목차
- MySQL Optimizer
- Join
- Index
- Etc
- Query Plan
- Practice
2. JOIN
MySQL의 대부분의 조인은 NestedLoop Join입니다.
사전지식: 릴레이션
하나의 주문은 여러 개의 상품을 가질 수 있다.
하나의 주문상품은 반드시 하나의 주문을 가질 수 있다.
하나의 상품은 여러 개의 상품카테고리를 가질 수 있다.
하나의 상품카테고리는 하나의 상품을 포함할 수 있다.
하나의 결재는 여러 개의 결재이력을 가질 수 있다.
하나의 결재이력은 하나의 결재를 포함할 수 있다.
* M:N의 관계는 중간에 테이블을 하나 더 생성해서 모든 테이블이 1:N 관계로 가져갈 수 있도록 합니다.
예시) 사원 - 부서 모델
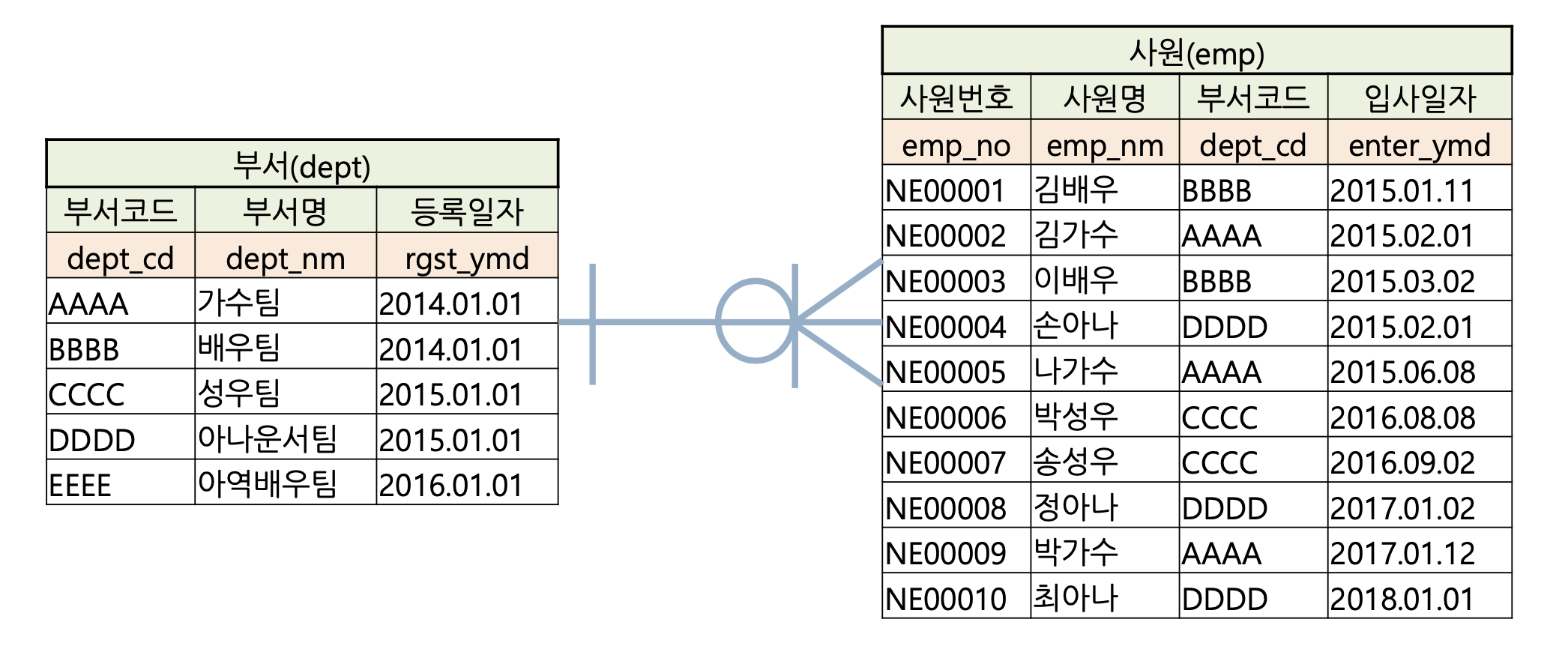
INNER JOIN
예시 1)
예시 2)

예시 3)

👉 예시 3과 같이 한 쪽의 테이블 내용만 필요한 데 GROUP BY, DISTINCT를 수행하는 것은 비효율적입니다. 이러한 쿼리는 튜닝이 필요합니다.
