목차
- MySQL Optimizer
- Join
- Index
- Etc
- Query Plan
- Practice
3. INDEX
인덱스의 종류
B-Tree
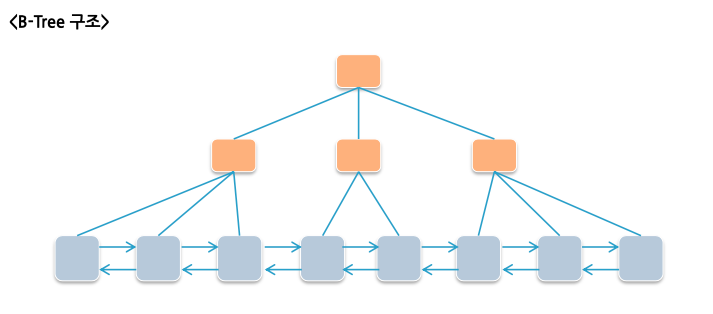
- MySQL에서는 기본적으로 B-Tree (Balanced Tree) 형태의 인덱스 구조를 사용합니다.
- Leaf 노드는 Double Linked List로 연결됩니다. (인덱스를 통한 정렬)
- 인덱스 트리를 타고 스캔할 수도 있고, 하나의 값을 찾아가서 이후 값들을 링크드 리스트를 타고 스캔할 수도 있습니다.
- Memory 엔진의 경우 HASH 인덱스를 지원하고, MyISAM 엔진은 GIS 처리를 위한 R-Tree (Spatial Key)를 지원합니다.
- 참고) MySQL 8.0에서 MyISAM 엔진은 없어졌습니다.
Clustered Index / Non Clustered Index
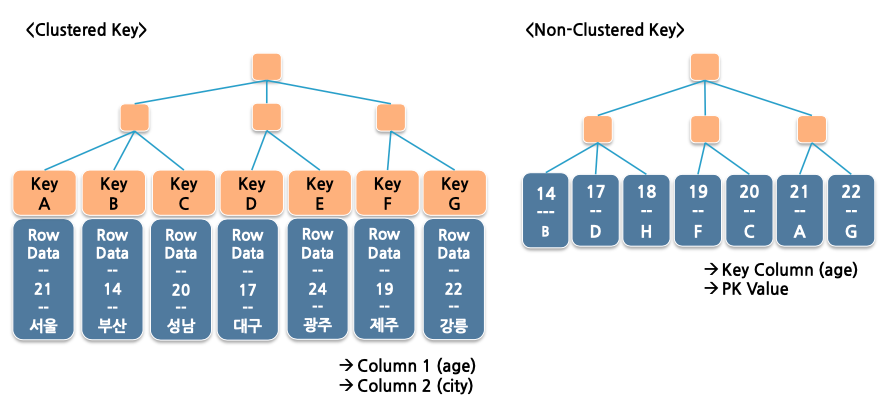
- InnoDB 엔진은 B-Tree 구조를 기본으로 Clustered 인덱스 구조를 가집니다.
- Clustered 인덱스의 Leaf Node에 모든 Row 데이터를 저장하여, Primary Key 혹은 Unique Key가 Clustered Key 역할을 수행하며 Clustered Key는 한 테이블에 1개만 존재합니다.
- Clustered Key를 통해 스캔하는 경우, 데이터가 모두 존재하므로 매우 빠르게 스캔할 수 있습니다.
- Primary/Unique Key 모두 선언되지 않은 테이블의 경우에는 6 byte의 Hidden Key를 생성합니다. (rowid)
- PK가 있다면 PK가 Clustered Key, PK 없고 UK가 있다면 UK가 Clustered Key, 모두 없으면 Hidden Key가 Clustered Key가 됩니다.
- Hidden Key는 사용할 수 없으므로 PK나 UK를 생성하도록 합니다.
- Non-Clustered Key는 데이터의 물리적인 위치 대신 PK 값을 참조합니다.
- Non-Clustered는 Key만 가지기 때문에 나머지 데이터는 저장하고 있지 않습니다.
