목차
- MySQL Optimizer
- Join
- Index
- Etc
- Query Plan
- Practice
4. etc
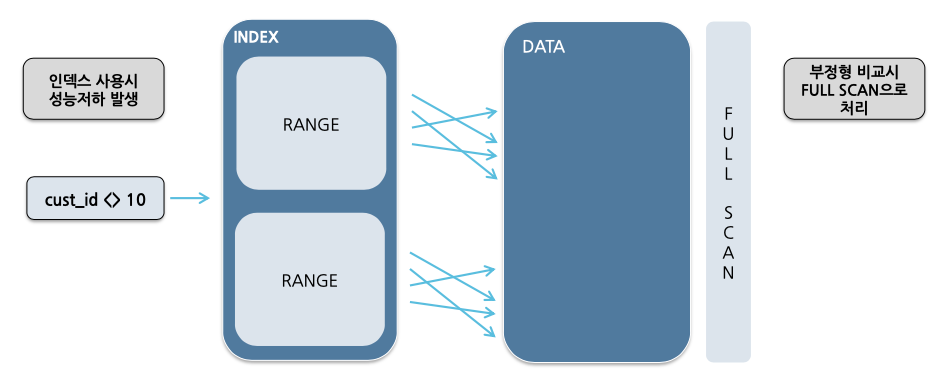
부정형 비교
인덱스가 존재하더라도 부정형 비교가 발생하는 경우에는 인덱스를 사용할 수 없습니다.
ex) SELECT * FROM cust WHERE cust_id <> 10;
👉 10을 기준으로 위, 아래를 각각 나눠 인덱스를 타는 것보다 풀테이블 스캔을 하는 것이 성능 상으로 더 좋습니다.
ex) SELECT * FROM cust WHERE cust_id not in (10,11,15,20);
👉 not in은 인덱스를 타지 않습니다. 참고로 코드값이 얼마 없을 때 in을 사용하면 인덱스를 태울 수 있습니다.
cf) is not null은 인덱스를 사용합니다.
Scalar subquery vs Join
Driving Table에서 1:1관계의 데이터를 얻는 방법은 아래의 3가지가 있습니다.
- Join 이용
select count(*)
from ( select a.product_id, b.product_name
from reserve a, product b
where a.product_id = b.product_id
limit 100000
) x;- select절에서 서브쿼리 이용 (Scalar subquery)
select count(*)
from ( select product_id, (select product_name
from reserve a
limit 100000
) x;- function 이용
select count(*)
from (select a.product_id, get_product_name(a.product_id)
from reserve a
limit 100000
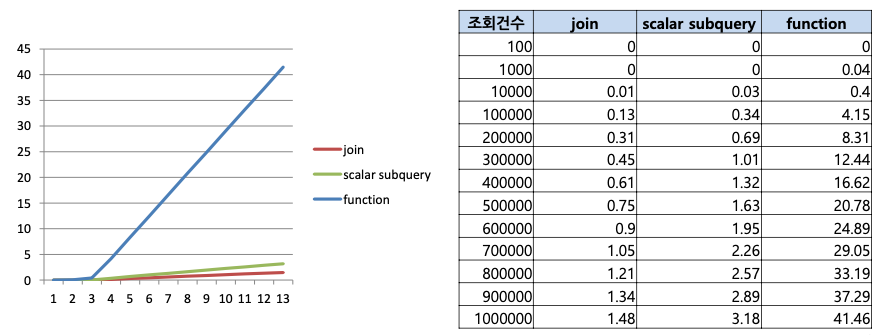
) x;Join > Scalar subquery > 함수 순으로 응답속도가 뛰어나며, 조인이 제일 성능 상 가장 유리합니다.
Join과 Scalar subquery는 조회건수가 적은 경우에는 비슷한 성능을 보이지만 결과셋이 큰 경우 응답속도 측면에 차이가 있기 때문에 Join으로 변경하는 것이 좋습니다.
Scalar subquery의 경우 outer의 건수만큼 쿼리를 실행시키므로 pasing비용 등의 추가비용이 발생합니다.
function은 간단하고 쿼리를 짧게 만들어주어 가독성 측면에서 좋지만 응답속도는 현저히 느리기 때문에 사용하지 않는 것을 권장합니다.
OLTP성 업무에서는 JOIN이나 scalar subquery를 써도 무방하지만 배치작업 등 대용량의 데이터를 처리하는 경우 JOIN으로 변경하는 것이 필요합니다. (밤에 돌리는 배치성 작업)
Derived Condition pushdown
Derived Condition pushdown은 outer query의 where조건을 inner query로 밀어넣어 처리량을 줄이는 방법입니다.