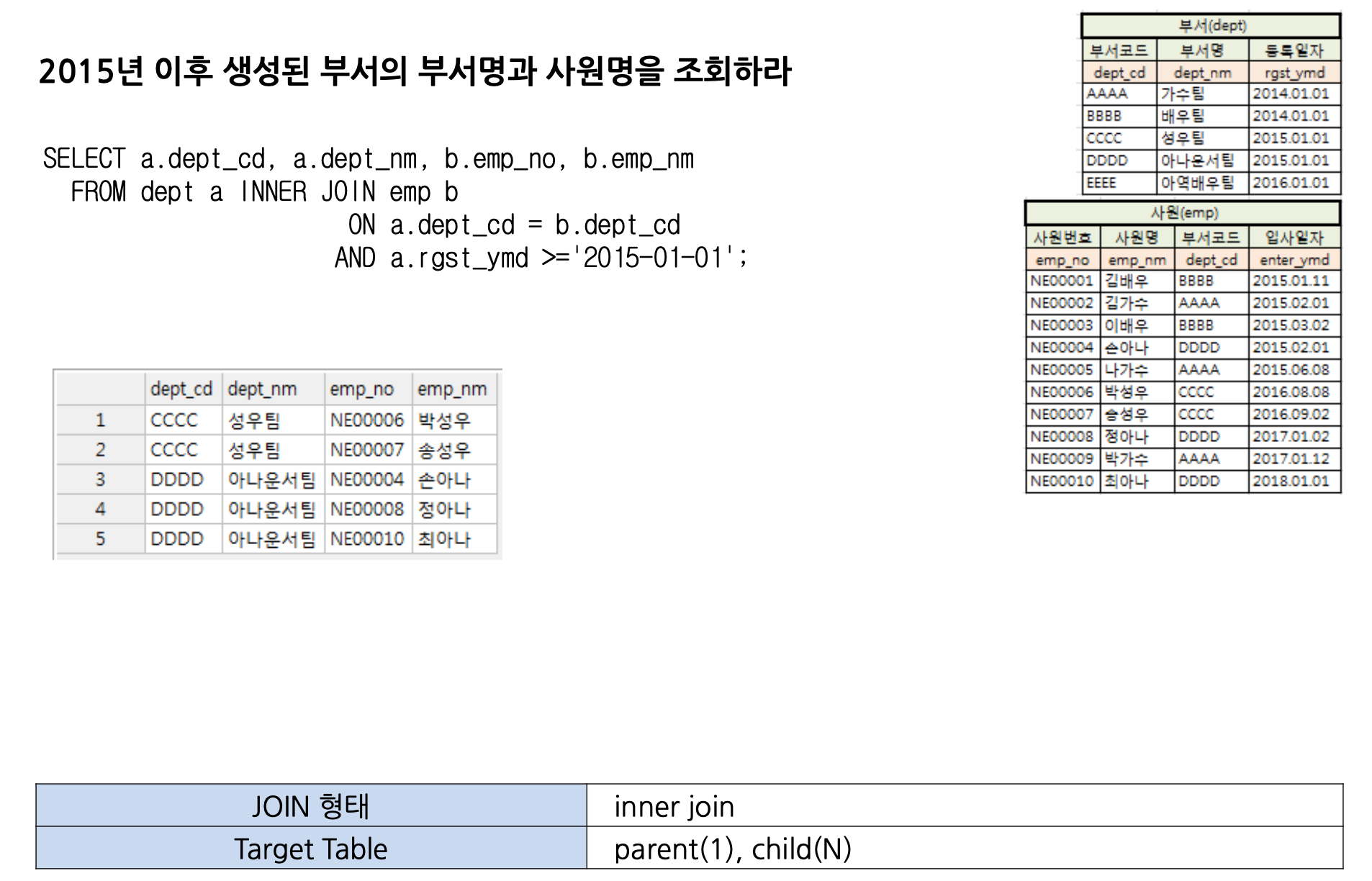
INNER JOIN의 개념
INNER JOIN이란 조인 대상 테이블 사이의 칼럼 값 Equal(=) 비교를 통해 같은 값을 가진 행끼리 연결하는 것입니다.
INNER JOIN의 형식
FROM A, B WHERE A.Key = B.Key(가장 많이 사용하는 형식)FROM A INNER JOIN B ON B.Key = A.Key(ANSI 표준)FROM A NATURAL JOIN B→ 동일한 이름을 가지는 칼럼은 모두 조인
ex)SELECT * FROM ordr a NATURAL JOIN ordr_prod bFROM A INNER JOIN B USING (A.Key)→ 지정된 칼럼과 동일한 이름의 칼럼 조인
ex)SELECT * FROM ordr a INNER JOIN ordr_prod b USING(ordr_no)
ANSI 표준을 사용하면 다른 DBMS로 이관하여도 바꿔야하는 것이 별로 없다는 장점이 있습니다.
만약 오라클을 사용하고 있다면 DBMS를 이관할 가능성이 크므로 ANSI 표준을 사용하는 것이 좋습니다.
실행계획
explain을 사용하여 실행계획을 확인할 수 있습니다.
