이 등장하게 됩니다. ULMfit에서는 NLP에서 본격적으 transfer learning이 도입되게 된 시점이라고 소개합니다. 여기서 transfer learning이란 대량의 다른 데이터로 일반적인 학습을 진행한 뒤에, 목적에 맞게 다시 튜닝을 통해 성능을 개선해 나가는 것을 의미합니다. 여기서 ULMfit은 text classification이라는 목적을 가지게 됩니다.

ULMfit의 전체적인 구조는 다음과 같으며 구조에 따른 학습 과정을 구분할 수 있습니다. 먼저 앞서 언급한 transfer learning부분으로, Language Model이 대량의 corpus를 기반으로 학습하게 됩니다. 다음으로 기학습된 언어 모델을 토대로 주어진 task에 맞게 추가 학습되면서 업데이트를 진행하게 됩니다. 마지막으로는 최종적으로 classifier가 출력되는 부분으로 word vector가 결국 분류기로 출력됨을 의미합니다.

각 과정에 대해서 보다 구체적이게 알아보겠습니다. transfer learning을 의미하는 일반 언어 모델이 학습되는 부분입니다. 논문에서는 Wikipedia의 정제된 28,595개의 article과 word를 기반으로 언어 모델을 학습(pre-trained)했다고 말합니다.

두번째 과정은 주어진 task에 맞추어 다시 언어 모델을 튜닝하는 부분입니다. 예를 들어, 주어진 task에서 100개의 텍스트와 그에 따른 label이 있다면, 해당 데이터만을 가지고 다시 학습 및 업데이트 과정을 거치게 됩니다.
이 때, 튜닝 시 사용하는 2가지 기법으로는 Discriminative Fine-tuning과 Slanted triangular learning rates가 있습니다.
- Discriminative Fine-tuning: 언어 모델을 튜닝할 때, 각 layer별 학습율(learning rate)을 서로 다르게 조정하는 것입니다. 깊은 layer에 대해서는 상위 layer에 비해 더 작은 학습율을 부여합니다.
- Slanted triangular learning rates: 튜닝 횟수에 따라서, 초반에는 작은 학습율을 적용하다가 점차 학습율을 증가하고 약 200번의 학습 후, 다시 학습율을 점진적으로 감소시킵니다.

ULMfit의 결과는 다음과 같습니다. 좌측 그래프를 보게 되면 pre-trained의 중요성을 볼 수 있습니다. train 데이터셋이 굉장히 부족함에도 불구하고 pre-trained된 ULMfit 모델을 사용하게 되면 error rate가 굉장히 낮음을 알 수 있습니다.

ULMfit 이후로는 모델의 parameter를 늘리고 pre-trained할 데이터양을 늘려 기하급수적으로 리소스가 필요한 모델들이 등장하게 됩니다. GPT, BERT, GPT2와 같은 모델은 글로벌 기업에서 엄청난 양의 데이터를 기반으로 학습한 pre-trained 모델을 제공합니다. 또 해당 모델들은 LSTM 모델이 아닌 모두 Transformer 기반의 모델임을 알 수 있습니다.
4. Transformer archietectures

Transformer기반 모델이 등장하게 된 계기는 LSTM 모델에도 발견되는 RNN의 태생적인 한계가 여전히 존재하기 때문입니다. 먼저 RNN은 sequential한 특징을 고려하기 때문에 병렬적 계산이 불가능하여 매우 느린 속도를 보입니다. 또한 입력 데이터의 sequential한 특징으로 긴 입력에 대한 Long-term Dependency 문제가 항상 존재했었고 LSTM, GRU로 해당 문제를 어느정도 해결할 수 있었지만 완전히는 불가능했습니다.
이 때, 모든 state를 참조할 수 있기 때문에 sequential한 특징에서 자유로운 Attention 매커니즘만을 활용한다면 RNN 계열의 모델의 한계를 해결할 수 있다고 생각했기에 Transformer 기반 모델들이 등장하게 됩니다.
