목차
- MySQL Optimizer
- Join
- Index
- Etc
- Query Plan
- Practice
5. 플랜/힌트의 이해
EXPLAIN STATEMENT
EXPLAIN
EXPLAIN은 MySQL이 어떻게 쿼리를 실행하는 지에 관한 정보를 보여주는 명령어입니다.
MySQL 5.6.3 이전 버전에서는 SELECT만 가능(Update, Delete의 경우 SELECT로 변환하여 수행해야 함)했으며,
MySQL 5.6.3 이후 버전은 SELECT, DELETE, INSERT, UPDATE, REPLACE 으로 기능이 확대되었고,
MySQL 8.0.18 이후부터는 EXPLAIN ANALYZE를 사용할 수 있게 되었습니다.
사용법
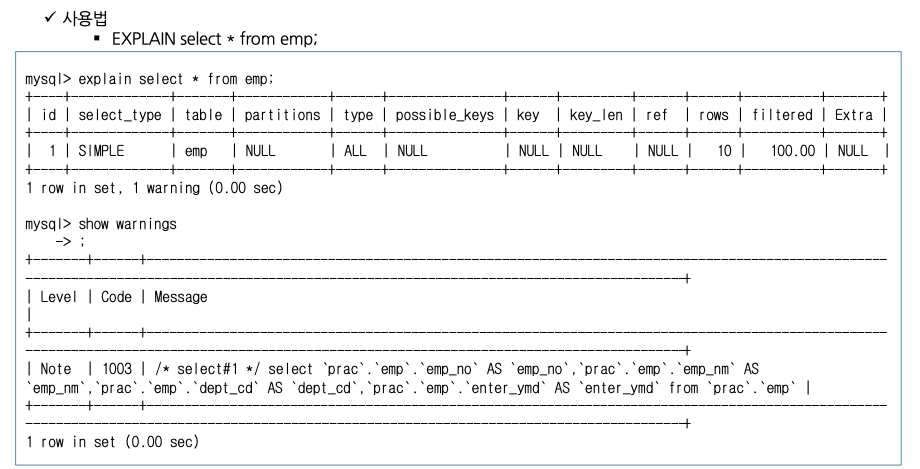
explain 내역에서 1 warning이라고 뜨는 것을 확인하기 위해 show warnings 명령어를 사용할 수 있습니다.
해당 내용을 통해 옵티마이저가 쿼리를 어떻게 변경했는지 볼 수 있습니다.
EXPLAIN FORMAT=[TRADITIONAL | JSON | TREE]
- Tree: 안에서 바깥으로, 위에서 아래로

EXPLAIN ANALYSE
- 실제 쿼리가 수행되어 정확한 row수, 실행시간 확인 가능
- 실제 수행되므로 매우 오래 걸릴 수 있음
- EXPLAIN 은 실제 실행 없이 대략적으로 분석
- Tree 형태로만 출력됨

EXPLAIN OUTPUT FORMAT
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | a | NULL | ALL | NULL | NULL | NULL | NULL | 14 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | b | NULL | ref | PRIMARY | PRIMARY | 8 | edu.a.ordr_no | 1 | 100.00 | Using index |
참고) filter가 100에 가까울수록 잘 활용된 것 (실제 사용 row수 / 파일에서 읽어온 row 수) * 100
- id : SELECT identifier
- select_type : SELECT 유형
- table : 테이블명 또는 Alias
- partitions : 쿼리결과와 일치하는 레코드의 파티션, 파티션되지 않은 테이블인 경우 NULL
- type : JOIN 유형 (Access 유형)
- possible_keys : 쿼리처리를 위해 옵티마이저가 고려한 인덱스 후보
- key : 옵티마이저가 실제 선택한 인덱스
- key_len : 선택된 인덱스에서 실제 사용한 인덱스의 길이
- ref : 조회를 위해 사용된 상수 또는 컬럼
- rows : 쿼리를 수행하기 위해 처리해야 하는 row의 개수 (옵티마이저 추정치)
- filtered : 조건에 의해 필터링되는 테이블 row의 예상 비율
- Extra : 쿼리 처리에 사용된 부가정보
select_type
-
SIMPLE
- union 또는 subquery가 없는 select문
- 아래 결과의 id가 동일하다는 것은 서브쿼리(계층) 없이 동등하게 조인된다는 의미

-
PRIMARY
- union의 첫번째 쿼리를 포함한 대부분의 outer 쿼리
- subquery, inline view ...

