Multivariate Guassian Distribution
Speech Recognition에서 GMM을 왜 알아야 할까?
Speech data를 이해하기 위해서는 Multivariate Guassian Distribution이 필요하기 때문이다. 그리고 이를 찾아주는 모델이 GMM이다. 그렇다면 왜 Multivariate Gussian Distribution이 필요한지부터 이야기해보자.
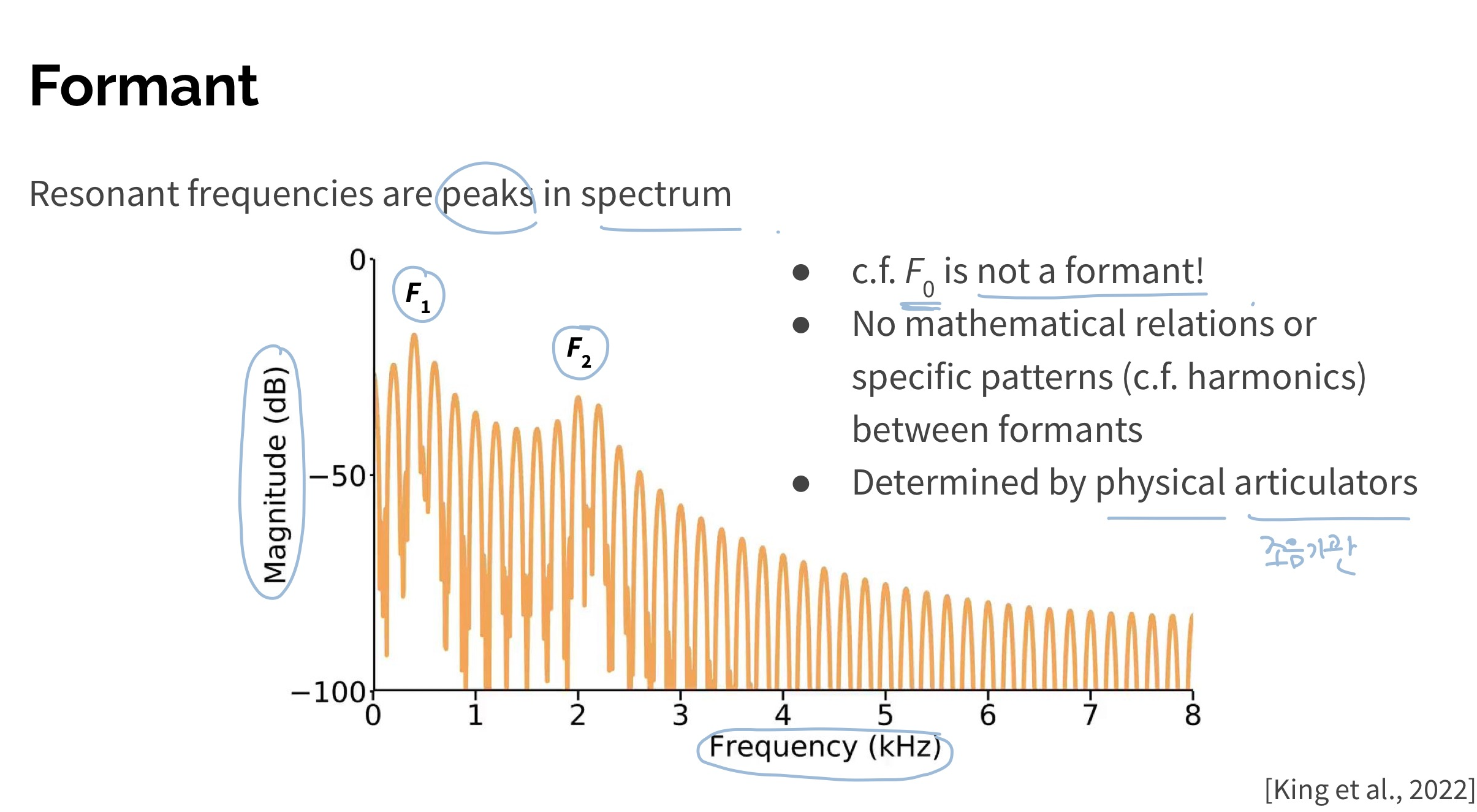
Acoustic data(sound)는 frequency domain을 x축으로 뒀을 때, 여러 개의 Formant(Bell distribution)으로 구성되어 있다. spectrum이란 어떤 frequency(주파수)에 어느 정도의 magnitude(음향에너지)가 있는 지를 그래프로 명확하게 표현한 것이다. 그리고 spectrum에서 magnitude가 두드러지게 큰 각각의 봉우리를 Formant라고 한다.