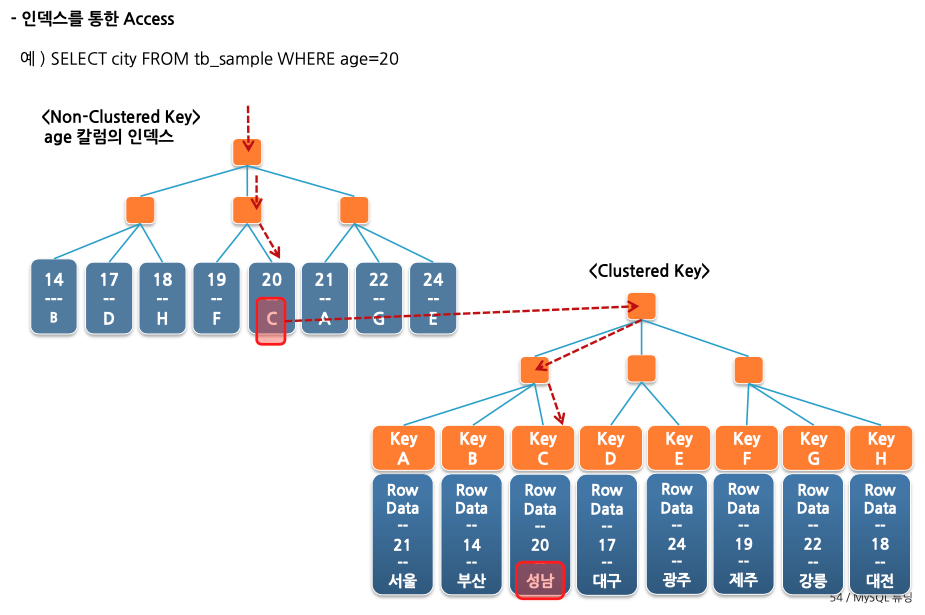
Non-Clustered Index로 데이터를 조회한다면 Non-Clustered Index 한 번, Clustered Index 한 번으로 총 인덱스 트리를 두 번 타게 됩니다.
복합인덱스
더 모여있는 데이터를 먼저 인덱스로 설정해주는 것이 좋습니다.
또한 =(Equal) 조건은 선행(좌측)으로 배치 <, >, Between등의 Range 조건 혹은 order by, group by 조건은 후행(우측)으로 배치합니다.

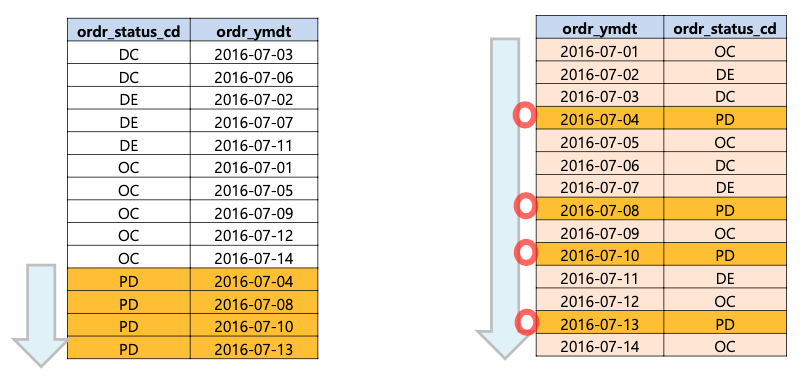
첫번째 경우로 복합인덱스를 설정하면 4건을 스캔하게 되고,
두번째 경우로 복합인덱스를 설정하면 15건을 스캔하게 됩니다.
예시와 달리 조건 2개가 모두 Range, Range 라면 하나의 컬럼에만 인덱스를 거는 것이 좋습니다.
만약 시분초까지 저장되는 컬럼이라면 같은 값이 존재하는 경우가 잘 없기 때문입니다.
실제 ordr_ymdt와 같은 타임스탬프 컬럼을 매우 많이 사용하므로 모든 경우의 복합인덱스를 설정하지 않고, ordr_ymdt에만 인덱스를 걸고 sort하는 것이 좋을 수 있습니다.
조인연결고리 이상
-
조인 연결고리는 양쪽 인덱스를 가지고 있어야 합니다.
- 조인의 참여하는 키 중 하나는 무조건 PK가 되어야 합니다.