-
UNION
- union 쿼리에서 PRIMARY를 제외한 나머지 select

- union 쿼리에서 PRIMARY를 제외한 나머지 select
-
DEPENDENT UNION
- union과 동일하나 outer query에 의존적인 union
- 안쪽으로 들어온 union

-
UNION RESULT
- union의 결과. id가 null인 것이 특징
-
SUBQUERY
- sub-query 혹은 sub-query를 구성하는 쿼리 중 첫번째 select

- sub-query 혹은 sub-query를 구성하는 쿼리 중 첫번째 select
-
DEPENDENT SUBQUERY
- subquery와 동일하나 outer query에 의존적

- subquery와 동일하나 outer query에 의존적
-
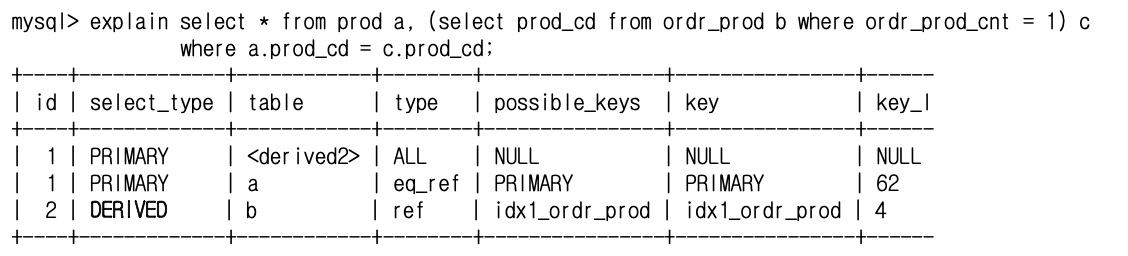
DERIVED
- from절에서의 서브쿼리( Inline view )
- select_type의 derived
- table의 derived
- primary에 derived2라고 적힌 것은 그 primary가 실제로는 id=2의 derived인 것
-
MATERIALIZED
- 메모리테이블로 생성되는 서브쿼리 ( 5.6이후 in절 성능개선으로 추가됨 )
- 아래 결과의 table에 subquery2의 뜻은 id=2의 subquery라는 것

-
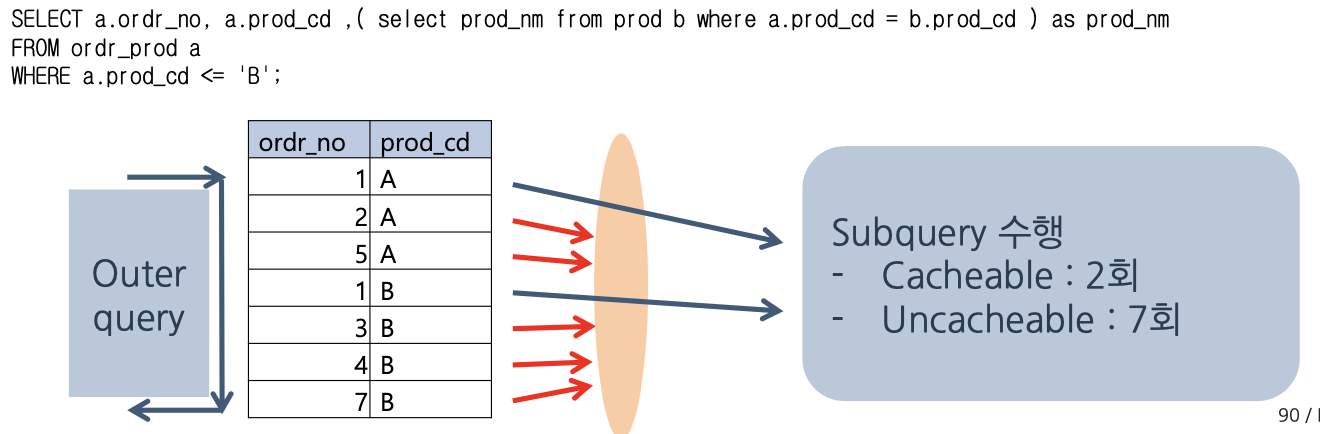
UNCACHEABLE SUBQUERY
- result 결과를 cache할 수 없는 서브 쿼리
- outer에서 공급되는 값이 subquery를 재처리해야 함
- outer에서 공급되는 값이 동일하더라도 cache된 결과 사용불가