1:1 관계라면 eq_ref, 1:N 관계이고 1이 driving이면 ref, 1:N 관계이고 N이 driving이면 eq_ref로 실행계획에 나타납니다.
mysql> explain SELECT * FROM ordr a , ordr_prod b where a.ordr_no =b.ordr_no;
+----+-------------+-------+------+---------------+---------+---------+---------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+---------------+------+-------+
| 1 | SIMPLE | a | ALL | PRIMARY | NULL | NULL | NULL | 14 | NULL |
| 1 | SIMPLE | b | ref | PRIMARY | PRIMARY | 8 | edu.a.ordr_no | 1 | NULL |
+----+-------------+-------+------+---------------+---------+---------+---------------+------+-------+
mysql> explain SELECT * FROM ordr a , ordr b where a.ordr_no =b.ordr_no;
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------+
| 1 | SIMPLE | a | ALL | PRIMARY | NULL | NULL | NULL | 14 | NULL |
| 1 | SIMPLE | b | eq_ref | PRIMARY | PRIMARY | 8 | edu.a.ordr_no | 1 | NULL |
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------+쿼리결과
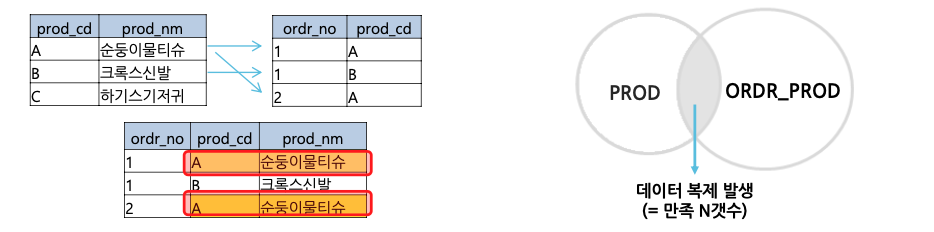
INNER JOIN 쿼리의 결과로는 1:N 관계에서 [=]조건을 만족하는 N의 건수가 최종 건수( N만큼 1의 데이터가 복제 )가 됩니다.
OUTER JOIN
OUTER JOIN 예시
예시 1)

예시 2)

예시 3)
👉 예시 2와 같이 한 쪽의 테이블 내용만 필요한 데 GROUP BY, DISTINCT를 수행하는 것은 비효율적입니다. 이러한 쿼리는 튜닝이 필요합니다.
OUTER JOIN의 개념
조인 시 한 쪽(또는 양쪽) 테이블에서 조인 조건에 맞지 않은 Row도 결과에 포함하기 위해 사용하는 JOIN입니다.
ex) 상품정보를 기준으로 주문된 상품을 조회한다. 이때, 팔리지 않은 것도 추출한다.
OUTER JOIN의 형식
FROM A LEFT (OUTER) JOIN B ON A.Key = B.Key
ex)SELECT * FROM prod a LEFT OUTER JOIN ordr_prod b ON a.prod_cd = b.prod_cd;FROM A RIGHT (OUTER) JOIN B ON A.Key = B.Key
ex)SELECT * FROM prod a RIGHT OUTER JOIN ordr_prod b ON a.prod_cd = b.prod_cd;
편의성을 위해 RIGHT OUTER JOIN은 잘 사용하지 않고 LEFT OUTER JOIN을 사용합니다.
(고정되는 쪽이 왼쪽으로 오도록 작성합니다.)
실행계획
explain을 사용하여 실행계획을 확인할 수 있습니다.
1:1 관계라면 eq_ref, 1:N 관계이고 1이 driving이면 ref, 1:N 관계이고 N이 driving이면 eq_ref로 실행계획에 나타납니다.