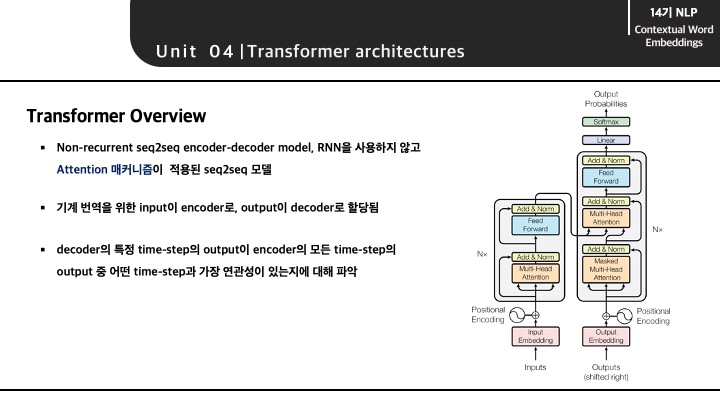
Transformer는 기계 번역을 위해 존재하는 input과 output이 encoder와 decoder로 구분되어 진행되는 seq2seq 모델입니다. 이 때, decoder의 어떤 step과 encoder의 전체 step 중 가장 연관성 있는 한 step을 찾아가면서 보다 효과적인 seq2seq 과정을 거치게 됩니다.
Attention이 모든 state를 참조할 수 있다는 의미는 decoder에서 output으로 나오는 매 step마다, encoder의 전체 step을 참고하기 때문입니다. 이 때, decoder가 encoder를 참고하는 과정에 있어 decoder의 단어와 step에 따라 attention value가 달라지게 됩니다.
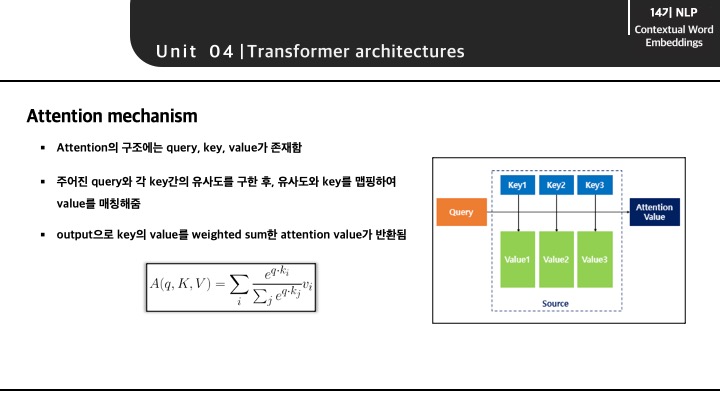
Tranformer 모델의 구조를 알아보기 전에 Attention 매커니즘에 대해서 아주 간단히 알아보겠습니다. 보통 Attention의 구조에는 query, key, value가 존재하며 3가지 특성을 가지고 attention value를 도출하게 됩니다.
Attention(Q, K, V) = Attention Value
Attention 매커니즘은 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다. 그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다. 그리고 유사도가 반영된 '값(Value)'을 모두 더해서 반환합니다. 여기서는 이 값을 Attention Value이라고 합니다.
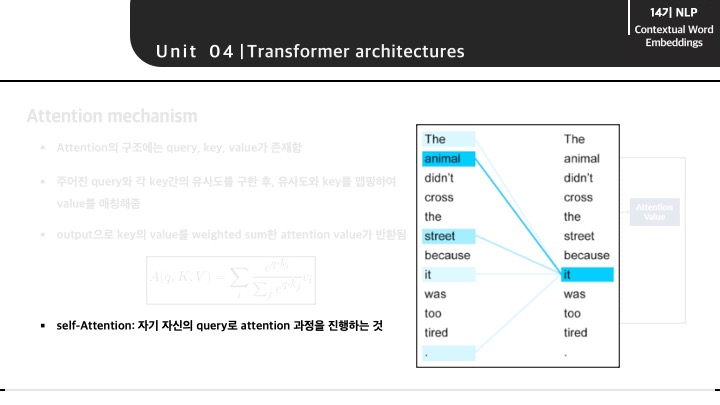
또 등장하는 개념은 self-attention 입니다. self-attention이란 자기 자신의 query로 attention value를 구하는 것으로, 그림과 같이 특정 단어가 자신의 문장에서 다른 단어와의 attention value를 구함으로써 dependency와 같은 value의 높고 낮음을 구할 수 있게 됩니다.