Formant는 acoustic data에서 중요한 요소이다. 특히 Formant는 Vowels(모음)의 특질을 구성한다. 사람들은 Formant가 같으면 동일한 모음으로, 다르면 서로 다른 모음이라고 인식한다.
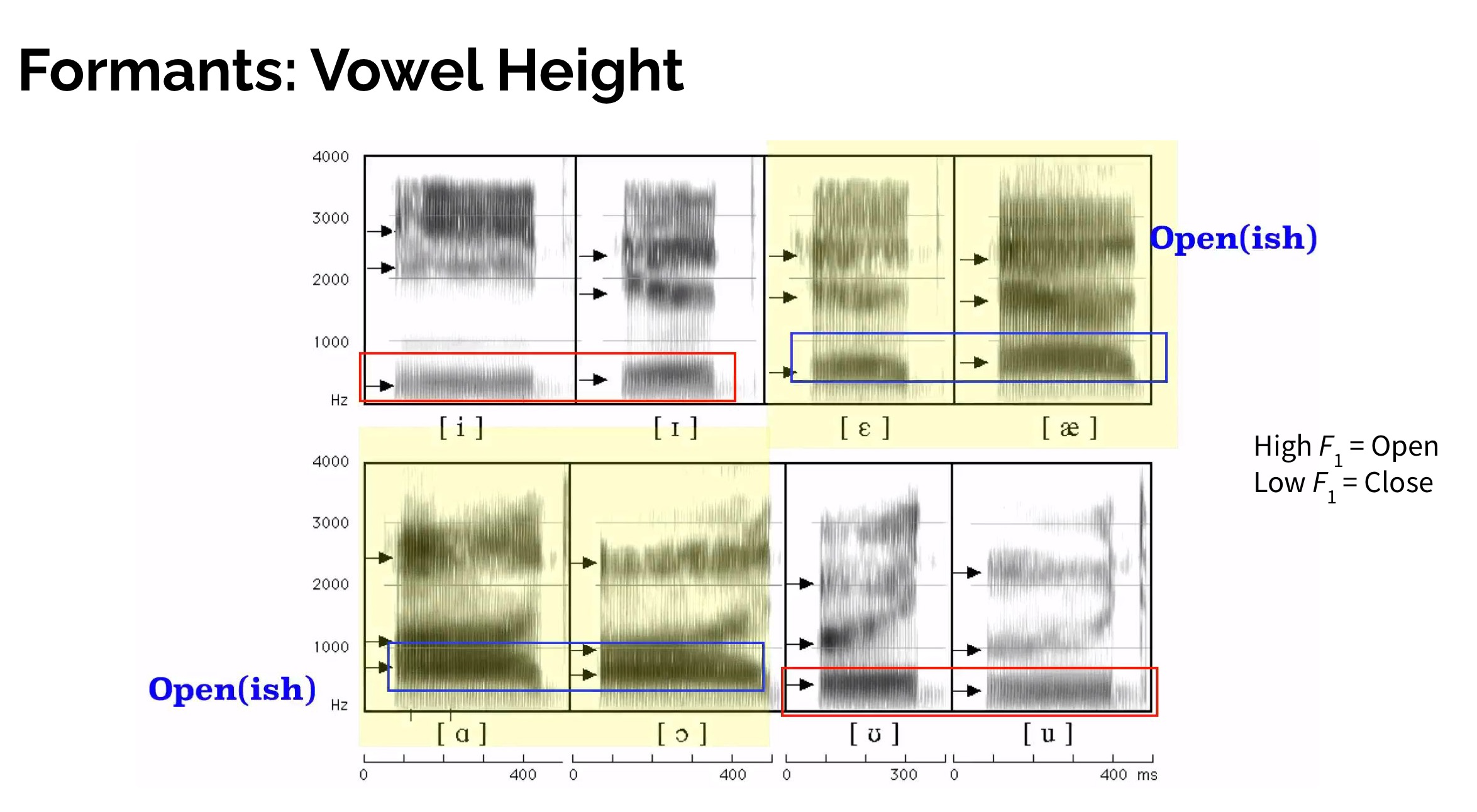
Acoustic data의 특징을 살펴보면,
(1) Not uniform
(2) Range: Not strictly limited
(3) Somehow mountain-like (bell-shape) around each formant: not really skewed
(4) Has long tails at both ends
==> Multivariate Gaussian Distribution이 최적
이와 같이 s(sound)를 x(speech signal)로 바꿔주기 위해서는 Multivariate Guassiana Distribution이 필요하다. 이를 찾는 방법 중 하나가 GMM이라 할 수 있겠다. 우선 GMM을 설명하기에 앞서 이를 위해 Unvariate Guassian Distribution을 찾는 방법인 MLE에 대해 간략히 살펴보고자 한다.