- type All -> 풀 테이블 스캔(인덱스 사용X)
- 조인컬럼이 되는 PK, FK 양쪽 모두에 인덱스가 존재하지 않는 경우 조인 효율이 떨어질 수 있습니다.
- 양쪽 모두에 인덱스가 존재하지 않는 경우 조인의 방향이 고정될 수 있습니다.
- 조인의 참여하는 키 중 하나는 무조건 PK가 되어야 합니다.
-
예시
예매가 1 티켓이 N인 1:N의 상황 (하나의 예매에 여러개의 발권이 나타나는 구조)

👉 의도와 다르게 full table스캔이 나타난 다음 eq_ref가 되면 조인 연결고리를 의심할 필요가 있습니다.
형변환

파란색으로 적힌 컬럼에는 단일 컬럼 인덱스가 설정되어 있습니다.
🤔 그렇다면 WHERE 조건에서 양쪽의 형이 다른 경우 인덱스를 탈게 될까요 안탈게 될까요?
select * from cust where ordr_no= '1';
👉 인덱스를 탑니다. 문자 '1'이 숫자 1로 형변환되게 되므로 인덱스 스캔에 문제가 없습니다.select * from cust where ordr_status_cd = 10;
👉 인덱스를 타지 않습니다. ordr_status_cd 쪽이 숫자로 형변환되므로 인덱스의 정보를 활용할 수 없습니다.select * from cust where ordr_ymdt = '2011-02-17';
👉 인덱스를 탑니다. 문자형은 date/time형태로 형변환 되므로 인덱스를 활용할 수 있습니다.select * from cust where ordr_ymdt = cast('2011-02-01' as datetime);
👉 인덱스를 탑니다. 상수쪽이 datetime으로 형변환 되므로 인덱스를 활용할 수 있습니다.select * from cust where substring(ordr_ymdt , 1, 4) = '2011' and substring(ordr_ymdt , 6, 2) = '02';
👉 인덱스를 타지 않습니다. 컬럼쪽에 명시적인 형변환이 일어나므로 인덱스를 활용할 수 없습니다.
👉 이는 between으로 쿼리를 변경하여 해결할 수 있습니다. (2011-02-01 ~ 2022-02-28)
형변환에는 우선순위가 있습니다.
- 문자와 숫자가 만나면 문자가 숫자로 형변환 됩니다.
- 문자와 날짜는 양쪽으로 형변환됩니다.
유리한 방향으로 형변환되며, 변수쪽이 형변환되면 인덱스를 탈 수 없게 됩니다.
Covered Index
쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스를 커버링 인덱스 (Covering Index 혹은 Covered Index) 라고합니다.
- SELECT 구문의 요청 칼럼과 WHERE 필터 등이 특정 인덱스의 구성 칼럼인 경우
- 데이터에 대한 접근 없이 인덱스 만으로 쿼리의 결과 생성 가능
- EXPLAIN 결과의 Extra 필드에 “Using index” 표시
- Clustered Key의 값은 모든 Non-Clustered Key에 포함되어 있음

위 그림은 cust_id가 pk, age가 단일 컬럼 인덱스인 경우입니다.
데이터 접근 없이 인덱스만으로 쿼리 결과 생성 가능한 경우이므로 Covered Index의 경우에 해당합니다.
explain 결과를 살펴보면, Extra에 Using Index으로 표시됩니다. (매우 좋은 케이스)
NULL의 인덱싱
- MySQL은 NULL값도 인덱싱 처리가 됩니다.
- IS NULL 조건으로 검색 시에 인덱스 range scan으로 처리할 수 있습니다.
mysql> update cust set age = null where cust_id = 10;
mysql> update cust set age = null where cust_id = 20;
mysql> explain SELECT * FROM cust WHERE age is null ; /* cust 테이블의 age 컬럼 속성이 nullable일때 */
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | cust | ref | idx2_age | idx2_age | 2 | const | 2 | Using index condition |
+----+-------------+-------+------+---------------+----------+---------+-------+------+-----------------------+- NOT NULL 컬럼에 NULL 비교를 하게되면, 불가능한 비교에 해당하므로 스키마 정보만 보고 빠르게 Impossible WHERE임을 알려줍니다.
mysql> explain select * from cust where zip_cd is null;
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------+- NULL 값을 인덱싱 하기 위한 1bit의 추가공간 필요합니다.