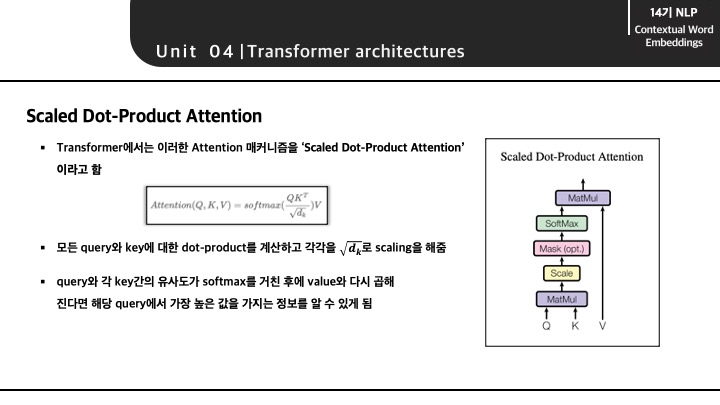
이렇게 self-attention이 일어나느 부분을 논문에서는 'Scaled Dot Product Attention'이라고 하는데, 마지막 softmax를 통해 어떤 step? 단어?와의 값을 뽑아낼 수있습니다.
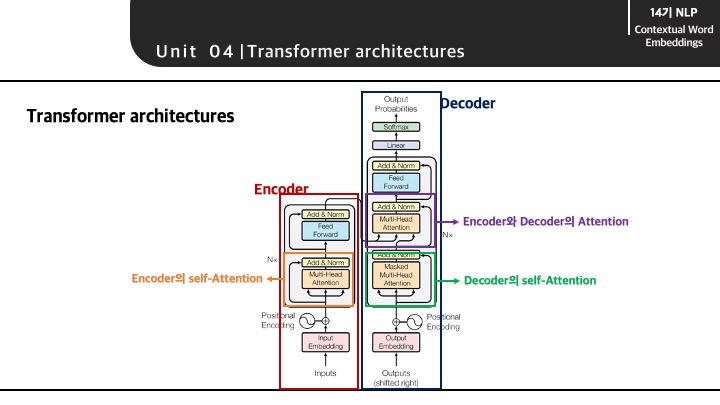
Transformer의 전체적인 구조는 다음과 같습니다. Encoder와 Decoder로 구성되어 있는 transformer의 구조에는 Multi-Head Attention을 또 확인할 수 있습니다. 여기서 보이는 Multi-Head Attetion 부분이 바로 self-attention이 발생되는 지점입니다.
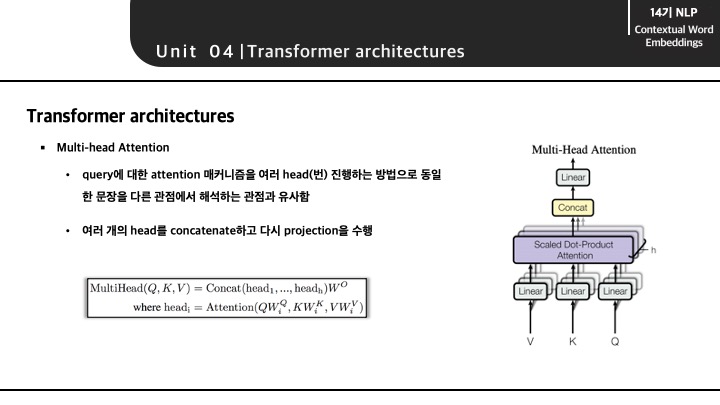
Multi-Head Attention이란 새로운 개념이라기 보다는 앞서 설명한 attention 매커니즘이 여러번 적용된 개념입니다. Multi-Head가 의미하는 것은 다양한 관점에서 바라볼 때, 보다 풍부한 정보를 얻을 수 있다는 것에 착안하여, attention을 다수로 진행함으로써 보다 많은 정보를 가져와 projection하여 다음 layer에 전달하는 과정을 말합니다.