-
UNCACHEABLE UNION
- union과 동일하지만, 공급되는 모든 값에 대해 union 쿼리 재처리
참고) Cacheable VS Uncheable
type : Access type
테이블을 어떻게 접근할 것인지에 대한 내용입니다. (중요❗️)
select_type 만으로는 튜닝거리인지 판단할 수 없어 type을 함께 확인하여야 합니다.
* MySQL 매뉴얼 상에는 join type이라고 되어 있으나 access type으로 해석하는 것이 일반적임.
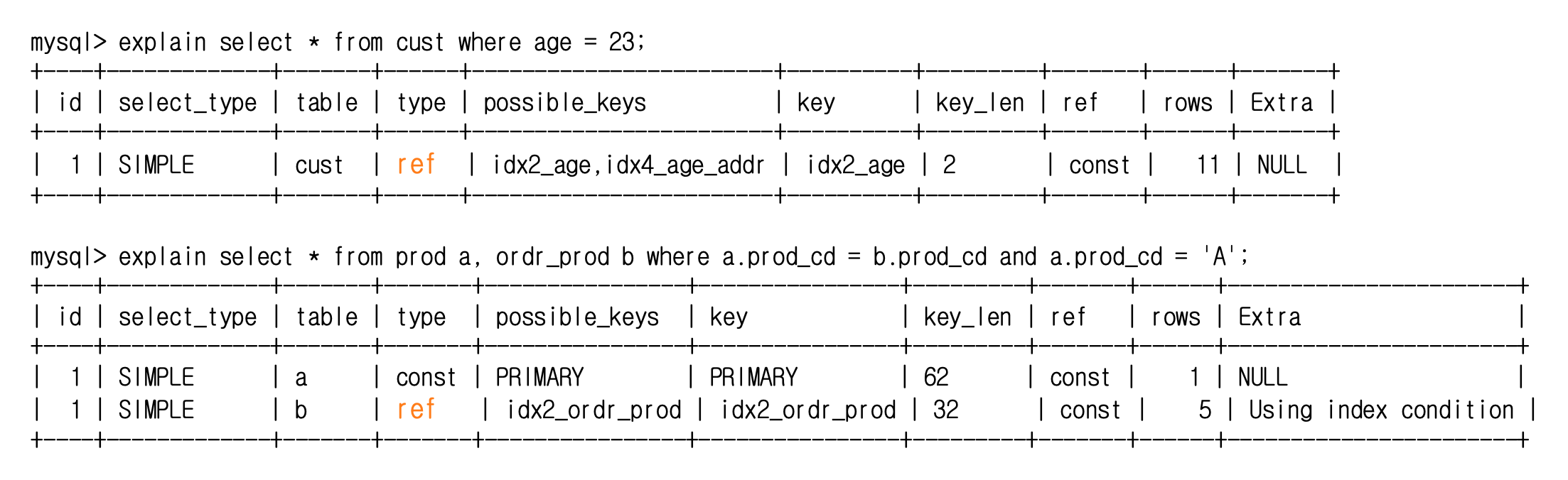
- system : 테이블에 오직 하나의 row만 존재하는 경우
- const : 매칭되는 row가 오직 1건, pk/unique key 사용

- eq_ref
- 조인시 선행 테이블에서 공급받은 값이 조인되는 테이블에 1개만 존재하는 경우
- 1:N 관계에서 1 의 관계에 해당하는 경우
- 1:1관계 혹은 1:N관계에서 N테이블이 선행으로 드라이빙되고 pk/unique key를 사용하는 경우

- 조인시 선행 테이블에서 공급받은 값이 조인되는 테이블에 1개만 존재하는 경우
- ref
- 이전 테이블과 매칭되는 모든 로우를 인덱스를 사용하여 Access
- 1:N 관계에서 N 의 관계에 해당하는 경우
- 조인시 pk/unique key를 100% 사용하지 못하거나( 복합pk의 선행컬럼만 이용) non-unique 인덱스를 사용
- 하나의 테이블에서 select 하는 경우 index key하나에 여러 row가 매칭되는 경우( non-unique )
- 제공되는 값에 매칭되는 row가 많지 않다면 좋은 join type임
- 동등조건으로 비교(=)
- 이전 테이블과 매칭되는 모든 로우를 인덱스를 사용하여 Access
- fulltext : Full text 인덱스를 사용하여 데이터 Access
- 매우 느 림
- fulltext가 필요하다면 검색엔진을 쓰는 것이 좋음. ( ex. elastic search )

- ref of null : ref와 동일하나 is null 비교가 추가된 형태
- is null 비교가 추가된 ref

- is null 비교가 추가된 ref
- index_merge : 동일한 테이블에서 두개 이상의 인덱스를 사용하는 경우
- 보통 쿼리 하나에 사용할 수 있는 인덱스는 하나이지만, 옵티마이저가 알아서 동일한 테이블에서 두 개 이상의 인덱스를 머지하여 데이터 접근한 경우
- → 옵티마이저가 잘 수행된 것!

- unique subquery
- in subquery에서 unique한 결과가 만들어지는 경우 ➔ value IN ( SELECT PK_col From tab WHERE ... )
- index subquery
- unique subquery와 유사
- in subquery 에서 중복된 결과가 만들어짐(중복제거필요 ➔ value IN (SELECT KEY_col From tab WHERE ... )
- range
- 주어진 범위 내의 row를 스캔
- <, >, IS NULL, BETWEEN, IN, LIKE 등의 연산자를 이용하여 인덱스 스캔

- index
- 인덱스 페이지 전체를 읽는 Index Full Scan
- 인덱스 페이지 스캔한다는 점을 제외하면 ALL(Full Table Scan)과 동일 (성능이 떨어짐)
- 일반적으로 인덱스가 테이블보다 작으므로 ALL보다는 빠를 가능성이 높음
- 인덱스 페이지를 full scan