MLE(Maximum Likelihood Estimation)
이 X 데이터를 가장 잘 설명하는 분포(distribution) = = parameter 를 찾는 것.
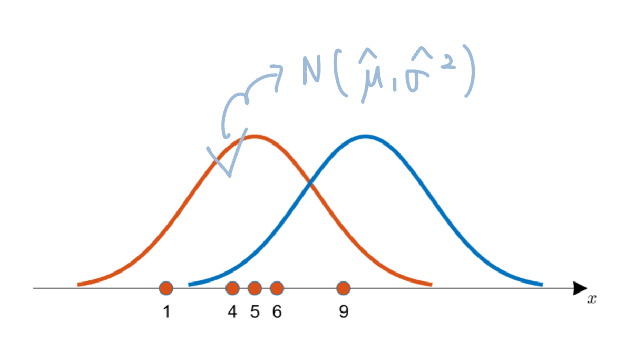
그렇다면 데이터를 설명하는 최적의 m개의 분포를 찾으려면?
GMM(Gaussian Mixture Model)
Problem:
(x데이터에 할당 된)label을 얻기 위해선 distribution(분포)이 필요하고, distribution을 얻기 위해선 label이 필요(=즉 x데이터가 각각 어느 라벨에 속하는지 알아야함)
=> distribution을 random하게 설정 or 데이터 x의 label을 random하게 설정
ex. , , ,,,,,
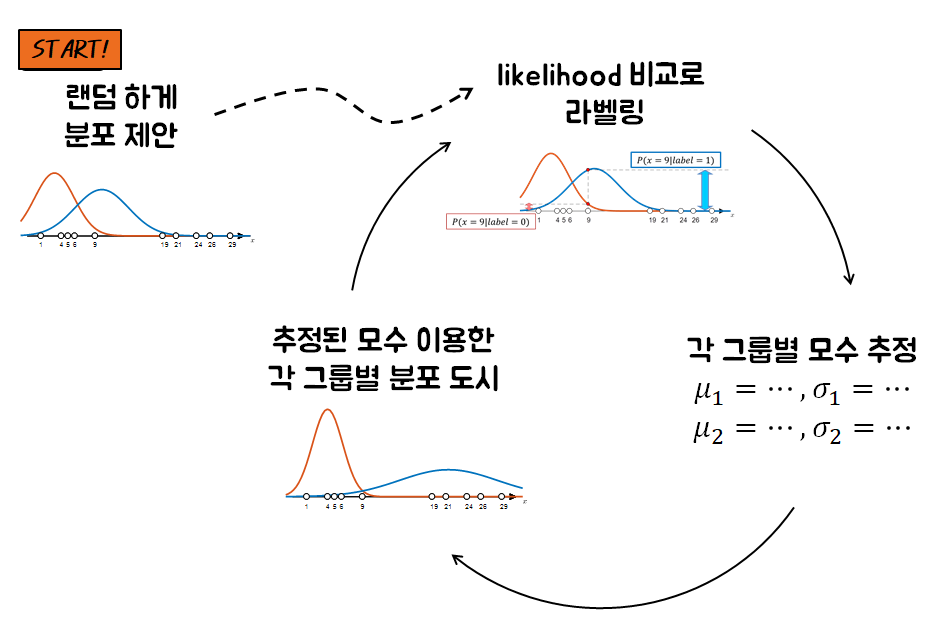
이와 같은 방식으로 label이 주어져있지 않은 데이터에 대해 데이터셋은 정규분포를 이룰 것이라 가정하고 clustering을 수행해주는 과정을 Gaussian Mixture Modeling이라고 한다.
이것은 EM-알고리즘(Expectation-Maximization)의 응용 중 하나이다.
E-step(Expectation): log-likelihood의 기댓값을 계산 = x변수의 label을 update
M-step(Maximization): Maximum Likelihood Estimation을 수행 = 모수(μ,σ)를 update
EM for GMM
: Acoustic data, : label, : distribution parameters


expected log-likelihood = (x가 'label m'에 속할 확률 * 'label m' 분포에서의 x likelihood)