mysql> explain SELECT * FROM prod a left outer JOIN ordr_prod b ON a.prod_cd = b.prod_cd;
+----+-------------+-------+------+----------------+----------------+---------+---------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+----------------+----------------+---------+---------------+------+-------------+
| 1 | SIMPLE | a | ALL | NULL | NULL | NULL | NULL | 7 | NULL |
| 1 | SIMPLE | b | ref | idx2_ordr_prod | idx2_ordr_prod | 32 | edu.a.prod_cd | 2 | Using where |
+----+-------------+-------+------+----------------+----------------+---------+---------------+------+-------------+
mysql> explain SELECT * FROM ordr_prod a left outer JOIN prod b ON a.prod_cd = b.prod_cd;
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------------+
| 1 | SIMPLE | b | ALL | NULL | NULL | NULL | NULL | 22 | NULL |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 62 | edu.b.prod_cd | 1 | Using where |
+----+-------------+-------+--------+---------------+---------+---------+---------------+------+-------------+쿼리결과
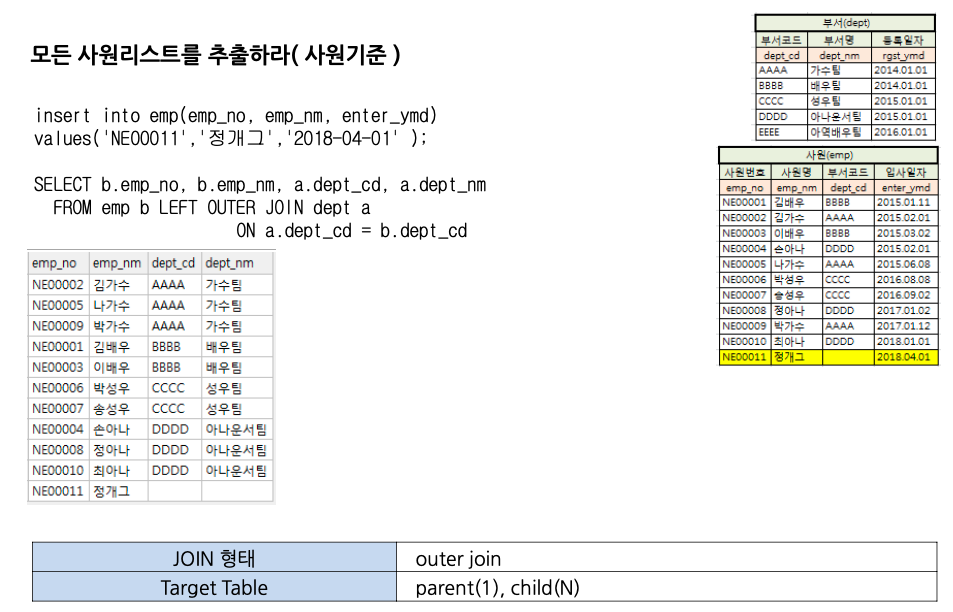
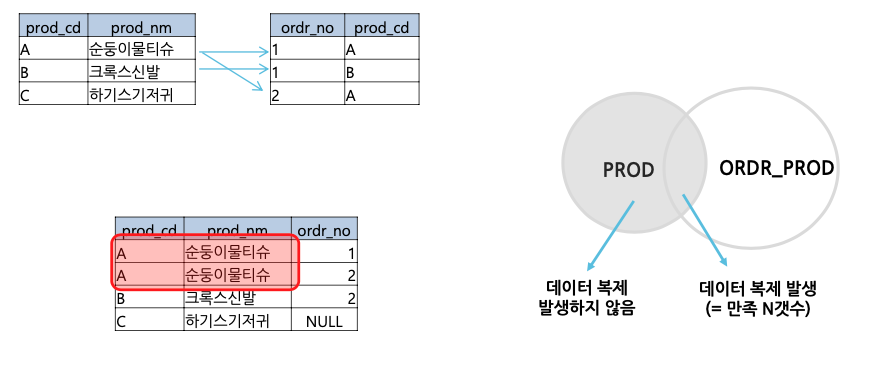
- 1:N 관계의 경우
1:N 관계의 LEFT OUTER JOIN 쿼리의 결과로는 1:N 관계( 1 left N )에서 [=]조건을 만족하는 N의 건수 + [=]조건을 만족하지 않는 1의 건수 (INNER JOIN 건수 + N) 가 최종 건수가 됩니다.
이때, [=]조건을 만족하는 N의 건수만큼 1의 데이터복제가 일어나게 됩니다.
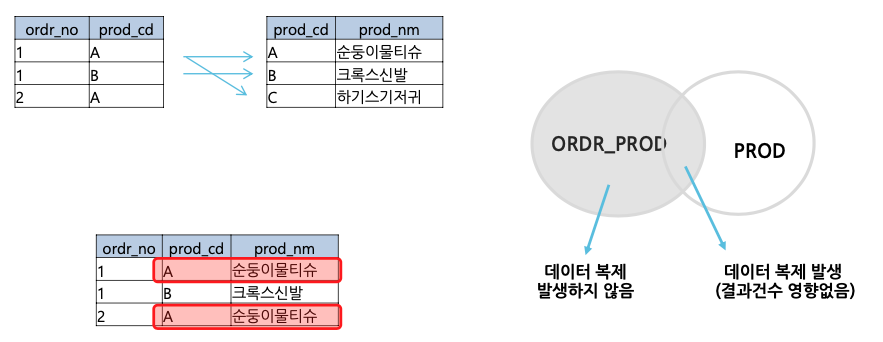
- N:1 관계의 경우
N:1 관계의 LEFT OUTER JOIN 쿼리의 결과로는 [=]조건과 관계없이 언제나 N건이 최종 건수가 됩니다.
Quiz
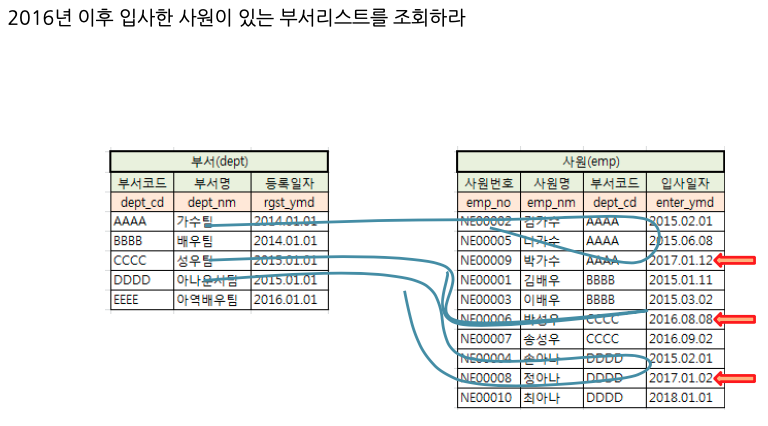
Q. 2016년 이후 입사한 사원이 있는 부서리스트를 조회하라.
👉
SELECT distinct a.dept_nm
FROM dept a, emp b
WHERE a.dept_cd = b.dept_cd AND b.enter_ymd >= '2016.01.01';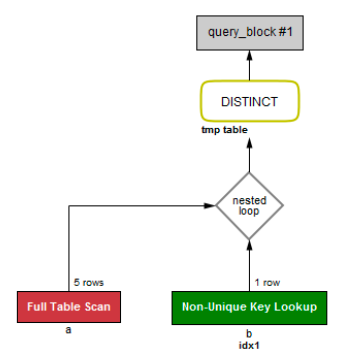
쿼리 계획 조회 시 distinct나 group by 사용 시 tmp table을 만드는 과정은 불필요한 과정인 것을 알 수 있습니다.