- ALL
- 전체 데이터 페이지를 읽는 Full Table Scan
- 위 엑세스 방법을 모두 사용할 수 없을 때 선택되는 scan 방식

Extra
옵티마이저가 어떤 기법으로 최적화를 시켰는지에 대한 정보입니다.
| 구분 | 설명 |
|---|---|
| const row not found | 대상테이블이 empty인 경우 |
| Distinct | 첫번째 매칭되는 row를 찾는 경우 이후의 row는 탐색을 중단 Distinct 처리에 사용 |
| FirstMatch | semi join first match 전략을 사용한 경우 |
| Full scan on NULL key | subquery 사용시 outer에서 null값을 공급받는 경우 |
| Impossible HAVING | Having 절이 항상 false인 경우 |
| Impossible WHERE | where절이 항상 false인 경우 ( ex. not null 컬럼에 대한 is null 비교 ) |
| Impossible WHERE noticed after reading const tables | 실행계획을 생성하는 과정에서 system/const type의 경우 이를 미리 실행해보고 false임을 판단 |
| Materialize( 5.6.7 이후 ) | subquery를 maerialize 형태로 최적화하는 경우 |
| No tables used | From절이 없거나 From절에 dual과 같은 상수 테이블이 사용되는 경우 ( ex. select 1; ) |
| Not Exists | left join형태의 anti join을 not exists 형태로 최적화하는 경우 |
| Range checked for each record( index map : N ) | 선행테이블의 레코드마다 range나 index merge등 인덱스를 사용할 수 있는지 체크 |
| Select tables optimized away | 인덱스 lookup 후 1개의 결과만 리턴하는 경우( 쿼리실행X ). group by가 없는 aggregate 함수만 포함되거나 커버링 인덱스의 선행컬럼이 =조건인 쿼리의 후행컬럼을 aggregation하는 경우 |
| Using filesort 👎 | 물리적인 정렬작업 수행 |
| Using index 👍 | 데이터 파일을 읽지 않고 인덱스만 읽어서 결과를 처리할 수 있는 경우( 커버링 인덱스 ) |