Dynamic 쿼리를 위한 인덱싱 구성
서비스 페이지 보다는 어드민 페이지와 같이 조건이 매우 많이 들어간 검색창의 경우에 인덱싱을 어떻게 구성하여야 할까요?
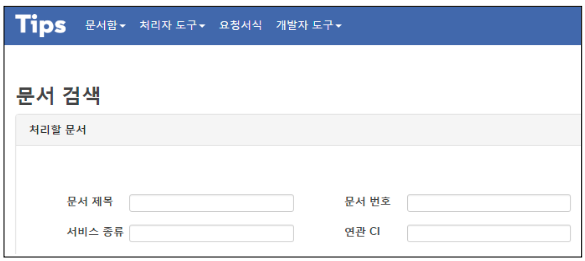
select * from document
where [ 문서제목 = ? ] AND [ 문서번호 = ? ] AND [ 서비스중류 = ? ] AND [ 연관 CI = ? ]N개의 검색항목으로 나올 수 있는 쿼리의 조합은 2^N개입니다.
하지만 모든 조합에 대해 인덱스를 추가할 수는 없으므로 자주 쓰는 조건을 위주로 인덱스를 구성하여야 합니다.
-
독립적으로 검색되는 컬럼이거나 복합적으로 조회될 일이 잘 없는 컬럼에 대해 경우의 수에서 제외시키고 단일 인덱스를 겁니다.
- 그 외의 것들에 복합인덱스를 고려하여 패턴을 줄입니다.
-
검색 필수 조건을 중심으로 데이터량과 R/W 빈도를 고려하여 인덱스를 구성합니다.
- 만약 4개의 검색 조건 중 2개가 필수항목이라면 쿼리 조합은 2^(4-2) = 4 개로 줄어들게 되므로 4개 쿼리만 살펴보면 됩니다.
-
선행 조건의 선택도가 좋다면 중간 조건은 생략 가능합니다.
- 만약 이름, 직급, 년도를 조건으로 급여내역을 검색하는 경우,
(이름, 직급, 급여지급일시)인덱스를 구성하는 것이 정확하지만 동명이인이 많아야 3~4명이므로 직급은 인덱스에서 제외시키고 필터처리(이름, 급여지급일시)만으로 인덱스를 구성해도 성능에 큰 영향이 없습니다. -
자주 사용되는 조합을 최우선으로 인덱스를 구성합니다.
- 모든 조합을 고려할 수 없고 모든 조합에 인덱스를 생성할 수 없으므로, 사용자를 인터뷰하거나 사용자의 검색패턴을 고려하여 자주 사용되는 조합을 최우선으로 인덱스를 구성합니다.
-
추가적으로 날짜 조건에 Default 값을 설정해주어 모든 기간에 대해 조회하는 쿼리가 발생하지 않도록 합니다.