위의 문제에서는 한 부서에 해당되는 사원이 1명이 있건 2명이 있건 관계 없습니다.
이를 위해 Outer Join 대신 Semi Join을 사용할 수 있습니다.
Semi Join
Semi Join은 조인되는 행의 개수와 상관없이 Outer 테이블의 결과를 추출하는 Join 방법입니다.
first match 기법
loose scan 기법

materialized temp table 기법
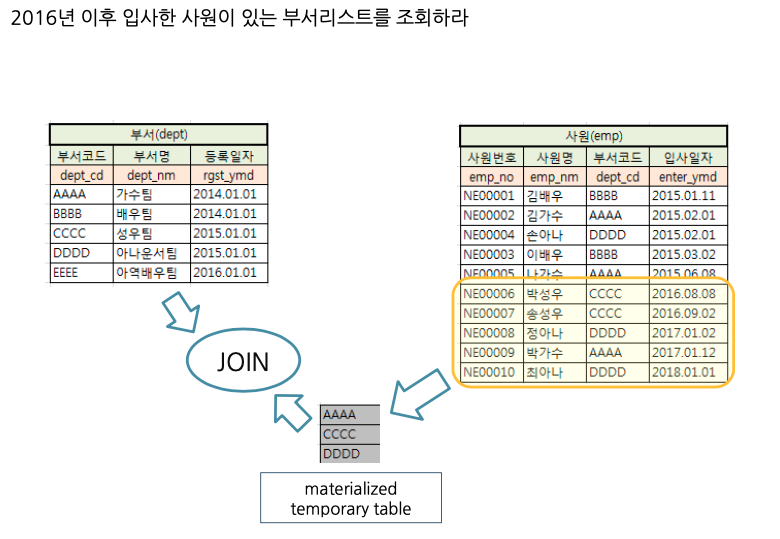
잡초뽑기 기법
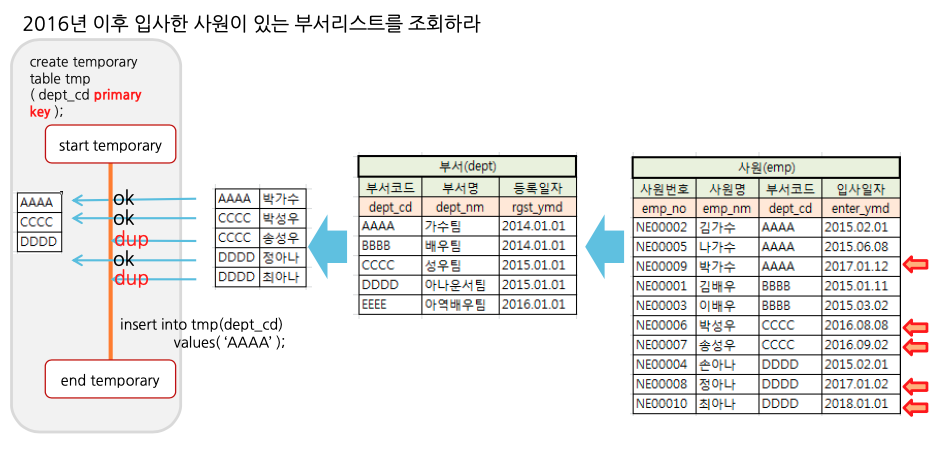
잡초뽑기 기법을 사용한다면 옵티마이저가 임의의 테이블을 만들어서 dept_cd를 pk로 지정하고 조인의 결과를 insert시키게 됩니다.
이때 중복된 결과는 dup으로 결과에 들어가지 않게 됩니다.
SEMI JOIN의 개념
SEMI JOIN은 서브 쿼리와 메인 쿼리와의 연결 처리를 위한 유사 조인 방식입니다.
WHERE절에 IN(sub-query) 또는 EXISTS(correlated sub-query)를 사용합니다.
❗️1:N의 관계에서 1의 테이블 결과만 조회하는 경우, group by가 있는데 집계함수(sum 등)가 없는 경우라면 SEMI JOIN의 사용을 고려하도록 합니다.
이러한 SEMI JOIN으로의 변경은 인덱스 다음으로 가장 중요한 튜닝 방법입니다.
SEMI JOIN의 형식
- IN (sub-query)
IN을 사용하는 경우 b의 쿼리를 먼저 실행하여 a와의 연관성을 확인하게 됩니다.
SELECT *
FROM prod a
WHERE a.prod_cd IN (SELECT b.prod_cd FROM ordr_prod b WHERE ordr_prod_cnt > 3);
SELECT *
FROM dept a
WHERE a.dept_cd IN (SELECT b.dept_cd FROM emp b where );- EXISTS (correlated sub-query)
SELECT *
FROM prod a
WHERE EXISTS (SELECT 1 FROM ordr_prod b
WHERE a.prod_cd = b.prod_cd AND b.ordr_prod_cnt >3);ANTI JOIN
ANTI JOIN의 개념
ANTI JOIN은 SEMI JOIN의 부정형입니다. WHERE절에 NOT IN, NOT EXISTS를 사용합니다.