| Using index condition 👍 | where 조건이 storage engine에서 필터링되는 경우 ( 메모리에 데이터를 올릴 때 필터링을 거침 ) |
| Using index for group by | using 인덱스와 유사. group by를 인덱스만 이용하여 처리 |
| Using join buffer | full table scan을 피하기 위하여 드라이빙 테이블의 결과셋을 temp로 생성 |
| Using MRR | non-clustered index를 통해 range 스캔하는 경우 중간에 random 버퍼를 이용하여 pk정렬수행 후 pk 순차스캔하는 효과를 발생시키는 경우 |
| Using intersect/union/sort_union | index merge 최적화 |
| Using temporary 🤔 | 쿼리처리를 위해 임시 테이블을 생성 |
| Using where | mysql engine에서 데이터를 filter처리하는 경우 ( 메모리에서 필터링 ) |
- Using filesort
- 물리적으로 파일 소트가 수행되는 경우로 튜닝의 대상
- 인덱스를 이용하여 없애면 좋음
- sort_buffer_size 보다 작은 데이터인 경우 sort_buffer를 활용
- sort_buffer_size 보다 큰 경우 sort_buffer만큼만 읽어서 quick sort를 수행하고 결과를 temp file에 기록.
- merge 대상이 있으면 merge 후 위 작업반복
- sort 연산은 굉장히 비싸므로 인덱스를 활용할 수 있도록 해야함
- filesort가 발생할 수 밖에 없는 경우 결과셋을 작게 가져가는 전략필요
- Using temporary
- 쿼리처리를 위해 임시 테이블을 생성하므로 튜닝 고려 필요
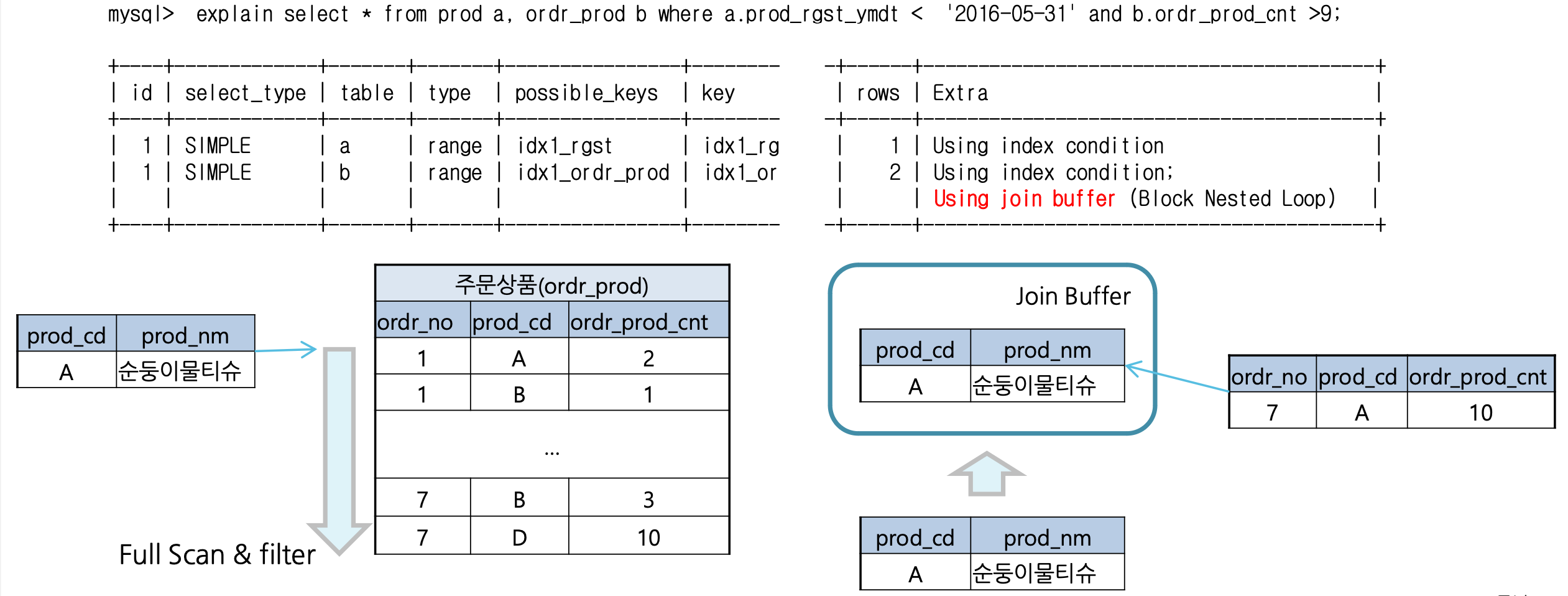
- Using join buffer
- join key가 없는 쿼리의 경우 옵티마이저는 조인버퍼를 이용하여 조인을 시도
- 둘 중 하나를 조인 버퍼로 사용
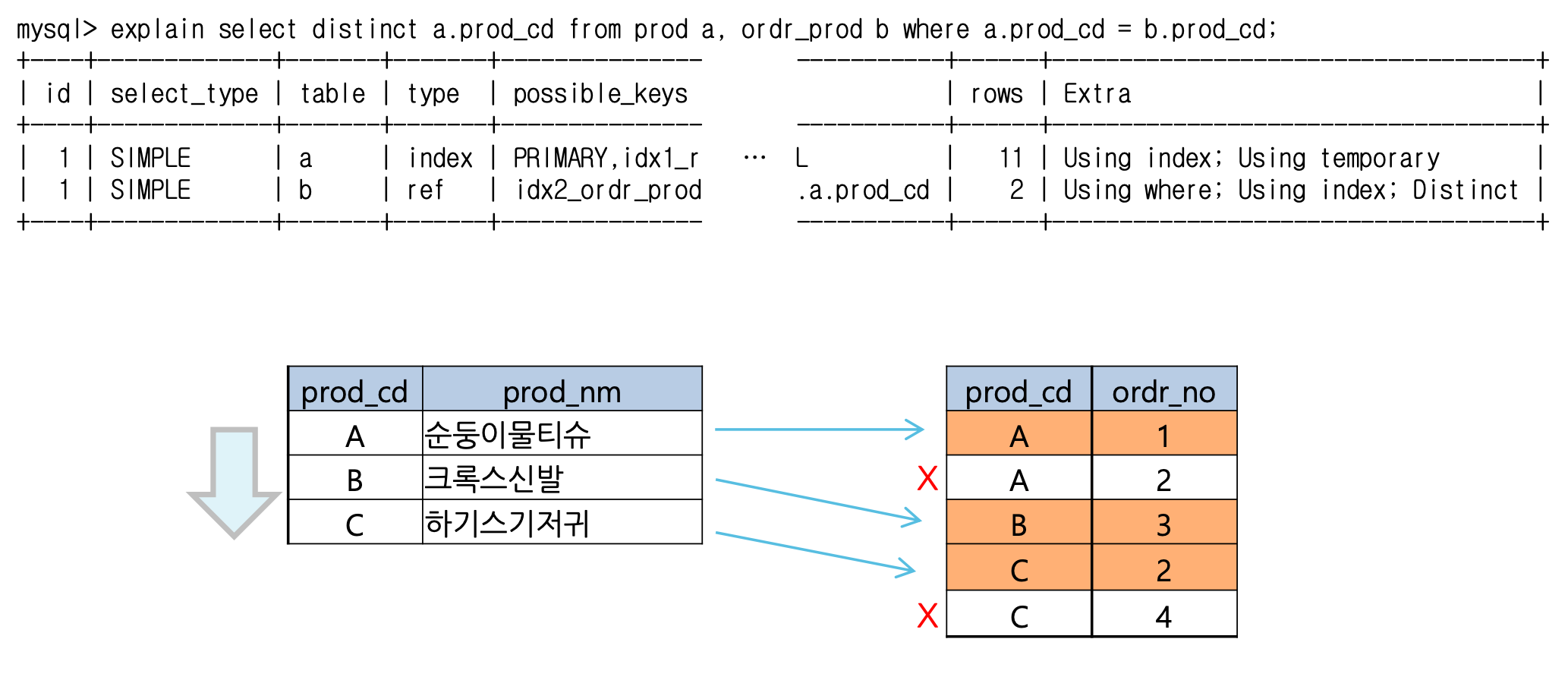
- Distinct
- 조인의 결과가 distinct이므로 조인 시 필요한 레코드만 조회하고 중복이 되는 레코드는 skip하는 경우
- semi join의 효과
- 명시적으로 in이나 exists를 사용하는 것이 더 직관적
- Impossible WHERE
- not null 컬럼의 is null 비교처럼 쿼리를 실행해보지 않고도 where절이 항상 false인 경우