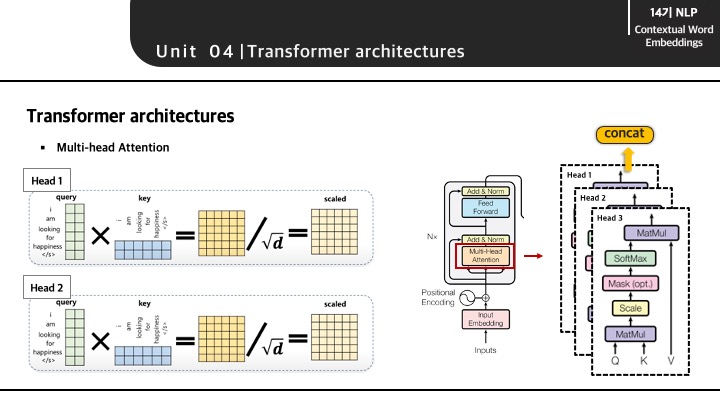
Multi-Head Attention이 이뤄지는 과정을 간단하게 시각화하게 되면 다음과 같습니다. 각 Head는 하나의 attention 과정을 의미하며, Scaled Dot Product Attention 과정이 각각 발생합니다. 그렇게 발생한 Head별 output은 concat되어 다음 layer로 전달되게 됩니다.
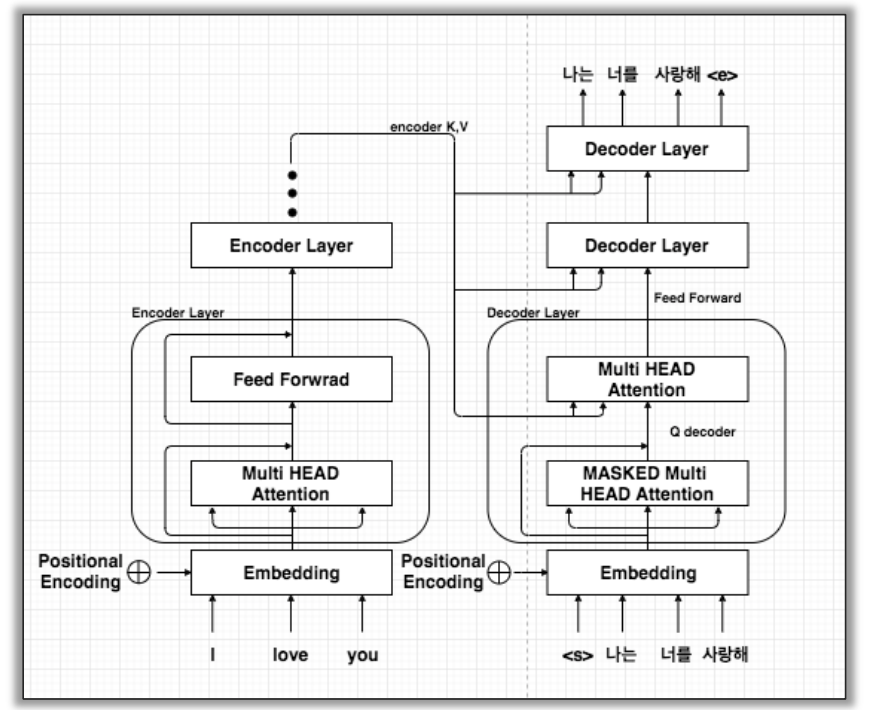
이러한 과정을 거치는 Transformer 모델을 예시로 보게 되면 다음과 같습니다. 본래 모든 과정을 살펴보게 되면 Embedding 과정과 Feed Forward 등의 과정이 있지만 이번 내용에서는 attention 과정이 이뤄지는 부분에 보다 집중하였습니다.
'I love you'라는 문장이 Encoder에 들어오게 되면 임베딩을 거친 후에 Multi-Head Attention 과정을 거칩니다. 여기서는 'I love you'의 각 단어가 문장 안에 존재하는 단어들과의 attention value를 통해 dependency를 확인할 수 있습니다.(여기서 언급한 dependency는 CS224n 5장의 dependeny를 의미하는 것이 아닌, 단어와 단어와의 연관도 정도로 표현하였습니다.) 반대로 Decoder 부분에서도 번역된 문장이 self attention 과정을 거칩니다. 다음으로 self-attention을 거친 두 문장은 Multi-Head Attention 과정을 거치면서(정확하게는 self-attention이라고 표현할 수는 없을 것 같습니다.) 보다 정확한 번역을 가능하게 해주는 것으로 이해했습니다.