ANTI JOIN의 형식
- NOT IN (sub-query)
SELECT a.prod_cd, a.prod_nm
FROM prod a
WHERE a.prod_cd NOT IN (SELECT b.prod_cd FROM ordr_prod b
WHERE b.ordr_prod_cnt > 3);- NOT EXISTS (correlated sub-query)
SELECT a.prod_cd, a.prod_nm
FROM prod a
WHERE NOT EXISTS (SELECT 1 FROM ordr_prod b
WHERE a.prod_cd = b.prod_cd AND b.ordr_prod_cnt > 3);- LEFT (OUTER) JOIN ... ON ... WHERE B.key is null
SELECT a.prod_cd, a.prod_nm
FROM prod a LEFT OUTER JOIN ordr_prod b
ON a.prod_cd = b.prod_cd and b.ordr_prod_cnt > 3
WHERE b.prod_cd IS NULL;조인 방식
NESTED LOOP
- MySQL 8.0.18 이전까지는 MySQL에서 지원하는 유일한 조인 방식이었습니다.
(현재는 Hash도 지원하게 되었습니다.) - 순차적인 처리를 하며, 먼저 처리되는 테이블의 처리 범위에 따라 전체 쿼리의 비용이 결정됩니다.
- 조인에 참여하는 레코드 건 수가 많아질 수록 전체적인 응답 속도 저하가 발생합니다.
- 조인 연결고리 칼럼에 인덱스 구성이 되어 있지 않은 경우, Lookup 횟수만큼 Full Table Scan을 해야 합니다.
- 다량의 Random I/O가 발생합니다.
- 주로 좁은 범위 처리에 유리합니다.
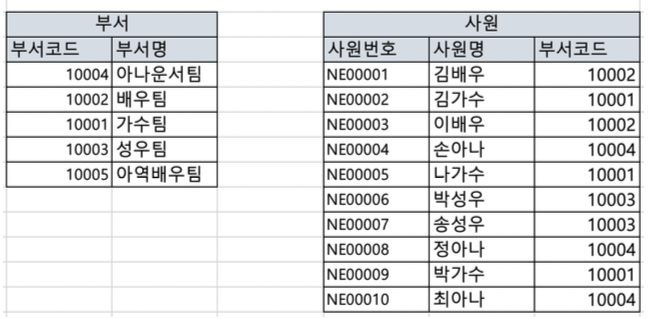
SELECT * FROM 부서 a, 사원 b WHERE a.부서코드 = b.부서코드인덱스가 없다고 가정하고 위의 쿼리를 수행하게 된다면 부서 테이블이 먼저 driving됩니다.
부서의 첫 row인 아나운서팀의 부서코드(10004)를 가져온 후,
사원 테이블을 full scan하여 10004에 해당하는 값을 가져오게 됩니다.
이때 10004에 해당하는 사원의 정보가 여러개라면 부서 정보를 중복시켜줍니다.
아나운서팀에 대한 작업이 끝나면 두 번째로 배우팀의 부서코드(10002)를 가져오고,
사원 테이블을 full scan하여 10002에 해당하는 모든 값을 가져와 부서 정보를 중복시켜줍니다.
이러한 과정을 아역배우팀까지 반복합니다.
NESTED LOOP 방식은 이렇게 선행테이블을 SCAN한 후에 후행테이블의 내용을 가져오게 됩니다.
❗️ 이때 선행테이블의 처리 범위에 따라 전체 쿼리 비용이 결정되므로, 선행테이블을 무엇으로 결정하는지가 중요합니다.
👉 따라서 NESTED LOOP 방식은 주로 좁은 범위 처리에 유리합니다.
SORT MERGE
- MySQL에서는 지원하지 않습니다.
- 조인의 대상범위가 넓을 경우 발생하는 Random Access를 줄이기 위한 경우나 연결고리에 마땅한 인덱 스가 존재하지 않을 경우 해결하기 위한 조인 방안입니다.
- 양쪽 테이블의 처리범위를 각자 Access하여 정렬한 결과를 차례로 Scan하면서 연결고리의 조건으로 Merge하는 방식입니다.
- 연결을 위해 랜덤액세스를 하지않고 스캔을 하면서 수행됩니다.
- Nested Loop Join과 같은 선행집합 개념이 없습니다.
- 정렬을 위한 영역(Sort Area Size)에 따라 효율에 큰 차이 발생합니다.
- 조인 연산자가 '='이 아닌 경우 nested loop 조인보다 유리한 경우가 많습니다.
SELECT * FROM 부서 a, 사원 b WHERE a.부서코드 = b.부서코드인덱스가 없다고 가정하고 위의 쿼리를 수행하게 된다면,
부서 테이블을 부서코드 기준으로 정렬하고 사원 테이블도 부서코드 기준으로 정렬하게 됩니다.
그 후 부서 테이블의 row 하나를 들고 sort된 사원 테이블에 해당되는 부분만 가져오고 이후는 확인하지 않습니다.