- not null 컬럼의 is null 비교처럼 쿼리를 실행해보지 않고도 where절이 항상 false인 경우
- Impossible WHERE noticed after reading const tables
- 실행계획 생성과정에서 system/const 액세스 타입인 경우 상수처리를 위해 미리 실행해보고 false임을 판단

- 실행계획 생성과정에서 system/const 액세스 타입인 경우 상수처리를 위해 미리 실행해보고 false임을 판단
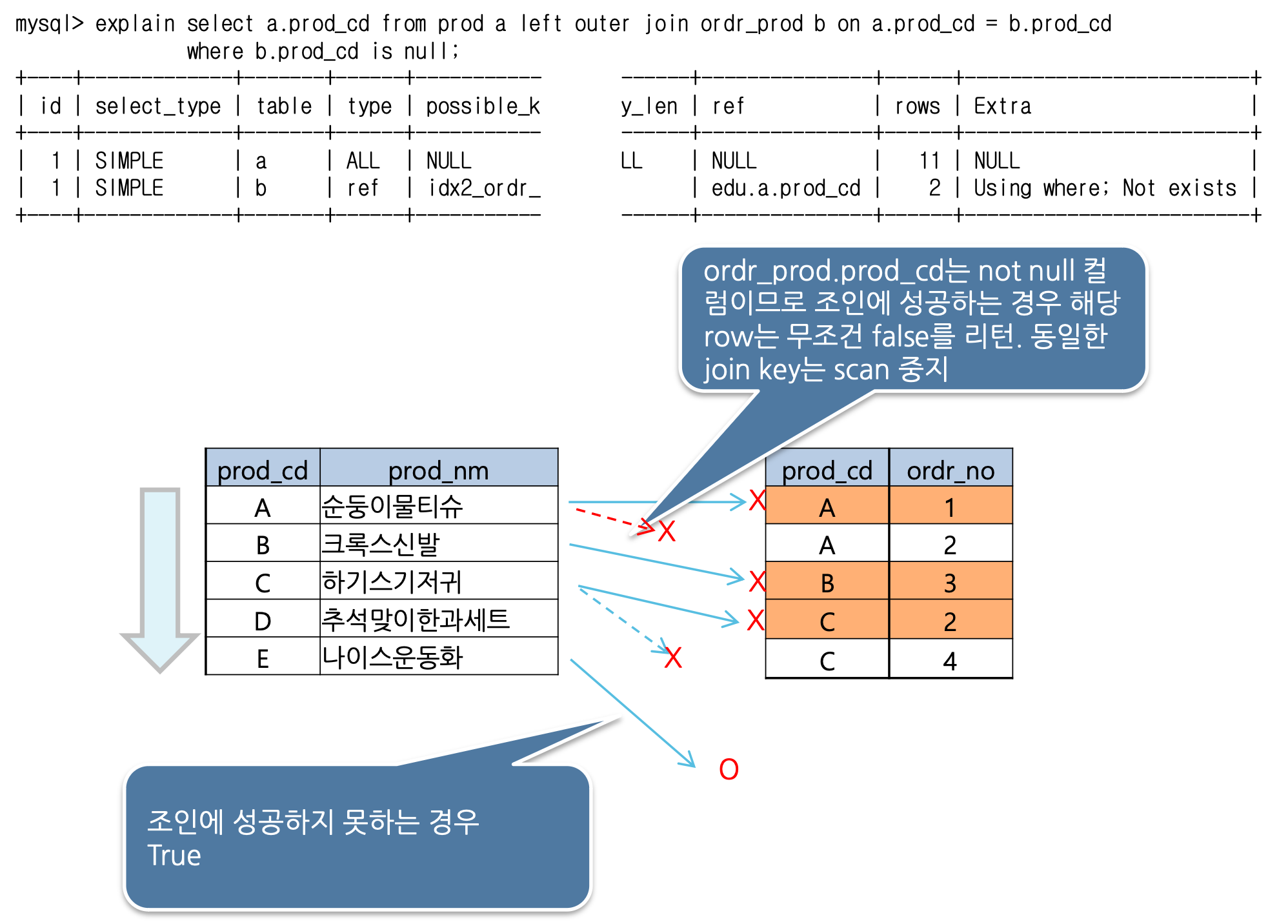
- not exists
- anti join의 특수한 형태
- 선행 테이블의 row별 1번씩만 스캔
- 조인에 성공하는 경우 stop, 조인에 실패하는 경우만을 결과셋으로 리턴
- Range checked for each record ( indexmap : N )
- 선행 테이블의 레코드마다 액세스 방법을 체크
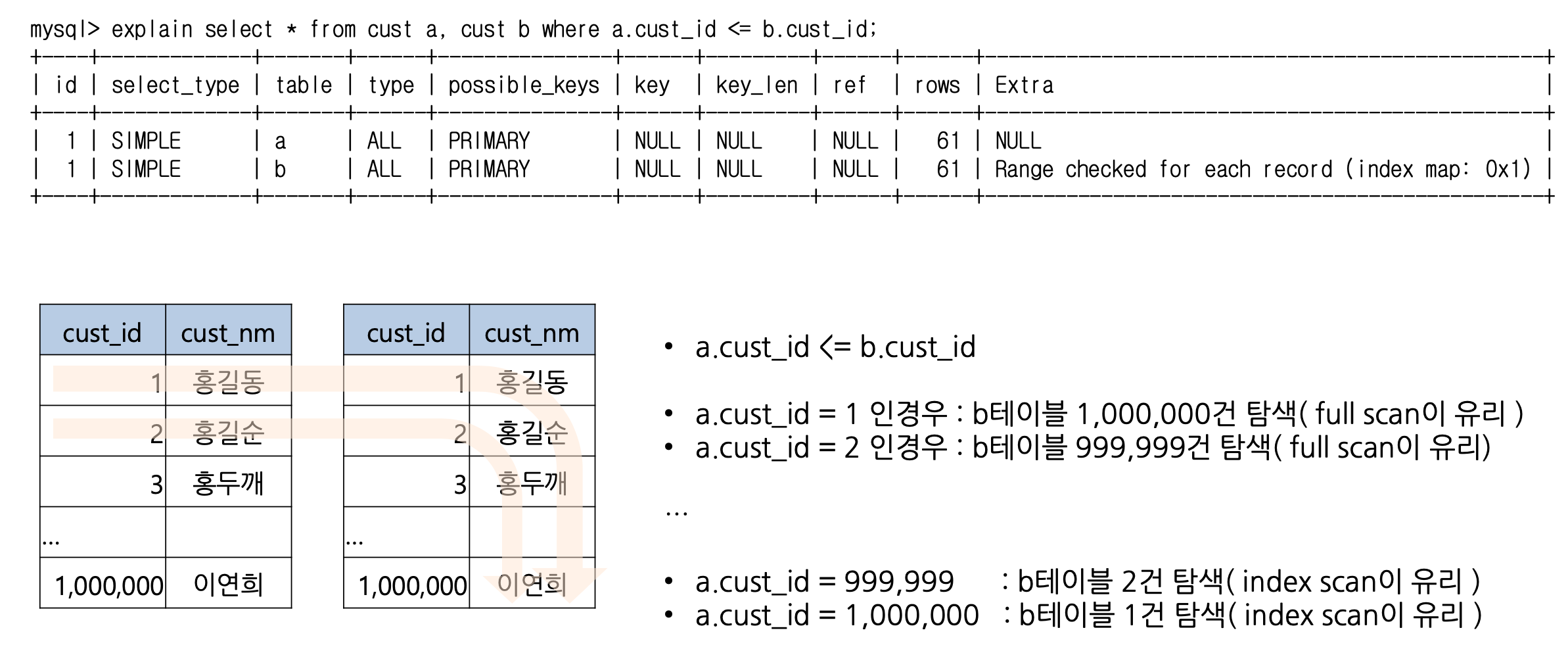
- index map : N
- N을 이진수로 변환하여 뒷자리부터 show create table 문에 나타난 인덱스 순서
- 1101이라면 (idx3, idx2,
idx1, pk)중 1에 해당하는 인덱스를 적용 후보로 선택 - 선행테이블의 각 레코드 단위로 pk, idx2, idx3를 이용하여 후행 테이블을 스캔한다는 의미
- 선행 테이블의 레코드마다 액세스 방법을 체크
HINT
INDEX HINT
- USE INDEX, IGNORE INDEX, FORCE INDEX
- 특정 인덱스를 지정하거나 사용하지 않게 함
- USE/FORCE INDEX를 사용하더라도 인덱스를 사용하지 않을 수 있음
SELECT * FROM TB1 USE INDEX( idx1) where ...
- STRAIGHT_JOIN
- JOIN 순서를 SQL에 명시된 순서대로 고정
SELECT STRAIGHT_JOIN * FROM TB1, TB2 ...
- SQL_CALC_FOUND_ROWS
- SELECT 하면서 COUNT를 동시 처리, LIMIT 사용시 주의
- 잘 사용하지 않음
```sql mysql> select SQL_CALC_FOUND_ROWS * from cust; 61 rows in set (0.00 sec) mysql> select FOUND_ROWS(); | 61 | mysql> select SQL_CALC_FOUND_ROWS * from cust limit 1; 1 row in set (0.00 sec) mysql> select FOUND_ROWS(); | 61 | ```
- SQL_CACHE / SQL_NO_CACHE