5. BERT

드디어 BERT 입니다. 앞서 살펴본 Transformer는 기계번역을 위한 seq2seq translation을 의미합니다. 하지만 BERT는 Transformer의 encoder부분을 차용하여 Bi-directional Language Model을 구축한 모델입니다.
BERT가 발견한 language model의 한계점은 기존에 가지고 있던 bi-direction의 문제점입니다. 보통 bi-direction은 ELMo에서도 확인할 수 있듯이, 순방향과 역방향이 모두 적용된 의미를 가집니다. 하지만 이러한 bi-direction의 순방향과 역방향은 각각 독립적으로 적용되기 때문에 순방향 혹은 역방향이라는 sequence를 가지게 됩니다. 즉, 다음 단어 혹은 전 단어를 예측할 때에도, 그 때까지 존재하는 단어만을 기반으로 예측에 활용할 수 있다는 의미입니다. 결국 순방향과 역방향 모델을 모두 적용함에도 불구하고 단어를 예측함에 있어 전체 단어를 모두 활용할 수는 없다는 것을 말합니다.
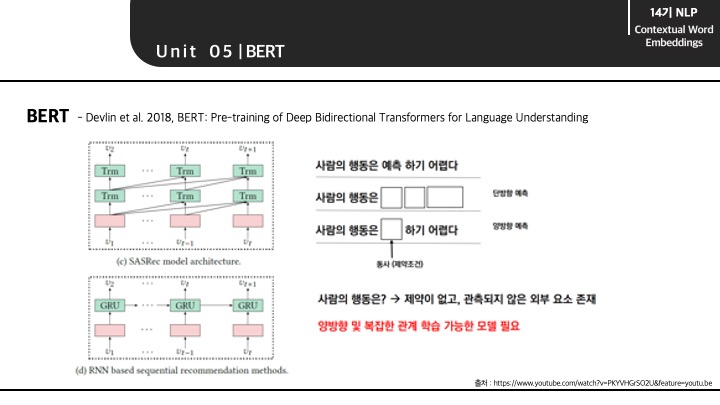
앞서 언급한 기존의 bi-direction은 순방향, 역방향 모델을 같이 활용한다고 해도 결국은 각 모델은 단방향 예측만 가능함을 알 수 있습니다. 하지만 위와 같은 양방향 예측이 한번에 가능하다면 가운데 들어갈 어떤 단어를 예측함에 있어 보다 많은 정보를 기반하여 가능하게 됩니다.

BERT는 이러한 문제를 Masked Language Model을 적용함으로써 해결할 수 있었습니다. 문장에 존재하는 단어 중 일부를 masked 처리한 뒤에, maksed 처리된 단어를 나머지 모든 단어로 예측하는 과정을 말합니다. 이렇게 되면 masked된 단어를 제외한 모든 단어를 활용할 수 있게 되면서 순방향과 역방향의 모든 문맥을 한번에 고려할 수 있게 됩니다.
BERT는 2가지 목적 함수를 가집니다. 첫번째는 앞서 언급한 masked된 단어를 예측하는 mask prediction이며 두번째는 문장과 문장간의 연속성 여부에 대한 정보를 학습하는 Next sentence prediction입니다.
참고자료
- KoreaUniv DSBA, [CS224N]-13. Contextual Word Representation and Pretraining, 이정훈
- Jeong Ukjae, CS224n Lecture 13 Modeling contexts of use: Contextual Representations and Pretraining
- wikidocs, 딥 러닝을 이용한 자연어 처리 입문 – 07) 엘모(Embeddings from Language Model, ELMo)
- Minsuk Heo 허민석, ELMo (Deep contextualized word representations)
- 전이 학습 기반 NLP (2): ULMFiT, 박성준
- wikidocs, 딥 러닝을 이용한 자연어 처리 입문 – 01) 어텐션 메커니즘 (Attetion Mechanism)
- Platfarm tech team, 어텐션 메커니즘과 transfomer(self-attention)
- 포자랩스의 기술 블로그, Attention is all you need paper 뽀개기
- KoreaUniv DSBA, Transformer & BERT, 김동화
- KoreaUniv DSBA, BERT4REC, 이정호