MySQL 8.0.22 버전 이상에서는 옵티마이저에서 자동 적용됩니다.
MySQL 8.0.22 미만 버전에서는 직접 쿼리 튜닝이 필요합니다. 👉 outer의 정보들을 inner로 집어 넣는 것이 튜닝 포인트입니다.

LIMIT n
LIMIT 절은 full scan이나 index scan 시 조건에 맞는 개수(N)을 만족하면 스캔을 중단합니다.
ORDER BY col1 LIMIT n 절의 경우 order by 절이 인덱스를 이용할 수 없다면 where 조건을 만족하는 모든 데이터를 물리 정렬 수행한 후 LIMIT 적용하므로 좋지 않은 응답속도를 보입니다.
실제 몇건을 스캔하는 지는 runtime에 알 수 있으므로 실행계획에는 limit와 무관하게 표시됩니다.
이에, 실행 계획에서 처리범위를 확인할 수 없지만 handler_read_xxxstatus를 확인하여 알 수 있습니다.


Union(ALL) ~ order by
Union [ALL] ~ order by 는 order by시 인덱스를 사용할 수 없으므로 언제나 filesort를 유발합니다.
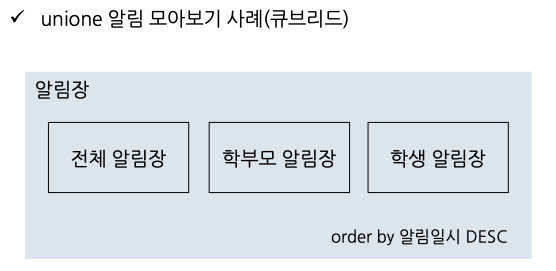
위 그림과 같은 경우에는 테이블이 분할되어 있기 때문에 order by시 인덱스를 타지 않아 filesort가 발생됩니다.
이는 SQL 튜닝으로 해결되지 않기 때문에 테이블 통합을 고려해보아야 합니다.
OR
OR 연산자는 논리합을 만들어내는 연산이므로 각 조건을 모두 확인해야 합니다.
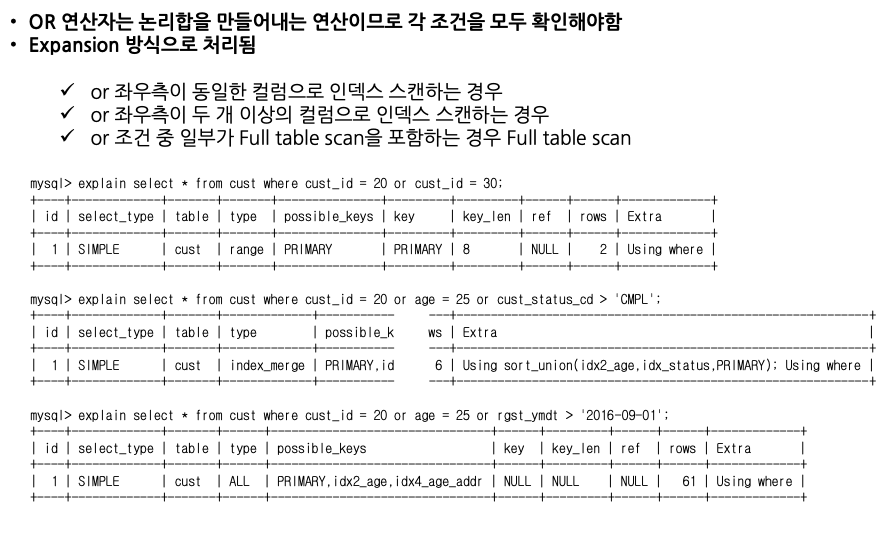
explain select * from cust where cust_id = 20 or cust_id = 30;- 쿼리가 2개 실행되는 것처럼 동작
explain select * from cust where cust_id = 20 or age = 25 or cust_status_cd > 'CMPL';- 스스로 인덱스를 이용
explain select * from cust where cust_id = 20 or age = 25 or rgst_ymdt > '2016-09-01';- 튜닝이 어려움
OR는 인덱스를 타는 경우도 있고 안타는 경우도 있기 때문에 튜닝이 어렵고 주의해서 봐야 합니다.
예제
-- index 구성 : idx_ymdt(reserve_datetime) , idx_buy_cd_ymdt(reserve_state_code, reserve_datetime)
SELECT *
FROM reserve
WHERE (reserve_state_code = 'ALL_CANCEL' OR reserve_state_code= 'COMPLETE' )
AND reserve_datetime >= '2016-08-01'
ORDER BY reserve_datetime DESC
LIMIT 10;👉 OR을 in으로 빼내어 (reserve_state_code)가 인덱스를 타도록 만듭니다.
select *
from reserve
where reserve_state_code in ('ALL_CANCEL', 'COMPLETE')
and rserve_datetime >= '2016-08-01'
order by reserve_datetime desc
limit 10;하지만 수정한 쿼리에서는 reserve_datetime으로는 정렬이 불가능하므로 Order by를 통한 정렬이 필요합니다.