- 명시적으로 Query Cache할 것인지 지정
- Query Cache Type=2인 경우 지정된 SQL 구문과 Result Set만 Cache 됨
SELECT SQL_NO_CACHE * FROM TB1 ...- 잘 사용하지 않음
- MySQL 8.0 이후부터 쿼리 캐시 기능이 사라짐
- lock 유발, 캐시 접근으로 인한 병목 현상 등
OPTIMIZER HINT
옵티마이저 힌트는 ANSI 표준으로 사용 가능합니다.
| Hint Name | 설명 | Applicable Scopes |
|---|---|---|
| BKA, NO_BKA | BKA(배치키엑세스) join 사용 | Query block, table |
| BNL, NO_BNL | BNL(블록네스티드루프) 사용 8.0.20 이후 해시조인 사용여부 제어 | Query block, table |
| DERIVED_CONDITION_PUSHDOWN, NO_DERIVED_CONDITION_PUSHDOWN | 외부 쿼리 조건의 derived 테이블 사용여부 | Query block, table |
| GROUP_INDEX, NO_GROUP_INDEX | group by 절 처리를 위한 인덱스 사용여부. Group by 처리에만 영향을 미침 | Index |
| HASH_JOIN, NO_HASH_JOIN | 8.0.18에서만 사용 | Query block, table |
| INDEX, NO_INDEX | group by, order by, where 절의 인덱스 사용여부. USE INDEX, IGNORE INDEX 에 대응 | Index |
| INDEX_MERGE, NO_INDEX_MERGE | INDEX MERGE 사용여부 | Table, index |
| JOIN_FIXED_ORDER | FROM절에 기술된 순서대로 조인, STRAIGHT_JOIN에 대응 | Query block |
| JOIN_INDEX, NO_JOIN_INDEX | table access(row를 찾는 방법)에 대한 인덱스 사용여부 | Index |
| JOIN_ORDER | 힌트에 명시된대로 조인 | Query block |
| JOIN_PREFIX | 힌트에 명시된 테이블을 드라이빙으로 조인 | Query block |
| JOIN_SUFFIX | 힌트에 명시된 테이블을 드리븐으로 조인 | Query block |
| MAX_EXECUTION_TIME | 쿼리의 실행시간을 제어 | Global |
| MERGE, NO_MERGE | 외부 쿼리 블록으로 derived table 또는 뷰를 병합 | Table |
| MRR, NO_MRR | MRR 사용 | Table, index |