모든 부서 테이블의 row에 대해 앞의 과정을 반복하게 됩니다.
이러한 SORT MERGE 방식은 정렬 후 머지만 진행하면 됩니다.
테이블이 매우 큰데 정렬을 위한 메모리가 적다면 효율이 낮아지게 됩니다.
SORT MERGE 방식은 메모리 공간이 클수록 좋으며, sort 부하가 발생합니다.
HASH
- MySQL 8.0.18 이상에서 지원됩니다.
- 해시값을 이용하여 테이블을 조인하는 방식입니다.
- Sort-Merge 조인은 소트의 부하가 많이 발생하기 때문에, 이를 보완하기 위한 방법으로 Sort 대신 해쉬값을 이용하는 조인입니다.
- 대용량 처리의 선결조건인 랜덤액세스와 정렬에 대한 부담을 해결할 수 있는 대안입니다.
- 2개의 조인 테이블 중 small rowset을 가지고 hash_area_size에 지정된 메모리 내에서 hash table 생성합니다.
- Hash table 생성 후 Nested Loop처럼 순차적인 처리 형태로 수행됩니다.
SELECT * FROM 부서 a, 사원 b WHERE a.부서코드 = b.부서코드인덱스가 없다고 가정하고 위의 쿼리를 수행하게 된다면, mysql 내부에서 hash function이 하나 만들어집니다.
ex) h(x)=mod(부서코드)
그 후 1:N의 1에 해당하는 테이블에 hash function을 적용하여 hash table을 생성합니다.
이후 N 테이블의 값을 하나씩 hash function을 적용하여 해당되는 버킷에 담습니다.
이러한 과정은 메모리에서만 처리되므로 매우 빠릅니다.
hash에 해당하는 몇몇 케이스(도큐먼트 참고)를 제외하고는 모두 nested loop로 튜닝 문제를 해결할 수 있습니다.
실습 - Nested Loop 의 이해
SELECT 부서코드, 부서명, 사원번호, 사원명
FROM 부서 A, 사원 B
where a.부서코드 = b.부서코드-
Access순서는? ( 두 테이블은 pk만 존재 )
- 부서가 먼저 driving되면 사원 테이블에서 모두 full scan해야 합니다 👉 5*10 스캔 필요
- 사원이 먼저 driving되면 부서 테이블에서 pk 인덱스를 타고 scan합니다 👉 10*1 스캔 필요
- 👉 그러므로 옵티마이저는 사원 테이블을 먼저 driving하게 됩니다.
- 하지만 가끔 옵티마이저가 사원을 먼저 driving하지 않는 경우가 발생하기 때문에 적절한 인덱스를 설정하는 것이 필요합니다.
-
필요한 인덱스를 만들고 스캔하는 것을 확인해봅시다.
-- 사원.사원명 인덱스 생성
SELECT 부서코드, 부서명, 사원번호, 사원명
FROM 부서 A, 사원 B
WHERE a.부서코드 = b.부서코드
AND B.사원명 = ‘정아나’;-- 부서.부서명 인덱스 생성
SELECT 부서코드, 부서명, 사원번호, 사원명
FROM 부서 A, 사원 B
WHERE a.부서코드 = b.부서코드
AND A.부서명 = ‘배우팀’;만약 따로 요구사항이 없다면, 기본적으로 pk와 fk에 인덱스를 걸도록 한다.
(* fk에 fk constraint를 거는 것이 아닌 그냥 인덱스를 거는 것)
조인 순서의 결정
- 기본적으로 MySQL 옵티마이저는 모든 테이블 조인 순서에 대해서 Cost를 계산합니다.
- Cost 측정 방법은 단일쿼리의 측정 방법과 동일합니다.
- 최소 Cost가 계산된 조인 순서를 기반으로 실행 계획을 생성합니다.
SELECT City.Name, Language
FROM Languages, Country, City
WHERE City.Country = Country.Code
AND City.ID = Country.Capital
AND City.Population >= 5000000
AND Languages.Country = Country.Code
AND Percentage > 4.0;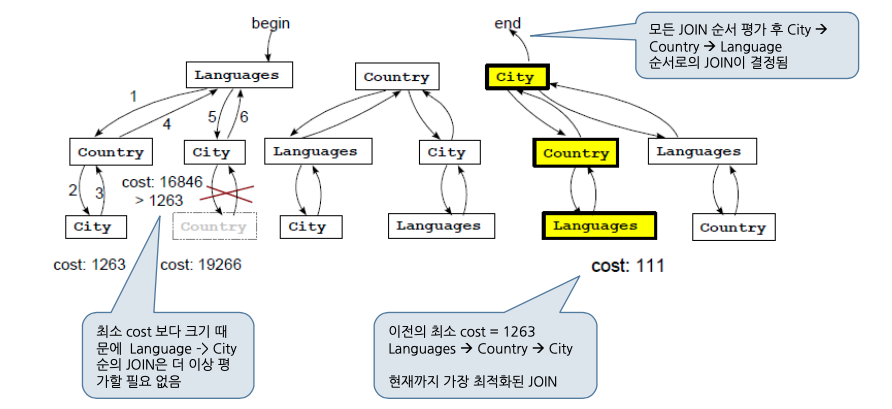
1:N Join 시 1의 결과만을 조회하는 경우의 튜닝
- Parent(1) / Child(N) 를 확인
- SELECT 절에 속한 컬럼 확인
- 모두 PARENT에만 속하는 경우 중복제거를 위한 ( inner / left outer ) group by 혹은 distinct를 사용하는지 확인하여 SEMI JOIN 형태로 변경
👉 플랜을 뜨기 전에 눈으로 쿼리를 보고 group by/distinct를 semi join으로 변경하면 매우 빨라질 수 있다는 것을 눈치챌 수 있다면 됩니다.