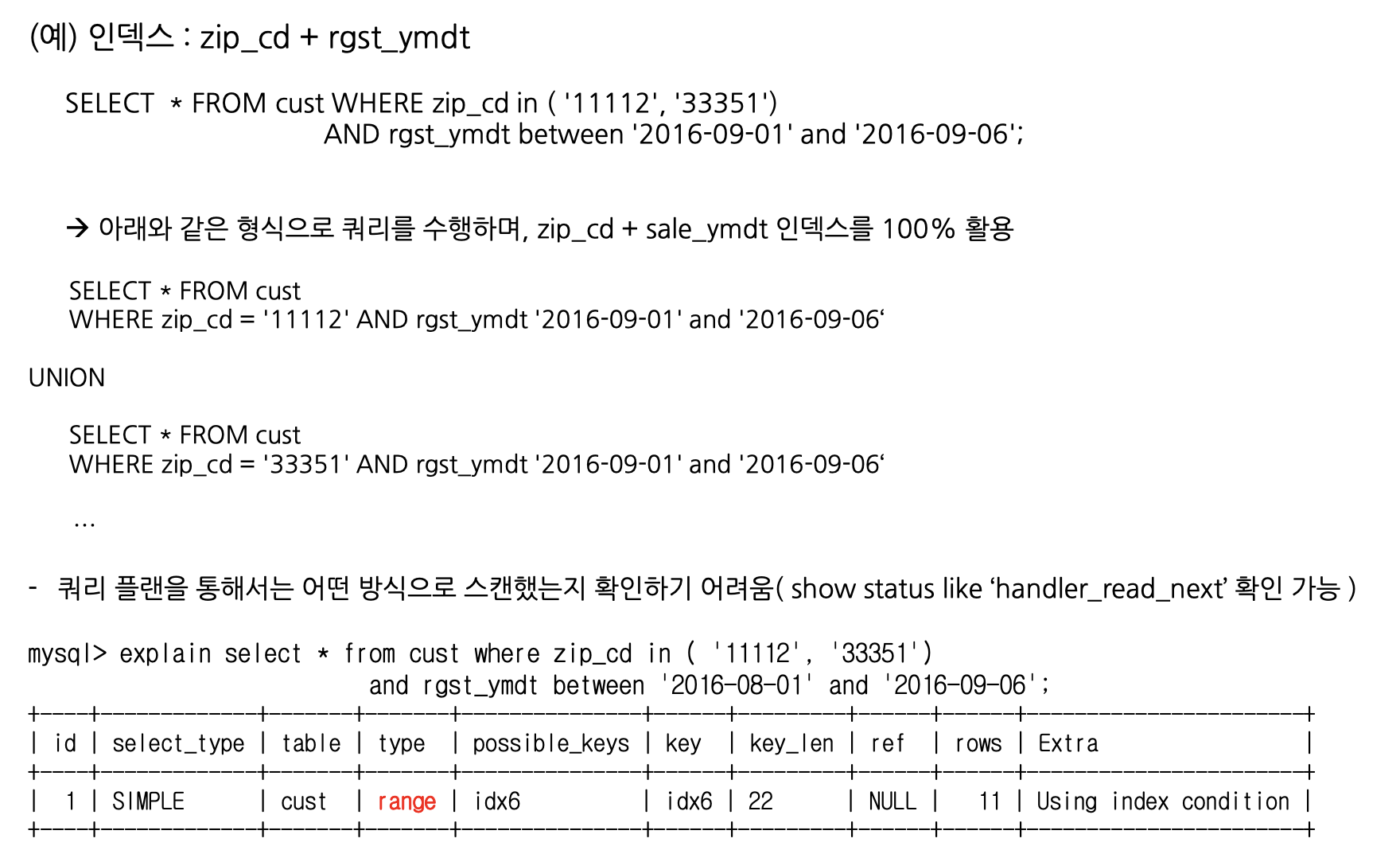
인덱스 활용기법: IN 절 처리
MySQL에서 인덱싱된 칼럼에 대한 IN 검색 쿼리는 직접 UNION으로 바꿀 필요 없이 MySQL이 내부적으로 UNION 방식으로 처리해줍니다.
Y/N으로 구성된 컬럼의 인덱스 구성
Y/N으로 구성된 컬럼의 경우 데이터의 분포도를 고려하여 인덱스 구성여부를 검토합니다.