👉 order by가 수행되지 않고 데이터 엑세스가 최소화되는 것이 좋으므로 Union으로 분리합니다.
select *
from (
(select *
from reserve
where reserve_state_code = 'ALL_CANCEL'
and reserve_datetime >= '2016-08-01'
order by reserve_datetime desc
limit 10)
union all
(select *
from reserve
where reserve_state_code = 'COMPLETE'
and reserve_datetime >= '2016-08-01'
order by reserve_datetime desc
limit 10)
) a
order by a.reserve_datetime desc
limit 10;👉 서브쿼리 안에서는 인덱스를 타므로 order by를 타지 않게 되며, 최종 20개를 뽑은 결과에서는 정렬을 수행하게 됩니다.
👉 이러한 부분은 옵티마이저가 알아서 해주는 부분이 아니므로 명시적으로 튜닝이 필요합니다.
요약
- ALL_CANCEL, COMPLETE로 분리후 각각 10건만 뽑아 정렬합니다.
- 각각 10개씩 뽑아야 전체 순서를 보장할 수 있습니다. (한쪽에 모두 포함될 수 있으므로)
- 건수를 줄이고 나서 order by를 실행하기 때문에 file sort가 최소한으로 일어나게 됩니다.
Group by ~ Order by NULL
- MySQL 8.0 미만 버전의 경우 group by는 정렬을 수반합니다.
- 그러므로 정렬이 필요하지 않다면 order by null 구문 활용하여야 합니다.
- MySQL 8.0 이상 버전부터는 group by에서 정렬이 수행되지 않습니다.
- 정렬이 필요한 경우라면 order by를 사용하여야 합니다.
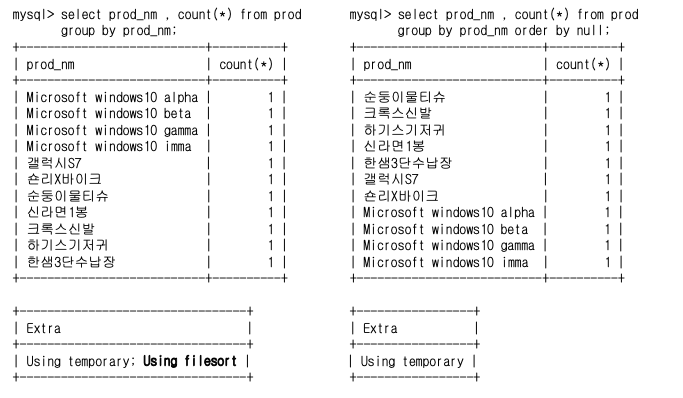
DINSTINCT vs. GROUP BY
GROUP BY를 이용하여 UNIQUE 결과를 찾는 경우와 DISTINCT를 사용하여 UNIQUE 결과를 찾는 경우,
MySQL 5.7 버전까지는 모두 결과셋이 동일하지만 정렬 유무의 차이가 발생합니다.
MySQL 8.0 버전부터는 동일한 결과를 볼 수 있습니다.

Loose Index Scan 유도
인덱스를 활용할 수 없는 조건절에는 조건을 추가하여 Loose Index Scan을 유도하도록 합니다.
아래의 예시는 복합 인덱스( vip_yn, age )가 존재하는 상황입니다.
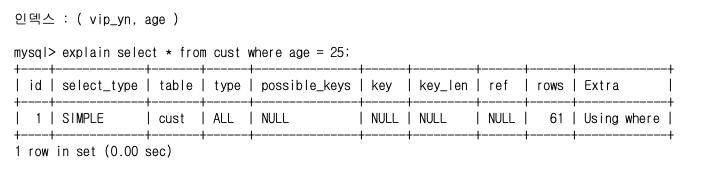
위와 같은 쿼리에서는 단일 인덱스는 없고 복합 인덱스만 있기 때문에 인덱스를 탈 수 없습니다.
(해당 칼럼을 선행 인덱스로 가진 인덱스가 없음)
이러한 쿼리에서 새로운 인덱스를 걸고 싶지 않다면, 선행 조건을 명시적으로 넣어 index scan을 유도할 수 있습니다.

수정된 쿼리를 통해 age에 대한 인덱스 추가 없이 기존 인덱스를 타도록 튜닝할 수 있습니다.