1:N 관계에서의 쿼리 패턴


위와 같은 형식으로 게시물의 목록을 보여주려면 덧글의 count를 뽑기위해 덧글 테이블을 모두 scan해야 합니다.
👉 반정규화하여 덧글의 개수를 게시물 테이블에서 가지고있게 합니다.
👉 모든 SNS가 게시물 형식을 가지므로 해당 개념 활용할 수 있습니다.
정리
- Join의 종류
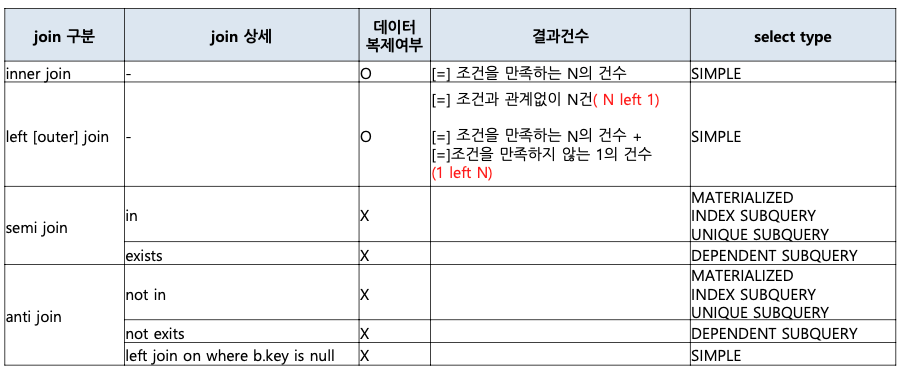
-
Join 방식
- Nested Loop Only ( < 8.0.18 ), Nested Loop & Hash ( >= 8.0.18 )
-
Join 순서의 결정
- 모든 액세스 패스의 cost를 계산하여 최소 cost의 조인 순서를 결정
연습문제
- 아래 쿼리들이 각각 어떤 종류의 조인인지 확인하고 실행 플랜을 확인해 보세요.
SELECT a.prod_cd, a.prod_nm
FROM prod a
WHERE NOT EXISTS (SELECT 1 FROM ordr_prod b
WHERE a.prod_cd = b.prod_cd AND b.ordr_prod_cnt > 3);SELECT a.prod_cd, a.prod_nm
FROM prod a INNER JOIN ordr_prod b USING (prod_cd)
WHERE b.ordr_prod_cnt = 3 ;SELECT a.prod_cd, a.prod_nm, b.ordr_no
FROM prod a LEFT JOIN ordr_prod b ON a.prod_cd = b.prod_cd
WHERE b.ordr_prod_cnt > 3;SELECT a.prod_cd, a.prod_nm
FROM prod a
WHERE a.prod_cd IN (SELECT b.prod_cd FROM ordr_prod b where ordr_prod_cnt > 3);-
상품(50건)테이블과 주문상품(500건)테이블이 있을 때 아래 각 쿼리의 결과는?
( 주문상품의 모든 상품번호는 상품테이블에 존재, 주문상품 테이블에 없는 상품번호는 총 5개 )
1.SELECT count(*) FROM 상품 A, 주문상품 B ON A.상품번호 = B.상품번호
2.SELECT count(*) FROM 상품 A LEFT OUTER JOIN 주문상품 B ON A.상품번호 = B.상품번호
3.SELECT count(*) FROM 주문상품 A LEFT OUTER JOIN 상품 B ON A.상품번호 = B.상품번호 -
아래 쿼리는 2016년 상반기에 등록된 상품 중 판매이력이 있는 상품을 조회하는 쿼리입니다.
SELECT a.prod_cd, a.prod_nm
FROM prod a INNER JOIN ordr_prod b ON a.prod_cd = b.prod_cd
WHERE a.prod_rgst_ymdt < ‘2016-07-01 00:00:00’
GROUP BY a.prod_cd, a.prod_nm ;다른 JOIN 방식을 사용하여 더 빠른 결과를 얻을 수 없는지 생각해 보고, 개선된 쿼리와 실행 플랜을 비교해 보세요. 실행 플랜을 비교해 보았다면, 기존 쿼리에서 어떤 부분이 비효율적인지 생각해 보세요.
👉 GROUP BY를 수행하지만 집계함수(SUM 등)이 없다면 SEMI JOIN으로 변경하기!
👉 1:N 관계를 1:1처럼 풀어주므로 DISK I/O가 확 줄어들 수 있음
❗️ 쿼리를 보고 형태를 찾아내는 것을 연습하는 것이 필요