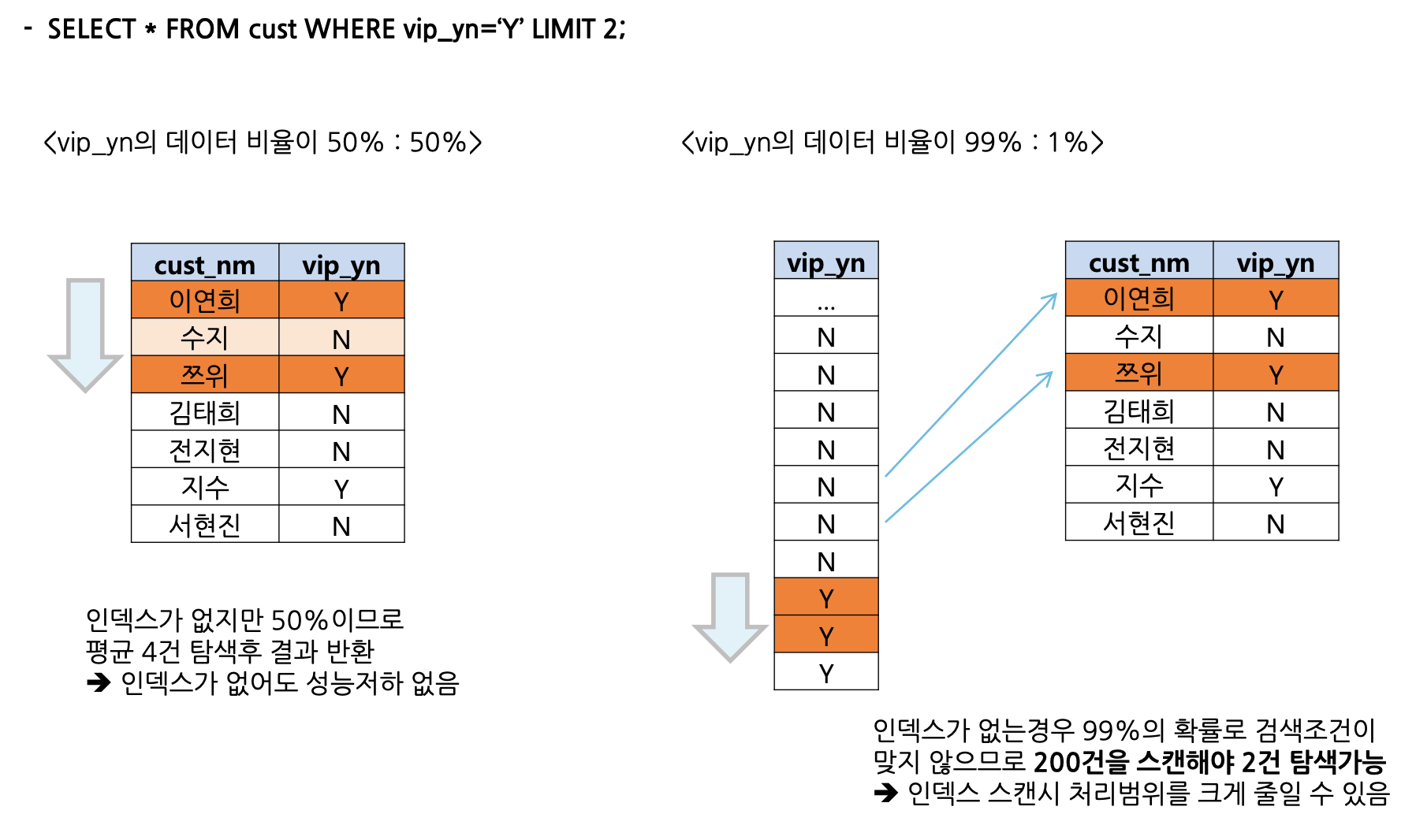
데이터의 비율이 50:50이라면 인덱스를 걸 필요가 없습니다.
만약 데이터가 한 쪽으로 몰린 경우, 몰린 쪽의 데이터를 조회한다면 인덱스가 필요합니다.
order by a ASC, b DESC 정렬 패턴
MySQL 5.7 버전까지는 descending 인덱스를 지원하지 않아 ascending으로 만들고 거꾸로 읽는 과정을 거치거나 데이터 입력 시 음수로 만드는 등의 과정을 거쳐야 했습니다.
하지만 MySQL 8.0 버전 이후부터는 descending 인덱스를 지원하게 되었습니다.

정리
- B-Tree 인덱스 구조를 사용
- PK는 Clusterd 인덱스로 생성되며 Leaf 노드에 모든 Row데이터를 저장
- Non-clustered 인덱스는 물리적 주소 대신 PK값을 참조하여 데이터를 접근
- 커버드 인덱스는 데이터페이지 접근없이 인덱스 페이지만으로 쿼리의 결과를 생성
- NULL을 값으로 인식하여 인덱스에 포함됨
- 인덱싱 컬럼에 대한 IN절은 Expansion으로 처리됨( UNION )