| NO_ICP | 인덱스 컨디션 푸쉬다운 사용 | Table, index |
| NO_RANGE_OPTIMIZATION | 인덱스 레인지를 비활성화. 인덱스를 사용하지 못하고 full scan으로 처리 | Table, index |
| ORDER_INDEX, NO_ORDER_INDEX | order by 절 처리를 위한 인덱스 사용여부 | Index |
| QB_NAME | 쿼리블록에 이름을 할당(쿼리블록에 대한 주석이라고 이해하면 됨) | Query block |
| RESOURCE_GROUP | 쿼리실행의 리소스 그룹설정 | Global |
| SEMIJOIN, NO_SEMIJOIN | 세미조인 사용여부 및 전략 선택 | Query block |
| SKIP_SCAN, NO_SKIP_SCAN | 스킵스캔 사용여부 | Table, index |
| SET_VAR | 쿼리실행을 위한 시스템 변수 제어. Ex) select /*+ SET_VAR(sort_buffer_size='8388608') */ from ... | Global |
| SUBQUERY | 서브쿼리의 세미조인 최적화 전략 제어 | Query block |
만약 query_timeout이 10초로 설정되어있는데, 특정 커리만 시간 제한을 다르게 하고싶다면 MAX_EXECUTION_TIME으로 힌트 설정 가능합니다.
또한 쿼리마다 시스템 변수를 제어하고 싶다면 SET_VAR를 사용합니다.
* 참고 : https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html
정리
- MySQL에서 플랜을 확인하기 위해서는 explain 명령어를 사용한다
- select_type은 SELECT 유형을 의미한다
- type은 Access type을 의미한다
- 👍 (좋은 경우) : Const, system, eq_ref
- 👎 (튜닝 필요) : ALL(테이블풀스캔), index(인덱스풀스캔)
- 🤔 (튜닝 고려) : range, ref
- extra는 실행계획을 생성할 때 적용하는 최적화 기법을 표현하거나 부가정보를 담는다
- 👍 (좋은 경우) : using index(커버링인덱스), using where(메모리에서 필터링)
- 👎 (튜닝 필요) : using filesort, using join buffer
- 👎 필요한 최종 결과에 비해 rows 가 많은 것은 튜닝이 필요하다
- 특정인덱스를 사용하거나 사용하지 않도록 하는 인덱스 힌트는 아래와 같다
- USE INDEX/FORCE INDEX
- IGNORE INDEX
- STRAIGHT JOIN은 드라이빙 순서를 고정할 때 사용하는 힌트이다
